
pyspider的使用
pyspider 是一個用python實現的功能強大的網路爬蟲系統,能在瀏覽器介面上進行指令碼的編寫,功能的排程和爬取結果的實時檢視,後端使用常用的資料庫進行爬取結果的儲存,還能定時設定任務與任務優先順序等。
本篇文章只是對這個框架使用的大體介紹,更多詳細資訊可見官方文件。
安裝
首先是環境的搭建,網上推薦的各種安裝命令,如:
pip install pyspider
但是因為各種許可權的問題,博主安裝報錯了,於是採用了更為簡單粗暴的方式,直接把原始碼下下來run。
pyspider的原始碼地址,直接download或者git clone都行,下載完成後,進入資料夾目錄。
系統預設用的Python是2.7版本,自己另外裝了個3.4的,原始碼用python3跑起來。
先進行安裝,在pyspider的路徑下敲命令:
python3 setup.py install
一堆的列印,完了之後沒什麼錯誤提示就是安裝完成了。
接下來跑起來:
python3 run.py
執行結果如下圖所示
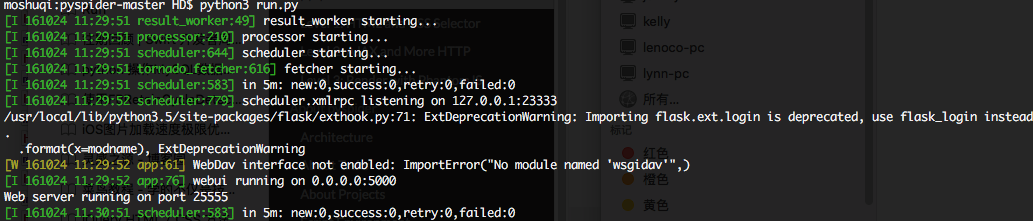
可以看到webui執行在5000埠處,在瀏覽器開啟127.0.0.1:5000或者localhost:5000,便能看到框架的UI介面,如下圖
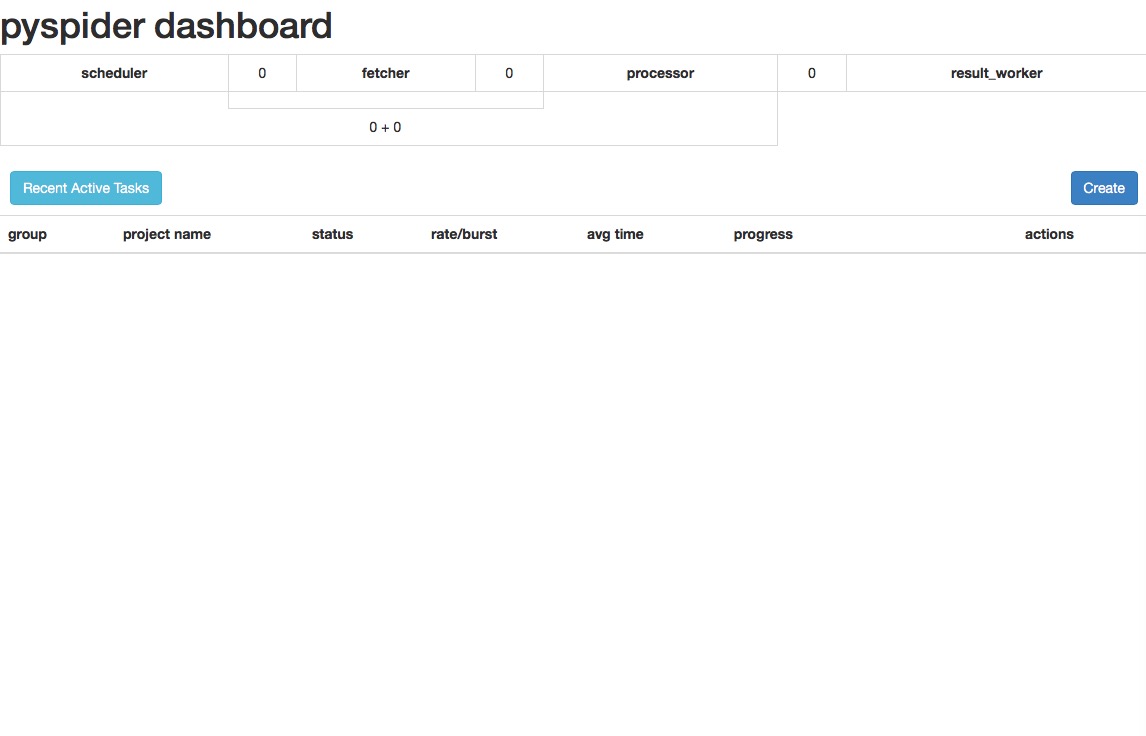
這樣pyspider就算是跑起來了。有的文章會提到需要安裝phantomjs,這個暫時用不上,先忽略。
開始
新建任務
第一次跑起來的時候因為沒有任務,介面的列表為空,右邊有個Create按鈕,點選新建任務。
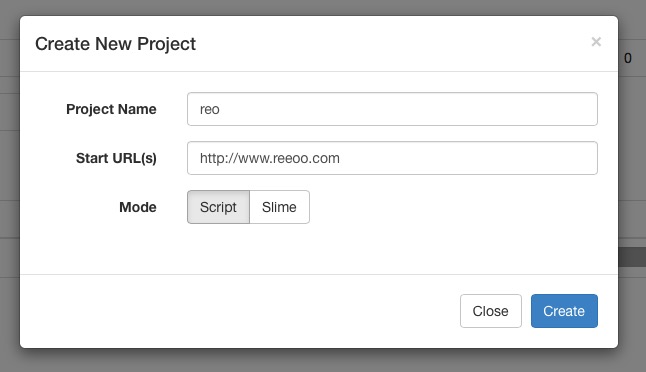
- Project Name:任務的名字,可以任意填
- Start URL(s):爬取任務開始的地址,這裡我們填目標網址的url
填寫完成後,點選Create,便建立成功並跳轉到了另一個介面,如下圖所示
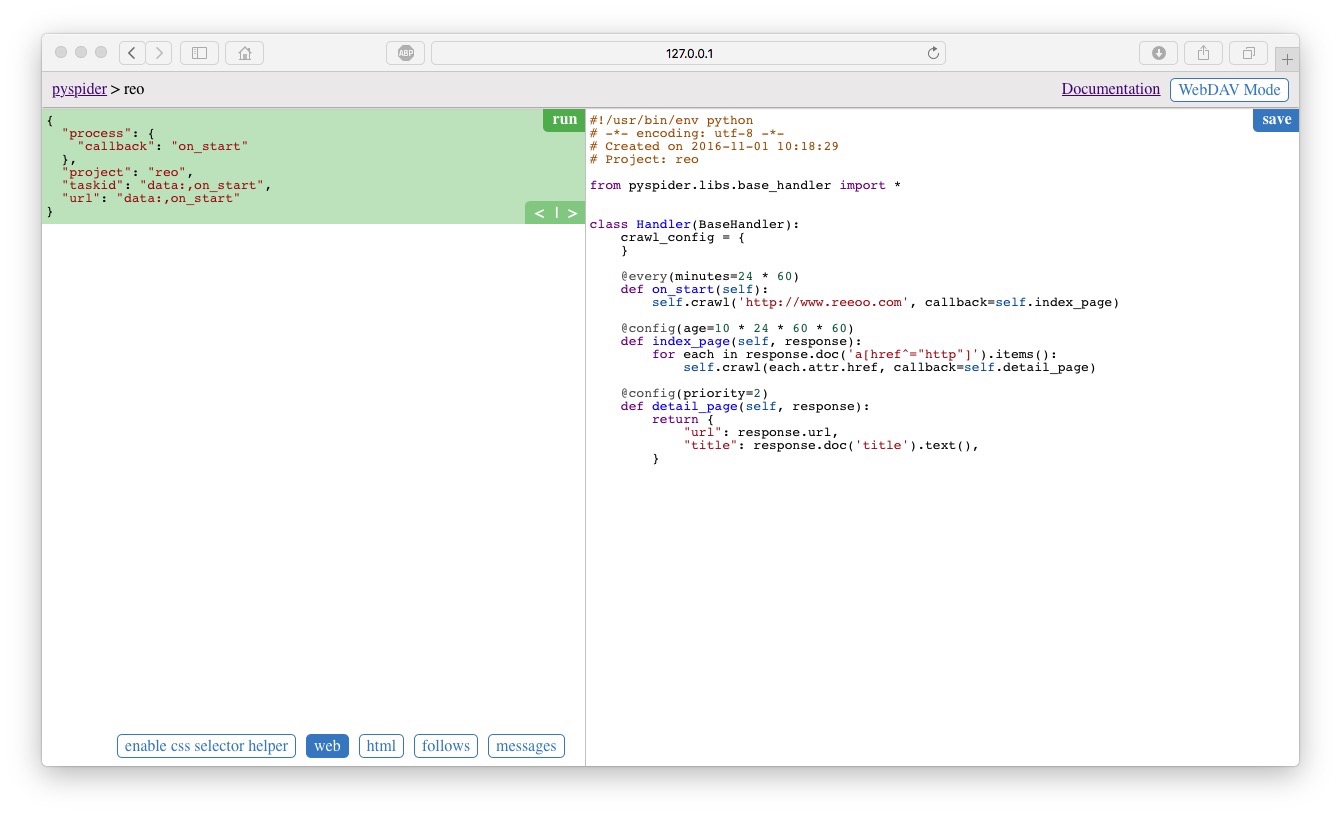
介面右邊區域自動生成了初始預設的程式碼:
#!/usr/bin/env python
# -*- encoding: utf-8 -*-
# Created on 2016-11-02 09:27:35
# Project: reo
from pyspider.libs.base_handler import *
class Handler(BaseHandler):
crawl_config = {
}
@every( -
on_start(self) 程式的入口,當點選左側綠色區域右上角的 run 按鈕時首先會呼叫這個函式
-
self.crawl(url, callback) pyspider庫主要的API,用於建立一個爬取任務,url 為目標地址,這裡為我們剛剛建立任務指定的起始地址,callback 為抓取到資料後的回撥函式
-
index_page(self, response) 引數為 Response 物件,response.doc 為 pyquery 物件(具體使用可見pyquery官方文件),pyquery和jQuery類似,主要用來方便地抓取返回的html文件中對應標籤的資料
-
detail_page(self, response) 返回一個 dict 物件作為結果,結果會自動儲存到預設的 resultdb 中,也可以通過過載方法來講結果資料儲存到指定的資料庫,後面會再提到具體的實現
其他一些引數
-
@every(minutes=24 * 60) 通知 scheduler(框架的模組) 每天執行一次
-
@config(age=10 * 24 * 60 * 60) 設定任務的有效期限,在這個期限內目標爬取的網頁被認為不會進行修改
-
@config(priority=2) 設定任務優先順序
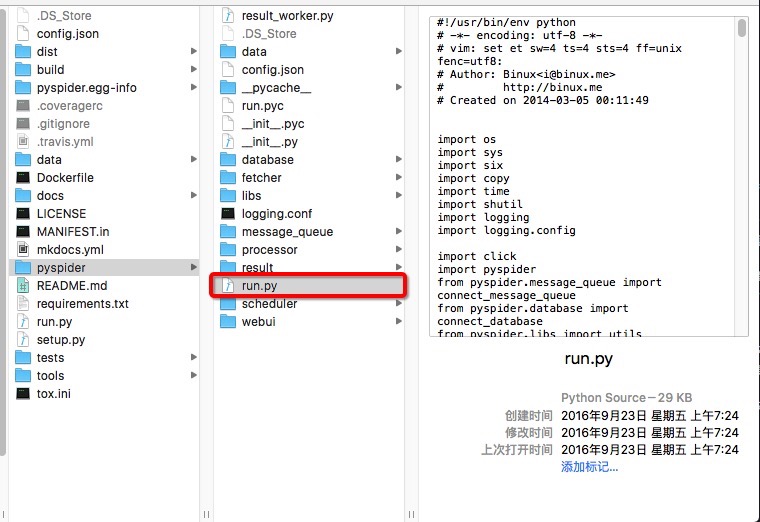
Ps. 需要注意的一個地方,前面跑的 run.py 不是下載的原始碼資料夾中的,而是在 pyspider 資料夾中的 run.py,如下圖,可以看到有兩個 run.py 檔案,雖然兩個都能跑起來,但我們用到的是圈出來的那個,否則不能通過 –config 配置。
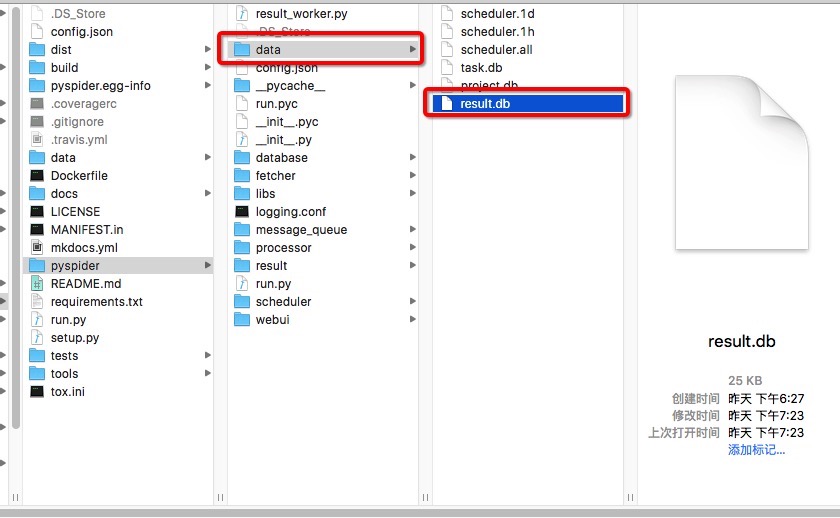
成功跑起來之後可以看到在當前資料夾中生成了一個 data 資料夾,生成的結果預設會儲存到 result.db 中,爬取資料後可開啟看裡面儲存了執行的結果。
執行
點選左邊綠色區域右上角的 run 按鈕,執行之後頁面下冊的 follows 按鈕出現紅色角標
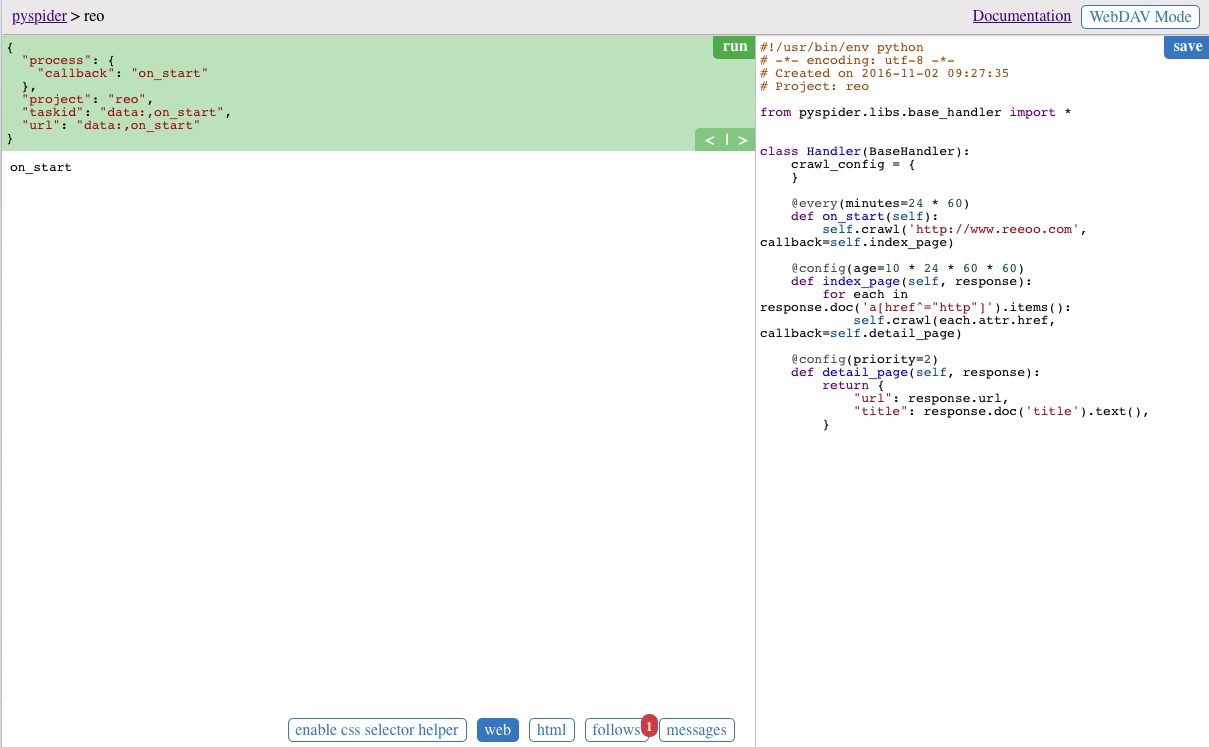
選中 follows 按鈕,看到 index_page 行,點選行右側的執行按鈕
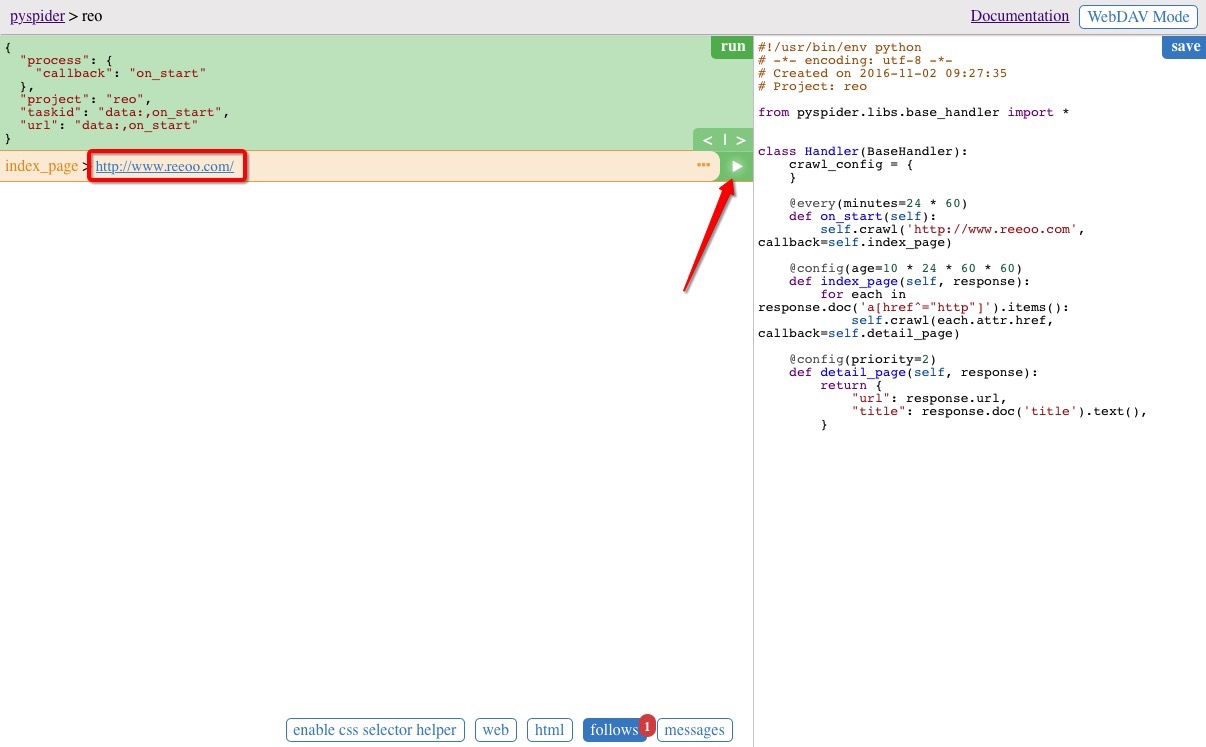
執行完成後顯示如下圖,即 www.reeoo.com 頁面上所有的url
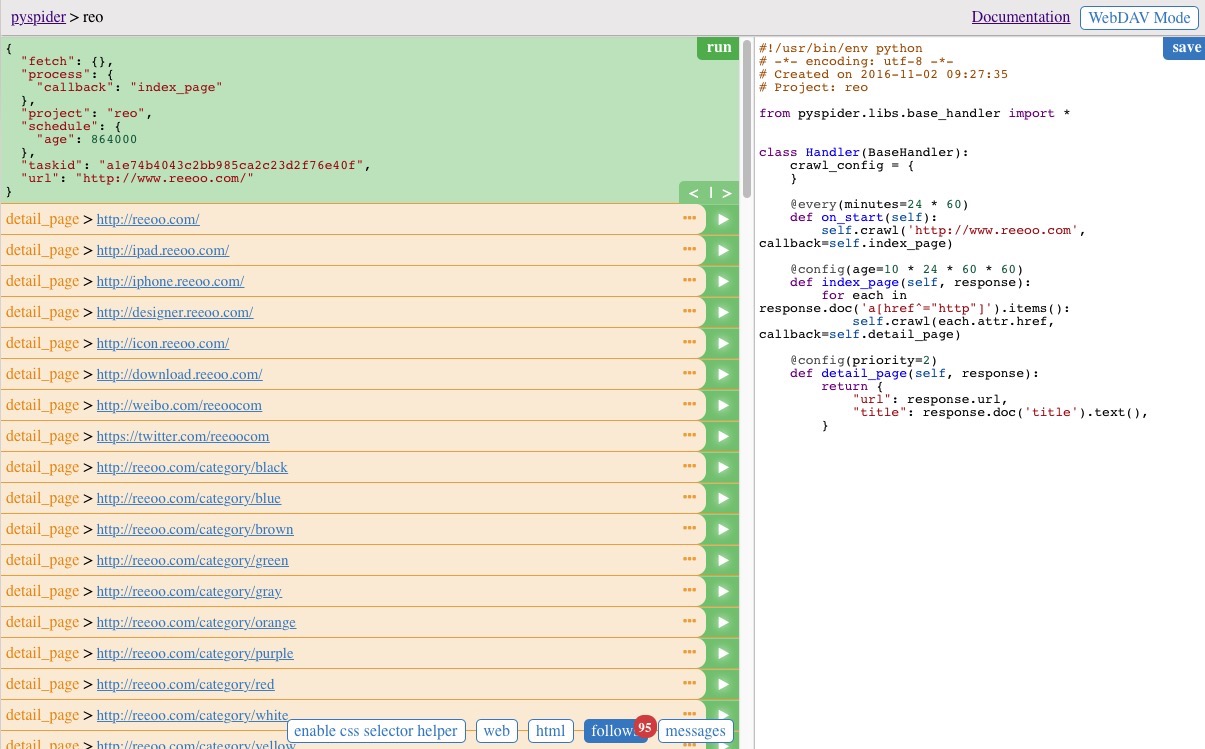
此時我們可以任意選擇一個結果執行,這時候呼叫的是 detail_page 方法,返回最終的結果。
結果為json格式的資料,這裡我們儲存的是網頁的 title 和 url,見左側黑色的區域
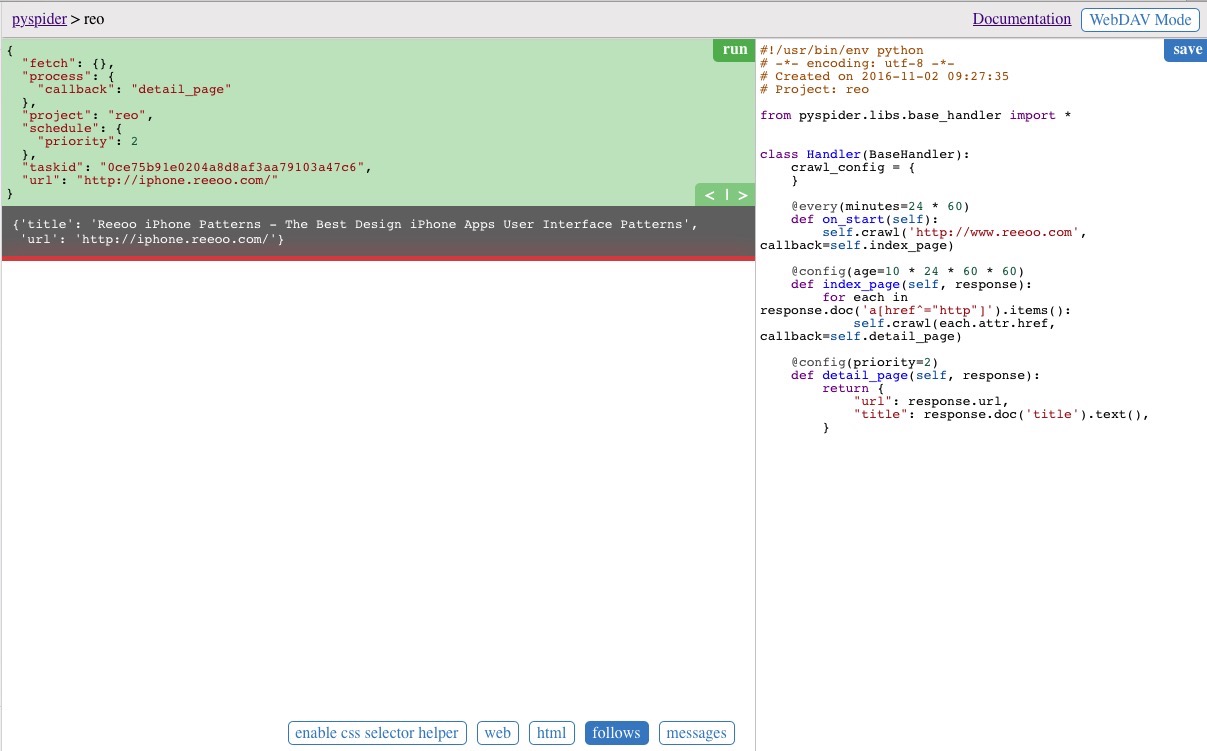
回到主頁面,此時看到任務列表顯示了我們剛剛建立的任務,設定 status 為 running,然後點選 Run 按鈕執行
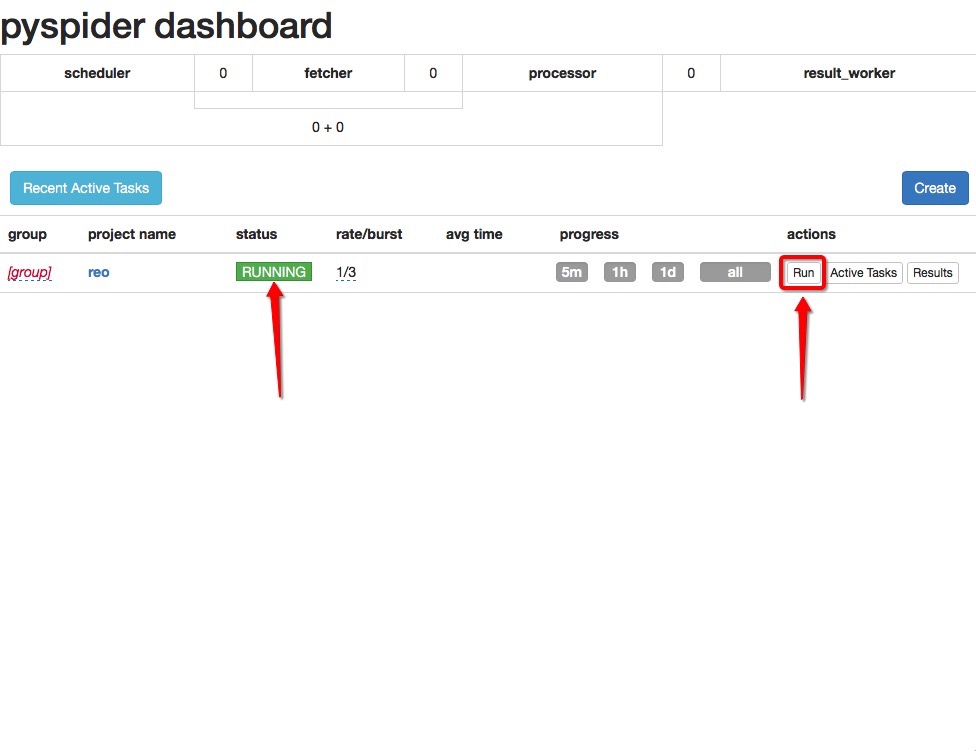
執行過程中可以看到整個過程的列印輸出
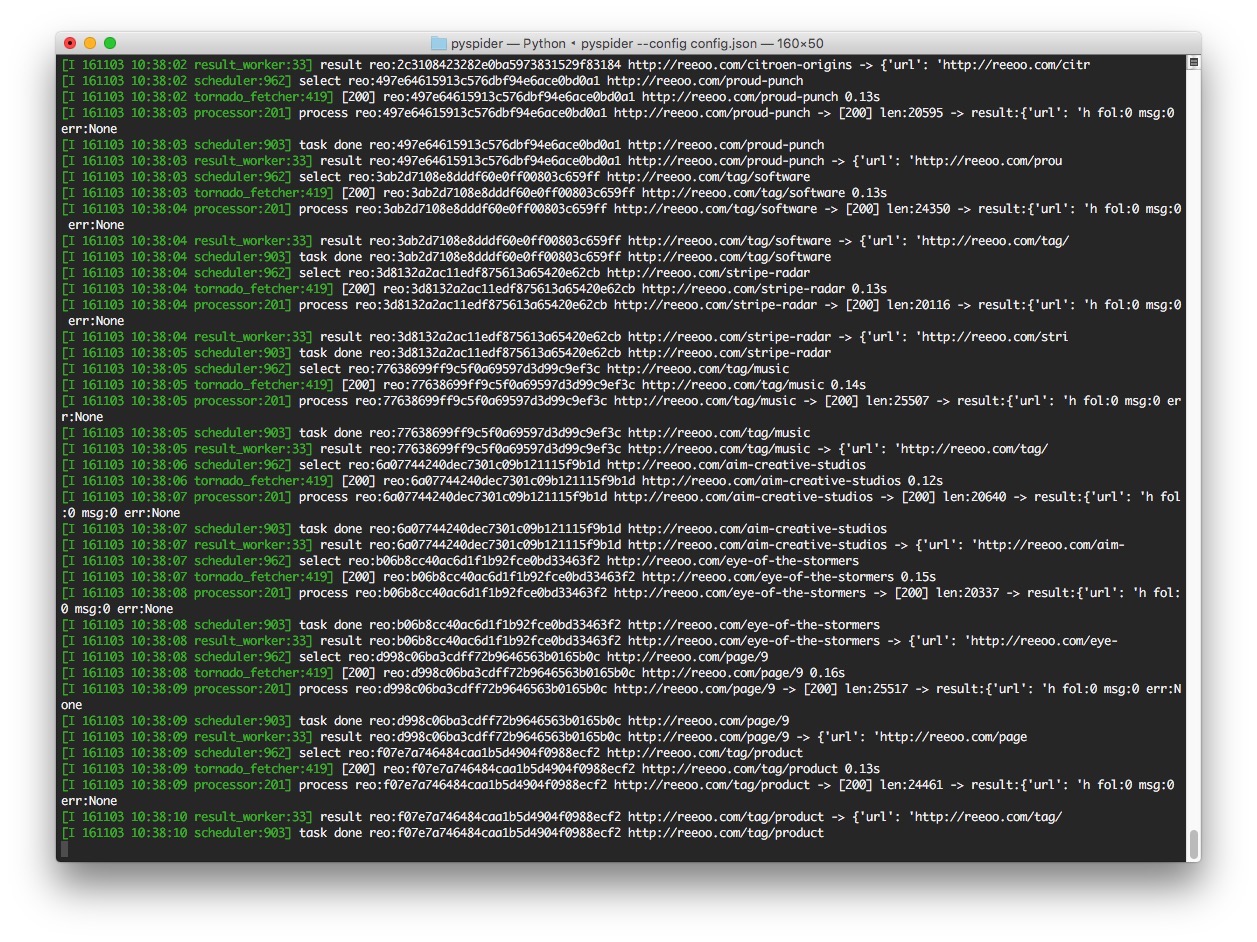
執行完成後,點選 Results 按鈕,進入到爬取結果的頁面
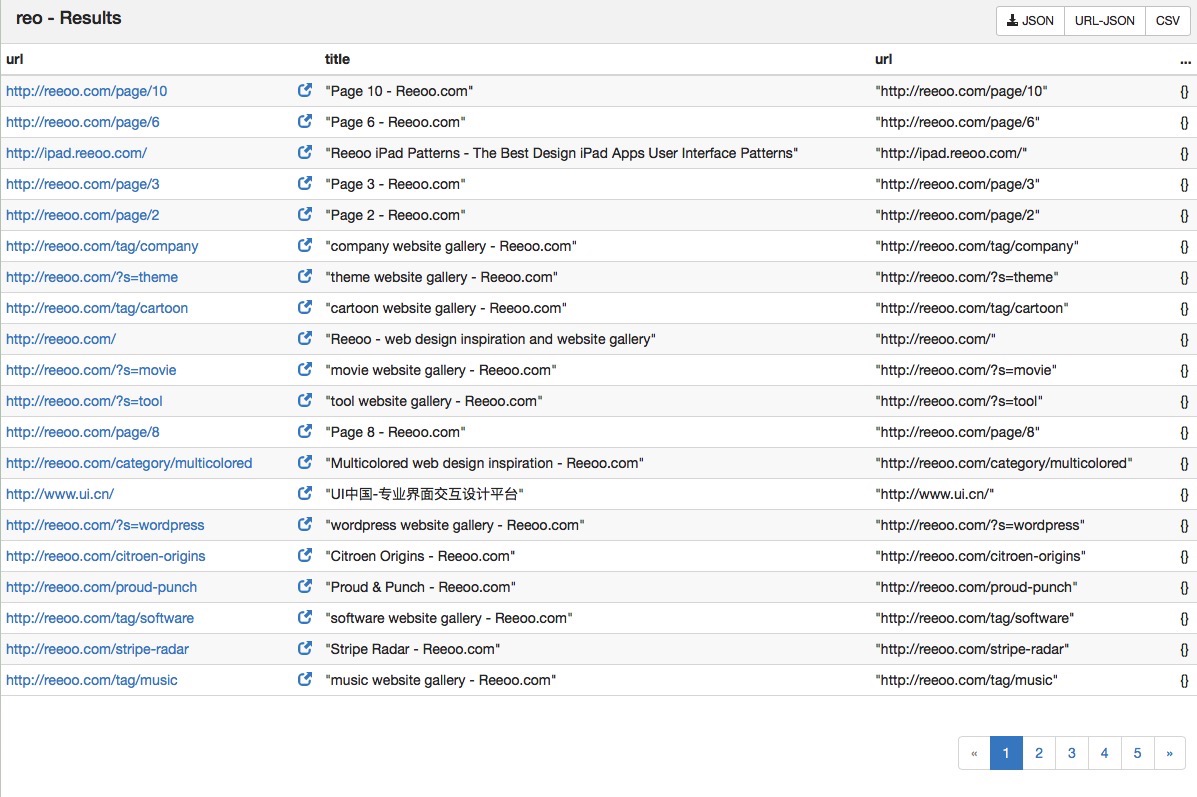
右上方的按鈕選擇將結果資料儲存成對應的格式,例如:JSON格式的資料為:

以上則為pyspider的基本使用方式。
自定義爬取指定資料
接下來我們通過自定義來抓取我們需要的資料,目標為抓取這個頁面中,每個詳情頁內容的標題、標籤、描述、圖片的url、點選圖片所跳轉的url。
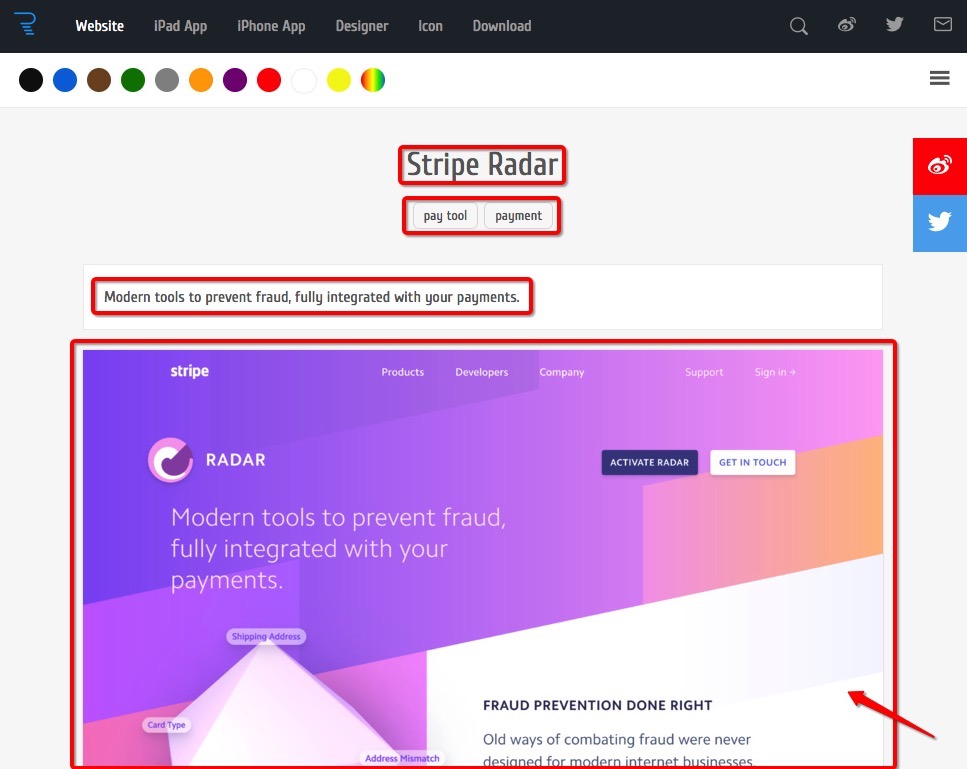
點選首頁中的 project name > reo,跳轉到指令碼的編輯介面
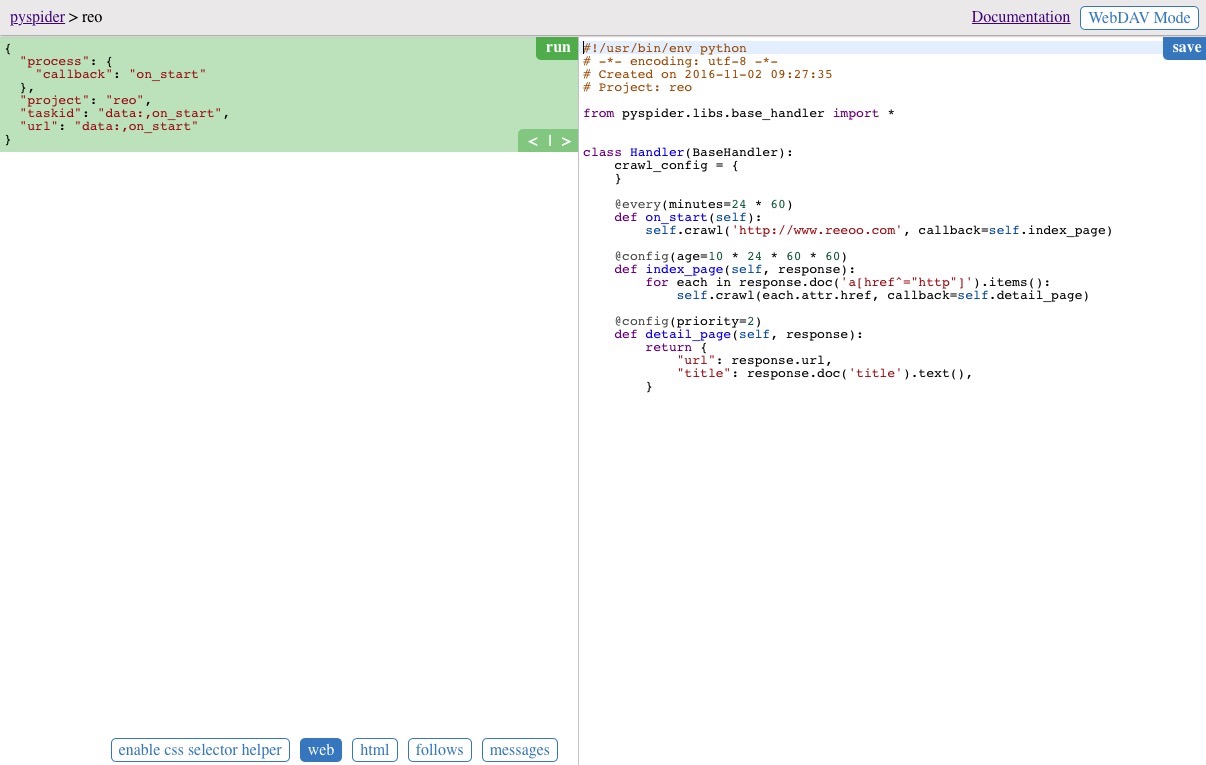
獲取所有詳情頁面的url
index_page(self, response) 函式為獲取到 www.reeoo.com 頁面所有資訊之後的回撥,我們需要在該函式中對 response 進行處理,提取出詳情頁的url。
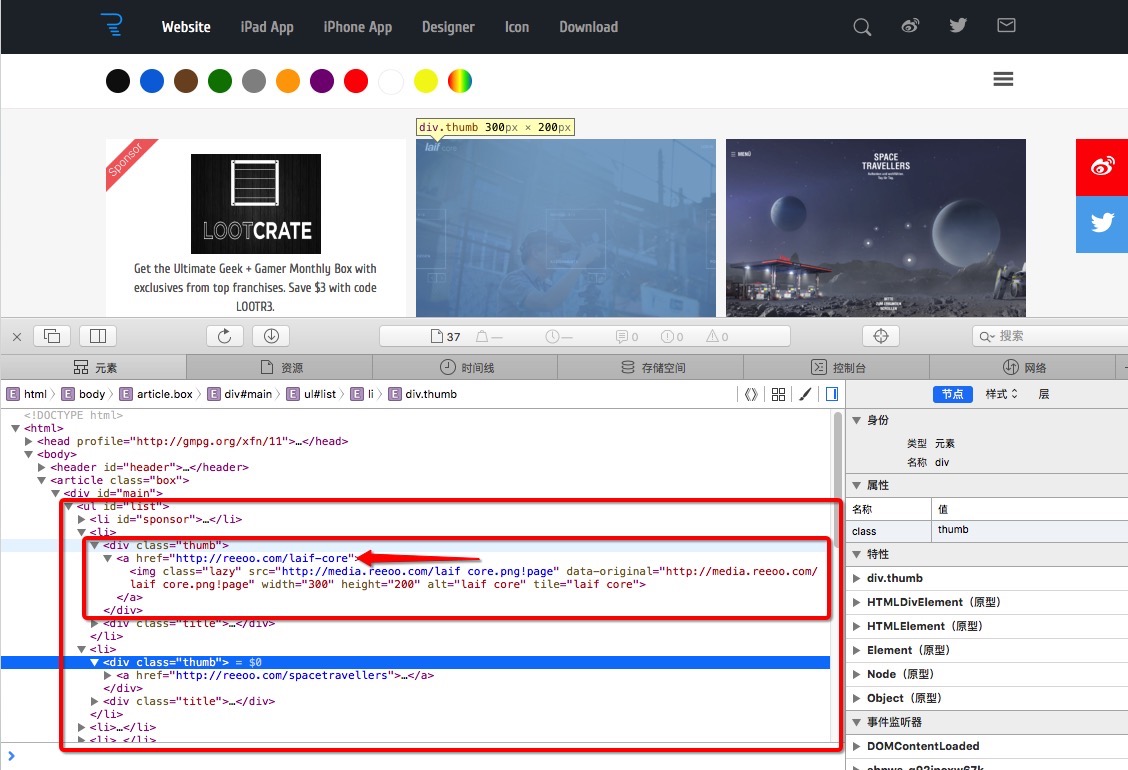
通過檢視原始碼,可以發現 class 為 thum 的 div 標籤裡,所包含的 a 標籤的 href 值即為我們需要提取的資料,如下圖
程式碼的實現
def index_page(self, response):
for each in response.doc('div[class="thumb"]').items():
detail_url = each('a').attr.href
print (detail_url)
self.crawl(detail_url, callback=self.detail_page)
response.doc(‘div[class=”thumb”]’).items() 返回的是所有 class 為 thumb 的 div 標籤,可以通過迴圈 for…in 進行遍歷。
each(‘a’).attr.href 對於每個 div 標籤,獲取它的 a 標籤的 href 屬性。
可以將最終獲取到的url列印,並傳入 crawl 中進行下一步的抓取。
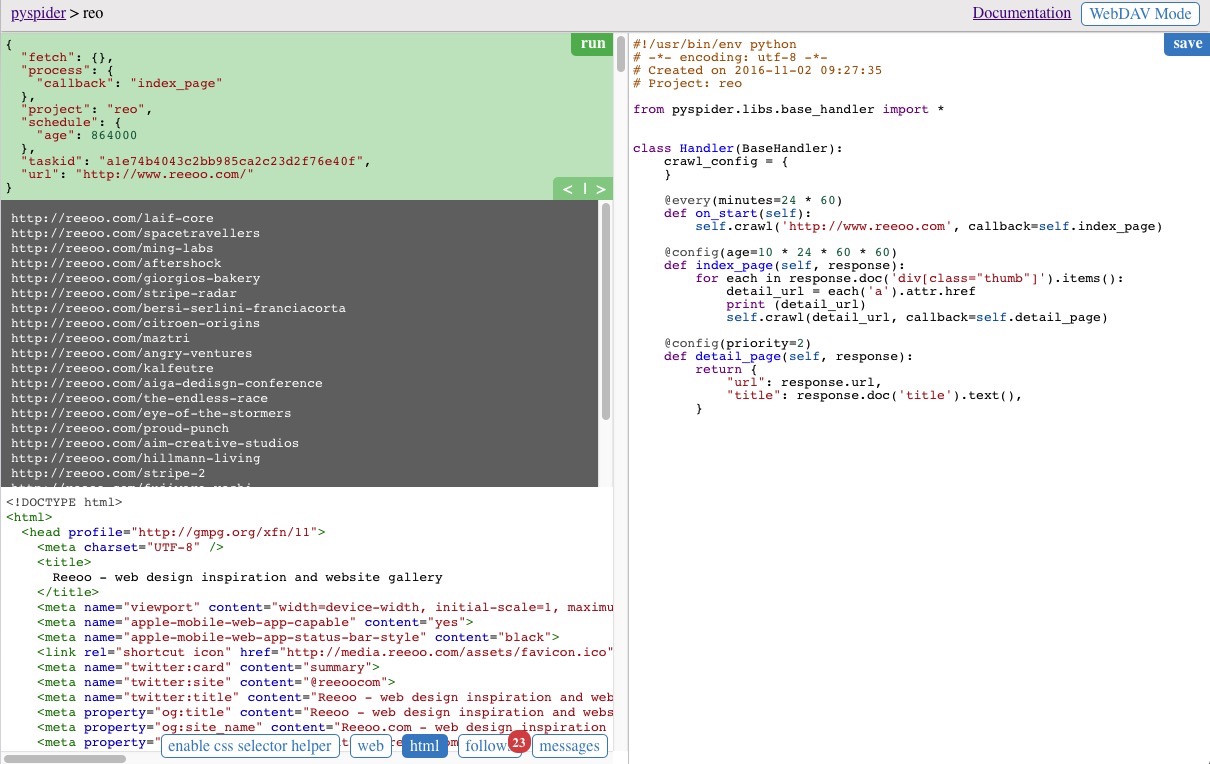
點選程式碼區域右上方的 save 按鈕儲存,並執行起來之後的結果如下圖,中間的灰色區域為列印的結果
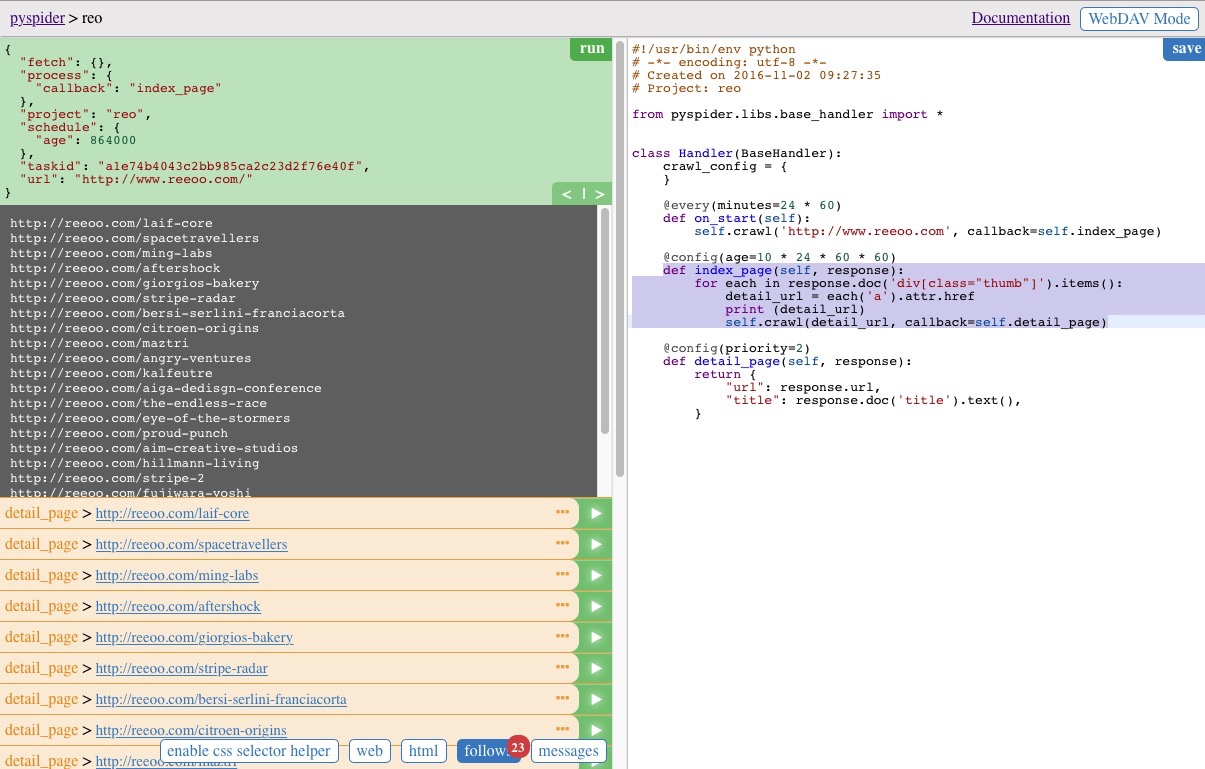
注意左側區域下方的幾個按鈕,可以展示當前所爬取頁面的一些資訊,web 按鈕可以檢視當前頁面,html 顯示當前頁面的原始碼,enable css selector helper 可以通過選中當前頁面的元素自動生成對應的 css 選擇器方便的插入到指令碼程式碼中,不過並不是總有效,在我們的demo中就是無效的~
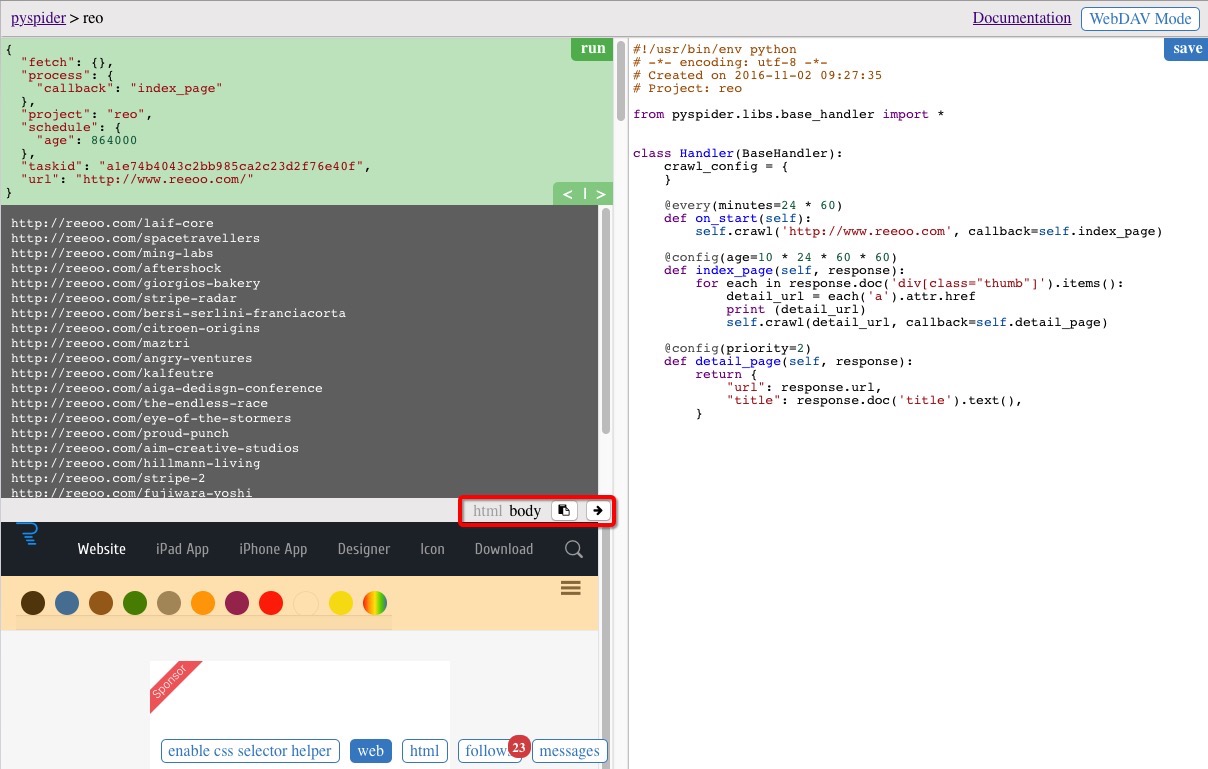
抓取詳情頁中指定的資訊
接下來開始抓取詳情頁中的資訊,任意選擇一條當前的結果,點選執行,如選擇第一個
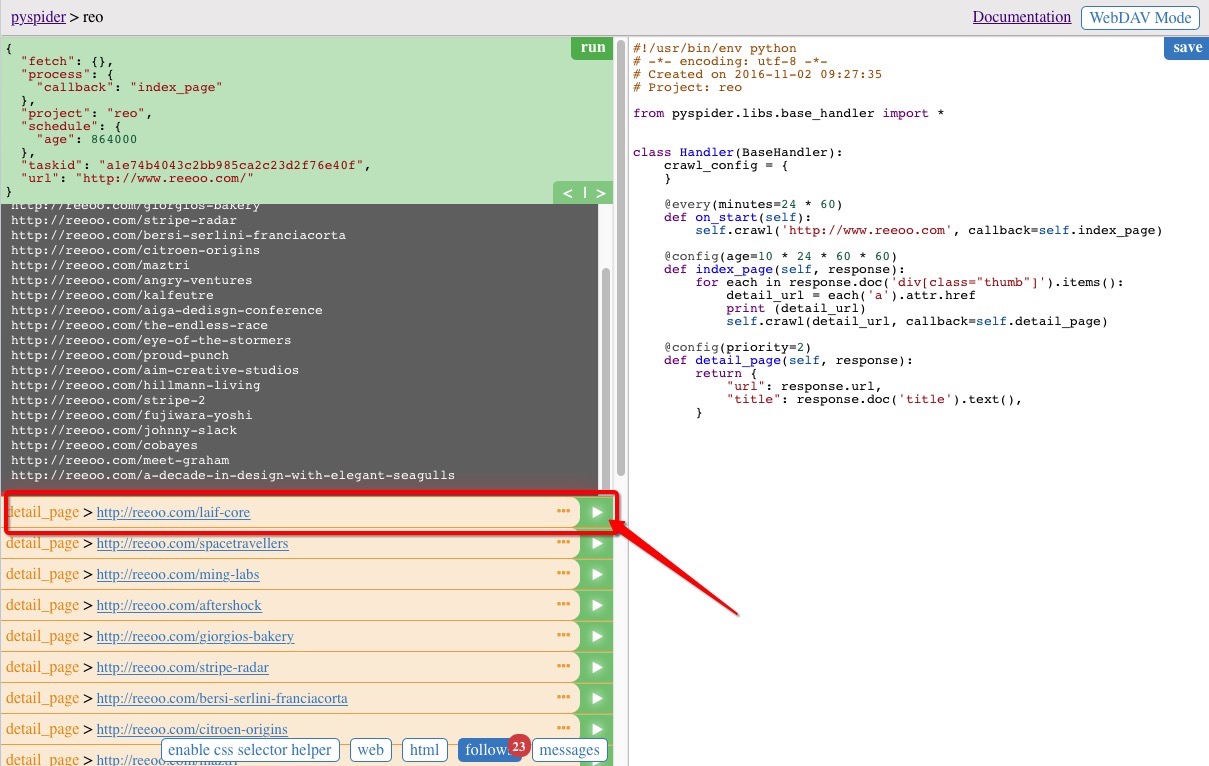
實現 detail_page 函式,具體的程式碼實現:
def detail_page(self, response):
header = response.doc('body > article > section > header')
title = header('h1').text()
tags = []
for each in header.items('a'):
tags.append(each.text())
content = response.doc('div[id="post_content"]')
description = content('blockquote > p').text()
website_url = content('a').attr.href
image_url_list = []
for each in content.items('img[data-src]'):
image_url_list.append(each.attr('data-src'))
return {
"title": title,
"tags": tags,
"description": description,
"image_url_list": image_url_list,
"website_url": website_url,
}
response.doc(‘body > article > section > header’) 引數和CSS的選擇器類似,獲取到 header 標籤, .doc 函式返回的是一個 pyquery 物件。
header(‘h1’).text() 通過引數 h1 獲取到標籤,text() 函式獲取到標籤中的文字內容,通過檢視原始碼可知道,我們所需的標題資料為 h1 的文字。
標籤頁包含在 header 中,a 的文字內容即為標籤,因為標籤有可能不為1,所以通過一個數組去儲存遍歷的結果 header.items(‘a’),具體html的原始碼如下圖:
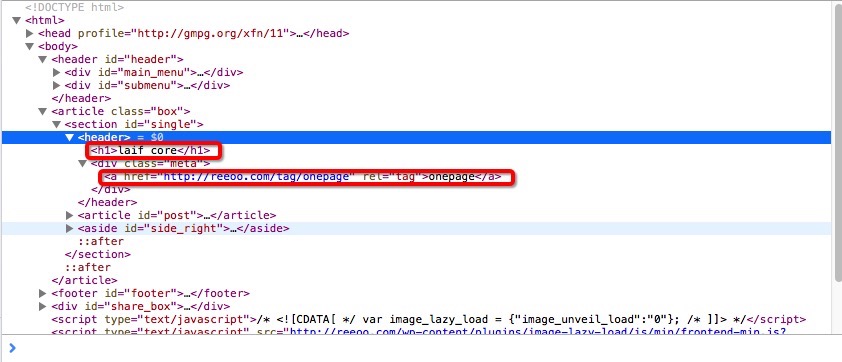
response.doc(‘div[id=”post_content”]’) 獲取 id 值為 post_content 的 div 標籤,並從中取得詳情頁的描述內容,有的頁面這部分內容可能為空。
其餘資料分析抓取的思路基本一致。
最終將需要的資料作為一個 dict 物件返回,即為最終的抓取結果
{"title":title,"tags":tags,"description":description,"image_url_list":image_url_list,"website_url":website_url,}儲存之後直接點選左邊區域的 run 按鈕執行起來,結果如圖,中間灰色區域為分析抓取到的結果。
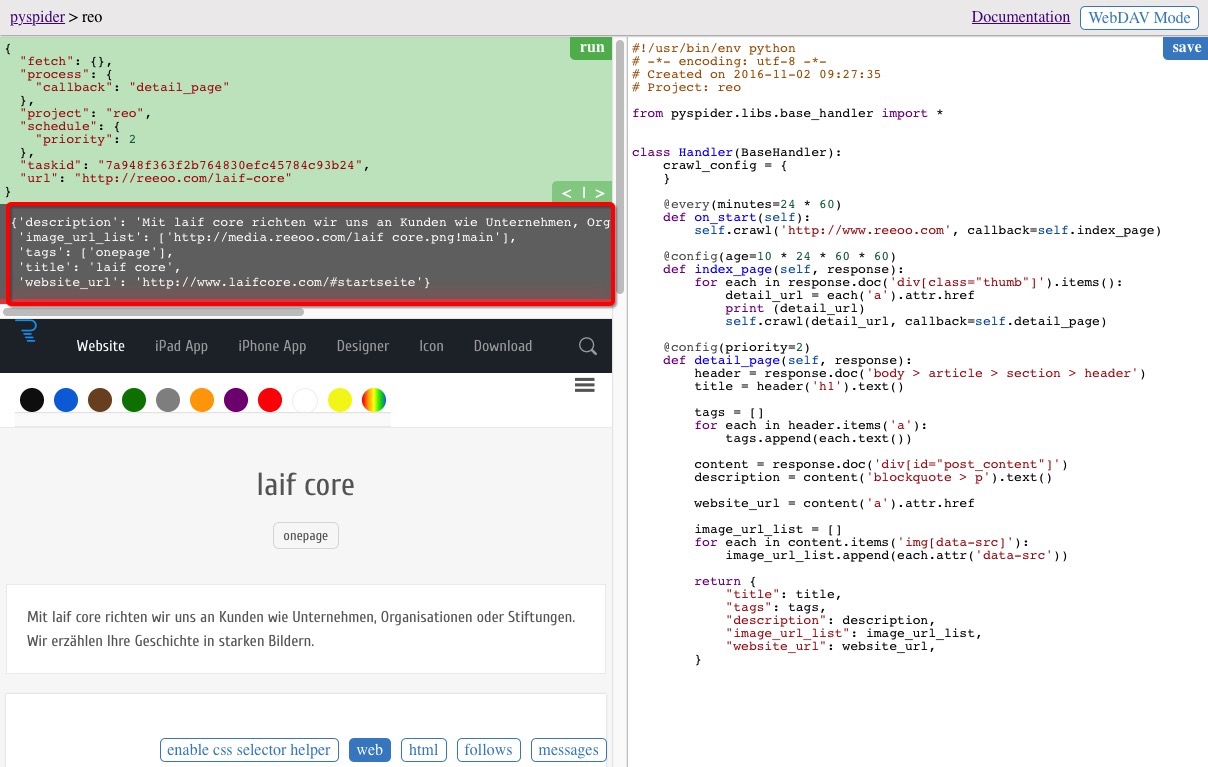
在主頁把任務重新跑起來,檢視執行結果,可以看到我們需要的資料都抓取下來
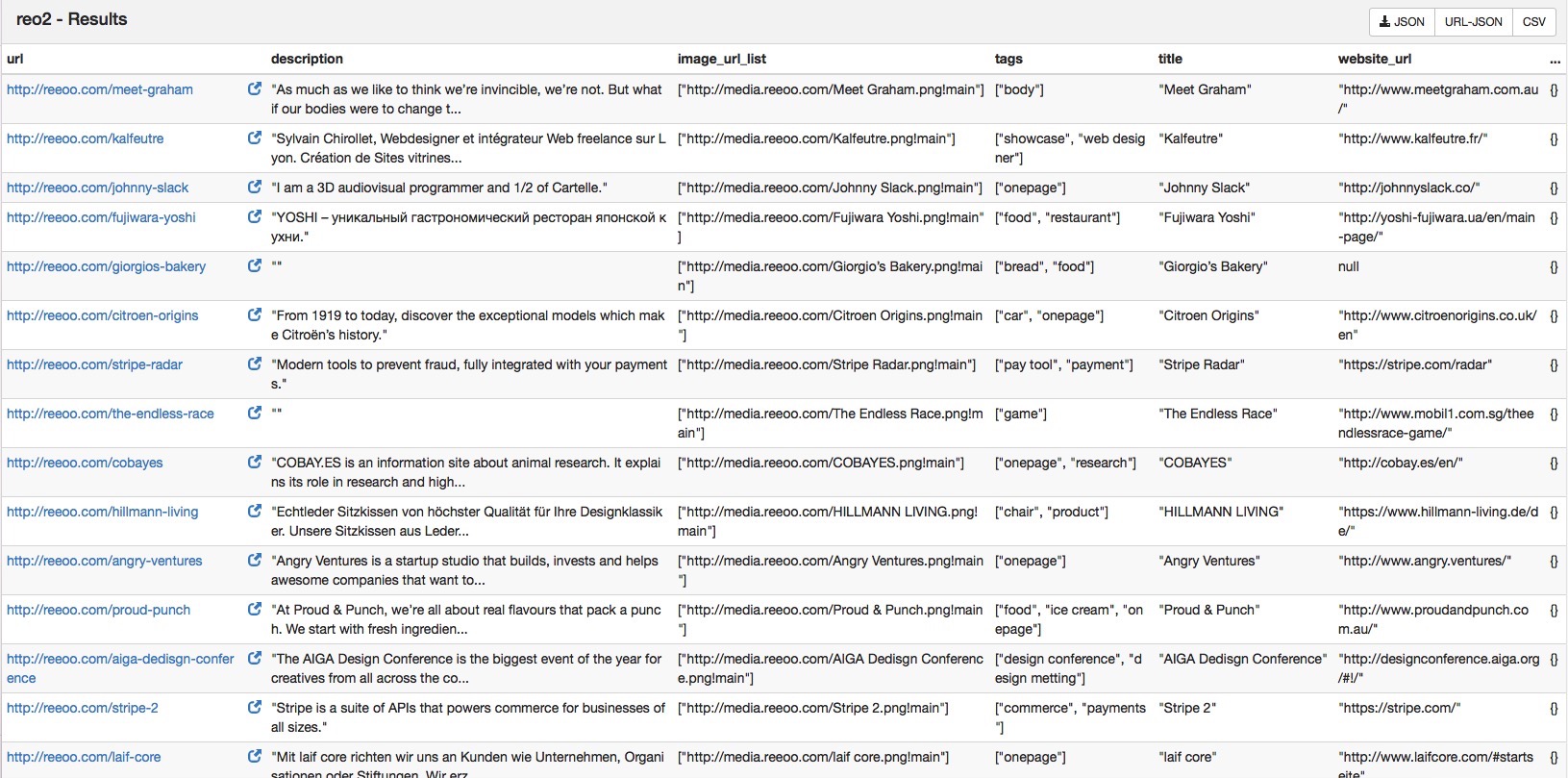
將資料儲存到本地的資料庫
抓取到的資料預設儲存到 resultdb 中,雖然很方便通過瀏覽器進行瀏覽和下載,但卻不太適合進行大規模的資料儲存。
所以最好的處理方式還是將資料儲存在常用的資料庫系統中,本例採用的資料庫為 mongodb。
引數的配置
新建一個檔案,命名為 config.json,放在 pyspider 檔案目錄下,以 JSON 格式儲存配置資訊。檔案到時候作為 pyspider 配置命令的引數。
檔案具體內容如下:
{"taskdb":"mongodb+taskdb://127.0.0.1:27017/pyspider_taskdb","projectdb":"mongodb+projectdb://127.0.0.1:27017/pyspider_projectdb","resultdb":"mongodb+resultdb://127.0.0.1:27017/pyspider_resultdb","message_queue":"redis://127.0.0.1:6379/db","webui":{"port":5001}}指定了資料庫的地址,“webui” 指定網頁的埠,這時候我們可以改成 5001 試試,不再用預設的 5000。
Ps. 在執行之前,你得保證開啟本地的資料庫 mongodb 和 redis,具體怎麼玩自行google,反正這兩個介面跑起來就對了~
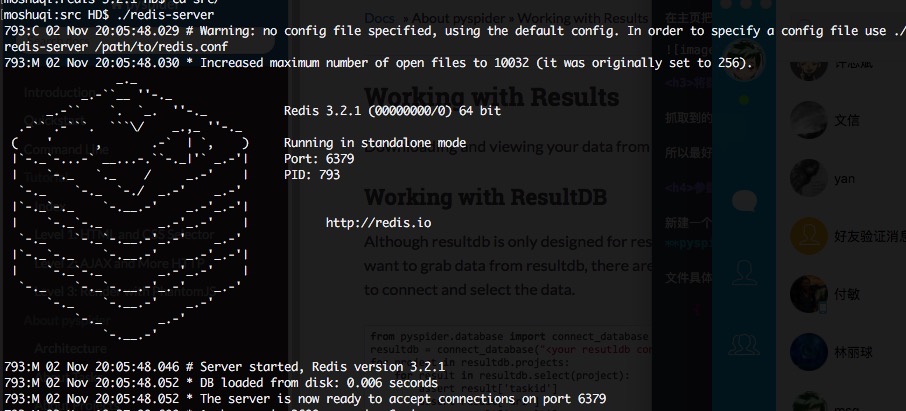
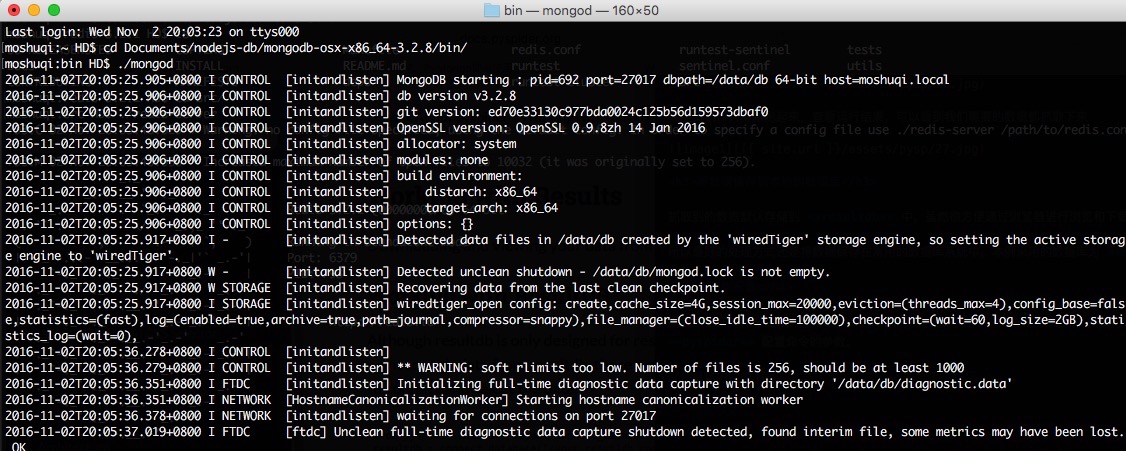
通過設定引數的命令重新執行起來:
pyspider --config config.json
資料庫儲存的實現
通過過載 on_result(self, result): 函式,將結果儲存到 mongodb 中,具體程式碼實現
import pymongo
...
def on_result(self, result):
if not result:
return
client = pymongo.MongoClient(host='127.0.0.1', port=27017)
db = client['pyspyspider_projectdb']
coll = db['website']
data = {
'title': result['title'],
'tags': result['tags'],
'description': result['description'],
'website_url': result['website_url'],
'image_url_list': result['image_url_list']
}
data_id = coll.insert(data)
print (data_id)
on_result(self, result) 在每一步抓取中都會呼叫,但只在 detail_page 函式呼叫後引數中的 result 才會不為 None,所以需要在開始的地方加上判斷。
db = client[‘pyspyspider_projectdb’] 中資料庫的名字 pyspyspider_projectdb 為之前在 config.json 配置檔案中的值。
coll = db[‘website’] 在資料庫中建立了一張名為 website 的表。
data_id = coll.insert(data) 將資料以我們制定的模式儲存到 mongodb 中。
(除了過載on_result方法外,也可以通過過載ResultWorker類來實行結果的處理,需要在配置檔案中加上對應的引數。)
重新新建一個任務,將完整的程式碼拷進去,在主介面完成的跑一遍。
執行過程中可以看到 mongodb 中的列印不斷有資料插入
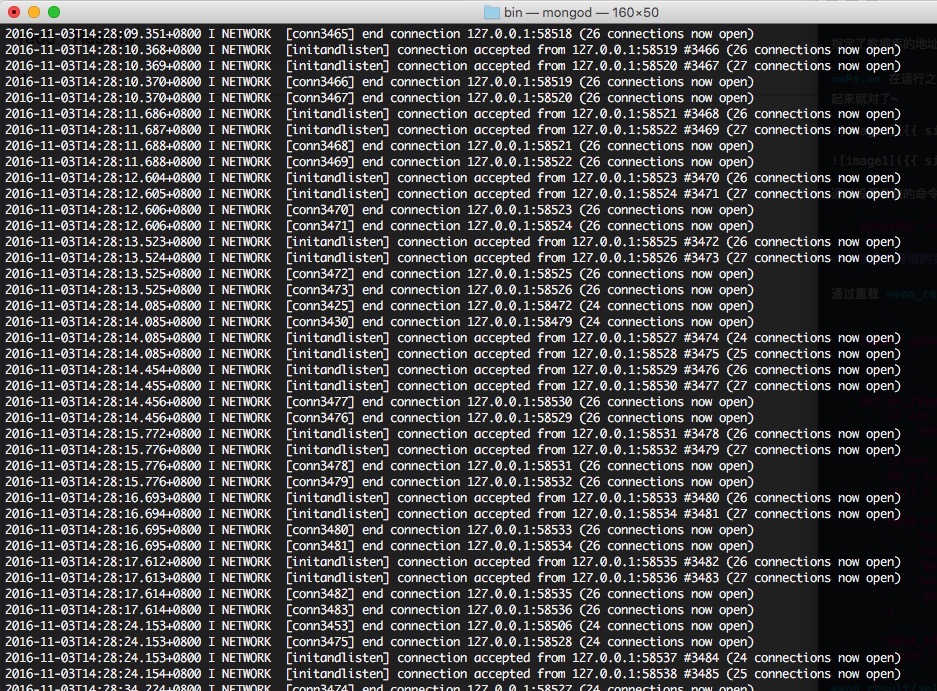
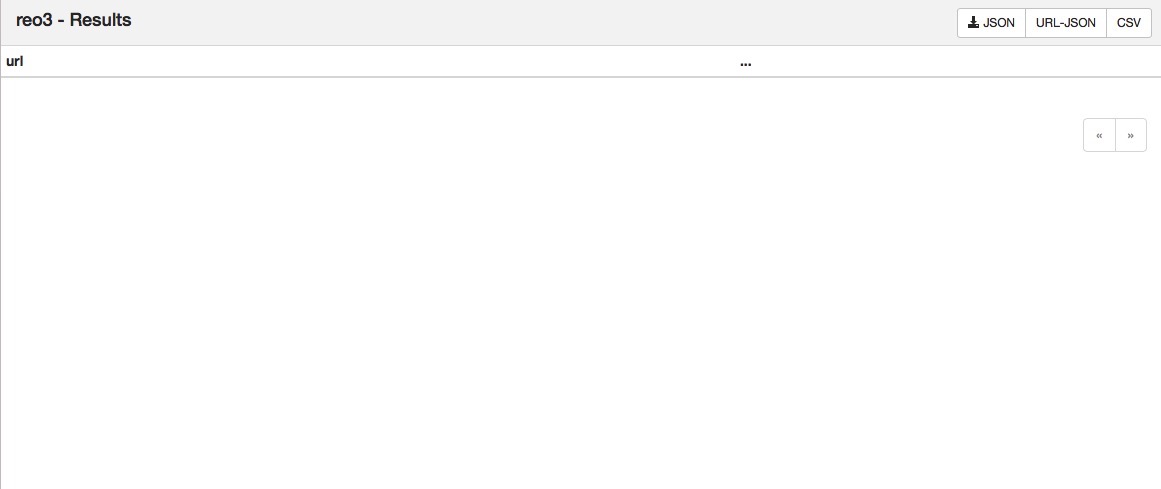
執行完成後,瀏覽器檢視結果,因為設定了資料庫的儲存,不再儲存在預設的 resultdb 中,此時瀏覽器的result介面是沒有資料的
通過命令列進入資料庫查詢資料:
use pyspyspider_projectdb
db.website.find()
可看到儲存到的資料
{"_id":ObjectId("5819e422e8e70103751f0f4c"),"image_url_list":["http://media.reeoo.com/MING Labs.png!main"],"website_url":"https://minglabs.com/en","tags":["design company","onepage","showcase"],"description":"MING Labs is a UX design and development company with offices in Germany, China and Singapore. We craft digital products for all screens and platforms.","title":"MING Labs"}{"_id":ObjectId("581ad797e8e7010fa8ea85c1"),"tags":["onepage"],"title":"SpaceTravellers","website_url":"https://www.totaltankstelle.de/spacetravellers/","image_url_list":["http://media.reeoo.com/SpaceTravellers.png!main"],"description":"Sie haben Treibstoff gesucht und viel mehr gefunden."}{"_id":ObjectId("581ad8ede8e70112e51bd4e1"),"website_url":"http://aftershock.cc/","title":"Aftershock","tags":["onepage"],"description":"Evento de design para aqueles que estão tentando viver (ou quase) de arte. Chega mais! Dia 22-23 de outubro. Botafogo-RJ","image_url_list":["http://media.reeoo.com/Aftershock.png!main"]}{"_id":ObjectId("581ad8ede8e70112e51bd4e3"),"website_url":"http://www.proudandpunch.com.au/","title":"Proud & Punch","tags":["food","ice cream","onepage"],"description":"At Proud & Punch, we’re all about real flavours that pack a punch. We start with fresh ingredients and turn them into tasty treats with a whole lot of flair, right here in Australia. We don’t take shortcuts and have nothing to hide. We’re just proudly real, proudly delicious and proudly here to give you the feel-good treat you’ve been waiting for.","image_url_list":["http://media.reeoo.com/Proud & Punch.png!main"]}{"_id":ObjectId("581ad8ede8e70112e51bd4e5"),"website_url":"http://www.mobil1.com.sg/theendlessrace-game/","title":"The Endless Race","tags":["game"],"description":"","image_url_list":["http://media.reeoo.com/The Endless Race.png!main"]}{"_id":ObjectId("581ad8eee8e70112e51bd4e7"),"website_url":"http://www.maztri.com/en/","title":"Maztri","tags":["design agency","showcase"],"description":"Maztri est une agence d’architecture intérieure et de design qui travaille sur la sensorialité des espaces et des objets qui nous entourent.","image_url_list":["http://media.reeoo.com/Maztri.png!main"]}...至此,我們便已將所抓取到的結果儲存到了本地。
其他
本文所舉例子只是最基本的使用方式,更復雜的,如通過引數的配置,讓爬蟲長期執行與伺服器定期對資料進行更新,對根網頁進行更深層次的處理,通過叢集的方式來執行爬蟲等。感興趣的可自行去研究了。
另,這個框架是國人寫的,附上官方文件的地址
相關推薦
pyspider爬取TripAdvisor
attr ems com () comment save format blog tex 1 #!/usr/bin/env python 2 # -*- encoding: utf-8 -*- 3 # Created on 2017-06-11 10:10:53
Python pyspider 安裝與開發
lib img 數據庫 localhost 垂直 god 服務器 eve rman PySpider 簡介 PySpider是一個國人編寫的強大的網絡爬蟲系統並帶有強大的WebUI。采用Python語言編寫,分布式架構,支持多種數據庫後端,強大的WebUI支持腳本編輯器、任
利用 pyspider 框架抓取貓途鷹酒店信息
tasks 啟動 font oca star 一鍵 resp att blank 利用框架 pyspider 能實現快速抓取網頁信息,而且代碼簡潔,抓取速度也不錯。 環境:macOS;Python 版本:Python3。 1.首先,安裝 pyspider 框架,
centos7 pyspider環境安裝
pyspider PySpider 是一個我個人認為非常方便並且功能強大的爬蟲框架,支持多線程爬取、JS動態解析,提供了可操作界面、出錯重試、定時爬取等等的功能,使用非常人性化。網上的參考文檔:http://www.jianshu.com/p/8eb248697475 http://cuiqingcai.c
pyspider中內容選擇器常用方法匯總
實例 .text span 部分 ons test tag .cn 給定 pyspider 的內容選擇器默認已經實例化一個pyquery對象,可以直接使用pyquery的api來獲取自己需要的內容。 1.在pyquery中使用response.doc就可以直接實例化一個py
Python3爬蟲(十六) pyspider框架
暫停 update trie 字典 管理 生成 qlite tps 方便 Infi-chu: http://www.cnblogs.com/Infi-chu/ 一、pyspider介紹1.基本功能 提供WebUI可視化功能,方便編寫和調試爬蟲 提供爬取進度監控、爬取結果查看
pyspider爬蟲框架的安裝和使用
latest with ide inux 本地 處理器 pytho 瀏覽器 uil pyspider是國人binux編寫的強大的網絡爬蟲框架,它帶有強大的WebUI、腳本編輯器、任務監控器、項目管理器以及結果處理器,同時支持多種數據庫後端、多種消息隊列,另外還支持JavaS
熟悉pyspider的裝飾器
代碼 有效 boa 開發者 board splay 參數 一次 單步調試 熟悉pyspider的裝飾器取經地點:https://segmentfault.com/a/1190000002477863 @config(age=10 * 24 * 60 * 60) 在這
pyspider基本使用和專案刪除
PySpider:一個國人編寫的強大的網路爬蟲系統並帶有強大的WebUI。採用Python語言編寫,分散式架構,支援多種資料庫後端,強大的WebUI支援指令碼編輯器,任務監視器,專案管理器以及結果檢視器。 一: 在cmd中使用pysider all啟動pyspider及其組 &nb
pyspider報錯: HTTP 599: SSL certificate problem: self signed certificate in certificate chain解決方案
出現上述問題,可以在抓取函式的crawl 方法中加入忽略證書驗證,validate_cert=False 即:self.crawl('__START_URL__', callback=self.index_page, validate_cert=False) validate_cert
windows10,安裝pyspider,python3.7 成功,但是不能啟動pyspider的解決辦法
最後一句出現 File "c:\users\13733\appdata\local\programs\python\python37\lib\site-packages\pyspider\run.py", line 231 async=True, get_object=False, no
pyspider使用
#!/usr/bin/env python # -*- encoding: utf-8 -*- # Created on 2018-11-08 22:33:55 # Project: qsbk from pyspider.libs.base_handler import * from lxml imp
關於 pyspider Web預覽界面太小的解決方法
運行 oat 一個 deb undo charm ext inline fixed 本人最近在學習pyspider時,遇到Web預覽界面太小而無法很好的進行開發,於是在網上搜索解決方法。 準備: css代碼: body{margin:0;padding:0;heigh
關於 pyspider Web預覽介面太小的解決方法
本人最近在學習pyspider時,遇到Web預覽介面太小而無法很好的進行開發,於是在網上搜索解決方法。 準備: css程式碼: body{margin:0;padding:0;height:100%;overflow:hidden}.warning{color:#f0ad4e}.e
pyspider安裝配置
關於 首先,在此附上專案的地址,以及官方文件 PySpider 官方文件 安裝 1. pip 首先確保你已經安裝了pip,若沒有安裝,請參照 pip安裝 2. phantomjs PhantomJS 是一個基於 WebKit 的伺服器端 J
Pyspider爬蟲簡單框架
pyspide 目錄 pyspider簡單介紹 pyspider的使用 實戰 pyspider簡單介紹 一個國人編寫的強大的網路爬蟲系統並帶有強大的WebUI。採用Python語言編寫,分散式架構,支援多種資料庫後端, 強大的WebUI支援
Linux 安裝pyspider 報錯“No such file or directory: 'curl-config”
During handling of the above exception, another exception occurred: Traceback (most recent call last)
Linux 下安裝pyspider deepin 或者Ubuntu(親測)
phantomjs PhantomJS 是一個基於 WebKit 的伺服器端 JavaScript API。它全面支援web而不需瀏覽器支援,其快速、原生支援各種Web標準:DOM 處理、CSS 選擇器、JSON、Canvas 和 SVG。 PhantomJS 可以用於頁面自動化、網路監測、
pyspider框架的使用
介紹 用Python編寫指令碼 功能強大的WebUI,包括指令碼編輯器,任務監視器,專案管理器和結果檢視器 MySQL,MongoDB,Redis,SQLite,Elasticsearch ; PostgreSQL使用SQLAlchemy作為資料庫後端
使用pyspider框架抓取貓途鷹旅遊資訊
這裡通過pyspider框架 可以直接:pip3 install pyspider 下載框架 pyspider all 執行 可以看到 run 0.0.0.0:5000 直接在瀏覽器輸入localhost:5000 進入 建立新專案 #!/usr/bin/env pyth