
基於使用者的協同過濾推薦—實現電影推薦
不正之處,歡迎指教。
“嗨,最經有什麼好看的電影嗎?”
“那個xxx,xxx我感覺還是不錯的,推薦你可以去看一下”
上述情景在我們的生活中可以說是很熟悉的,當我們不知道選擇哪一部電影去看的時候,我們就會去詢問周圍的人,希望從他們那裡可以得到一些比較好的推薦,這是屬於典型的推薦情景。當我們在詢問別人的時候往往會有一個自己的判斷,比較傾向於向那些和自己觀影差不多的人去詢問,你比較喜歡看文藝片,甲喜歡看日本的動漫,那麼你是不太會去想他詢問的,你會向同樣喜歡看文藝片的乙去詢問。也就是找那些和自己相似度比較大的人來詢問。
在我們網購的時候,經常會出現你可能對XX也感興趣,提示的XX和你之前瀏覽過的或者購買過的很相似,不同於我們上述的基於使用者的推薦,這種是就要物品的推薦,在本文中,先討論基於使用者的推薦,後續會討論基於物品的推薦。
1.協同過濾
協同過濾(Collaborative Filtering)字面上的解釋就是在別人的幫助下來過濾篩選,協同過濾一般是在海量的使用者中發現一小部分和你品味比較相近的,在協同過濾中,這些使用者稱為鄰居,然後根據他們喜歡的東西組織成一個排序的目錄來推薦給你。問題的重點就是怎樣去尋找和你比較相似的使用者,怎麼將那些鄰居的喜好組織成一個排序的目錄給你,要實現一個協同過濾的系統,需要以下幾個步驟:
1.收集使用者的愛好
2.找到相似的使用者或者物品
3.計算推薦
在收集使用者的喜歡方面,一般的方式有評分,投票,轉發,儲存書籤,點選連線等等 ,有了使用者的喜好之後,就可以通過這些共同的喜好來計算使用者之間的相似度了。
2.相似度計算
相似度的計算一般是基於向量的,可以將一個使用者對所有的物品的偏好作為一個向量來計算使用者之間的相似度,或者將所有使用者對於某一個物品的偏好作為一個向量計算物品之間的相似度,相似度的計算有下列幾種方式:
計算歐幾里得距離:
利用歐幾里得距離計算相似度時,將相似度定義如下:
皮爾遜相關係數:
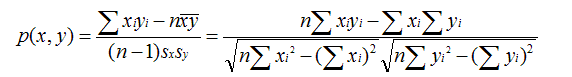
其中sx,sy表示x和y的標準差。
Cosine相似度:

Tanimoto係數,也稱作Jaccard係數:

3.計算推薦
要計算推薦的話必須先要找到和你最相似的使用者,這裡我們用鄰居表示與你最為相似的使用者。相似使用者的計算可能有很多,在實際中我們會給出一個數字K表示和你最為相似的使用者。在計算相似度的時候,理論上要計算你與所有使用者的相似度,但是當資料量比較大的時候,這樣做是很費時間的 ,資料集中可能有很多使用者和你是沒有關係的,在計算是完全是沒有必要的,所以需要物品到使用者的反查表,也就是沒一件物品對應的使用者資訊,有了這個表,就可以過濾掉很多和你沒有關係的使用者,減少計算量。
計算出了所有的鄰居之後,是不是要將你所有鄰居的所有商品推薦給你呢,當然不是了。假設每一個商品的權重為1,計算得到A使用者和你的相似度為0.2,B使用者和你的相似度為0.7,那麼可以將AB使用者的所有商品乘以他們對應的相似度大小,得到每一個物品的推薦度大小,比方說A中的商品有a,b,c,B中的商品有c,d,那麼a商品的推薦程度就是
0.2,b商品的推薦程度就是0.2.c對應的推薦程度就是1*0.2+1*0.7=0.9,d的推薦度就是0.7,所以在推薦的時候,優先把c推薦給你,其次是d。
總結來說,推薦的過程就是先計算使用者之間的相似度,根據相似度的高低選取前K個使用者,在這K個使用者中計算沒一件物品的推薦程度。
4.實驗過程
針對上面的過程,我們將在MovieLens(http://movielens.org)資料集上進行實驗,在實驗中,我們主要利用到的資料集中的兩個檔案u.data和u.item,其中u.item中記錄的是電影的相關資訊,u.data中主要是使用者對電影的評分資訊,評分的範圍是1-5,檔案的每一列分別表示使用者ID,電影ID,評分,時間戳。實驗主要參考這裡
import math
from texttable import Texttable
def calcSimlaryCosDist(user1, user2):
sum_x = 0.0
sum_y = 0.0
sum_xy = 0.0
avg_x = 0.0
avg_y = 0.0
for key in user1:
avg_x += key[1]
avg_x = avg_x / len(user1)
for key in user2:
avg_y += key[1]
avg_y = avg_y / len(user2)
for key1 in user1:
for key2 in user2:
if key1[0] == key2[0]:
sum_xy += (key1[1] - avg_x) * (key2[1] - avg_y)
sum_y += (key2[1] - avg_y) * (key2[1] - avg_y)
sum_x += (key1[1] - avg_x) * (key1[1] - avg_x)
if sum_xy == 0.0:
return 0
sx_sy = math.sqrt(sum_x * sum_y)
return sum_xy / sx_sy
def readFile(file_name):
f=open(file_name,"r",encoding='utf-8')
line=[]
line=f.readlines()
f.close()
return line
#讀取電影資訊,返回電影的字典,key值為電影ID,value值為電影資訊
def getMoviesList(file_name):
lines=readFile(file_name)
movie_info={}
for movie in lines:
arr=movie.split("|")
movie_info[int(arr[0])]=arr[1:]
return movie_info
#將rating檔案中的資訊轉化為陣列格式
#返回使用者ID,電影ID,評分,時間戳的格式
def getRatingInformation(ratings):
r=[]
for line in ratings:
rate=line.split('\t')
r.append([int(rate[0]),int(rate[1]),int(rate[2])])
return r
#生成使用者評分的資料結構
#輸入:[[2,1,5],[2,4,2]...],使用者2對電影1的評分是5分
#輸出:使用者打分字典和電影與值打分關聯使用者的字典
#rate_dic[2]=[(1,5),(4,2)].... 表示使用者2對電影1的評分是5,對電影4的評分是2
def createUserRankDic(rates):
user_rate_dict={}
item_to_user={}
for i in rates:
user_rank=(i[1],i[2])
#使用者和電影評分之間的字典
if i[0] in user_rate_dict:
user_rate_dict[i[0]].append(user_rank)
else:
user_rate_dict[i[0]]=[user_rank]
#每一部電影和與之相關的使用者字典
if i[1] in item_to_user:
item_to_user[i[1]].append(i[0])
else:
item_to_user[i[1]]=[i[0]]
return user_rate_dict,item_to_user
#計算與制定的鄰居之間最為相近的鄰居
#輸入:指定的使用者ID,使用者對電影的評分表,電影對應的使用者表
#輸出:與制定使用者最為相鄰的鄰居列表
# 1.使用者字典:dic[使用者id]=[(電影id,電影評分)...]
# 2.電影字典:dic[電影id]=[使用者id1,使用者id2...]
def calcNearestNeighbor(userid,user_dict,item_dict):
neighbors=[]
for item in user_dict[userid]:
#在每一部電影與之相關的使用者中查詢鄰居
for neighbor in item_dict[item[0]]:
if neighbor!=userid and neighbor not in neighbors:
neighbors.append(neighbor)
#計算相似度並輸出
neighbors_dist=[]
for neighbor in neighbors:
dist=calcSimlaryCosDist(user_dict[userid],user_dict[neighbor])
neighbors_dist.append([dist,neighbor])
neighbors_dist.sort(reverse=True)
return neighbors_dist
def recommendationByUserFC(file_name,userid,k=5):
test_contents=readFile(file_name) #讀取檔案
test_rates=getRatingInformation(test_contents) #得到使用者電影評分之間關係的標準格式
# 格式化成字典資料
# 1.使用者字典:dic[使用者id]=[(電影id,電影評分)...]
# 2.電影字典:dic[電影id]=[使用者id1,使用者id2...]
test_dict,test_item_to_user=createUserRankDic(test_rates)
#計算與userid最為相近的前k個使用者,返回陣列的格式為[[相似度,使用者id]...]
neighbors=calcNearestNeighbor(userid,test_dict,test_item_to_user)[:k]
#計算鄰居的每一部電影與被推薦使用者之間的相似度大小
recommend_dict={}
for neighbor in neighbors:
neighbor_user_id=neighbor[1] #鄰居使用者的ID
movies=test_dict[neighbor_user_id] #鄰居使用者對電影的評分列表
#計算每一部電影對使用者的推薦程度大小
for movie in movies:
if movie[0] not in recommend_dict:
recommend_dict[movie[0]]=neighbor[0]
else:
recommend_dict[movie[0]]+=neighbor[0]
#建立推薦的列表
recommend_list=[]
for key in recommend_dict:
recommend_list.append([recommend_dict[key],key]) #將字典轉化為list,其中元素的第一項為推薦程度大小,第二項為電影的ID
recommend_list.sort(reverse=True) #根據推薦的程度大小進行排序
user_movies=[i[0] for i in test_dict[userid]] #userid使用者評分過的所有電影
return [i[1] for i in recommend_list], user_movies, test_item_to_user, neighbors
if __name__=='__main__':
movies=getMoviesList('u.item') #獲取電影的列表
recommend_list, user_movie, items_movie, neighbors = recommendationByUserFC('u.data',1,80)
neighbors_id=[i[1] for i in neighbors] #所有鄰居的ID
table = Texttable()
table.set_deco(Texttable.HEADER)
table.set_cols_dtype(['t', # text
't', # float (decimal)
't']) # automatic
table.set_cols_align(["l", "l", "l"])
rows = []
rows.append([u"movie name", u"release", u"from userid"])
#輸出前20個推薦項
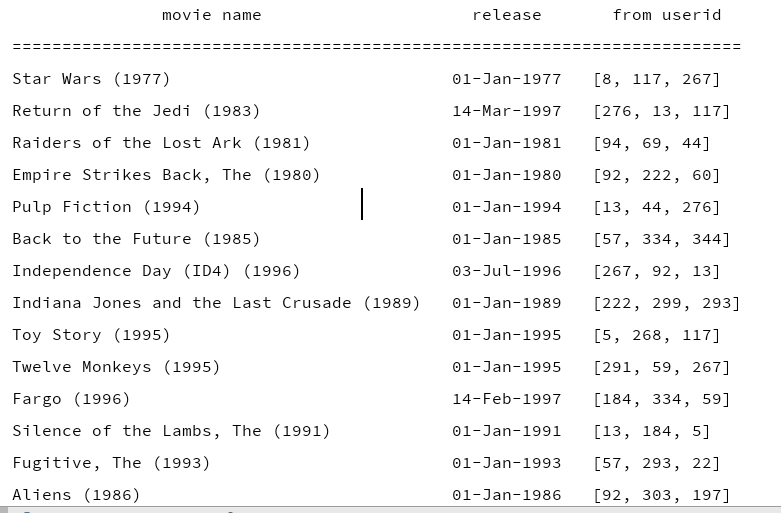
for movie_id in recommend_list[:20]:
from_user = []
for user_id in items_movie[movie_id]:
if user_id in neighbors_id:
from_user.append(user_id)
rows.append([movies[movie_id][0], movies[movie_id][1], from_user[:3]])
table.add_rows(rows)
print (table.draw())
4.參考文章
http://www.ibm.com/developerworks/cn/web/1103_zhaoct_recommstudy2/index.html
http://blog.csdn.net/ygrx/article/details/15501679