
資料探勘之資料處理——SVM神經網路的資料分類預測-義大利葡萄酒種類識別
*************
使用的工具:Matlab
分類器:SVM
*************
1、案例背景:
在葡萄酒製造業中,對於葡萄酒的分類具有很大意義,因為這涉及到不同種類的葡萄酒的存放以及出售價格,採用SVM做為分類器可以有效預測相關葡萄酒的種類,從UCI資料庫中得到wine資料記錄的是在義大利某一地區同一區域上三種不同品種的葡萄酒的化學成分分析,資料裡含有178個樣本分別屬於三個類別(類別標籤已給),每個樣本含有13個特徵分量(化學成分),將這178個樣本50%做為訓練樣本,另50%做為測試樣本,用訓練樣本對SVM分類器進行訓練,用得到的模型對測試樣本的進行分類標籤預測,最終得到96.6292%的分類準確率.
.....
2、模型的建立:

這只是一個簡單的模型建立,其實我就覺得 叫“過程”更加的貼切
3、資料匯入:
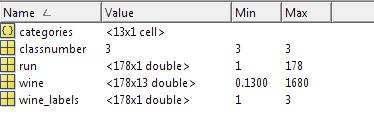
load chapter12_wine.mat;載入測試資料wine,
其中包含的資料為 classnumber = 3, wine:178*13的矩陣, 型別標籤wine_labes:178*1的列向量
如圖:
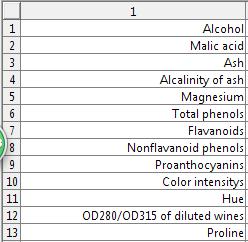
其中13個屬性值分別為:酒精Alcohol、蘋果酸Malic
acid、灰分的鹼度Alcalinity of ash、鎂(元素)Magnesium、總酚含量Total phenols、黃酮類化合物flavanoids、酚Nonflavanoid phenols、原花青素proanthocyanins、色澤度color intensitys、色調hue、淡酒OD280/OD315 of diluted wines、脯氨酸proline
可以看到13個屬性值在178樣本中的分佈情況:
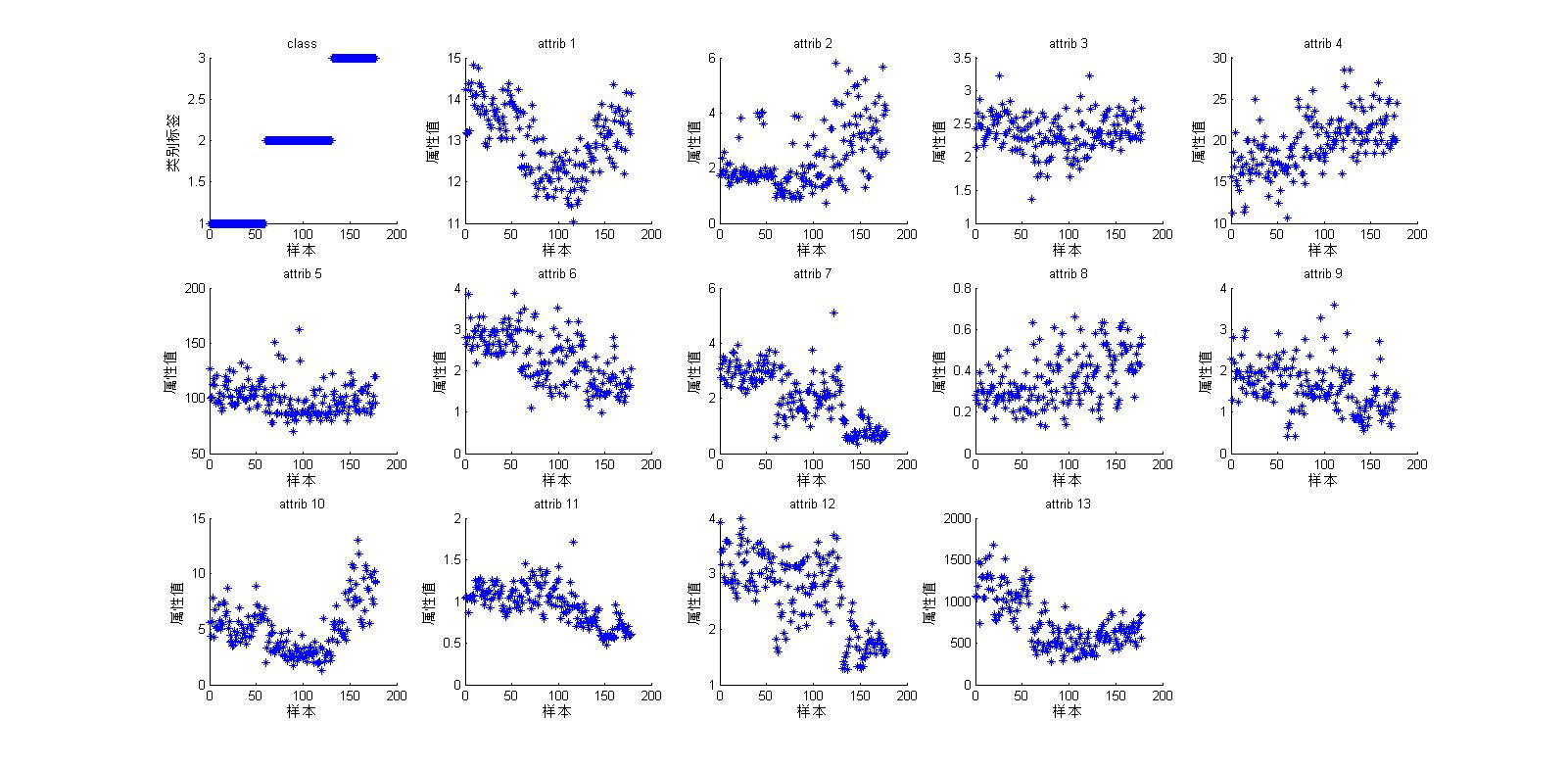
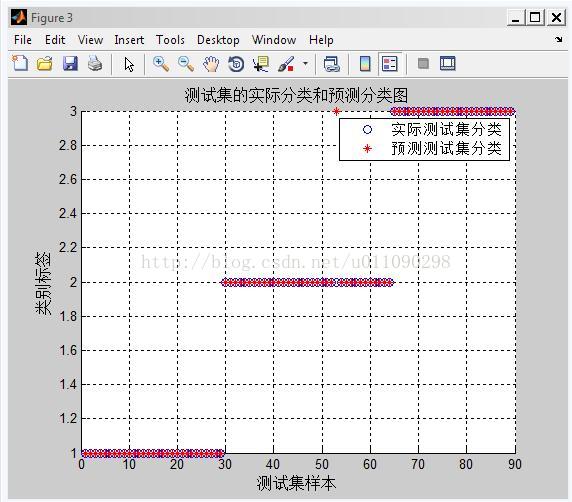
4、處理結果:
看出來,紅色的預測和藍色實際分類還是很吻合的,分類正確率還是很高的
5、附錄:Matlab程式碼
% SVM神經網路的資料分類預測----義大利葡萄酒種類識別 %% 清空環境變數 close all; clear; clc; format compact; %% 資料提取 % 載入測試資料wine,其中包含的資料為classnumber = 3,wine:178*13的矩陣,wine_labes:178*1的列向量 load chapter12_wine.mat; % 畫出測試資料的box視覺化圖 figure; boxplot(wine,'orientation','horizontal','labels',categories); title('wine資料的box視覺化圖','FontSize',12); xlabel('屬性值','FontSize',12); grid on; % 畫出測試資料的分維視覺化圖 figure subplot(3,5,1); hold on for run = 1:178 plot(run,wine_labels(run),'*'); end xlabel('樣本','FontSize',10); ylabel('類別標籤','FontSize',10); title('class','FontSize',10); for run = 2:14 subplot(3,5,run); hold on; str = ['attrib ',num2str(run-1)]; for i = 1:178 plot(i,wine(i,run-1),'*'); end xlabel('樣本','FontSize',10); ylabel('屬性值','FontSize',10); title(str,'FontSize',10); end % 選定訓練集和測試集 % 將第一類的1-30,第二類的60-95,第三類的131-153做為訓練集 train_wine = [wine(1:30,:);wine(60:95,:);wine(131:153,:)]; % 相應的訓練集的標籤也要分離出來 train_wine_labels = [wine_labels(1:30);wine_labels(60:95);wine_labels(131:153)]; % 將第一類的31-59,第二類的96-130,第三類的154-178做為測試集 test_wine = [wine(31:59,:);wine(96:130,:);wine(154:178,:)]; % 相應的測試集的標籤也要分離出來 test_wine_labels = [wine_labels(31:59);wine_labels(96:130);wine_labels(154:178)]; %% 資料預處理 % 資料預處理,將訓練集和測試集歸一化到[0,1]區間 [mtrain,ntrain] = size(train_wine); [mtest,ntest] = size(test_wine); dataset = [train_wine;test_wine]; % mapminmax為MATLAB自帶的歸一化函式 [dataset_scale,ps] = mapminmax(dataset',0,1); dataset_scale = dataset_scale'; train_wine = dataset_scale(1:mtrain,:); test_wine = dataset_scale( (mtrain+1):(mtrain+mtest),: ); %% SVM網路訓練 model = svmtrain(train_wine_labels, train_wine, '-c 2 -g 1'); %% SVM網路預測 [predict_label, accuracy] = svmpredict(test_wine_labels, test_wine, model); %% 結果分析 % 測試集的實際分類和預測分類圖 % 通過圖可以看出只有一個測試樣本是被錯分的 figure; hold on; plot(test_wine_labels,'o'); plot(predict_label,'r*'); xlabel('測試集樣本','FontSize',12); ylabel('類別標籤','FontSize',12); legend('實際測試集分類','預測測試集分類'); title('測試集的實際分類和預測分類圖','FontSize',12); grid on;</span>