
關於深度學習中卷積核操作
直接舉例進行說明輸出圖片的長和寬。
輸入照片為:32*32*3,
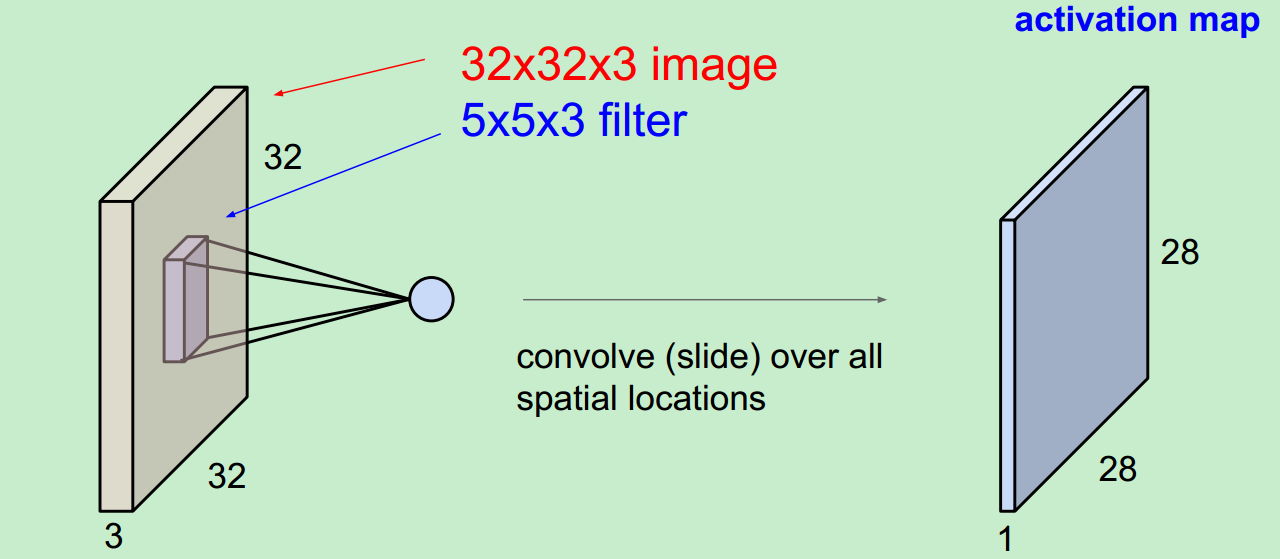
這是用一個Filter得到的結果,即使一個activation map。(filter 總會自動擴充到和輸入照片一樣的depth)。
當我們用6個5*5的Filter時,我們將會得到6個分開的activation maps,如圖所示:
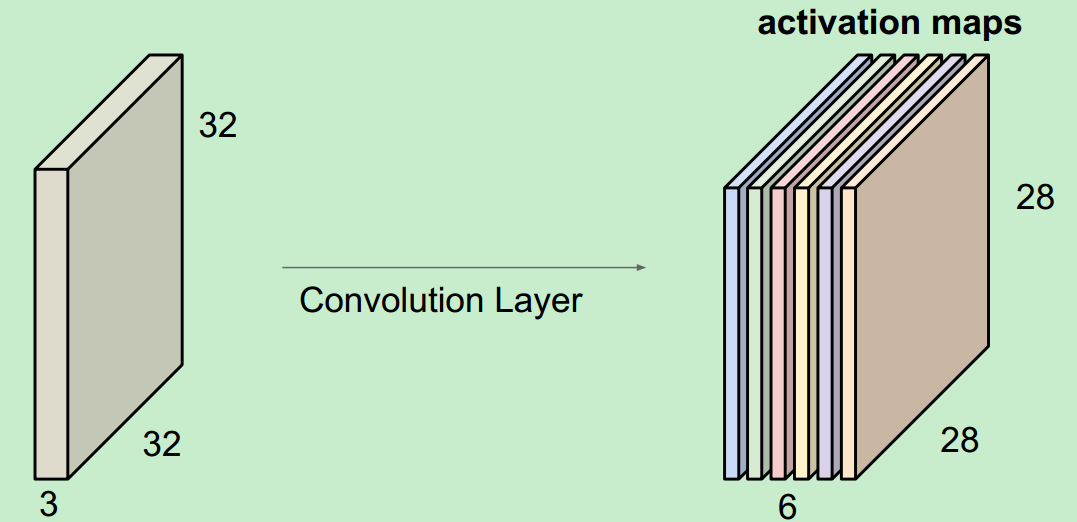
得到的“新照片”的大小為:28*28*6.
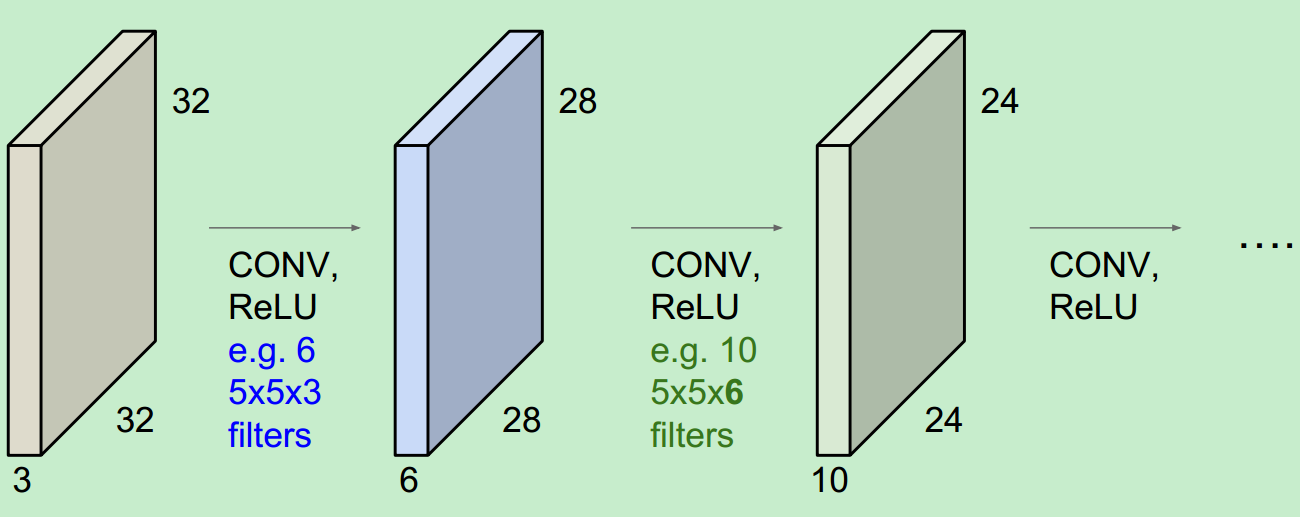
其實,每個卷積層之後都會跟一個相應的啟用函式(activation functions):
微觀上,假設現在input為7*7,Filter尺寸為3*3,output過程如下所示:

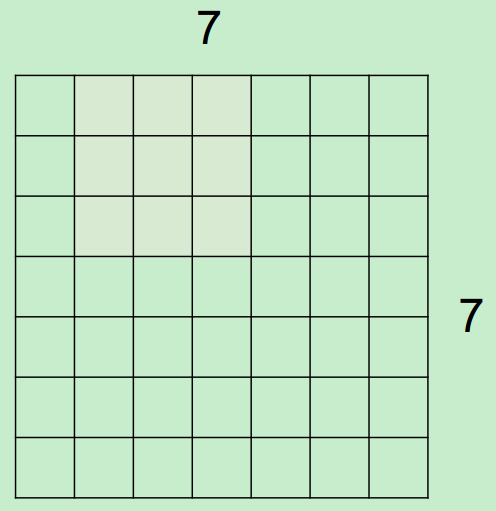
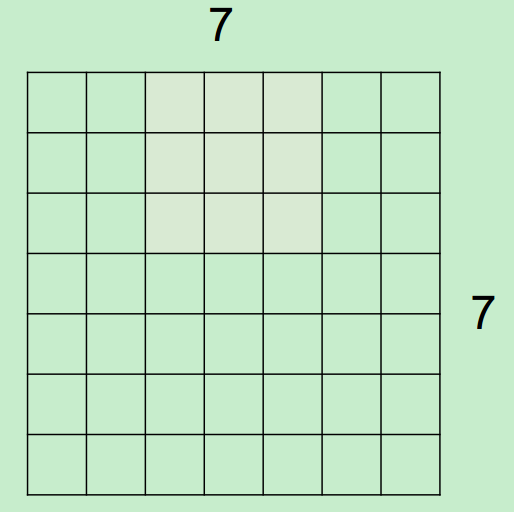
 最終得到一個5*5的output。
最終得到一個5*5的output。
假設,input為7*7,Filter尺寸為3*3,stride(步長)為2,則output過程如下所示:
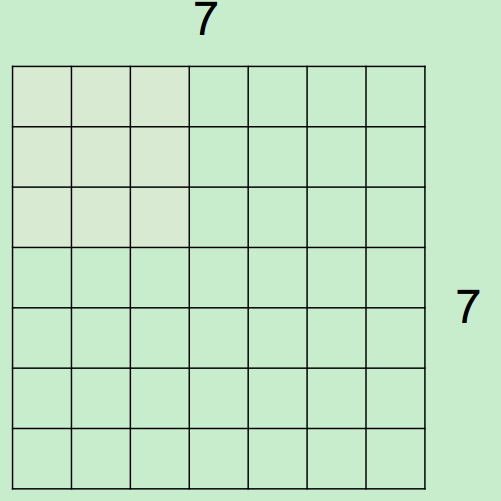
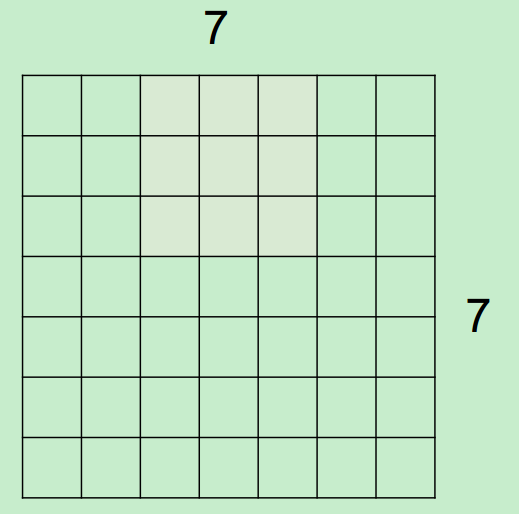
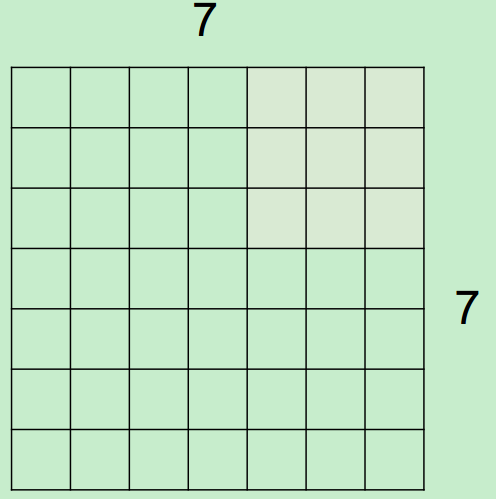 最終得到一個3*3的output。
最終得到一個3*3的output。
注:在這個例子中stride不能為3,因為那樣就越界了。
總的來說
Output size=(N-F)/stride +1
當有填充(pad)時,例如對一個input為7*7進行pad=1填充,Filter為3*3,stride=1,會得到一個7*7的output。
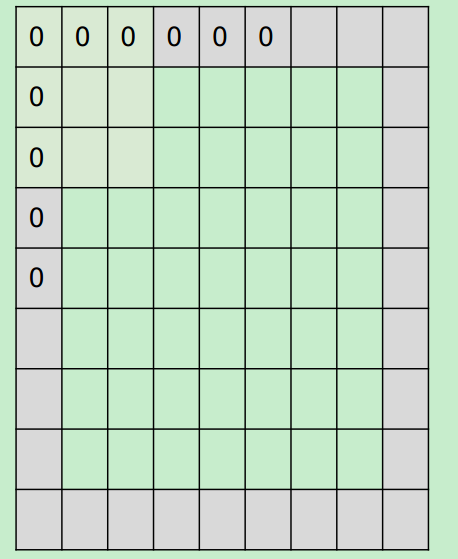
Output size=(N-F+2*pad)/stride +1
注:0填充(pad)的主要目的是因為我們在前面的圖中所示的那樣,一直用5*5的Filter進行卷積,會導致體積收縮的太快,不利於特徵的提取。
舉例說明:

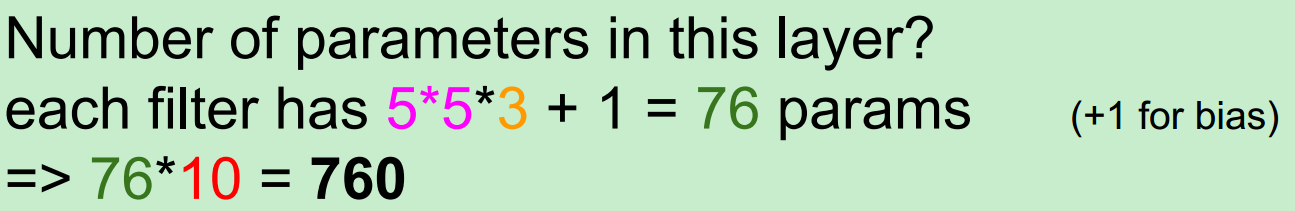
在這裡要注意一下1*1的卷積核,為什麼呢?
舉例:一個56*56*64的input,用32個1*1的卷積核進行卷積(每一個卷積核的尺寸為1*1*64,執行64維的點乘操作),將得到一個56*56*32的output,看到輸出的depth減少了,也就是降維,那麼parameters也會相應的減少。
下面介紹一下Pooling(池化)操作:
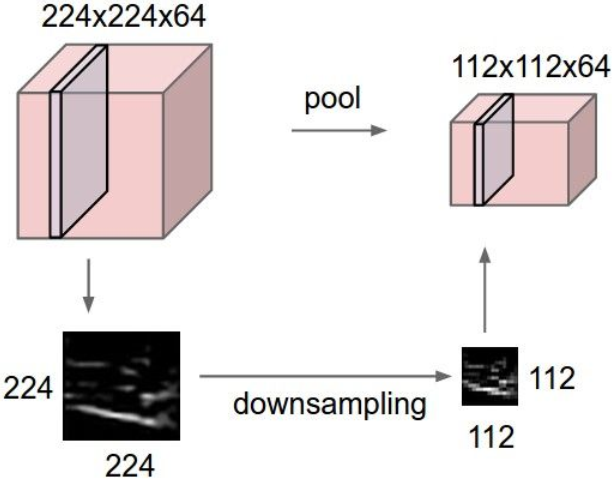
將represention變小,易於操作和控制,對每一個activation map單獨進行操作。
用的最多的是最大池化(MAX POOLING):

Output size=(N-F)/S +1
相關推薦
關於深度學習中卷積核操作
直接舉例進行說明輸出圖片的長和寬。 輸入照片為:32*32*3, 這是用一個Filter得到的結果,即使一個activation map。(filter 總會自動擴充到和輸入照片一樣的depth)。 當我們用6個5*5的Filter時,我們將會得到6個分開的acti
深度學習中卷積核問題
1、卷積核為什麼採用奇數?淺層來看,肯定採用卷積核尺寸採用偶數×偶數的效果比奇數×奇數差。(1)保證了錨點剛好在中間,方便以模組中心為標準進行滑動卷積;(2)考慮padding時,影象的兩邊依然相對稱。2、1×1卷積核的作用(1)可以對影象進行升維操作和降維操作;(2)多個f
深度學習中卷積和池化的總結
深度學習中卷積和池化的總結 涉及到padding的設定:https://www.jianshu.com/p/05c4f1621c7e 以及strides=[batch, height, width, channels]中,第一個、第三個引數必須為1的解釋。http://www.itdaa
深度學習中卷積和池化的一些總結
最近完成了hinton的深度學習課程的卷積和池化的這一章節了,馬上就要結束了。這個課程的作業我寫的最有感受,待我慢慢說來。 1:裡面有幾個理解起來的難點,一個是卷積,可以這麼來理解。 這幅圖是對一個5*5的矩陣A進行3*3的矩陣B的卷積,那麼就從最上角到右下角,生成卷積之
CNN中feature map、卷積核、卷積核個數、filter、channel的概念解釋,以及CNN 學習過程中卷積核更新的理解
feature map、卷積核、卷積核個數、filter、channel的概念解釋 feather map的理解 在cnn的每個卷積層,資料都是以三維形式存在的。你可以把它看成許多個二維圖片疊在一起(像豆腐皮一樣),其中每一個稱為一個feature map。 feather map 是怎
深度學習基礎--卷積--為什麼卷積核時4維的
為什麼卷積核時4維的 因為本來就是4維的,input_channelkernel_sizekernel_size*output_channel 正常來說,引數的個數不是隻和卷積核大小及數量有關嗎,256個1通道的55的卷積核引數應該是256155吧,和輸入的特徵圖數量應該沒有
CNN相關要點介紹(一)——卷積核操作、feature map的含義以及資料是如何被輸入到神經網路中
一、卷積核的定義 下圖顯示了CNN中最重要的部分,這部分稱之為卷積核(kernel)或過濾器(filter)或核心(kernel)。因為TensorFlow官方文件中將這個結構稱之為過濾器(filter),故在本文中將統稱這個結構為過濾器。如下圖1所示,
直觀理解深度學習的卷積操作,超讚!
翻譯 | 於志鵬 趙朋飛 校對 | 翟修川 整理 | 凡江 轉自 | AI研習社 近幾年隨著功能強大的深度學習框架的出現,在深度學習模型中搭建卷積神經網路變得十分容易,甚至只需要一行程式碼就可以完成。 但是理解卷積,特別是對第一次接
深度學習基礎--卷積--1*1的卷積核與全連線的區別
1*1的卷積核與全連線的區別 11的卷積核是輸入map大小不固定的;而全連線是固定的。 11卷積的主要作用有以下兩點: 1)降維( dimension reductionality ),inception中就是這個用。 2)加入非線性,畢竟有啟用
深度學習——深卷積網絡:實例探究
技術分享 模塊 變化 技術 減少 開始 出了 經典 問題: 1. 三個經典網絡 紅色部分不重要,現在已經不再使用 這篇文章較早,比如現在常用max,而當時用avg,當時也沒有softmax 這篇文章讓CV開始重視DL的使用,相對於LeNet-5,它的優點有兩個:更大,使用
深度學習-conv卷積
mage www. dep vol 才有 splay 變換 還要 filter 過濾器(卷積核) 傳統的圖像過濾器算子有以下幾種: blur kernel:減少相鄰像素的差異,使圖像變平滑。 sobel:顯示相鄰元素在特定方向上的差異。 sharpen :強化相鄰像素的差
深度學習之卷積自編碼器
一、自編碼器 自編碼器(Autoencoder)是一種旨在將它們的輸入複製到的輸出的神經網路。他們通過將輸入壓縮成一種隱藏空間表示(latent-space representation),然後這種重構這種表示的輸出進行工作。這種網路由兩部分組成,如下圖: 編碼器:將輸入壓縮為潛在空間
深度學習:卷積,反池化,反捲積,卷積可解釋性,CAM ,G_CAM
憑什麼相信你,我的CNN模型?(篇一:CAM和Grad-CAM):https://www.jianshu.com/p/1d7b5c4ecb93 憑什麼相信你,我的CNN模型?(篇二:萬金油LIME):http://bindog.github.io/blog/2018/02/11/model-ex
深度學習:卷積神經網路,卷積,啟用函式,池化
卷積神經網路——輸入層、卷積層、啟用函式、池化層、全連線層 https://blog.csdn.net/yjl9122/article/details/70198357?utm_source=blogxgwz3 一、卷積層 特徵提取 輸入影象是32*32*3,3是它的深度(即R
深度學習筆記——卷積神經網路
程式碼參考了零基礎入門深度學習(4) - 卷積神經網路這篇文章,我只對程式碼裡可能存在的一些小錯誤進行了更改。至於卷積神經網路的原理以及程式碼裡不清楚的地方可以結合該文章理解,十分淺顯易懂。 import numpy as np from functools import reduce fro
深度學習基礎--卷積神經網路的不變性
卷積神經網路的不變性 不變性的實現主要靠兩點:大量資料(各種資料);網路結構(pooling) 不變性的型別 1)平移不變性 卷積神經網路最初引入區域性連線和空間共享,就是為了滿足平移不變性。 關於CNN中的平移不變性的來源有多種假設。 一個想法是平移不變性
深度學習基礎--卷積--反捲積(deconvolution)
反捲積(deconvolution) 這個概念很混亂,沒有統一的定義,在不同的地方出現,意義卻不一樣。 上取樣的卷積層有很多名字: 全卷積(full convolution), 網路內上取樣( in-network upsampling), 微步幅卷積(fractio
深度學習基礎--卷積--區域性連線層(Locally-Connected Layer)
區域性連線層(Locally-Connected Layer) locally-conv的概念來自傳統ML中的模型初始化(隨機樹方法中每個影象的crop都對應特定的一棵樹)。 引數共享這個策略並不是每個場景下都合適的。有一些特定的場合,我們不能把圖片上的這些視窗資料都視作作用等同
深度學習基礎--卷積--加速的卷積運算
加速的卷積運算 convolution在GPU上如何實現,文中介紹了三種方法 1)最直觀的方法是直接實現(即一般的卷積運算) 缺點:這種實現呢需要處理許多的corner case。 文中介紹cuda-convnet2是實現了該種方法,該種方法在不同取值的卷積引數空間效
深度學習基礎--卷積計算和池化計算公式
卷積計算和池化計算公式 卷積 卷積計算中,()表示向下取整。 輸入:n* c0* w0* h0 輸出:n* c1* w1* h1 其中,c1就是引數中的num_output,生成的特徵圖個數。 w1=(w0+2pad-kernel_size)/stride+1;