
自然語言處理2 -- jieba分詞用法及原理
系列文章,請多關注
Tensorflow原始碼解析1 – 核心架構和原始碼結構
帶你深入AI(1) - 深度學習模型訓練痛點及解決方法
自然語言處理1 – 分詞
自然語言處理2 – jieba分詞用法及原理
自然語言處理3 – 詞性標註
自然語言處理4 – 句法分析
自然語言處理5 – 詞向量
自然語言處理6 – 情感分析
1 概述
上篇文章我們分析了自然語言處理,特別是中文處理中,分詞的幾個主要難點。為了解決這些難點,我們提出了基於字串匹配的演算法和基於統計的分詞演算法。針對當前的幾種分詞引擎,我們對其分詞準確度和速度進行了評估。jieba分詞作為一個開源專案,在準確度和速度方面均不錯,是我們平時常用的分詞工具。本文將對jieba分詞的使用方法以及原理進行講解,便於我們在理解jieba分詞原理的同時,加深對前文講解的分詞難點和演算法的理解。
2 jieba分詞用法
jieba分詞是一個開源專案,地址為https://github.com/fxsjy/jieba。它在分詞準確度和速度方面均表現不錯。其功能和用法如下。
2.1 分詞
支援三種分詞模式
- 精確分詞,試圖將句子最精確的切開,適合文字分析
- 全模式,把句子中所有的可以成詞的詞語都掃描出來, 速度非常快,但是不能解決歧義
- 搜尋引擎模式,在精確模式基礎上,對長詞進行再次切分,提高recall,適合於搜尋引擎。
# encoding=utf-8
import jieba
seg_list = jieba.cut("我來到北京清華大學", cut_all= 輸出為
【全模式】: 我/ 來到/ 北京/ 清華/ 清華大學/ 華大/ 大學
【精確模式】: 我/ 來到/ 北京/ 清華大學
【新詞識別】:他, 來到, 了, 網易, 杭研, 大廈 (此處,“杭研”並沒有在詞典中,但是也被Viterbi演算法識別出來了)
【搜尋引擎模式】: 小明, 碩士, 畢業, 於, 中國, 科學, 學院, 科學院, 中國科學院, 計算, 計算所, 後, 在, 日本, 京都, 大學, 日本京都大學, 深造
2.2 新增自定義詞典
主要是為了解決新詞問題,jieba分詞基於HMM演算法會自動識別新詞,但使用者如果能直接給出新詞,則準確率會更高。
使用起來很簡單,我們先建立一個檔案,比如user_dict.txt,其中每一行代表一個新詞,分別為詞語,詞頻,詞性。如下:
創新辦 3 i
雲端計算 5
凱特琳 nz
臺中
然後在程式碼中分詞前,載入這個自定義詞典即可。
jieba.load_userdict("user_dict.txt")
載入自定義詞典的分詞效果:
之前: 李小福 / 是 / 創新 / 辦 / 主任 / 也 / 是 / 雲 / 計算 / 方面 / 的 / 專家 /
載入自定義詞庫後: 李小福 / 是 / 創新辦 / 主任 / 也 / 是 / 雲端計算 / 方面 / 的 / 專家 /
2.3 調整詞典
# 1 使用del_word()使得某個詞語不會出現
>>> print('/'.join(jieba.cut('如果放到post中將出錯。', HMM=False)))
如果/放到/post/中將/出錯/。
>>> jieba.del_word("中將")
>>> print('/'.join(jieba.cut('如果放到post中將出錯。', HMM=False)))
如果/放到/post/中/將/出錯/。
# 2 使用add_word()新增新詞到字典中
>>> print('/'.join(jieba.cut('「臺中」正確應該不會被切開', HMM=False)))
「/臺/中/」/正確/應該/不會/被/切開
>>> jieba.add_word("臺中")
>>> print('/'.join(jieba.cut('「臺中」正確應該不會被切開', HMM=False)))
「/臺中/」/正確/應該/不會/被/切開
# 3 使用suggest_freq()調整某個詞語的詞頻,使得其在設定的詞頻高是能分出,詞頻低時不能分出
>>> jieba.suggest_freq('臺中', True)
69
>>> print('/'.join(jieba.cut('「臺中」正確應該不會被切開', HMM=False)))
「/臺中/」/正確/應該/不會/被/切開
2.4 關鍵詞提取
關鍵詞提取,將文字中最能表達文字含義的詞語抽取出來,有點類似於論文的關鍵詞或者摘要。關鍵詞抽取可以採取:
- 有監督學習:文字作為輸入,關鍵詞作為標註,進行訓練得到模型。此方法難點在於需要大量人工標註
- 無監督學習:先抽取出候選詞,對每個候選詞打分,取出前K個分值高的作為最後的關鍵詞。jieba分詞實現了基於TF-IDF和基於TextRank的關鍵詞抽取演算法。
基於TF-IDF的關鍵詞抽取演算法,目標是獲取文字中詞頻高,也就是TF大的,且語料庫其他文字中詞頻低的,也就是IDF大的。這樣的詞可以作為文字的標誌,用來區分其他文字。
from jieba import analyse
# 引入TF-IDF關鍵詞抽取介面
tfidf = analyse.extract_tags
# 原始文字
text = "執行緒是程式執行時的最小單位,它是程序的一個執行流,\
是CPU排程和分派的基本單位,一個程序可以由很多個執行緒組成,\
執行緒間共享程序的所有資源,每個執行緒有自己的堆疊和區域性變數。\
執行緒由CPU獨立排程執行,在多CPU環境下就允許多個執行緒同時執行。\
同樣多執行緒也可以實現併發操作,每個請求分配一個執行緒來處理。"
# 基於TF-IDF演算法進行關鍵詞抽取
keywords = tfidf(text)
print "keywords by tfidf:"
# 輸出抽取出的關鍵詞
for keyword in keywords:
print keyword + "/",
# 輸出為:
keywords by tfidf:
執行緒/ CPU/ 程序/ 排程/ 多執行緒/ 程式執行/ 每個/ 執行/ 堆疊/ 區域性變數/ 單位/ 併發/ 分派/ 一個/ 共享/ 請求/ 最小/ 可以/ 允許/ 分配/
__基於TextRank的關鍵詞抽取演算法__步驟為,
- 先將文字進行分詞和詞性標註,將特定詞性的詞(比如名詞)作為節點新增到圖中。
- 出現在一個視窗中的詞語之間形成一條邊,視窗大小可設定為2~10之間,它表示一個視窗中有多少個詞語。
- 對節點根據入度節點個數以及入度節點權重進行打分,入度節點越多,且入度節點權重大,則打分高。
- 然後根據打分進行降序排列,輸出指定個數的關鍵詞。
from jieba import analyse
# 引入TextRank關鍵詞抽取介面
textrank = analyse.textrank
# 原始文字
text = "執行緒是程式執行時的最小單位,它是程序的一個執行流,\
是CPU排程和分派的基本單位,一個程序可以由很多個執行緒組成,\
執行緒間共享程序的所有資源,每個執行緒有自己的堆疊和區域性變數。\
執行緒由CPU獨立排程執行,在多CPU環境下就允許多個執行緒同時執行。\
同樣多執行緒也可以實現併發操作,每個請求分配一個執行緒來處理。"
print "\nkeywords by textrank:"
# 基於TextRank演算法進行關鍵詞抽取
keywords = textrank(text)
# 輸出抽取出的關鍵詞
for keyword in keywords:
print keyword + "/",
# 輸出為:
keywords by textrank:
執行緒/ 程序/ 排程/ 單位/ 操作/ 請求/ 分配/ 允許/ 基本/ 共享/ 併發/ 堆疊/ 獨立/ 執行/ 分派/ 組成/ 資源/ 實現/ 執行/ 處理/
2.5 詞性標註
利用jieba.posseg模組來進行詞性標註,會給出分詞後每個詞的詞性。詞性標示相容ICTCLAS 漢語詞性標註集,可查閱網站https://www.cnblogs.com/chenbjin/p/4341930.html
>>> import jieba.posseg as pseg
>>> words = pseg.cut("我愛北京天安門")
>>> for word, flag in words:
... print('%s %s' % (word, flag))
...
我 r # 代詞
愛 v # 動詞
北京 ns # 名詞
天安門 ns # 名詞
2.6 並行分詞
將文字按行分隔後,每行由一個jieba分詞程序處理,之後進行歸併處理,輸出最終結果。這樣可以大大提高分詞速度。
jieba.enable_parallel(4) # 開啟並行分詞模式,引數為並行程序數
jieba.disable_parallel() # 關閉並行分詞模式
2.7 Tokenize:返回詞語在原文的起止位置
result = jieba.tokenize(u'永和服裝飾品有限公司')
for tk in result:
print("word %s\t\t start: %d \t\t end:%d" % (tk[0],tk[1],tk[2]))
# 輸出為
word 永和 start: 0 end:2
word 服裝 start: 2 end:4
word 飾品 start: 4 end:6
word 有限公司 start: 6 end:10
2.8 延遲載入機制
jieba採用延遲載入方式,import jieba 時不會立刻載入jieba詞典,使用時才開始載入。如果想提前載入和初始化,可以手動觸發
import jieba
jieba.initialize() # 手動初始化(可選)
3 jieba分詞原始碼結構
我們分詞的jieba原始碼版本為0.39。程式碼結構如下

主要的模組如下
- 基本API的封裝,在Tokenizer類中,相當於一個外觀類。如cut del_word add_word enable_parallel initialize 等
- 基於字串匹配的分詞演算法,包含一個很大很全的詞典,即dict.txt檔案
- 基於統計的分詞演算法,實現了HMM隱馬爾科夫模型。jieba分詞使用了字串分詞和統計分詞,結合了二者的優缺點。
- 關鍵詞提取,實現了TFIDF和TextRank兩種無監督學習演算法
- 詞性標註,實現了HMM隱馬爾科夫模型和viterbi演算法
4 jieba分詞原理分析
jieba分詞綜合了基於字串匹配的演算法和基於統計的演算法,其分詞步驟為
- 初始化。載入詞典檔案,獲取每個詞語和它出現的詞數
- 切分短語。利用正則,將文字切分為一個個語句,之後對語句進行分詞
- 構建DAG。通過字串匹配,構建所有可能的分詞情況的有向無環圖,也就是DAG
- 構建節點最大路徑概率,以及結束位置。計算每個漢位元組點到語句結尾的所有路徑中的最大概率,並記下最大概率時在DAG中對應的該漢字成詞的結束位置。
- 構建切分組合。根據節點路徑,得到詞語切分的結果,也就是分詞結果。
- HMM新詞處理:對於新詞,也就是dict.txt中沒有的詞語,我們通過統計方法來處理,jieba中採用了HMM隱馬爾科夫模型來處理。
- 返回分詞結果:通過yield將上面步驟中切分好的詞語逐個返回。yield相對於list,可以節約儲存空間。
4.1 初始化
詞典是基於字串匹配的分詞演算法的關鍵所在,決定了最終分詞的準確度。jieba詞典dict.txt是jieba作者採集了超大規模的語料資料,統計得到的。有5M,包含349,046條詞語。每一行對應一個詞語,包含詞語 詞數 詞性三部分。如下
鳳凰寺 22 ns
鳳凰山 311 ns
鳳凰嶺 15 ns
鳳凰嶺村 2 ns
鳳凰木 3 ns
初始化時,先載入詞典檔案dict.txt,遍歷每一行,生成詞語-詞數的鍵值對和總詞數,並將生成結果儲存到cache中,下次直接從cache中讀取即可。程式碼如下,刪除了無關的log列印。只需要看關鍵節點程式碼即可,不提倡逐行逐行閱讀程式碼,最重要的是理解程式碼執行的主要流程和關鍵演算法。
def initialize(self, dictionary=None):
# 獲取詞典路徑
if dictionary:
abs_path = _get_abs_path(dictionary)
if self.dictionary == abs_path and self.initialized:
return
else:
self.dictionary = abs_path
self.initialized = False
else:
abs_path = self.dictionary
with self.lock:
try:
with DICT_WRITING[abs_path]:
pass
except KeyError:
pass
if self.initialized:
return
# 獲取cache_file
default_logger.debug("Building prefix dict from %s ..." % (abs_path or 'the default dictionary'))
t1 = time.time()
if self.cache_file:
cache_file = self.cache_file
# default dictionary
elif abs_path == DEFAULT_DICT:
cache_file = "jieba.cache"
# custom dictionary
else:
cache_file = "jieba.u%s.cache" % md5(
abs_path.encode('utf-8', 'replace')).hexdigest()
cache_file = os.path.join(
self.tmp_dir or tempfile.gettempdir(), cache_file)
# prevent absolute path in self.cache_file
tmpdir = os.path.dirname(cache_file)
# 載入cache_file
load_from_cache_fail = True
if os.path.isfile(cache_file) and (abs_path == DEFAULT_DICT or
os.path.getmtime(cache_file) > os.path.getmtime(abs_path)):
try:
with open(cache_file, 'rb') as cf:
self.FREQ, self.total = marshal.load(cf)
load_from_cache_fail = False
except Exception:
load_from_cache_fail = True
# cache_file不存在或者載入失敗時,載入原始詞典
if load_from_cache_fail:
wlock = DICT_WRITING.get(abs_path, threading.RLock())
DICT_WRITING[abs_path] = wlock
with wlock:
# 載入原始詞典,得到每個詞與其詞數的鍵值對,以及總詞數。單個詞數除以總詞數,即可計算詞頻
self.FREQ, self.total = self.gen_pfdict(self.get_dict_file())
try:
# 儲存載入的原始詞典到cache_file中
fd, fpath = tempfile.mkstemp(dir=tmpdir)
with os.fdopen(fd, 'wb') as temp_cache_file:
marshal.dump(
(self.FREQ, self.total), temp_cache_file)
_replace_file(fpath, cache_file)
except Exception:
try:
del DICT_WRITING[abs_path]
except KeyError:
pass
self.initialized = True
# 載入原始詞典
def gen_pfdict(self, f):
lfreq = {}
ltotal = 0
f_name = resolve_filename(f)
# 遍歷詞典每一行,一行包含一個詞,詞數,以及詞性
for lineno, line in enumerate(f, 1):
try:
line = line.strip().decode('utf-8')
# 取出詞語和它的詞數
word, freq = line.split(' ')[:2]
freq = int(freq)
# 將詞語和它的詞數構造成鍵值對
lfreq[word] = freq
# 計算總詞數,這個是為了以後計算某個詞的詞頻,詞頻越大,則改詞出現的概率越大
ltotal += freq
# 遍歷詞語中的每個字,如果該字沒有出現在詞典中,則建立其詞語-詞數鍵值對,詞數設定為0
for ch in xrange(len(word)):
wfrag = word[:ch + 1]
if wfrag not in lfreq:
lfreq[wfrag] = 0
except ValueError:
raise ValueError(
'invalid dictionary entry in %s at Line %s: %s' % (f_name, lineno, line))
f.close()
# 返回詞語-詞數的鍵值對,以及總詞數
return lfreq, ltotal
初始化可以簡單理解為,讀取詞典檔案,構建詞語-詞數鍵值對,方便後面步驟中查詞典,也就是字串匹配。
4.2. 切分短語
使用漢字正則,切分出連續的漢字和英文字元,形成一段段短語。可以理解為以空格 逗號 句號為分隔,將輸入文字切分為一個個短語,之後會基於一個個短語來分詞。程式碼如下
def cut(self, sentence, cut_all=False, HMM=True):
# 編碼轉換,utf-8或gbk
sentence = strdecode(sentence)
# 根據是否全模式,以及是否採用HMM隱馬爾科夫,來設定正則re_han re_skip,以及cut_block
if cut_all:
re_han = re_han_cut_all
re_skip = re_skip_cut_all
else:
re_han = re_han_default
re_skip = re_skip_default
if cut_all:
cut_block = self.__cut_all
elif HMM:
cut_block = self.__cut_DAG
else:
cut_block = self.__cut_DAG_NO_HMM
# 將輸入文字按照空格 逗號 句號等字元進行分割,生成一個個語句子串
blocks = re_han.split(sentence)
# 遍歷語句子串
for blk in blocks:
if not blk:
continue
if re_han.match(blk):
# 對語句進行分詞
for word in cut_block(blk):
yield word
else:
tmp = re_skip.split(blk)
for x in tmp:
if re_skip.match(x):
yield x
elif not cut_all:
for xx in x:
yield xx
else:
yield x
- 首先進行將語句轉換為UTF-8或者GBK。
- 然後根據使用者指定的模式,設定cut的真正實現。
- 然後根據正則,將輸入文字分為一個個語句。
- 最後遍歷語句,對每個語句單獨進行分詞。
4.3 構建DAG
下面我們來分析預設模式,也就是精確模式下的分詞過程。先來看__cut_DAG方法。
def __cut_DAG(self, sentence):
# 得到語句的有向無環圖DAG
DAG = self.get_DAG(sentence)
# 動態規劃,計算從語句末尾到語句起始,DAG中每個節點到語句結束位置的最大路徑概率,以及概率最大時節點對應詞語的結束位置
route = {}
self.calc(sentence, DAG, route)
x = 0
buf = ''
N = len(sentence)
while x < N:
# y表示詞語的結束位置,x為詞語的起始位置
y = route[x][1] + 1
# 從起始位置x到結束位置y,取出一個詞語
l_word = sentence[x:y]
if y - x == 1:
# 單字,一個漢字構成的一個詞語
buf += l_word
else:
# 多漢字詞語
if buf:
if len(buf) == 1:
yield buf
buf = ''
else:
if not self.FREQ.get(buf):
# 詞語不在字典中,也就是新詞,使用HMM隱馬爾科夫模型進行分割
recognized = finalseg.cut(buf)
for t in recognized:
yield t
else:
for elem in buf:
yield elem
buf = ''
yield l_word
# 該節點取詞完畢,跳到下一個詞語的開始位置
x = y
# 通過yield,逐詞返回上一步切分好的詞語
if buf:
if len(buf) == 1:
yield buf
elif not self.FREQ.get(buf):
recognized = finalseg.cut(buf)
for t in recognized:
yield t
else:
for elem in buf:
yield elem
主體步驟如下
- 得到語句的有向無環圖DAG
- 動態規劃構建Route,計算從語句末尾到語句起始,DAG中每個節點到語句結束位置的最大路徑概率,以及概率最大時節點對應詞語的結束位置
- 遍歷每個節點的Route,組裝詞語組合。
- 如果詞語不在字典中,也就是新詞,使用HMM隱馬爾科夫模型進行分割
- 通過yield將詞語逐個返回。
下面我們來看構建DAG的過程。先遍歷一個個切分好的短語,對這些短語來進行分詞。首先要構建短語的有向無環圖DAG。查詞典進行字串匹配的過程中,可能會出現好幾種可能的切分方式,將這些組合構成有向無環圖,如下圖所示
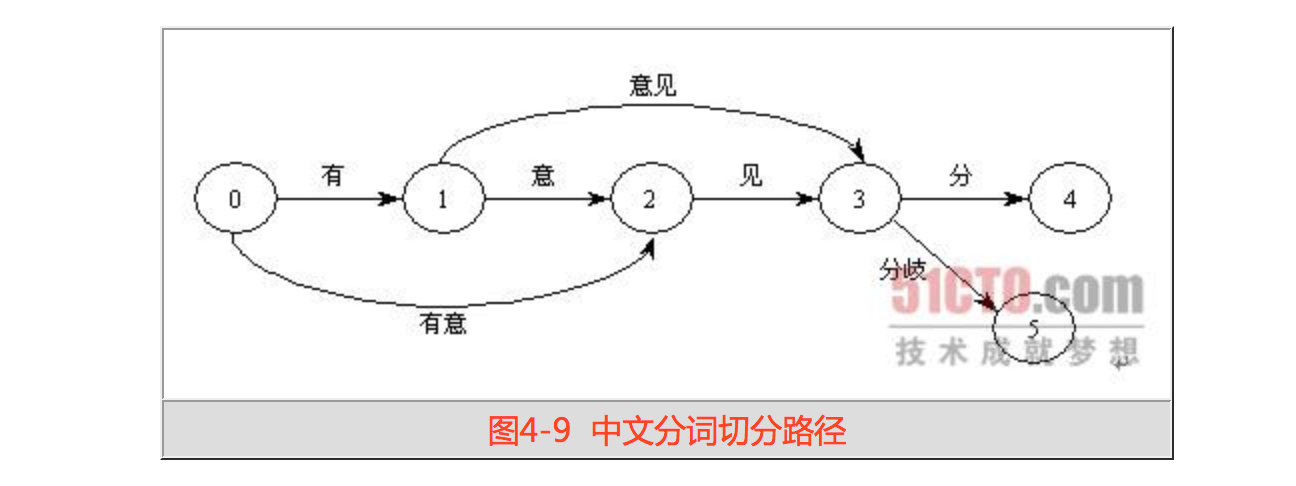
可以看到,構成了兩條路徑:
- 有意/見/分歧
- 有/意見/分歧
DAG中記錄了某個詞的開始位置和它可能的結束位置。開始位置作為key,結束位置是一個list。比如位置0的DAG表達為
{0: [1, 2]}, 也就是說0位置為詞的開始位置時,1,2位置都有可能是詞的結束位置。上面語句的完整DAG為
{
0: [1, 2],
1: [2, 3],
2: [3],
3: [4, 5],
4: [5]
}
DAG構建過程的程式碼如下:
# 獲取語句的有向無環圖
def get_DAG(self, sentence):
self.check_initialized()
DAG = {}
N = len(sentence)
for k in xrange(N):
tmplist = []
i = k
frag = sentence[k]
while i < N and frag in self.FREQ:
if self.FREQ[frag]:
tmplist.append(i)
i += 1
frag = sentence[k:i + 1]
if not tmplist:
tmplist.append(k)
DAG[k] = tmplist
return DAG
4.4 構建節點最大路徑概率,以及結束位置
中文一般形容詞在前面,而相對來說更關鍵的名詞和動詞在後面。考慮到這一點,jieba中對語句,從右向左反向計算路徑的最大概率,這個類似於逆向最大匹配。每個詞的概率 = 字典中該詞的詞數 / 字典總詞數。對於上圖構建每個節點的最大路徑概率的過程如下:
p(5)= 1,
p(4)= max(p(5) * p(4->5)),
p(3)= max(p(4) * p(4->5), p(5) * p(3->5)), # 對於節點3,他有3->4, 3->5兩條路徑,我們取概率最大的路徑作為節點3的路徑概率,並記下概率最大時節點3的結束位置
p(2) = max(p(3) * p(2->
相關推薦
自然語言處理2 -- jieba分詞用法及原理
系列文章,請多關注 Tensorflow原始碼解析1 – 核心架構和原始碼結構 帶你深入AI(1) - 深度學習模型訓練痛點及解決方法 自然語言處理1 – 分詞 自然語言處理2 – jieba分詞用法及原理 自然語言處理3 – 詞性標註 自然語言處理4 – 句法分析 自然語言處理5 –
自然語言處理之jieba分詞
在所有人類語言中,一句話、一段文字、一篇文章都是有一個個的片語成的。詞是包含獨立意義的最小文字單元,將長文字拆分成單個獨立的詞彙的過程叫做分詞。分詞之後,文字原本的語義將被拆分到在更加精細化的各個獨立詞彙中,詞彙的結構比長文字簡單,對於計算機而言,更容易理解和分析,所以,分詞往往是自然
自然語言處理之中文分詞器-jieba分詞器詳解及python實戰
中文分詞是中文文字處理的一個基礎步驟,也是中文人機自然語言互動的基礎模組,在進行中文自然語言處理時,通常需要先進行分詞。本文詳細介紹現在非常流行的且開源的分詞器結巴jieba分詞器,並使用python實
自然語言處理入門----中文分詞原理
1.中文分詞原理介紹
1.1 中文分詞概述
中文分詞(Chinese Word Segmentation) 指的是將一個漢字序列切分成一個一個單獨的詞。分詞就是將連續的字序列按照一定的規範重新組合成詞序列的過程。
1.2 中文分詞方法介紹
現有的分詞方法可分為三大類:基於字串匹配的分
自然語言處理與中文分詞的難點總結
中文自動分詞
指的是使用計算機自動對中文文字進行詞語的切分,即像英文那樣使得中文句子中的詞之間有空格以標識。中文自動分詞被認為是中文自然語言處理中的一個最基本的環節。
中文分詞的難點
· 未登入詞,基於詞庫的分詞方法往往不能識別新詞、特定領域的專有詞。人名、機構名、
自然語言處理之中文分詞器詳解
中文分詞是中文文字處理的一個基礎步驟,也是中文人機自然語言互動的基礎模組,不同於英文的是,中文句子中沒有詞的界限,因此在進行中文自然語言處理時,通常需要先進行分詞,分詞效果將直接影響詞性,句法樹等模組
自然語言處理的中文分詞方法
中文分詞方法
平臺:win7,python,vs2010
1、CRF++
CRF++是著名的條件隨機場開源工具,也是目前綜合性能最佳的CRF工具。
一、工具包的下載:
其中有兩種,一種是Linux下(帶原始碼)的,一種是win32的,下載
ht
自然語言處理之_SentencePiece分詞
1、 說明 SentencePiece是一個google開源的自然語言處理工具包。網上是這麼描述它的:資料驅動、跨語言、高效能、輕量級——面向神經網路文字生成系統的無監督文字詞條化工具。 那麼它究竟是幹什麼的呢?先舉個例子:假設在資料探勘時,有一列特徵T是文字描述,我們需要將其轉
自然語言處理工具pyhanlp分詞與詞性標註
Pyhanlp分詞與詞性標註的相關內容記得此前是有分享過的。可能時間太久記不太清楚了。以下文章是分享自“baiziyu”所寫(小部
自然語言處理之jieba, gensim模塊
src tex tokenize 出現 其中 lambda pip 理論 aid 一,自然語言處理
自然語言處理(NLP) :自然語言處理是計算機科學領域與人工智能領域中的一個重要方向。它研究能實現人與計算機之間用自然語言進行有效通信的各種理論和方法。自然語言處理是一門融
C#自然語言處理2-識別語音並執行程序
程式例項:解析語音,開啟記事本,visual studio或瀏覽器(本例開啟的是chrome)。
可以擴充套件為執行其他任務,修改開啟程序的程式碼即可。
...
public partial class Form1 : Form
{
python自然語言處理——2.1 獲取文字語料庫
微信公眾號:資料運營人本系列為博主的讀書學習筆記,如需轉載請註明出處。
第二章 獲取文字預料和詞彙資源
2.1 獲取文字語料庫古騰堡語料庫網路和聊天文字布朗語料庫路透社語料庫就職演說語料庫標註文字語料庫其他文字語料庫文字語料庫結構
2.1 獲取文字語料庫
一個文字語料庫是一
【python資料處理】jieba分詞
jieba(結巴)是一個強大的分詞庫,完美支援中文分詞
三種分詞模式
import jieba
s = u'我想和女朋友一起去北京故宮博物院參觀和閒逛。'
cut = jieba.cut(s)
#三種模式
print( '【Output】精確模式:')
prin
自然語言處理(NLP) 三:詞袋模型 + 文字分類
1.詞袋模型
(BOW,bag of words)
用詞頻矩陣作為每個樣本的特徵
Are you curious about tokenization ? Let’s see how it works! we need to analyze a coupl
自然語言(NLP)處理流程—IF-IDF統計—jieba分詞—Word2Vec模型訓練使用
開發環境 jupyter notebook
一、資料感知—訓練與測試資料
import numpy as np
import pandas as pd
# 建立輸出目錄
output_dir =
【自然語言處理】python中的jieba分詞使用手冊
這篇文章是轉載的,但是我沒找到出處啊,宣告一下~
jieba
“結巴”中文分詞:做最好的 Python 中文分片語件
"Jieba" (Chinese for "to stutter") Chinese text segmentation: built to b
Python 自然語言處理(基於jieba分詞和NLTK)
----------歡迎加入學習交流QQ群:657341423
自然語言處理是人工智慧的類別之一。自然語言處理主要有那些功能?我們以百度AI為例
從上述的例子可以看到,自然語言處理最基本的功能是詞法分析,詞法分析的功能主要有:
分詞分句
詞語標註
詞法時態
jieba分詞快速入門 自然語言處理
jieba
"結巴"中文分詞:做最好的Python中文分片語件 "Jieba"
Feature
支援三種分詞模式:
精確模式,試圖將句子最精確地切開,適合文字分析;
全模式,把句子中所有的可以成詞的詞語都掃描出來, 速度非常快,但是不能解決歧義;
搜尋引擎模
【自然語言處理入門】01:利用jieba對資料集進行分詞,並統計詞頻
一、基本要求
使用jieba對垃圾簡訊資料集進行分詞,然後統計其中的單詞出現的個數,找到出現頻次最高的top100個詞。
二、完整程式碼
# -*- coding: UTF-8 -*-
fr
自然語言處理學習3:中文分句re.split(),jieba分詞和詞頻統計FreqDist
1. 使用re.split() 分句,re.split(delimiter, text)
import jieba
import re
# 輸入一個段落,分成句子,可使用split函式來實現
paragraph = "生活對我們任何人來說都不容易!我們必須努力,最重要的是