
MapReduce框架在Yarn上的詳解
MapReduce任務解析
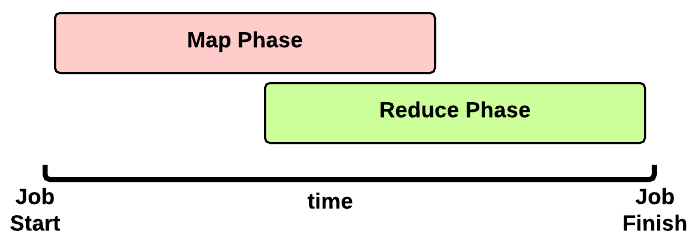
在YARN上一個MapReduce任務叫做一個Job。一個Job的主程式在MapReduce框架上實現的應用名稱叫MRAppMaster.
MapReduce任務的Timeline
這是一個MapReduce作業執行時間:
- Map 階段:根據資料塊會執行多個Map Task
- Reduce 階段:根據配置項會執行多個Reduce Task
為提高Shuffle效率Reduce階段會在Map階段結束之前就開始。(直到所有MapTask完成之後ReduceTask才能完成,因為每個ReduceTask依賴所有的MapTask的結果)
Map階段
首先看看Map階段,一個
使用者會提交什麼?
當一個客戶端提交的應用時會提供以下多種型別的資訊到YARN上。
- 一個configuration(配置項):Hadoop有預設的配置項,所以即使什麼都不寫它也有預設的配置項載入。優先順序高到低順序是使用者指定的配置項>etc/conf下的XML>預設配置項
- 一個JAR包
- 一個map()實現(Map抽象類的實現)
- 一個combiner 實現(combiner抽象類的實現,預設是跟Reduce實現一樣)
- 一個reduce()實現(Reduce抽象類的實現)
- 輸出輸入資訊:
- 輸入目錄:輸入目錄的指定,如輸入HDFS上的目錄、S3或是多少個檔案。
- 輸出目錄:輸出目錄的指定,在HDFS還是在S3。
- 輸入目錄:輸入目錄的指定,如輸入HDFS上的目錄、S3或是多少個檔案。
輸入目錄中的檔案數用於決定一個Job的MapTask的數量。
那麼到底會有多少個MapTask呢?
Application Master會為每一個split(分片)建立一個MapTask。通常情況下,每個檔案都會是一個split。如果檔案太大(大於128M、HDFS預設塊大小)就會分為多個split並關聯到這個檔案,也就是一個檔案會產生多個Map Task。獲取split數量方法程式碼如下 getSplits() of the FileInputFormat class:
num_splits = 0 for each input file f: remaining = f.length while remaining / split_size > split_slope: num_splits += 1 remaining -= split_size
split_slope = 1.1
split_size =~ dfs.blocksize
MapTask執行過程
Application Master會向Resource Maneger資源管理器提交job所需要的資源:為每一個split檔案申請一個container來執行Map Task。
為了提高檔案讀取效率container在map split所在的機器上執行是最為理想的。因此AM會根據資料本地性>CPU>記憶體匹配的方式分配container
- 如果發現一個Node Manager上有所需的map split那麼相關的container就會分配到這個NM上(因為根據HDFS備份機制有3臺機器上同時擁有相同的塊);
- 否則, 會分配到機櫃內的其他機器上;
- 否則, 會分配到叢集上的任何一個機器上
當容器被分配給AM時Map Task任務就會啟動。
Map 階段:示例
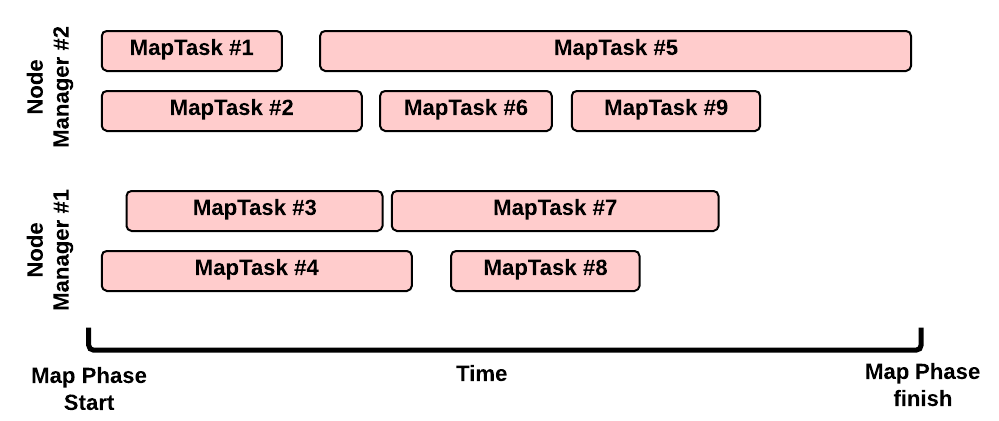
這是一個典型的Map執行場景:
- 有2個Node Manager:每個Node Manager擁有2GB記憶體,而每個MapTask需要1GB記憶體,因此每個NM可以同時執行2個container
- 沒有其他的應用程式在叢集中執行
- 我們的job有9個split (例如,在輸入目錄裡有8個檔案,但其中只有一個是大於HDFS塊大小的檔案,所以我們把它分為2個map split);因此需要9個map
MapTask執行的Timeline
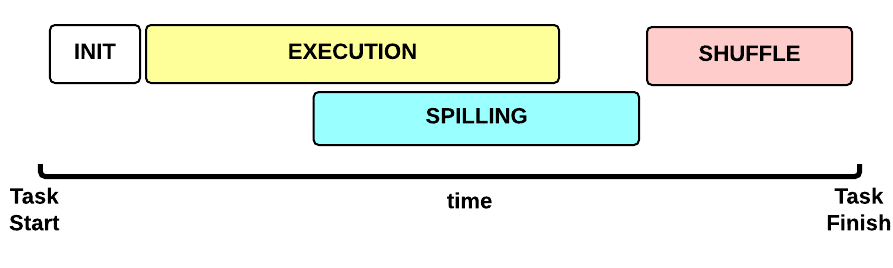
現在讓我們專注於一個Map Task任務。這是Map Task任務執行時間線:
- 初始化(INIT)階段:初始化Map Task(預設是什麼都沒有。。)
- 執行(EXECUTION)階段: 對於每個 (key, value)執行map()函式
- 排序(SPILLING)階段:map輸出會暫存到記憶體當中排序,當快取達到一定程度時會寫到磁碟上,並刪除記憶體裡的資料
- SHUFFLE 階段:排序結束後,會合並所有map輸出,並分割槽傳輸給reduce。
MapTask:初始化(INIT)
1. 建立一個Task上下文,Reduce也繼承自它(TaskAttemptContext.class)
2. 建立MAP例項Mapper.class
3. 設定input (e.g., InputFormat.class, InputSplit.class, RecordReader.class)
4. 設定output (NewOutputCollector.class)
5. 建立mapper的上下文(MapContext.class, Mapper.Context.class)
6. 初始化輸入,例如
7. 建立一個SplitLineReader.class object
8. 建立一個HdfsDataInputStream.class object
MapTask:執行(EXECUTION)
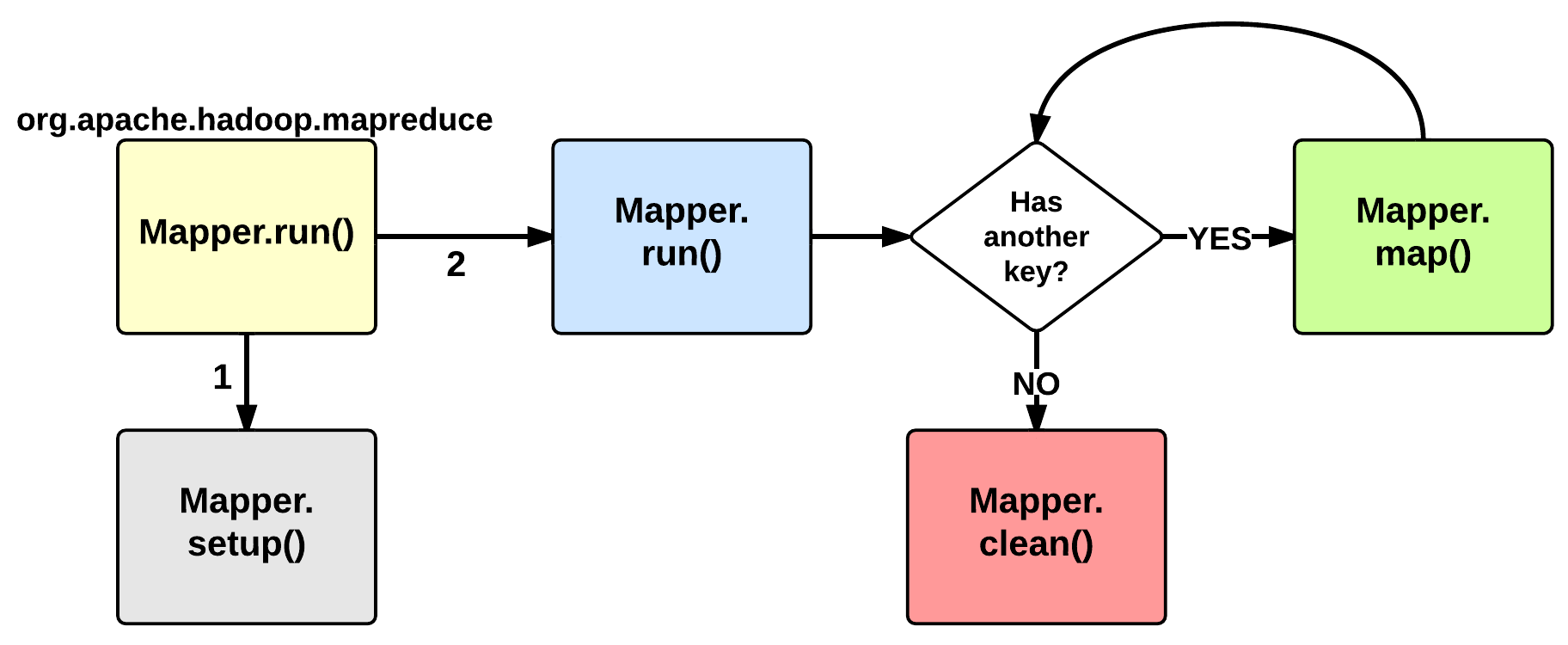
Map的執行階段從 Mapper class的run 方法開始,我們通常要寫的也就是它了。預設情況下run之前會呼叫setup方法:這個函式沒有做任何事情,但是我們可以重寫它來配置相關的類變數等資訊。執行setup方法之後會對每一個<key, value>執行map()函式。之後map context會儲存這些資料到一個快取區,為後續排序做準備。
當map執行完處理時,還會呼叫一個clean方法:預設情況下,也不執行任何操作,但使用者也可以重寫它。
MapTask:排序(SPILLING)
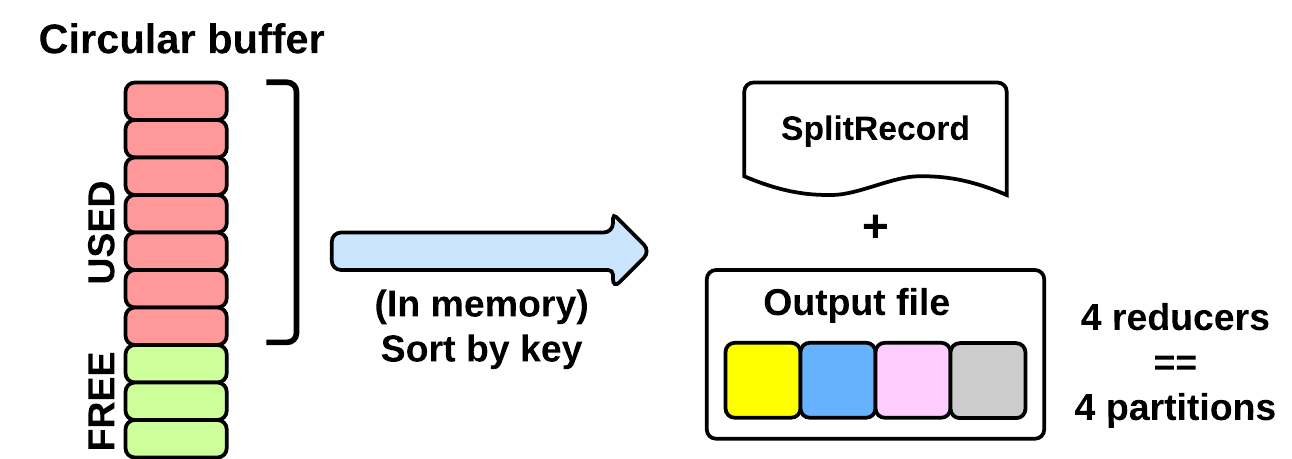
執行階段期間map會把資料寫進一個快取區(MapTask.MapOutputBuffer)。這個快取大小由配置項設定mapreduce.task.io.sort.mb (預設:100MB)。為了提高硬碟刷寫速度快取區達到80%會寫資料到磁碟,會有一個單獨的執行緒並行執行。當快取區容量達到100%那麼就要等到這個單獨的執行緒把資料寫完才能繼續執行map方法。
排序執行緒會執行以下動作:
1. 建立一個SpillRecord和一個FSOutputStream (在本地檔案系統)
2. 在記憶體中對鍵值對進行快速排序
3. 分割槽
4. 按順序寫入本地分割槽檔案。
Shuffle階段

shuffle階段主要是做資料的排序和合並操作,然後把資料存到本地檔案系統上,等待Reduce來獲取資料。等到所有的MapTask產出的資料傳輸都Reduce機器上,並對資料進行排序以後才能算是Shuffle過程的結束。也就說從Map函數出來之後到Reduce函式之前的所有資料操作都叫Shuffle操作,包括排序、合併、分割槽、傳輸等。
Reduce階段
Reduce階段的run與Map階段的run執行是類似的。
ref:http://ercoppa.github.io/HadoopInternals/AnatomyMapReduceJob.html