
關於TCP封包、粘包、半包
關於Tcp封包
很多朋友已經對此作了不少研究,也花費不少心血編寫了實現程式碼和blog文件。當然也充斥著一些各式的評論,自己看了一下,總結一些心得。
首先我們學習一下這些朋友的心得,他們是:
//………………
當然還有太多,很多東西粘來粘區也不知道到底是誰的原作,J
看這些朋友的blog是我建議親自看一下TCP-IP詳解卷1中的相關內容【原理性的內容一定要看】。
TCP大致工作原理介紹:
工作原理
TCP-IP詳解卷1第17章中17.2節對TCP服務原理作了一個簡明介紹(以下藍色字型摘自《TCP-IP詳解卷1第17章17.2節》):
儘管T C P和U D P都使用相同的網路層( I P),T C P
面向連線意味著兩個使用T C P的應用(通常是一個客戶和一個伺服器)在彼此交換資料之前必須先建立一個T C P連線。這一過程與打電話很相似,先撥號振鈴,等待對方摘機說“喂”,然後才說明是誰。在第1 8章我們將看到一個T C P連線是如何建立的,以及當一方通訊結束後如何斷開連線。
在一個T C P連線中,僅有兩方進行彼此通訊。在第1 2章介紹的廣播和多播不能用於T C P。
T C P通過下列方式來提供可靠性:
• 應用資料被分割成T C P認為最適合傳送的資料塊。這和U D P完全不同,應用程式產生的資料報長度將保持不變。由
• 當T C P發出一個段後,它啟動一個定時器,等待目的端確認收到這個報文段。如果不能及時收到一個確認,將重發這個報文段。在第2 1章我們將瞭解T C P協議中自適應的超時及重傳策略。
• 當T C P收到發自T C P連線另一端的資料,它將傳送一個確認。這個確認不是立即傳送,通常將推遲幾分之一秒,這將在1 9 . 3節討論。
• T C P將保持它首部和資料的檢驗和。這是一個端到端的檢驗和,目的是檢測資料在傳輸過程中的任何變化。如果收到段的檢驗和有差錯,
• 既然T C P報文段作為I P資料報來傳輸,而I P資料報的到達可能會失序,因此T C P報文段的到達也可能會失序。如果必要, T C P將對收到的資料進行重新排序,將收到的資料以正確的順序交給應用層。
• 既然I P資料報會發生重複, T C P的接收端必須丟棄重複的資料。
• T C P還能提供流量控制。T C P連線的每一方都有固定大小的緩衝空間。T C P的接收端只允許另一端傳送接收端緩衝區所能接納的資料。這將防止較快主機致使較慢主機的緩衝區溢位。兩個應用程式通過T C P連線交換8 bit位元組構成的位元組流。T C P不在位元組流中插入記錄識別符號。我們將這稱為位元組流服務(byte stream service)。如果一方的應用程式先傳1 0位元組,又傳2 0位元組,再傳5 0位元組,連線的另一方將無法瞭解發方每次傳送了多少位元組。收方可以分4次接收這8 0個位元組,每次接收2 0位元組。一端將位元組流放到T C P連線上,同樣的位元組流將出現在T C P連線的另一端。另外,T C P對位元組流的內容不作任何解釋。T C P不知道傳輸的資料位元組流是二進位制資料,還是A S C I I字元、E B C D I C字元或者其他型別資料。對位元組流的解釋由T C P連線雙方的應用層解釋。這種對位元組流的處理方式與U n i x作業系統對檔案的處理方式很相似。U n i x的核心對一個應用讀或寫的內容不作任何解釋,而是交給應用程式處理。對U n i x的核心來說,它無法區分一個二進位制檔案與一個文字檔案。
T C P如何確定報文段的長度
我仍然引用官方解釋《TCP-IP詳解卷1》第18章18.4節:
最大報文段長度( M S S)表示T C P傳往另一端的最大塊資料的長度。當一個連線建立時【三次握手】,連線的雙方都要通告各自的M S S。我們已經見過M S S都是1 0 2 4。這導致I P資料報通常是4 0位元組長:2 0位元組的T C P首部和2 0位元組的I P首部。
在有些書中,將它看作可“協商”選項。它並不是任何條件下都可協商。當建立一個連
接時,每一方都有用於通告它期望接收的M S S選項(M S S選項只能出現在S Y N報文段中)。如果一方不接收來自另一方的M S S值,則M S S就定為預設值5 3 6位元組(這個預設值允許2 0位元組的I P首部和2 0位元組的T C P首部以適合5 7 6位元組I P資料報)。
一般說來,如果沒有分段發生, M S S還是越大越好(這也並不總是正確,參見圖2 4 - 3和圖2 4 - 4中的例子)。報文段越大允許每個報文段傳送的資料就越多,相對I P和T C P首部有更高的網路利用率。當T C P傳送一個S Y N時,或者是因為一個本地應用程序想發起一個連線,或者是因為另一端的主機收到了一個連線請求,它能將M S S值設定為外出介面上的M T U長度減去固定的I P首部和T C P首部長度。對於一個乙太網, M S S值可達1 4 6 0位元組。使用IEEE 802.3的封裝(參見2 . 2節),它的M S S可達1 4 5 2位元組。
如果目的I P地址為“非本地的( n o n l o c a l )”,M S S通常的預設值為5 3 6。而區分地址是本地還是非本地是簡單的,如果目的I P地址的網路號與子網號都和我們的相同,則是本地的;如果目的I P地址的網路號與我們的完全不同,則是非本地的;如果目的I P地址的網路號與我們的相同而子網號與我們的不同,則可能是本地的,也可能是非本地的。大多數T C P實現版都提供了一個配置選項(附錄E和圖E- 1),讓系統管理員說明不同的子網是屬於本地還是非本地。這個選項的設定將確定M S S可以選擇儘可能的大(達到外出介面的MT U長度)或是預設值5 3 6。
M S S讓主機限制另一端傳送資料報的長度。加上主機也能控制它傳送資料報的長度,這將使以較小M T U連線到一個網路上的主機避免分段。
只有當一端的主機以小於5 7 6位元組的MT U直接連線到一個網路中,避免這種分段才會有效。
如果兩端的主機都連線到乙太網上,都採用5 3 6的M S S,但中間網路採用2 9 6的M T U,也將會
出現分段。使用路徑上的M T U發現機制(參見2 4 . 2節)是關於這個問題的唯一方法。
以上說明MSS的值可以通過協商解決,這個協商過程會涉及MTU的值的大小,前面說了:【MSS=外出介面上的MTU-IP首部-TCP首部】,我們來看看資料進入TCP協議棧的封裝過程:
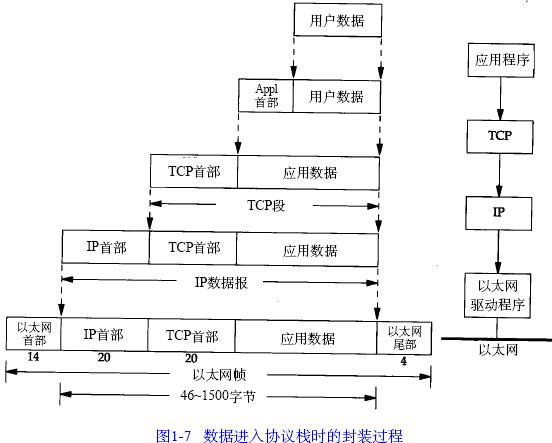
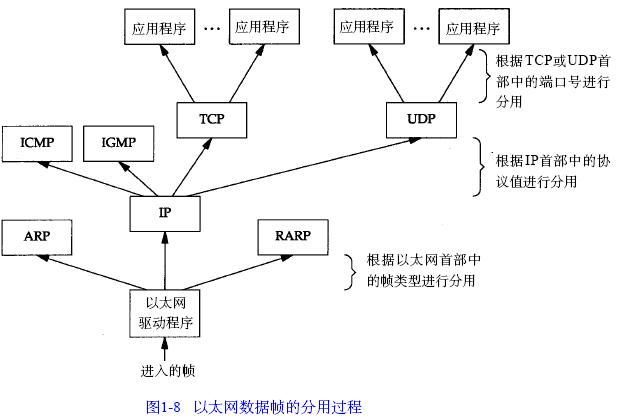
最後一層乙太網幀的大小應該就是我們的出口MTU大小了。當目的主機收到一個乙太網資料幀時,資料就開始從協議棧中由底向上升,同時去掉各層協議加上的報文首部。每層協議盒都要去檢查報文首部中的協議標識,以確定接收資料的上層協議。這個過程稱作分用( D e m u l t i p l e x i n g),圖1 - 8顯示了該過程是如何發生的。
那麼什麼是MTU呢,這實際上是資料鏈路層的一個概念,乙太網和802.3這兩種區域網技術標準都對“鏈路層”的資料幀有大小限制:
l 最大傳輸單元MTU
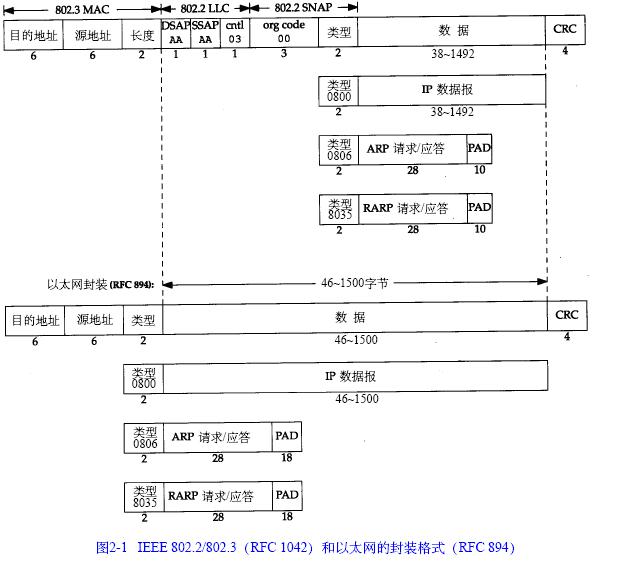
正如在圖2 - 1看到的那樣,乙太網和8 0 2 . 3對資料幀的長度都有一個限制,其最大值分別是1 5 0 0和1 4 9 2位元組。鏈路層的這個特性稱作M T U,最大傳輸單元。不同型別的網路大多數都有一個上限。
如果I P層有一個數據報要傳,而且資料的長度比鏈路層的M T U還大,那麼I P層就需要進行分片( f r a gm e n t a t i o n),把資料報分成若干片,這樣每一片都小於M T U。我們將在11 . 5節討論IP分片的過程。
圖2 - 5列出了一些典型的M T U值,它們摘自RFC 1191[Mogul and Deering 1990]。點到點的鏈路層(如S L I P和P P P)的M T U並非指的是網路媒體的物理特性。相反,它是一個邏輯限制,目的是為互動使用提供足夠快的響應時間。在2 . 1 0節中,我們將看到這個限制值是如何計算出來的。在3 . 9節中,我們將用n e t s t a t命令打印出網路介面的M T U。
l 路徑MTU
當在同一個網路上的兩臺主機互相進行通訊時,該網路的M T U是非常重要的。但是如果
兩臺主機之間的通訊要通過多個網路,那麼每個網路的鏈路層就可能有不同的M T U。重要的
不是兩臺主機所在網路的M T U的值,重要的是兩臺通訊主機路徑中的最小MT U。它被稱作路
徑M T U。
兩臺主機之間的路徑M T U不一定是個常數。它取決於當時所選擇的路由。而選路不一定
是對稱的(從A到B的路由可能與從B到A的路由不同),因此路徑M T U在兩個方向上不一定是
一致的。
RFC 1191[Mogul andDeering 1990]描述了路徑M T U的發現機制,即在任何時候確定路徑
M T U的方法。我們在介紹了I C M P和I P分片方法以後再來看它是如何操作的。在11. 6節中,我
們將看到I C M P的不可到達錯誤就採用這種發現方法。在11. 7節中,還會看到, t r a c e r o u t e程式
也是用這個方法來確定到達目的節點的路徑M T U。在11 . 8節和24 . 2節,將介紹當產品支援路
徑M T U的發現方法時,U D P和TC P是如何進行操作的。
TCP的超時與重傳
前面談到TCP如何保證傳輸可靠性是說到“當T C P發出一個段後,它啟動一個定時器,等待目的端確認收到這個報文段。如果不能及時收到一個確認,將重發這個報文段”,下面我看一下TCP的超時與重傳。
T C P提供可靠的運輸層。它使用的方法之一就是確認從另一端收到的資料。但資料和確認都有可能會丟失。T C P通過在傳送時設定一個定時器來解決這種問題。如果當定時器溢位時還沒有收到確認,它就重傳該資料。對任何實現而言,關鍵之處就在於超時和重傳的策略,即怎樣決定超時間隔和如何確定重傳的頻率。
對每個連線,T C P管理4個不同的定時器。
1) 重傳定時器使用於當希望收到另一端的確認。
2) 堅持( p e r s i s t)定時器使視窗大小資訊保持不斷流動,即使另一端關閉了其接收視窗。
3) 保活( k e e p a l iv e )定時器可檢測到一個空閒連線的另一端何時崩潰或重啟。
4) 2MSL定時器測量一個連線處於T I M E_ WA I T狀態的時間。
T C P超時與重傳中最重要的部分就是對一個給定連線的往返時間( RT T)的測量。由於路由器和網路流量均會變化,因此我們認為這個時間可能經常會發生變化, T C P應該跟蹤這些變化並相應地改變其超時時間。
大多數源於伯克利的T C P實現在任何時候對每個連線僅測量一次RT T值。在傳送一個報文段時,如果給定連線的定時器已經被使用,則該報文段不被計時。
具體RTT值的估算比較麻煩,需要可以參考《TCP-IP詳解卷1第21章》
TCP經受延時的確認
互動資料總是以小於最大報文段長度的分組傳送。對於這些小的報文段,接收方使用經受時延的確認方法來判斷確認是否可被推遲傳送,以便與回送資料一起傳送。這樣通常會減少報文段的數目。
通常T C P在接收到資料時並不立即傳送A C K;相反,它推遲傳送,以便將A C K與需要沿該方向傳送的資料一起傳送(有時稱這種現象為資料捎帶A C K)。絕大多數實現採用的時延為200 ms,也就是說,T C P將以最大200ms 的時延等待是否有資料一起傳送。
我們看看另一位朋友的blog對此的介紹:
摘要:當使用TCP傳輸小型資料包時,程式的設計是相當重要的。如果在設計方案中不對TCP資料包的延遲應答,Nagle演算法,Winsock緩衝作用引起重視,將會嚴重影響程式的效能。這篇文章討論了這些問題,列舉了兩個案例,給出了一些傳輸小資料包的優化設計方案。
背景:當Microsoft TCP棧接收到一個數據包時,會啟動一個200毫秒的計時器。當ACK確認資料包發出之後,計時器會復位,接收到下一個資料包時,會再次啟動200毫秒的計時器。為了提升應用程式在內部網和Internet上的傳輸效能,Microsoft TCP棧使用了下面的策略來決定在接收到資料包後什麼時候傳送ACK確認資料包:
1、如果在200毫秒的計時器超時之前,接收到下一個資料包,則立即傳送ACK確認資料包。
2、如果當前恰好有資料包需要發給ACK確認資訊的接收端,則把ACK確認資訊附帶在資料包上立即傳送。
3、當計時器超時,ACK確認資訊立即傳送。為了避免小資料包擁塞網路,Microsoft TCP棧預設啟用了Nagle演算法,這個演算法能夠將應用程式多次呼叫Send傳送的資料拼接起來,當收到前一個數據包的ACK確認資訊時,一起傳送出去。下面是Nagle
演算法的例外情況:
1、如果Microsoft TCP棧拼接起來的資料包超過了MTU值,這個資料會立即傳送,而不等待前一個數據包的ACK確認資訊。在乙太網中,TCP的MTU(Maximum TransmissionUnit)值是1460位元組。
2、如果設定了TCP_NODELAY選項,就會禁用Nagle演算法,應用程式呼叫Send傳送的資料包會立即被投遞到網路,而沒有延遲。為了在應用層優化效能,Winsock把應用程式呼叫Send傳送的資料從應用程式的緩衝區複製到Winsock
核心緩衝區。Microsoft TCP棧利用類似Nagle演算法的方法,決定什麼時候才實際地把資料投遞到網路。核心緩衝區的預設大小是8K,使用SO_SNDBUF選項,可以改變Winsock核心緩衝區的大小。如果有必要的話,
Winsock能緩衝大於SO_SNDBUF緩衝區大小的資料。在絕大多數情況下,應用程式完成Send呼叫僅僅表明資料被複制到了Winsock核心緩衝區,並不能說明資料就實際地被投遞到了網路上。唯一一種例外的情況是:通過設定SO_SNDBUT為0禁用了Winsock核心緩衝區。
Winsock使用下面的規則來嚮應用程式表明一個Send呼叫的完成:
1、如果socket仍然在SO_SNDBUF限額內,Winsock複製應用程式要傳送的資料到核心緩衝區,完成Send呼叫。
2、如果Socket超過了SO_SNDBUF限額並且先前只有一個被緩衝的傳送資料在核心緩衝區,Winsock複製要傳送的資料到核心緩衝區,完成Send呼叫。
3、如果Socket超過了SO_SNDBUF限額並且核心緩衝區有不只一個被緩衝的傳送資料,Winsock複製要傳送的資料到核心緩衝區,然後投遞資料到網路,直到Socket降到SO_SNDBUF限額內或者只剩餘一個要傳送的資料,才完成Send呼叫。
案例1
一個Winsock TCP客戶端需要傳送10000個記錄到Winsock TCP服務端,儲存到資料庫。記錄大小從20位元組到100
位元組不等。對於簡單的應用程式邏輯,可能的設計方案如下:
1、客戶端以阻塞方式傳送,服務端以阻塞方式接收。
2、客戶端設定SO_SNDBUF為0,禁用Nagle演算法,讓每個資料包單獨的傳送。
3、服務端在一個迴圈中呼叫Recv接收資料包。給Recv傳遞200位元組的緩衝區以便讓每個記錄在一次Recv呼叫中被獲取到。
效能:在測試中發現,客戶端每秒只能傳送5條資料到服務段,總共10000條記錄,976K位元組左右,用了半個多小時才全部傳到伺服器。
分析:因為客戶端沒有設定TCP_NODELAY選項,Nagle演算法強制TCP棧在傳送資料包之前等待前一個數據包的ACK確認資訊。然而,客戶端設定SO_SNDBUF為0,禁用了核心緩衝區。因此,10000個Send呼叫只能一個數據包一個數據包的傳送和確認,由於下列原因,每個ACK確認資訊被延遲200毫秒:
1、當伺服器獲取到一個數據包,啟動一個200毫秒的計時器。
2、服務端不需要向客戶端傳送任何資料,所以,ACK確認資訊不能被髮回的資料包順路攜帶。
3、客戶端在沒有收到前一個數據包的確認資訊前,不能傳送資料包。
4、服務端的計時器超時後,ACK確認資訊被髮送到客戶端。
如何提高效能:在這個設計中存在兩個問題。第一,存在延時問題。客戶端需要能夠在200毫秒內傳送兩個資料包到服務端。因為客戶端預設情況下使用Nagle演算法,應該使用預設的核心緩衝區,不應該設定SO_SNDBUF為0。一旦TCP
棧拼接起來的資料包超過MTU值,這個資料包會立即被髮送,不用等待前一個ACK確認資訊。第二,這個設計方案對每一個如此小的的資料包都呼叫一次Send。傳送這麼小的資料包是不很有效率的。在這種情況下,應該把每個記錄補充到100位元組並且每次呼叫Send傳送80個記錄。為了讓服務端知道一次總共傳送了多少個記錄,客戶端可以在記錄前面帶一個頭資訊。
案例二:一個Winsock TCP客戶端程式開啟兩個連線和一個提供股票報價服務的Winsock TCP服務端通訊。第一個連線作為命令通道用來傳輸股票編號到服務端。第二個連線作為資料通道用來接收股票報價。兩個連線被建立後,客戶端通過命令通道傳送股票編號到服務端,然後在資料通道上等待返回的股票報價資訊。客戶端在接收到第一個股票報價資訊後傳送下一個股票編號請求到服務端。客戶端和服務端都沒有設定SO_SNDBUF和TCP_NODELAY
選項。
效能:測試中發現,客戶端每秒只能獲取到5條報價資訊。
分析:
這個設計方案一次只允許獲取一條股票資訊。第一個股票編號資訊通過命令通道傳送到服務端,立即接收到服務端通過資料通道返回的股票報價資訊。然後,客戶端立即傳送第二條請求資訊,send呼叫立即返回,傳送的資料被複制到核心緩衝區。然而,TCP棧不能立即投遞這個資料包到網路,因為沒有收到前一個數據包的
ACK確認資訊。200毫秒後,服務端的計時器超時,第一個請求資料包的ACK確認資訊被髮送回客戶端,客戶端的第二個請求包才被投遞到網路。第二個請求的報價資訊立即從資料通道返回到客戶端,因為此時,客戶端的計時器已經超時,第一個報價資訊的ACK確認資訊已經被髮送到服務端。這個過程迴圈發生。
如何提高效能:在這裡,兩個連線的設計是沒有必要的。如果使用一個連線來請求和接收報價資訊,股票請求的ACK確認資訊會被返回的報價資訊立即順路攜帶回來。要進一步的提高效能,客戶端應該一次呼叫Send傳送多個股票請求,服務端一次返回多個報價資訊。如果由於某些特殊原因必須要使用兩個單向的連線,客戶端和服務端都應該設定TCP_NODELAY
選項,讓小資料包立即傳送而不用等待前一個數據包的ACK確認資訊。
提高效能的建議:
上面兩個案例說明了一些最壞的情況。當設計一個方案解決大量的小資料包傳送和接收時,應該遵循以下的建議:
1、如果資料片段不需要緊急傳輸的話,應用程式應該將他們拼接成更大的資料塊,再呼叫Send。因為傳送緩衝區
很可能被複制到核心緩衝區,所以緩衝區不應該太大,通常比8K小一點點是很有效率的。只要Winsock核心緩衝區
得到一個大於MTU值的資料塊,就會發送若干個資料包,剩下最後一個數據包。傳送方除了最後一個數據包,都不會
被200毫秒的計時器觸發。
2、如果可能的話,避免單向的Socket資料流接連。
3、不要設定SO_SNDBUF為0,除非想確保資料包在呼叫Send完成之後立即被投遞到網路。事實上,8K的緩衝區適合大多數
情況,不需要重新改變,除非新設定的緩衝區經過測試的確比預設大小更高效。
4、如果資料傳輸不用保證可靠性,使用UDP。
結論:
1. TCP提供了面向“連續位元組流”的可靠的傳輸服務,TCP並不理解流所攜帶的資料內容,這個內容需要應用層自己解析。
2. “位元組流”是連續的、非結構化的,而我們的應用需要的是有序的、結構化的資料資訊,因此我們需要定義自己的“規則”去解讀這個“連續的位元組流“,那解決途徑就是定義自己的封包型別,然後用這個型別去對映“連續位元組流”。
如何定義封包,我們回顧一下前面這個資料進入協議棧的封裝過程圖:
封包其實就是將上圖中進入協議棧的使用者資料[即使用者要傳送的資料]定義為一種方便識別和交流的型別,這有點類似信封的概念,信封就是一種人們之間通訊的格式,信封格式如下:
信封格式:
收信人郵編
收信人地址
收信人姓名
信件內容
那麼在程式裡面我們也需要定義這種格式:在C++裡面只有結構和類這種兩種型別適合表達這個概念了。網路上很多朋友對此表述了自己的看法並貼出了程式碼:比如
/************************************************************************/
/* 資料封包資訊定義開始 */
/************************************************************************/
#pragma pack(push,1) //將原對齊方式壓棧,採用新的1位元組對齊方式
/* 封包型別列舉[此處根據需求列舉] */
typedef enum{
NLOGIN=1,
NREG=2,
NBACKUP=3,
NRESTORE=3,
NFILE_TRANSFER=4,
NHELLO=5
} PACKETTYPE;
/* 包頭 */
typedef struct tagNetPacketHead{
byte version;//版本
PACKETTYPE ePType;//包型別
WORD nLen;//包體長度
} NetPacketHead;
/* 封包物件[包頭&包體] */
typedef struct tagNetPacket{
NetPacketHeadnetPacketHead;//包頭
char * packetBody;//包體
} NetPacket;
#pragma pack(pop)
/**************資料封包資訊定義結束**************************/
3. 發包順序與收包問題
a) 由於TCP要通過協商解決傳送出去的報文段的長度,因此我們傳送的資料很有可能被分割甚至被分割後再重組交給網路層傳送,而網路層又是採用分組傳送,即網路層資料報到達目標的順序完全無法預測,那麼收包會出現半包、粘包問題。舉個例子,傳送端連續傳送兩端資料msg1和msg2,那麼傳送端[傳輸層]可能會出現以下情況:
i. Msg1和msg2小於TCP的MSS,兩個包按照先後順序被髮出,沒有被分割和重組
ii. Msg1過大被分割成兩段TCP報文msg1-1、msg2-2進行傳送,msg2較小直接被封裝成一個報文傳送
iii. Msg1過大被分割成兩段TCP報文msg1-1、msg2-2,msg1-1先被傳送,剩下的msg1-2和msg2[較小]被組合成一個報文傳送
iv. Msg1過大被分割成兩段TCP報文msg1-1、msg2-2,msg1-1先被傳送,剩下的msg1-2和msg2[較小]組合起來還是太小,組合的內容在和後面再發送的msg3的前部分資料組合起來發送
v. ……………………….太多……………………..
b) 接收端[傳輸層]可能出現的情況
i. 先收到msg1,再收到msg2,這種方式太順利了。
ii. 先收到msg1-1,再收到msg1-2,再收到msg2
iii. 先收到msg1,再收到msg2-1,再收到msg2-2
iv. 先收到msg1和msg2-1,再收到msg2-2
v. //…………還有很多………………
c) 其實“接收端網路層”接收到的分組資料報順序和傳送端比較可能完全是亂的,比如發“送端網路層”傳送1、2、3、4、5,而接收端網路層接收到的資料報順序卻可能是2、1、5、4、3,但是“接收端的傳輸層”會保證連結的有序性和可靠性,“接收端的傳輸層”會對“接收端網路層”收到的順序紊亂的資料報重組成有序的報文[即傳送方傳輸層發出的順序],然後交給“接收端應用層”使用,所以“接收端傳輸層”總是能夠保證資料包的有序性,“接收端應用層”[我們編寫的socket程式]不用擔心接收到的資料的順序問題。
d) 但是如上所述,粘包問題和半包問題不可避免。我們在接收端應用層需要自己編碼處理粘包和半包問題。一般做法是定義一個緩衝區或者是使用標準庫/框架提供的容器迴圈存放接收到資料,邊接收變判斷緩衝區資料是否滿足包頭大小,如果滿足包頭大小再判斷緩衝區剩下資料是否滿足包體大小,如果滿足則提取。詳細步驟如下:
1. 接收資料存入緩衝區尾部
2. 緩衝區資料滿足包頭大小否
3. 緩衝區資料不滿足包頭大小,回到第1步;緩衝區資料滿足包頭大小則取出包頭,接著判斷緩衝區剩餘資料滿足包頭中定義的包體大小否,不滿足則回到第1步。
4. 緩衝區資料滿足一個包頭大小和一個包體大小之和,則取出包頭和包體進行使用,此處使用可以採用拷貝方式轉移緩衝區資料到另外一個地方,也可以為了節省記憶體直接採取呼叫回撥函式的方式完成資料使用。
5. 清除緩衝區的第一個包頭和包體資訊,做法一般是將緩衝區剩下的資料拷貝到緩衝區首部覆蓋“第一個包頭和包體資訊”部分即可。
粘包、半包處理具體實現很多朋友都有自己的做法,比如最前面貼出的連結,這裡我也貼出一段參考:
緩衝區實現標頭檔案:
#include<windows.h>
#ifndef_CNetDataBuffer_H_
#define_CNetDataBuffer_H_
#ifndefTCPLAB_DECLSPEC
#defineTCPLAB_DECLSPEC _declspec(dllimport)
#endif
/************************************************************************/
/* 資料封包資訊定義開始 */
/************************************************************************/
#pragmapack(push,1) //將原對齊方式壓棧,採用新的1位元組對齊方式
/* 封包型別列舉[此處根據需求列舉] */
typedef enum{
NLOGIN=1,
NREG=2,
NBACKUP=3,
NRESTORE=3,
NFILE_TRANSFER=4,
NHELLO=5
} PACKETTYPE;
/* 包頭 */
typedef structtagNetPacketHead{
byte version;//版本
PACKETTYPE ePType;//包型別
WORD nLen;//包體長度
} NetPacketHead;
/* 封包物件[包頭&包體] */
typedef structtagNetPacket{
NetPacketHead netPacketHead;//包頭
char * packetBody;//包體
} NetPacket;
#pragmapack(pop)
/**************資料封包資訊定義結束**************************/
//緩衝區初始大小
#defineBUFFER_INIT_SIZE 2048
//緩衝區膨脹係數[緩衝區膨脹後的大小=原大小+係數*新增資料長度]
#defineBUFFER_EXPAND_SIZE 2
//計算緩衝區除第一個包頭外剩下的資料的長度的巨集[緩衝區資料總長度-包頭大小]
#defineBUFFER_BODY_LEN (m_nOffset-sizeof(NetPacketHead))
//計算緩衝區資料當前是否滿足一個完整包資料量[包頭&包體]
#defineHAS_FULL_PACKET ( \
(sizeof(NetPacketHead)<=m_nOffset)&& \
((((NetPacketHead*)m_pMsgBuffer)->nLen)<= BUFFER_BODY_LEN) \
)
//檢查包是否合法[包體長度大於零且包體不等於空]
#defineIS_VALID_PACKET(netPacket) \
((netPacket.netPacketHead.nLen>0)&& (netPacket.packetBody!=NULL))
//緩衝區第一個包的長度
#defineFIRST_PACKET_LEN(sizeof(NetPacketHead)+((NetPacketHead*)m_pMsgBuffer)->nLen)
/* 資料緩衝 */
class/*TCPLAB_DECLSPEC*/ CNetDataBuffer
{
/* 緩衝區操作相關成員 */
private:
char *m_pMsgBuffer;//資料緩衝區
int m_nBufferSize;//緩衝區總大小
int m_nOffset;//緩衝區資料大小
public:
int GetBufferSize() const;//獲得緩衝區的大小
BOOL ReBufferSize(int);//調整緩衝區的大小
BOOL IsFitPacketHeadSize() const;//緩衝資料是否適合包頭大小
BOOL IsHasFullPacket() const;//緩衝區是否擁有完整的包資料[包含包頭和包體]
BOOL AddMsg(char *pBuf,int nLen);//新增訊息到緩衝區
const char *GetBufferContents() const;//得到緩衝區內容
void Reset();//緩衝區復位[清空緩衝區資料,但並未釋放緩衝區]
void Poll();//移除緩衝區首部的第一個資料包
public:
CNetDataBuffer();
~CNetDataBuffer();
};
#endif
緩衝區實現檔案:
#defineTCPLAB_DECLSPEC _declspec(dllexport)
#include"CNetDataBuffer.h"
/* 構造 */
CNetDataBuffer::CNetDataBuffer()
{
m_nBufferSize = BUFFER_INIT_SIZE;//設定緩衝區大小
m_nOffset = 0;//設定資料偏移值[資料大小]為0
m_pMsgBuffer = NULL;
m_pMsgBuffer = newchar[BUFFER_INIT_SIZE];//分配緩衝區為初始大小
ZeroMemory(m_pMsgBuffer,BUFFER_INIT_SIZE);//緩衝區清空
}
/* 析構 */
CNetDataBuffer::~CNetDataBuffer()
{
if (m_nOffset!=0)
{
delete [] m_pMsgBuffer;//釋放緩衝區
m_pMsgBuffer = NULL;
m_nBufferSize=0;
m_nOffset=0;
}
}
/************************************************************************/
/* Description: 獲得緩衝區中資料的大小 */
/* Return: 緩衝區中資料的大小 */
/************************************************************************/
INTCNetDataBuffer::GetBufferSize() const
{
return this->m_nOffset;
}
/************************************************************************/
/* Description: 緩衝區中的資料大小是否足夠一個包頭大小 */
/* Return: 如果滿足則返回True,否則返回False
/************************************************************************/
BOOLCNetDataBuffer::IsFitPacketHeadSize() const
{
returnsizeof(NetPacketHead)<=m_nOffset;
}
/************************************************************************/
/* Description: 判斷緩衝區是否擁有完整的資料包(包頭和包體) */
/* Return: 如果緩衝區包含一個完整封包則返回True,否則False */
/************************************************************************/
BOOLCNetDataBuffer::IsHasFullPacket() const
{
//如果連包頭大小都不滿足則返回
//if (!IsFitPacketHeadSize())
// returnFALSE;
return HAS_FULL_PACKET;//此處採用巨集簡化程式碼
}
/************************************************************************/
/* Description: 重置緩衝區大小 */
/* nLen: 新增加的資料長度 */
/* Return: 調整結果 */
/************************************************************************/
BOOLCNetDataBuffer::ReBufferSize(int nLen)
{
char *oBuffer = m_pMsgBuffer;//儲存原緩衝區地址
try
{
nLen=(nLen<64?64:nLen);//保證最小增量大小
//新緩衝區的大小=增加的大小+原緩衝區大小
m_nBufferSize =BUFFER_EXPAND_SIZE*nLen+m_nBufferSize;
m_pMsgBuffer = newchar[m_nBufferSize];//分配新的緩衝區,m_pMsgBuff指向新緩衝區地址
ZeroMemory(m_pMsgBuffer,m_nBufferSize);//新緩衝區清零
CopyMemory(m_pMsgBuffer,oBuffer