
模型評估與選擇(中篇)-ROC曲線與AUC曲線

P-R曲線
以二分類問題為例進行說明。分類結果的混淆矩陣如下圖所示。
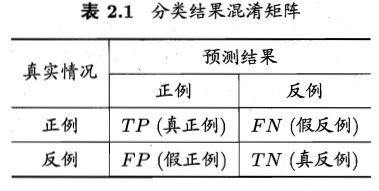
假設,現在我們用某一演算法h對樣本進行二分類(劃分為正例、反例)。由於演算法可能與理想方法存在誤差,因此在劃分結果中,劃分為正例的那部分樣本中,可能存在正例,也可能存在反例。同理,在劃分為反例的那部分樣本中,也可能存在這樣的誤差。因此,我們需要定義一些指標來衡量我們的演算法的好壞程度。下面是兩個是目前常用的指標——查準率、查全率。
查準率P定義為:
查全率R定義為:
P-R曲線,即基於這兩個指標對演算法進行直觀衡量。
下面根據我的理解,談一下P-R曲線是如何做出來的。
假設,我們的資料集包含n個樣本
假設,我們將閾值設得很高,開始時,只認為
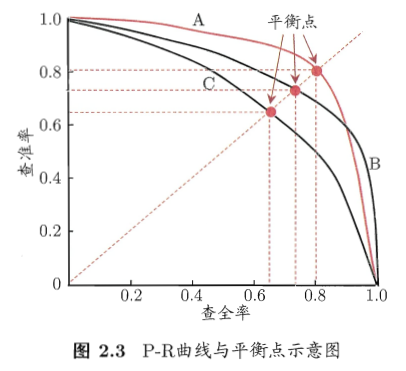
從圖上所示,不同的演算法,對應著不同的P-R曲線。如圖所示,我們有A,B,C三條曲線。通常,我們認為如果一條曲線甲,能夠被另一條曲線乙包住,則認為乙的效能優於甲。因為如果我們的演算法h是最接近真實演算法的條件下,在不斷調整閾值
在圖2.3上,就是曲線B的效能要高於曲線C。但是A和B發生了交叉,所以不能判斷出A、B之間哪個演算法更優。
比較兩個分類器好壞時,顯然是查得又準又全的比較好,也就是的PR曲線越往座標(1,1)的位置靠近越好。因此,在圖上標記了“平衡點(Break-Even Point,簡稱
ROC曲線
roc曲線:受試者操作特徵(Receiver Operating Characteristic),roc曲線上每個點反映著對同一訊號刺激的感受性。
對於0,1兩類分類問題,一些分類器得到的結果往往不是0,1這樣的標籤,如神經網路,得到諸如0.5,0,8這樣的分類結果。這時,我們人為取一個閾值,比如0.4,那麼小於0.4的為0類,大於等於0.4的為1類,可以得到一個分類結果。同樣,這個閾值我們可以取0.1,0.2等等。取不同的閾值,得到的最後的分類情況也就不同。
如下面這幅圖:
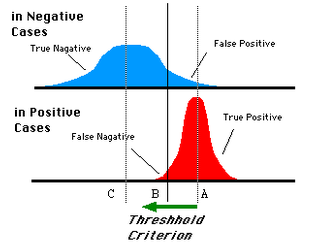
藍色表示原始為負類分類得到的統計圖,紅色為正類得到的統計圖。那麼我們取一條直線,直線左邊分為負類,右邊分為正,這條直線也就是我們所取的閾值。
閾值不同,可以得到不同的結果,但是由分類器決定的統計圖始終是不變的。這時候就需要一個獨立於閾值,只與分類器有關的評價指標,來衡量特定分類器的好壞。
還有在類不平衡的情況下,如正樣本90個,負樣本10個,直接把所有樣本分類為正樣本,得到識別率為90%。但這顯然是沒有意義的。
如上就是ROC曲線的動機。
關於兩類分類問題,分類混淆矩陣如下:
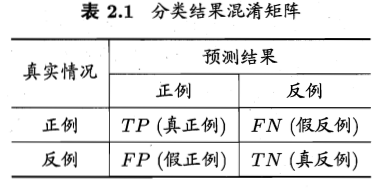
於是我們得到四個指標,分別為真正例,假正例;假反例,真反例。
ROC空間將假正例率(False Positive Rate, 簡稱FPR)定義為 X軸,真正例率(True Positive Rate, 簡稱TPR)定義為 Y 軸。這兩個值由上面四個值計算得到,公式如下:
TPR:在所有實際為正例的樣本中,被正確地判斷為正例之比率。
FPR:在所有實際為反例的樣本中,被錯誤地判斷為正例之比率。
放在具體領域來理解上述兩個指標。
如在醫學診斷中,判斷有病的樣本。
那麼儘量把有病的揪出來是主要任務,也就是第一個指標TPR,要越高越好。
而把沒病的樣本誤診為有病的,也就是第二個指標FPR,要越低越好。
不難發現,這兩個指標之間是相互制約的。如果某個醫生對於有病的症狀比較敏感,稍微的小症狀都判斷為有病,那麼他的第一個指標應該會很高,但是第二個指標也就相應地變高。最極端的情況下,他把所有的樣本都看做有病,那麼第一個指標達到1,第二個指標也為1。
我們以FPR為橫軸,TPR為縱軸,得到如下ROC空間。
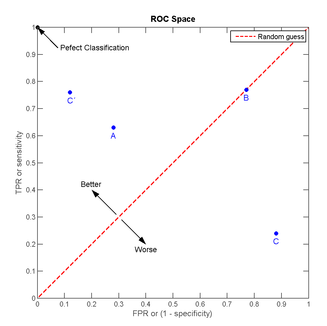
我們可以看出,左上角的點
上圖中一個閾值,得到一個點。現在我們需要一個獨立於閾值的評價指標來衡量這個醫生的醫術如何,也就是遍歷所有的閾值,得到ROC曲線。
還是一開始的那幅圖,假設如下就是某個醫生的診斷統計圖,直線代表閾值。我們遍歷所有的閾值,能夠在ROC平面上得到如下的ROC曲線。
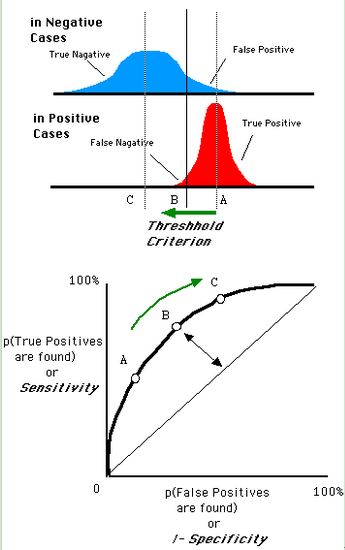
曲線距離左上角越近,證明分類器效果越好。
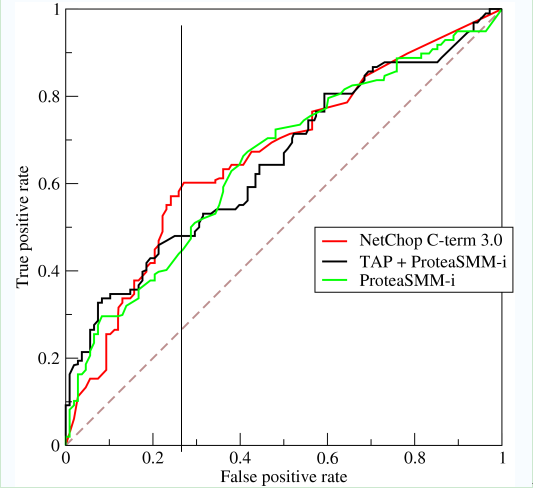
如上,是三條ROC曲線,在0.23處取一條直線。那麼,在同樣的低FPR=0.23的情況下,紅色分類器得到更高的PTR。也就表明,ROC越往上,分類器效果越好。我們用一個標量值AUC來量化他。
附加說明:
從表2.1可以看到,真正例率和假正例率的分母,就是真實的正例個數,和反例個數。對一組資料
在某一演算法
相關推薦
模型評估與選擇(中篇)-ROC曲線與AUC曲線
P-R曲線 以二分類問題為例進行說明。分類結果的混淆矩陣如下圖所示。 假設,現在我們用某一演算法h對樣本進行二分類(劃分為正例、反例)。由於演算法可能與理想方法存在誤差,因此在劃分結果中,劃分為正例的那部分樣本中,可能存在正例,也可能存在反例。同理,
西瓜書《機器學習》學習筆記 二 模型評估與選擇(二) 效能度量 ROC AUC...
目錄 3、效能度量(performance measure) 衡量模型泛化能力的評價標準,就是效能度量。 效能度量 <————> 任務需求 在對比不同模型的“好壞”時,使用不同的效能度量往往會導致不同的結果,這也意味著模型的好壞是相
3D模型體素化(Voxelization)過程實現與分析
體素化方法 體素化能夠對模型進行簡化,得到均勻的網格,在求模型的測地線,求交等過程中有較好的應用。個人理解,把體素化分為基於CPU的方法和基於GPU渲染的方法。輸入是三角面片,輸出體素化格子。 基於CPU的體素化方法 體素化無非是對模型所在空
Spring Boot 揭秘與實戰(八) 發布與部署 - 遠程調試
hat artifact pom.xml href span 發布 作者 elf ava 文章目錄 1. 依賴 2. 部署 3. 調試 4. 源代碼 設置遠程調試,可以在正式環境上隨時跟蹤與調試生產故障。 依賴 在 pom.xml 中增加遠程調試依賴。 <pl
KCF:High-Speed Tracking with Kernelized Correlation Filters 的翻譯與分析(一)。分享與轉發請註明出處-作者:行於此路
High-Speed Tracking with Kernelized Correlation Filters 的翻譯與分析 基於核相關濾波器的高速目標跟蹤方法,簡稱KCF 寫在前面,之所以對這篇文章進行精細的閱讀,是因為這篇文章極其重要,在目標跟蹤領域石破天驚的一篇論文,
資料結構與演算法(一)--- 資料結構與演算法概念
一、資料結構 資料結構是計算機儲存、組織資料的方式。(資料結構是指資料與資料之間的關係。) 資料結構是指相互之間存在一種或多種特定關係的資料元素的集合。通常情況下,精心選擇的資料結構可以帶來更高的執行或者儲存效率。資料結構往往同高效的檢索演算法和索引技術有關。
演算法設計與分析(一)——遞迴與分治
目錄 D、走迷宮 提示: 提示: NOJ 2018.9.21 A、二分查詢 時限:1000ms 記憶體限制:10000K 總時限:3000ms 描述 給定一個單調遞增的整數序列,問某個整數是否在序列中。 輸入
資料結構與演算法(3)- C++ STL與java se中的vector
宣告:雖然本系列部落格與具體的程式語言無關。但是本文作者對c++相對比較熟悉,其次是java,所以難免會有視角上的偏差。舉例也大多是和這兩門語言相關。 上一篇部落格概念性的介紹了vector,我們有了大致的印象:vector不過就是看上去可以自增長的陣列麼。這篇部落格將稍微
ArcGIS API for JavaScript 實戰與解析(一):簡介與快速上手
在這篇文章之前廢話幾句。 自從過完十一假期,每天都在奔波和加班中度過,直到今天才真正能夠休息。隱約記得去年是同樣的情形,但並不是相同的事由,希望明年十月對我好一點。 從二月到十月的八個月裡,我幾乎每天都堅持學習,從程式語言、軟體開發到機器學習、WebGIS,還有
攔截器(Interceptor)與過濾器(Filter)的區別與使用
Filter:過濾器 Interceptor:攔截器 過濾從客戶端向伺服器傳送的請求。(既可攔截Action,也可攔截靜態資源,如:html、css、js、圖片等) 攔截是客戶端對Actio
矩陣分析與應用(二)——內積與範數
常數向量的內積與範數 兩個m×1的向量之間的內積(點積)定義為: ⟨x,y⟩=xHy=∑i=1mx∗iyi 其夾角定義為: cosθ=⟨x,y⟩⟨x,x⟩⟨y,y⟩−−−−−−−−−√=
詳解c++ 引用(reference)與 指標(pointer)的區別與聯絡
引用(reference) 與指標(pointer)之間有什麼區別和聯絡呢?我相信,對於很多初學c++的程式猿來說,不是一件簡單的事.那麼在c++中,引用與指標到底有什麼聯絡和區別呢?要弄清楚這個問題,我們必須明白 : 1.什麼是引用? 2.怎樣使用引用?
深度學習框架TensorFlow學習與應用(五)——TensorBoard結構與視覺化
一、TensorBoard網路結構 舉例: import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data #載入資料集 mnist=input_dat
(Stanford CS224d) Deep Learning and NLP課程筆記(三):GloVe與模型的評估
本節課繼續講授word2vec模型的演算法細節,並介紹了一種新的基於共現矩陣的詞向量模型——GloVe模型。最後,本節課重點介紹了word2vec模型評估的兩種方式。 Skip-gram模型 上節課,我們介紹了一個十分簡單的word2vec模型。模型的目標是預測word \(o\)出現在另一個word \(c
決策樹模型組合之隨機森林與GBDT(轉)
get 9.png 生成 代碼 margin ast decision 損失函數 固定 版權聲明: 本文由LeftNotEasy發布於http://leftnoteasy.cnblogs.com, 本文可以被全部的轉載或者部分使用,但請註明出處,如果有問題,請
模型類的設計與實現(四)
介紹 傳遞數據 規則 添加 play using ota 實體類 重要 實體類是現實實體在計算機中的表示。它貫穿於整個架構,負擔著在各層次及模塊間傳遞數據的職責。 一般來說,實體類可以分為“貧血實體類”和“充血實體類”,前者僅僅保存實體的屬性,而後者還包含一些實體間的關系與
Java搜索引擎選擇: Elasticsearch與Solr(轉)
文件格式 article base 使用 社區 run 穩定 tails 定制 Elasticsearch簡介 Elasticsearch是一個實時的分布式搜索和分析引擎。它可以幫助你用前所未有的速度去處理大規模數據。 它可以用於全文搜索,結構化搜索以及分析,當然你也可
windows下的IO模型之選擇(select)模型
工作者線程 dfs read 沒有 應用 ould 設置 spa fine 1.選擇(select)模型:選擇模型:通過一個fd_set集合管理套接字,在滿足套接字需求後,通知套接字。讓套接字進行工作。避免套接字進入阻塞模式,進行無謂的等待。選擇模型的核心的FD_SET集合
windows下的IO模型之異步選擇(WSAAsyncSelect)模型
系列 發送數據 post 使用 寫入 種類 cleanup 標準 過程 異步選擇(WSAAsyncSelect)模型是一個有用的異步I/O 模型。其核心函數是WSAAsyncSelect, (關於異步io的理解詳情可以看:http://www.cnblogs.com/cur
機器學習(二)工作流程與模型調優
發生 較高的 mode lan 包含 因此 增加 絕對值 輸入 上一講中主要描述了機器學習特征工程的基本流程,其內容在這裏:機器學習(一)特征工程的基本流程 本次主要說明如下: 1)數據處理:此部分已經在上一節中詳細討論 2)特征工程:此部分已經在上一節中詳細討論