
周志華《Machine Learning》 學習筆記系列(1)
機器學習是目前資訊科技中最激動人心的方向之一,其應用已經深入到生活的各個層面且與普通人的日常生活密切相關。本文為清華大學最新出版的《機器學習》教材的Learning Notes,書作者是南京大學周志華教授,多個大陸首位彰顯其學術奢華。本篇主要介紹了該教材前兩個章節的知識點以及自己一點淺陋的理解。
1 緒論
傍晚小街路面上沁出微雨後的溼潤,和熙的細風吹來,擡頭看看天邊的晚霞,嗯,明天又是一個好天氣。走到水果攤旁,挑了個根蒂蜷縮、敲起來聲音濁響的青綠西瓜,一邊滿心期待著皮薄肉厚瓢甜的爽落感,一邊愉快地想著,這學期狠下了工夫,基礎概念弄得清清楚楚,演算法作業也是信手拈來,這門課成績一定差不了!哈哈,也希望自己這學期的machine learning課程取得一個好成績!
1.1 機器學習的定義
正如我們根據過去的經驗來判斷明天的天氣,吃貨們希望從購買經驗中挑選一個好瓜,那能不能讓計算機幫助人類來實現這個呢?機器學習正是這樣的一門學科,人的“經驗”對應計算機中的“資料”,讓計算機來學習這些經驗資料,生成一個演算法模型,在面對新的情況中,計算機便能作出有效的判斷,這便是機器學習。
另一本經典教材的作者Mitchell給出了一個形式化的定義,假設:
- P:計算機程式在某任務類T上的效能。
- T:計算機程式希望實現的任務類。
- E:表示經驗,即歷史的資料集。
若該計算機程式通過利用經驗E在任務T上獲得了效能P的改善,則稱該程式對E進行了學習。
1.2 機器學習的一些基本術語
假設我們收集了一批西瓜的資料,例如:(色澤=青綠;根蒂=蜷縮;敲聲=濁響), (色澤=烏黑;根蒂=稍蜷;敲聲=沉悶), (色澤=淺自;根蒂=硬挺;敲聲=清脆)……每對括號內是一個西瓜的記錄,定義:
- 所有記錄的集合為:資料集。
- 每一條記錄為:一個例項(instance)或樣本(sample)。
- 例如:色澤或敲聲,單個的特點為特徵(feature)或屬性(attribute)。
- 對於一條記錄,如果在座標軸上表示,每個西瓜都可以用座標軸中的一個點表示,一個點也是一個向量,例如(青綠,蜷縮,濁響),即每個西瓜為:一個特徵向量(feature vector)。
- 一個樣本的特徵數為:維數(dimensionality),該西瓜的例子維數為3,當維數非常大時,也就是現在說的“維數災難”。
在計算機程式學習經驗資料生成演算法模型的過程中,每一條記錄稱為一個“訓練樣本”,同時在訓練好模型後,我們希望使用新的樣本來測試模型的效果,則每一個新的樣本稱為一個“測試樣本”。定義:
- 所有訓練樣本的集合為:訓練集(trainning set),[特殊]。
- 所有測試樣本的集合為:測試集(test set),[一般]。
- 機器學習出來的模型適用於新樣本的能力為:泛化能力(generalization),即從特殊到一般。
在西瓜的例子中,我們是想計算機通過學習西瓜的特徵資料,訓練出一個決策模型,來判斷一個新的西瓜是否是好瓜。可以得知我們預測的是:西瓜是好是壞,即好瓜與差瓜兩種,是離散值。同樣地,也有通過歷年的人口資料,來預測未來的人口數量,人口數量則是連續值。定義:
- 預測值為離散值的問題為:分類(classification)。
- 預測值為連續值的問題為:迴歸(regression)。
在我們預測西瓜是否是好瓜的過程中,很明顯對於訓練集中的西瓜,我們事先已經知道了該瓜是否是好瓜,學習器通過學習這些好瓜或差瓜的特徵,從而總結出規律,即訓練集中的西瓜我們都做了標記,稱為標記資訊。但也有沒有標記資訊的情形,例如:我們想將一堆西瓜根據特徵分成兩個小堆,使得某一堆的西瓜儘可能相似,即都是好瓜或差瓜,對於這種問題,我們事先並不知道西瓜的好壞,樣本沒有標記資訊。定義:
- 訓練資料有標記資訊的學習任務為:監督學習(supervised learning),容易知道上面所描述的分類和迴歸都是監督學習的範疇。
- 訓練資料沒有標記資訊的學習任務為:無監督學習(unsupervised learning),常見的有聚類和關聯規則。
2 模型的評估與選擇
2.1 誤差與過擬合
我們將學習器對樣本的實際預測結果與樣本的真實值之間的差異成為:誤差(error)。定義:
- 在訓練集上的誤差稱為訓練誤差(training error)或經驗誤差(empirical error)。
- 在測試集上的誤差稱為測試誤差(test error)。
- 學習器在所有新樣本上的誤差稱為泛化誤差(generalization error)。
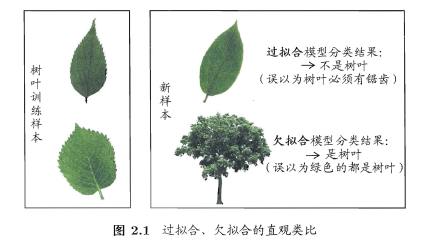
顯然,我們希望得到的是在新樣本上表現得很好的學習器,即泛化誤差小的學習器。因此,我們應該讓學習器儘可能地從訓練集中學出普適性的“一般特徵”,這樣在遇到新樣本時才能做出正確的判別。然而,當學習器把訓練集學得“太好”的時候,即把一些訓練樣本的自身特點當做了普遍特徵;同時也有學習能力不足的情況,即訓練集的基本特徵都沒有學習出來。我們定義:
- 學習能力過強,以至於把訓練樣本所包含的不太一般的特性都學到了,稱為:過擬合(overfitting)。
- 學習能太差,訓練樣本的一般性質尚未學好,稱為:欠擬合(underfitting)。
可以得知:在過擬合問題中,訓練誤差十分小,但測試誤差教大;在欠擬合問題中,訓練誤差和測試誤差都比較大。目前,欠擬合問題比較容易克服,例如增加迭代次數等,但過擬合問題還沒有十分好的解決方案,過擬合是機器學習面臨的關鍵障礙。
2.2 評估方法
在現實任務中,我們往往有多種演算法可供選擇,那麼我們應該選擇哪一個演算法才是最適合的呢?如上所述,我們希望得到的是泛化誤差小的學習器,理想的解決方案是對模型的泛化誤差進行評估,然後選擇泛化誤差最小的那個學習器。但是,泛化誤差指的是模型在所有新樣本上的適用能力,我們無法直接獲得泛化誤差。
因此,通常我們採用一個“測試集”來測試學習器對新樣本的判別能力,然後以“測試集”上的“測試誤差”作為“泛化誤差”的近似。顯然:我們選取的測試集應儘可能與訓練集互斥,下面用一個小故事來解釋why:
假設老師出了10 道習題供同學們練習,考試時老師又用同樣的這10道題作為試題,可能有的童鞋只會做這10 道題卻能得高分,很明顯:這個考試成績並不能有效地反映出真實水平。回到我們的問題上來,我們希望得到泛化效能好的模型,好比希望同學們課程學得好並獲得了對所學知識”舉一反三”的能力;訓練樣本相當於給同學們練習的習題,測試過程則相當於考試。顯然,若測試樣本被用作訓練了,則得到的將是過於”樂觀”的估計結果。
2.3 訓練集與測試集的劃分方法
如上所述:我們希望用一個“測試集”的“測試誤差”來作為“泛化誤差”的近似,因此我們需要對初始資料集進行有效劃分,劃分出互斥的“訓練集”和“測試集”。下面介紹幾種常用的劃分方法:
2.3.1 留出法
將資料集D劃分為兩個互斥的集合,一個作為訓練集S,一個作為測試集T,滿足D=S∪T且S∩T=∅,常見的劃分為:大約2/3-4/5的樣本用作訓練,剩下的用作測試。需要注意的是:訓練/測試集的劃分要儘可能保持資料分佈的一致性,以避免由於分佈的差異引入額外的偏差,常見的做法是採取分層抽樣。同時,由於劃分的隨機性,單次的留出法結果往往不夠穩定,一般要採用若干次隨機劃分,重複實驗取平均值的做法。
2.3.2 交叉驗證法
將資料集D劃分為k個大小相同的互斥子集,滿足D=D1∪D2∪…∪Dk,Di∩Dj=∅(i≠j),同樣地儘可能保持資料分佈的一致性,即採用分層抽樣的方法獲得這些子集。交叉驗證法的思想是:每次用k-1個子集的並集作為訓練集,餘下的那個子集作為測試集,這樣就有K種訓練集/測試集劃分的情況,從而可進行k次訓練和測試,最終返回k次測試結果的均值。交叉驗證法也稱“k折交叉驗證”,k最常用的取值是10,下圖給出了10折交叉驗證的示意圖。
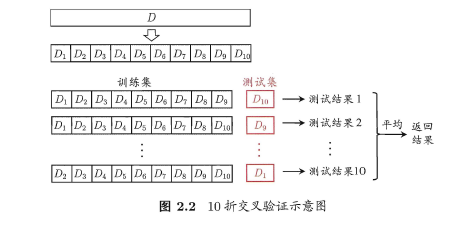
與留出法類似,將資料集D劃分為K個子集的過程具有隨機性,因此K折交叉驗證通常也要重複p次,稱為p次k折交叉驗證,常見的是10次10折交叉驗證,即進行了100次訓練/測試。特殊地當劃分的k個子集的每個子集中只有一個樣本時,稱為“留一法”,顯然,留一法的評估結果比較準確,但對計算機的消耗也是巨大的。
2.3.3 自助法
我們希望評估的是用整個D訓練出的模型。但在留出法和交叉驗證法中,由於保留了一部分樣本用於測試,因此實際評估的模型所使用的訓練集比D小,這必然會引入一些因訓練樣本規模不同而導致的估計偏差。留一法受訓練樣本規模變化的影響較小,但計算複雜度又太高了。“自助法”正是解決了這樣的問題。
自助法的基本思想是:給定包含m個樣本的資料集D,每次隨機從D 中挑選一個樣本,將其拷貝放入D’,然後再將該樣本放回初始資料集D 中,使得該樣本在下次取樣時仍有可能被採到。重複執行m 次,就可以得到了包含m個樣本的資料集D’。可以得知在m次取樣中,樣本始終不被採到的概率取極限為:
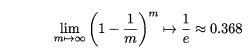
這樣,通過自助取樣,初始樣本集D中大約有36.8%的樣本沒有出現在D’中,於是可以將D’作為訓練集,D-D’作為測試集。自助法在資料集較小,難以有效劃分訓練集/測試集時很有用,但由於自助法產生的資料集(隨機抽樣)改變了初始資料集的分佈,因此引入了估計偏差。在初始資料集足夠時,留出法和交叉驗證法更加常用。
2.4 調參
大多數學習演算法都有些引數(parameter) 需要設定,引數配置不同,學得模型的效能往往有顯著差別,這就是通常所說的”引數調節”或簡稱”調參” (parameter tuning)。
學習演算法的很多引數是在實數範圍內取值,因此,對每種引數取值都訓練出模型來是不可行的。常用的做法是:對每個引數選定一個範圍和步長λ,這樣使得學習的過程變得可行。例如:假定演算法有3 個引數,每個引數僅考慮5 個候選值,這樣對每一組訓練/測試集就有5*5*5= 125 個模型需考察,由此可見:拿下一個引數(即經驗值)對於演算法人員來說是有多麼的happy。
最後需要注意的是:當選定好模型和調參完成後,我們需要使用初始的資料集D重新訓練模型,即讓最初劃分出來用於評估的測試集也被模型學習,增強模型的學習效果。用上面考試的例子來比喻:就像高中時大家每次考試完,要將考卷的題目消化掉(大多數題目都還是之前沒有見過的吧?),這樣即使考差了也能開心的玩耍了~。
相關推薦
周志華《Machine Learning》 學習筆記系列(1)
機器學習是目前資訊科技中最激動人心的方向之一,其應用已經深入到生活的各個層面且與普通人的日常生活密切相關。本文為清華大學最新出版的《機器學習》教材的Learning Notes,書作者是南京大學周志華教授,多個大陸首位彰顯其學術奢華。本篇主要介紹了該教材前兩個章
《機器學習-西瓜書》-周志華-學習筆記系列(1)--序言、前言和主要符號表
寫在前面的話: 自己於今天(2018年9月4日)看完了機器學習-西瓜書-周志華-清華大學出版社書籍,對於這本書的評價就是:好書,自己可以在每一個字裡行間感受到作者的用心,每當看到一個不懂的名詞的時候,作者都會用通俗的例子來講解,遇到公式的時候,也會進行推導,側邊欄的一些說明資訊往往能帶給自己
學習 Machine Learning Mastery With Python (1)
測試套件 實際應用 十分 機器學習 小數 機器學習算法 很多 結果 分鐘 1 介紹 1.1 機器學習的錯誤的想法 一定要對python 編程和python語法非常了解 深入學習scikit learn使用的機器學習算法的理論和參數 避免或者不能接觸實際項目中的其他部分。
C++菜鳥學習筆記系列(6)——簡單標頭檔案的編寫
C++菜鳥學習筆記系列(6) ——簡單標頭檔案的編寫 我們在上一篇部落格 C++菜鳥學習筆記系列(5)中已經敘述了一些關於在C++中建立自己的資料型別的一些方法,但是隨之而來的一個問題是我們在建立了一個自定義類之後經常還要在其他的檔案中使用同樣的類,這時候我們可
C++菜鳥學習筆記系列(9)——迭代器
C++菜鳥學習筆記系列(9) 本期主題:迭代器介紹 我們在C++菜鳥學習筆記系列(7)、C++菜鳥學習筆記系列(8)中分別介紹了C++語言標準庫型別string,vector 的定義及使用。 對於string型別的物件我們可以通過範圍for語句和索引的方式訪問其
C++菜鳥學習筆記系列(12)——算術運算子
C++菜鳥學習筆記系列(12) 本期主題:算術運算子 C++語言為我們提供了一套豐富的運算子,並定義了這些運算子用於內建型別的運算物件時所執行的操作。同時當運算物件時類型別時,C++語言也允許我們指定上述運算子的含義(運算子的過載)。 在介紹後面的算術運算子之前
C++菜鳥學習筆記系列(14)——條件語句
C++菜鳥學習筆記系列(14) 本期主題:條件語句 和其他大多數語言類似的,C++語言也為我們提供了條件執行語句(if、switch)這些都是我們寫程式中最常見也是最常用的語句。在本期的部落格中我們就主要圍繞這兩個語句進行簡單的討論。 在開始之前,我們先了解一下
vim 學習筆記系列(前言)
今天上午的時候,看到大神在用vim程式設計,畫面直觀,速度很快,操作只需要用命令符就可以實施。 所以可以推斷vim的命令符是複雜的,那麼學習過程中記憶會很漫長,很痛苦,但是如果記住了這些命令符,並可
Keras深度學習框架學習筆記系列(2)- Keras的安裝與配置
這裡主要講述Ubuntu16.04環境下Keras的安裝與配置,安裝過程基本上參考了Keras官方中文文件中的安裝說明,由於我只使用了CPU進行加速,因此忽略了CUDA開發環境及相應加速庫的安裝過程,
C++菜鳥學習筆記系列(15)——迭代語句
C++菜鳥學習筆記系列(15) 本期主題:迭代語句(包括while語句、傳統for語句、範圍for語句、do…while語句) 迭代語句就是我們常說的迴圈,它重複執行一些操作直到滿足某個條件才停下來。不同的是while語句和for語句都是在執行迴圈體之前先進行條
Pro Android學習筆記 ActionBar(1):Home圖標區
ces tom 新的 方便 find rac vertica lba manifest ?? Pro Android學習筆記(四八):ActionBar(1):Home圖標區 2013年03月10日 ? 綜合 ? 共 3256字 ? 字號 小 中 大 ? 評論關閉
Machine Learning——octave的操作(1)——DAY2
mil 畫出 基礎上 isp res 增加 rand nbsp span 1.PS1(‘>>’); ——不顯示版本 2.輸出: a=pi; format long format short(4位) disp(sprintf(‘%0.2f’,a)) 3.矩陣的輸入
Vue學習筆記重點(1)
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>todo-list元件版</title> <script
web前端學習(四)JavaScript學習筆記部分(1)-- JavaScript基礎教程
1、JavaScript基礎教程 1.1、Javascript基礎-介紹、實現、輸出 1.1.1、JavaScript是網際網路上最流行的指令碼語言,這門語言可用於web和HTML,更可廣泛用於服務端、pc端、移動端。 1.1.2、JavaScript指令碼語言 JavaScript是一種輕量級的
C++基礎教程面向物件(學習筆記5(1))
建構函式初始化列表 在上一課中的學習過程中,為簡單起見,我們使用賦值運算子在建構函式中初始化了類成員資料。例如: class Something { private: int m_value1; double m_value2; char
MongoDB學習筆記:(1)MongoDB在Win10下的安裝及配置
1. 下載 下載連結: https://www.mongodb.com/download-center?jmp=nav#community 2. 安裝 3. 配置 1. 安裝完的目錄結構 [C:\Program Fil
python學習筆記總結(1)
一.python中的幾種資料型別: 1 Number(數字) 包括int,long,float,complex 2 String(字串) 3 List(列表) 4 Dictionary(字典) 5 Tuple(元組) 6 Bool(布林) 包括True
數字語音訊號處理學習筆記——緒論(1)
版權宣告:本文為博主原創文章,未經博主允許不得轉載。 https://blog.csdn.net/u013538664/article/details/25043707 1.緒論 1.1概述 語言是人類交換資訊最方便、最快捷的一種方式,在高度發達的資訊社會
Unity3D學習筆記————GUI(1)
using System.Collections; using System.Collections.Generic; using UnityEngine; public class GUItest2 : MonoBehaviour { float value; p
C++學習筆記基礎(1)
1,C++與C最大的區別 以前學過一些c語言,現在開始學習C++,我感覺最大的區別就是c++多了一個class的關鍵詞,也就使得c++成為了面向物件的語言,而c語言是面向過程的語言。面向物件的三大特性:封裝,繼承,和多型。 封裝:主要是利用class裡面的訪問級別關鍵字,有