
程式設計師的深度學習入門指南
本文根據費良巨集在2016QCon全球軟體開發大會(上海)上的演講整理而成。
今天我想跟大家分享的話題與深度學習有關。事實上,深度學習本身是一個非常龐大的知識體系。今天的內容,不會涉及深度學習的理論知識,更多想從程式設計師的視角出發,讓大家觀察一下深度學習對我們程式設計師意味著什麼,以及我們如何能夠利用這樣一個高速發展的學科,來幫助程式設計師提升軟體開發的能力。
前言
1973年,美國上映了一部熱門的科幻電影叫做《Westworld》,三年之後又有一個續集叫做《Futureworld》。這部電影在80年代初被引進到中國叫《未來世界》。那部電影對我來講簡直可以說得上是震撼。影片中出現了很多機器人,表情豐富的面部下面都是整合電路板。這讓那時候的我覺得未來世界都是那麼遙遠、那麼樣的神祕。時間轉到了2016年,很多朋友可能都在追看HBO斥巨資拍攝的同一個題材的系列劇《Westworld》。如果前兩部電影還是侷限在機器人、人工智慧這樣的話題,2016年的新劇則在劇情、以及對於人工智慧的思考方面有了很大的突破。不再渲染機器人是否會威脅到人類,而是在探討 “Dreams are mainly memories“這一類更具哲理的問題。記憶究竟如何影響了智慧這個話題非常值得我們去思考,也給我們一個很好的啟示 – 今天,人工智慧領域究竟有了怎樣的發展和進步。
今天我們探討的話題不僅僅是簡單的人工智慧。如果大家對深度學習感興趣,我相信各位一定會在搜尋引擎上搜索過類似相關的關鍵字。我在Google上以deep learning作為關鍵字得到了2,630萬個搜尋的結果。這個數字比一週之前足足多出了300多萬的結果。這個數字足以看得出來深度學習相關的內容發展的速度,人們對深度學習的關注也越來越高。

從另外的一個角度,我想讓大家看看深度學習在市場上究竟有多麼熱門。從2011年到現在一共有140多家專注人工智慧、深度學習相關的創業公司被收購。僅僅在2016年這種併購就發生了40多起。其中最瘋狂的是就是Google,已經收購了 11 家人工智慧創業公司,其中最有名的就是擊敗了李世石九段的 DeepMind。排名之後的就要數 Apple、Intel以及Twitter。以Intel 公司為例,僅在今年就已經收購了 3 家創業公司,Itseez、Nervana 和 Movidius。這一系列大手筆的併購為了佈局人工智慧以及深度學習的領域。
當我們去搜索深度學習話題的時候,經常會看到這樣的一些晦澀難懂的術語:Gradient descent(梯度下降演算法)、Backpropagation(反向傳播演算法)、Convolutional Neural Network(卷積神經網路)、受限玻耳茲曼機(Restricted Boltzmann Machine)等等。如你開啟任何一篇技術文章,你看到的通篇都是各種數學公式。大家看到下面左邊的圖,其實並不是一篇高水準的學術論文,而僅僅是維基百科關於玻耳茲曼機的介紹。維基百科是科普層面的內容,內容複雜程度就超過了大多數數學知識的能力。

右邊的那張圖則是深度學習很流行的深度學習框架Theano 的一個簡單的例子。對於大多數程式設計師而言學習這一類框架和程式程式碼的時候更讓人抓狂,大段程式碼我們完全不明就裡。我們看到的很多概念,對很多程式設計師來說覺得非常陌生,所以這確實是對程式設計師的一個很大的挑戰。
在這樣的背景之下,我今天的的話題可以歸納成三點:第一,我們為什麼要學習深度學習;第二,深度學習最核心的關鍵概念就是神經網路,那麼究竟什麼是神經網路;第三,作為程式設計師,當我們想要成為深度學習開發者的時候,我們需要具備怎樣的工具箱,以及從哪裡著手進行開發。
為什麼要學習深度學習
首先我們談談為什麼要學習深度學習。在這個市場當中,最不缺乏的就是各種概念以及各種時髦新技術的詞彙。深度學習有什麼不一樣的地方?我非常喜歡Andrew Ng(吳恩達)曾經用過的一個比喻。他把深度學習比喻成一個火箭。這個火箭有一個最重要的部分,就是它的引擎,目前來看在這個領域裡面,引擎的核心就是神經網路。大家都知道,火箭除了引擎之外還需要有燃料,那麼大資料其實就構成了整個火箭另外的重要組成部分——燃料。以往我們談到大資料的時候,更多是強調儲存和管理資料的能力,但是這些方法和工具更多是對於以往歷史資料的統計、彙總。而對於今後未知的東西,這些傳統的方法並不能夠幫助我們可以從大資料中得出預測的結論。如果考慮到神經網路和大資料結合,我們才可能看清楚大資料真正的價值和意義。Andrew Ng就曾經說過“我們相信(神經網路代表的深度學習)是讓我們獲得最接近於人工智慧的捷徑”。這就是我們要學習深度學習的一個最重要的原因。

其次,隨著我們進行資料處理以及運算能力的不斷提升,深度學習所代表的人工智慧技術和傳統意義上人工智慧技術比較起來,在效能上有了突飛猛進的發展。這主要得益於在過去幾十間計算機和相關產業不斷髮展帶來的成果。在人工智慧的領域,效能是我們選擇深度學習另一個重要的原因。

這是一段Nvidia 在今年公佈的關於深度學習在無人駕駛領域應用的視訊。我們可以看到,將深度學習應用在自動駕駛方面,僅僅經歷了3千英里的訓練,就可以達到什麼樣的程度。在今年年初進行的實驗上,這個系統還不具備真正智慧能力,經常會出現各種各樣的讓人提心吊膽的狀況,甚至在某些情況下還需要人工干預。但經過了3千英里的訓練之後,我們看到在山路、公路、泥地等各種複雜的路況下面,無人駕駛已經有了一個非常驚人的表現。請大家注意,這個深度學習的模型只經過了短短几個月、3千英里的訓練。如果我們不斷完善這種模型的話,這種處理能力將會變得何等的強大。這個場景裡面最重要的技術無疑就是深度學習。我們可以得出一個結論:深度學習可以為我們提供強大的能力,如果程式設計師擁有了這個技術的話,無異於會讓每個程式設計師如虎添翼。
神經網路快速入門
如果我們對於學習深度學習沒有任何疑慮的話,接下來就一定會關心我需要掌握什麼樣的知識才能讓我進入到這個領域。這裡面最重要的關鍵技術就是“神經網路”。說起“神經網路”,容易混淆是這樣兩個完全不同的概念。一個是生物學神經網路,第二個才是我們今天要談起的人工智慧神經網路。可能在座的各位有朋友在從事人工智慧方面的工作。當你向他請教神經網路的時候,他會丟擲許多陌生的概念和術語讓你聽起來雲裡霧裡,而你只能望而卻步了。對於人工智慧神經網路這個概念,大多數的程式設計師都會覺得距離自己有很大的距離。因為很難有人願意花時間跟你分享神經網路的本質究竟是什麼。而你從書本上讀的到的理論和概念,也很讓你找到一個清晰、簡單的結論。
今天就我們來看一看,從程式設計師角度出發神經網路究竟是什麼。我第一次知道神經網路這個概念是通過一部電影—1991年上映的《終結者2》。男主角施瓦辛格有一句臺詞:“My CPU is a neural-net processor; a learning computer.“(我的處理器是一個神經處理單元,它是一臺可以學習的計算機)。從歷史來看人類對自身智力的探索,遠遠早於對於神經網路的研究。1852年,義大利學者因為一個偶然的失誤,將人類的頭顱掉到硝酸鹽溶液中,從而獲得第一次通過肉眼關注神經網路的機會。這個意外加速了人對人類智力奧祕的探索,開啟了人工智慧、神經元這樣概念的發展。
生物神經網路這個概念的發展,和今天我們談的神經網路有什麼關係嗎?我們今天談到的神經網路,除了在部分名詞上借鑑了生物學神經網路之外,跟生物學神經網路已經沒有任何關係,它已經完全是數學和計算機領域的概念,這也是人工智慧發展成熟的標誌。這點大家要區分開,不要把生物神經網路跟我們今天談到的人工智慧有任何的混淆。
神經網路的發展並不是一帆風順的,這中間大概經歷了三起三折的過程。
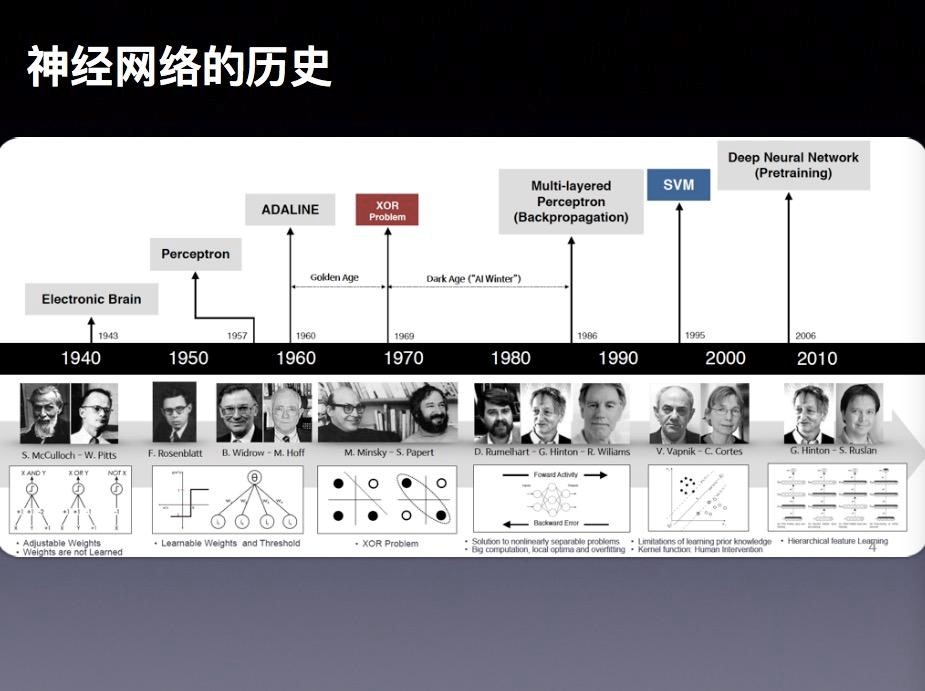
大約在1904年,人類已經對人腦的神經元有了最初步的認識和了解。1943年的時候,心理學家麥卡洛克 (McCulloch) 和數學家 Pitts 參考了生物神經元的結構,發表了抽象的神經元模型M。這個概念的提出,激發了大家對人智力探索的熱情。到了1949年,有一個心理學家赫布(Hebb)提出了著名的Hebb模型,認為人腦神經細胞的突觸上的強度上是可以變化的。於是計算科學家們開始考慮用調整權值的方法來讓機器學習,這就奠定了今天神經網路基礎演算法的理論依據。到了1958年,計算科學家羅森布拉特(Rosenblatt)提出了由兩層神經元組成的神經網路,並給它起了一個很特別的名字—“感知器”(Perceptron)。人們認為這就是人類智慧的奧祕,許多學者和科研機構紛紛投入到對神經網路的研究中。美國軍方也大力資助了神經網路的研究,並認為神經網路是比“曼哈頓工程”更重要的專案。這段時間直到1969年才結束,這個時期可以看作神經網路的一次高潮。事實上感知器只能做簡單的線性分類任務。但是當時的人們熱情太過於高漲,並沒有清醒的認識到這點不足。於是,當人工智慧領域的巨擘明斯基(Minsky)指出個問題的時候,事態就發生了反轉。明斯基指出,如果將計算層增加到兩層,則計算量過大並且缺少有效的學習演算法。所以,他認為研究更深層的網路是沒有價值的。明斯基在1969年出版了一本叫《Perceptron》的書,裡面通過數學證明了感知器的弱點,尤其是感知器對XOR(異或)這樣的簡單分類任務都無法解決。由於明斯基在人工智慧領域的巨大影響力以及書中呈現的明顯的悲觀態度,這很大多數多學者紛紛放棄了對於神經網路的研究。於是神經網路的研究頓時陷入了冰河期。這個時期又被稱為“AI Winter”。將近十年以後,神經網路才會迎來複蘇。
時間到了1986年,Rumelhar和Hinton提出了劃時代的反向傳播演算法(Backpropagation,BP)。這個演算法有效的解決了兩層神經網路所需要的複雜計算量問題,從而帶動了使用兩層神經網路研究的熱潮。我們看到的大部分神經網路的教材,都是在著重介紹兩層(帶一個隱藏層)神經網路的內容。這時候的Hinton 剛剛初露崢嶸,30年以後正是他重新定義了神經網路,帶來了神經網路復甦的又一個春天。儘管早期對於神經網路的研究受到了生物學的很大的啟發,但從BP演算法開始研究者們更多是從數學上尋求問題的最優解,不再盲目模擬人腦網路。這是神經網路研究走向成熟的里程碑的標誌。
90年代中期,由Vapnik等人提出了支援向量機演算法(Support Vector Machines,支援向量機)。很快這個演算法就在很多方面體現出了對比神經網路的巨大優勢,例如:無需調參、高效率、全域性最優解等。基於這些理由,SVM演算法迅速打敗了神經網路演算法成為那個時期的主流。而神經網路的研究則再次陷入了冰河期。
在被人摒棄的十個年頭裡面,有幾個學者仍然在堅持研究。這其中的很重要的一個人就是加拿大多倫多大學的Geoffery Hinton教授。2006年,他的在著名的《Science》雜誌上發表了論文,首次提出了“深度信念網路”的概念。與傳統的訓練方式不同,“深度信念網路”有一個“預訓練”(pre-training)的過程,這可以方便的讓神經網路中的權值找到一個接近最優解的值,之後再使用“微調”(fine-tuning)技術來對整個網路進行優化訓練。這兩個技術的運用大幅度減少了訓練多層神經網路的時間。在他的論文裡面,他給多層神經網路相關的學習方法賦予了一個新名詞— “深度學習”。
很快,深度學習在語音識別領域嶄露頭角。接著在2012年,深度學習技術又在影象識別領域大展拳腳。Hinton與他的學生在ImageNet競賽中,用多層的卷積神經網路成功地對包含一千個類別的一百萬張圖片進行了訓練,取得了分類錯誤率15%的好成績,這個成績比第二名高了將近11個百分點。這個結果充分證明了多層神經網路識別效果的優越性。從那時起,深度學習就開啟了新的一段黃金時期。我們看到今天深度學習和神經網路的火熱發展,就是從那個時候開始引爆的。

可以說在過去十幾年時間裡,圖中這四位學者引領了深度學習發展最。第一位就是Yann LeCun,他曾在多倫多大學隨 Hinton攻讀博士後,現在是紐約大學的教授,同時還是Facebook人工智慧最重要的推動者和科學家。第二位就是是之前我們多次提到的Geoffrey Hinton,現在是Google Brain。第三位是Bengio,他是蒙特利爾大學的教授,他仍然堅持在學術領域裡面不斷探索。Benjio主要貢獻在於他對RNN(遞迴神經網路)的一系列推動。第四位是Andrew Ng(吳恩達),大家在很多媒體上見到過他。上個月他還來到北京參加過一次技術大會。因為他的華人身份更容易被大家接受。在純理論研究上面Andrew Ng 的光芒不如上述三位大牛,甚至可以說有不小的差距,但是在工程方面的應用他仍然是人工智慧領域的權威。
神經網路究竟可以用來幹什麼?神經網路如果放到簡單概念上,可以理解成幫助我們實現一個分類器。對於絕大多數人工智慧需求其實都可以簡化成分類需求。更準確的描述就是絕大多數與智慧有關的問題,都可以歸結為一個在多維空間進行模式分類的問題
例如,識別一封郵件,可以告訴我們這是垃圾郵件或者是正常的郵件;或者進行疾病診斷,將檢查和報告輸入進去實現疾病的判斷。所以說,分類器就是神經網路最重要的應用場景。

究竟什麼是分類器,以及分類器能用什麼方式實現這個功能?簡單來說,將一個數據輸入給分類器,分類器將結果輸出。曾經有人問過這樣一個問題,如果對一個非專業的人士,你如何用通俗表達方法向他介紹神經網路的分類器。有人就用了水果識別做為例子。例如,我非常喜歡吃蘋果,當你看到一個新蘋果,你想知道它是不是好吃是不是成熟,你鑑別的依據是很多年裡你品嚐過的許許多多的蘋果。你會通過色澤、氣味或其它的識別方法加以判斷。這樣判斷過程在深度學習和神經網路裡面,我們就稱之為訓練過的分類器。這個分類器建立完成之後,就可以幫助我們識別食入的每個蘋果是不是成熟。對於傳統的人工智慧方法,例如邏輯迴歸來說,它的決策平面是線性的。所以,這一類的方法一般只能夠解決樣本是線性可分的情況。如果樣本呈現非線性的時候,我們可以引入多項式迴歸。隱層的神經元對原始特徵進行了組合,並提取出來了新的特徵,而這個過程是模型在訓練過程中自動“學習”出來的。
利用神經網路構建分類器,這個神經網路的結構是怎樣的?
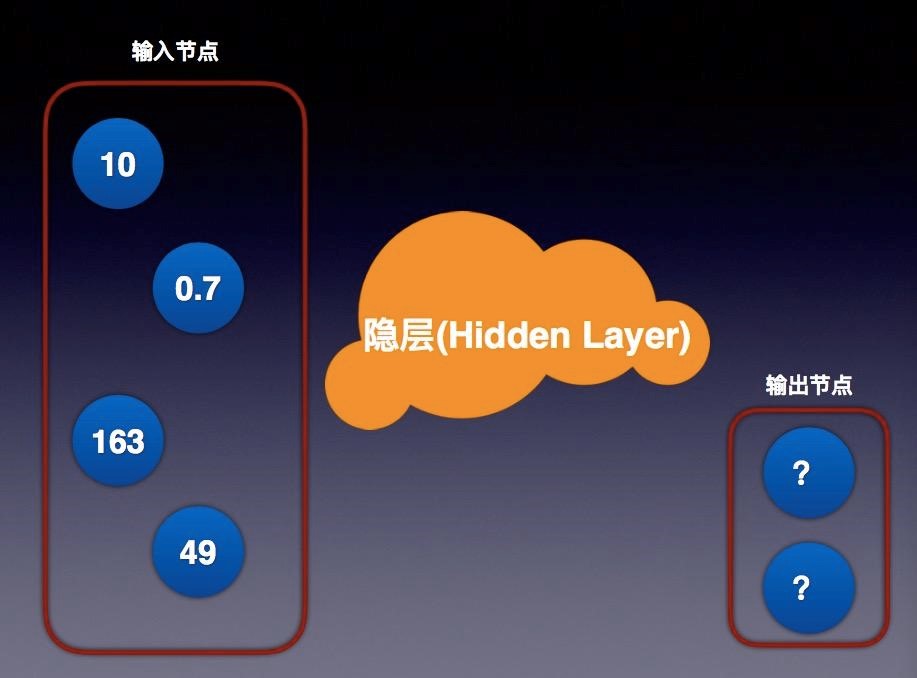
其實這個結構非常簡單,我們看到這個圖就是簡單神經網路的示意圖。神經網路本質上就是一種“有向圖”。圖上的每個節點借用了生物學的術語就有了一個新的名詞 – “神經元”。連線神經元的具有指向性的連線(有向弧)則被看作是“神經”。這這個圖上神經元並不是最重要的,最重要的是連線神經元的神經。每個神經部分有指向性,每一個神經元會指向下一層的節點。節點是分層的,每個節點指向上一層節點。同層節點沒有連線,並且不能越過上一層節點。每個弧上有一個值,我們通常稱之為”權重“。通過權重就可以有一個公式計算出它們所指的節點的值。這個權重值是多少?我們是通過訓練得出結果。它們的初始賦值往往通過隨機數開始,然後訓練得到的最逼近真實值的結果作為模型,並可以被反覆使用。這個結果就是我們說的訓練過的分類器。
節點分成輸入節點和輸出節點,中間稱為隱層。簡單來說,我們有資料輸入項,中間不同的多個層次的神經網路層次,就是我們說的隱層。之所以在這樣稱呼,因為對我們來講這些層次是不可見的。輸出結果也被稱作輸出節點,輸出節點是有限的數量,輸入節點也是有限數量,隱層是我們可以設計的模型部分,這就是最簡單的神經網路概念。
如果簡單做一個簡單的類比,我想用四層神經網路做一個解釋。左邊是輸入節點,我們看到有若干輸入項,這可能代表不同蘋果的RGB值、味道或者其它輸入進來的資料項。中間隱層就是我們設計出來的神經網路,這個網路現在有不同的層次,層次之間權重是我們不斷訓練獲得一個結果。最後輸出的結果,儲存在輸出節點裡面,每一次像一個流向一樣,神經是有一個指向的,通過不同層進行不同的計算。在隱層當中,每一個節點輸入的結果計算之後作為下一層的輸入項,最終結果會儲存在輸出節點上,輸出值最接近我們的分類,得到某一個值,就被分成某一類。這就是使用神經網路的簡單概述。

除了從左到右的形式表達的結構圖,還有一種常見的表達形式是從下到上來表示一個神經網路。這時候,輸入層在圖的最下方,輸出層則在圖的最上方。從左到右的表達形式以Andrew Ng和LeCun的文獻使用較多。而在 Caffe框架裡則使用的則是從下到上的表達。
簡單來說,神經網路並不神祕,它就是有像圖,利用圖的處理能力幫助我們對特徵的提取和學習的過程。2006年Hinton的那篇著名的論文中,將深度學習總結成三個最重要的要素:計算、資料、模型。有了這三點,就可以實現一個深度學習的系統。
程式設計師需要的工具箱
對於程式設計師來說,掌握理論知識是為了更好的程式設計實踐。那就讓我們我們來看看,對於程式設計師來說,著手深度學習的實踐需要準備什麼樣的工具。
硬體
從硬體來講,我們可能需要的計算能力,首先想到的就是CPU。除了通常的CPU架構以外,還出現了附加有乘法器的CPU,用以提升計算能力。此外在不同領域會有DSP的應用場景,比如手寫體識別、語音識別、等使用的專用的訊號處理器。還有一類就是GPU,這是一個目前深度學習應用比較熱門的領域。最後一類就是FPGA(可程式設計邏輯閘陣列)。這四種方法各有其優缺點,每種產品會有很大的差異。相比較而言CPU雖然運算能力弱一些,但是擅長管理和排程,比如讀取資料,管理檔案,人機互動等,工具也豐富。DSP相比而言管理能力較弱,但是強化了特定的運算能力。這兩者都是靠高主頻來解決運算量的問題,適合有大量遞迴操作以及不便拆分的演算法。GPU 的管理能力更弱一些,但是運算能力更強。但由於計算單元數量多,更適合整塊資料進行流處理的演算法。FPGA在管理與運算處理方面都很強,但是開發週期長,複雜演算法開發難度較大。就實時性來說,FPGA是最高的。單從目前的發展來看,對於普通程式設計師來說,現實中普遍採用的計算資源就還是是CPU以及GPU的模式,其中GPU是最熱門的領域。

為什麼是GPU?簡單來說就是效能的表現導致這樣的結果。隨著CPU的不斷髮展,工藝水平逐步提高,我們開始擔心摩爾定律會不會失效。但是GPU的概念橫空出世,NVIDIA 的CEO 黃仁勳得意的宣稱摩爾定律沒有失效。我們看到最近幾年,GPU處理能力的提升是非常驚人的。今年釋出的Nvidia P100的處理能力已經達到令人恐怖的效果。與CPU處理能力做一個對比,雖然CPU的主頻要遠遠高過GPU的主頻,例如目前GPU在主頻在0.5GHz到1.4gHz,處理單元達到3584個;而且最常見的CPU,比如Intel的處理器,大約只有20幾個處理單元。這種差別是僅僅在處理單元的數量上就已經存在了巨大的差別。所以深度學習具備大量處理能力計算要求的情況下,GPU無疑具有非常強大的優勢。

GPU並不是完全完美的方案!對於程式設計師來講,我們也應該瞭解到它天生的不足。相比CPU,它仍然存在許多的侷限。首先,比如:這種技術需要繫結特定的硬體、對程式語言的有一定的限制。簡單來說,開發的靈活性不如CPU。我們習慣的CPU已經幫助我們遮蔽掉處理了許多的硬體上細節問題,而GPU則需要我們直接面對這些底層的處理資源進行程式設計。第二,在GPU領域不同廠商提供了不相容的框架。應用的演算法需要針對特定的硬體進行開發、完善。這也意味著採用了不同框架的應用對於計算環境的依賴。第三,目前GPU是通過PCIe外部配件的方式和計算機整合在一起。眾所周知,PCIe連線的頻寬是很大的瓶頸,PCIe 3.0 頻寬不過7.877 Gbit/s。考慮到計算需求較大的時,我們會使用顯示卡構成GPU的叢集(SLI),這個頻寬的瓶頸對於效能而言就是一個很大的制約。最後,就是有限的記憶體容量的限制。現在Intel新推出的E7處理器的記憶體可以達到2TB。但是對於GPU而言,即使是Nvidia 的 P100 提供有16GB的記憶體,將四塊顯示卡構成SLI(Scalable Link Interface)也只有64GB的視訊記憶體容量。如果你的模型需要較大的記憶體,恐怕就需要做更好的優化才可以滿足處理的需要。這些都是GPU目前的缺陷和不足。我們在著手使用GPU這種技術和資源的時候一定要意識到這一點。
GPU除了硬體上具備了一定的優勢以外,Nvidia還為程式設計師提供了一個非常好的開發框架-CUDA。利用這個程式設計框架,我們通過簡單的程式語句就可以訪問GPUs中的指令集和平行計算的記憶體。對於這個框架下的平行計算記憶體,CUDA提供了統一管理記憶體的能力。這讓我們可以忽略GPU的差異性。目前的編成介面是C語言的擴充套件,絕大多數主流程式語言都可以使用這個框架,例如C/C++、Java、Python以及.NET 等等。
今年的中秋節假期,我為自己DIY了一臺深度學習工作站。起因是我買了一塊GeForce GTX 1070顯示卡,準備做一些深度學習領域的嘗試。因為我的老的電腦上PCIe 2.0 的插槽無法為新的顯示卡供電。不得已之下,只好更新了全部裝置,於是就組裝了一臺我自己的深度學習工作站。這個過程是充滿挑戰的,這並不僅僅是需要熟悉各個部件的裝配。最重要的是要考慮很多細節的的搭配的問題。比如說供電的問題,要計算出每個單元的能耗功率。這裡面又一個重要的指標就是TDP( Thermal Design Power)。Intel 6850K的TDP值是140W,1070顯示卡的值是150W。於是,系統搭配的電源就選擇了650W的主動電源。其次,如果我們用多塊顯示卡(SLI),就必須考慮到系統頻寬的問題。普通的CPU和主機板在這方面有很大侷限。就我的最基本的需求而言我需要的最大的PCI Expres Lanes 是 40。這樣算下來,Intel i7-6850K就是我能找到最便宜而且可以達到要求的CPU了。

我在這兩天的時間裡面,走了很多彎路,所以就想跟大家分享一下我的經驗。
第一,Linux在顯示卡驅動的相容性方面有很多問題。大多數Linux 分發版本提供的 Nvidia顯示卡驅動是一個叫做Nouveau的開源版本的驅動。這個版本是通過逆向工程而開發的,對於新的Nvidia 的技術支援的很不好,所以一定要遮蔽這個驅動。第二,Nvida的驅動以及CUDA合cuDnn 的配置上也有很多搭配的問題。官方的版本只提供了針對特定Linux 分發版本的支援。相比較而言,Ubuntu 16.04 在這方面表現的更出色一些。再有就是CuDNN需要在Nvidia 官網註冊以後才可以下載。第三,Nvidia 的驅動有很多版本。例如Nvidia P100架構的顯示卡需要最新的370版本才能支援,但是官網上可以下載的穩定版本只是367。最後,就是令人煩心的軟體的依賴關係,安裝的順序等等。舉一個例子,在GPU上編譯Tensorflow 是不支援GCC 5.x的版本,只能自行安裝 GCC 4.9並修改編譯選項。另外,Bazel 也會對JDK 的版本有一定的要求。

除了自己去DIY一個深度學習工作站這個選項之外,另外一個選擇就是採用雲端計算環境所提供的計算資源。不久之前 AWS 釋出了最新一款深度學習的EC2例項型別,叫做p2。這個例項的型別使用了NVIDIA 的 K80的GPU,包括三種不同規格,第一種2xlarge,第二種是8xlarge,第三種是16xlarge。以p2.16xlarge為例,提供了16塊K80 GPU ,GPU 視訊記憶體達到了192G,並行處理單元的數量達到了驚人的39,936個。
當你在考慮去開發一個應用、去著手進行深度學習嘗試的時候,我建議大家可以試試這種方式,這個選擇可以很輕鬆的幫助我們計算資源以及硬體上各種麻煩的問題。
這是我前天為這次分享而準備的一個AWS 上p2的例項。僅僅通過幾條命令就完成了例項的更新、驅動的安裝和環境的設定,總共的資源建立、設定時間大概在10分鐘以內。而之前,我安裝除錯前面提到的那臺計算機,足足花了我兩天時間。

另外,從成本上還可以做一個對比。p2.8xLarge 例項每小時的費用是7.2美元。而我自己那臺計算機總共的花費了是¥16,904元。這個成本足夠讓我使用350多個小時的p2.8xLarge。在一年裡使用AWS深度學習站就可以抵消掉我所有的付出。隨著技術的不斷的升級換代,我可以不斷的升級我的例項,從而可以用有限的成本獲得更大、更多的處理資源。這其實也是雲端計算的價值所在。
雲端計算和深度學習究竟有什麼關係?今年的8月8號,在IDG網站上發表了一篇文章談到了這個話題。文章中做了這樣一個預言:如果深度學習的並行能力不斷提高,雲端計算所提供的處理能力也不斷髮展,兩者結合可能會產生新一代的深度學習,將帶來更大影響和衝擊。這個是需要大家考慮和重視的一個方向!
軟體
深度學習除了硬體的基礎環境之外。程式設計師會更關心與開發相關的軟體資源。這裡我羅列了一些自己曾經使用過的軟體框架和工具。

- Scikit-learn是最為流行的一個Python機器學習庫。它具有如下吸引人的特點:簡單、高效且異常豐富的資料探勘/資料分析演算法實現; 基於NumPy、SciPy以及matplotlib,從資料探索性分析,資料視覺化到演算法實現,整個過程一體化實現;開源,有非常豐富的學習文件。
- Caffe專注在卷及神經網路以及影象處理。不過Caffe已經很久沒有更新過了。這個框架的一個主要的開發者賈揚清也在今年跳槽去了Google。也許曾經的霸主地位要讓位給他人了。
- Theano 是一個非常靈活的Python 機器學習的庫。在研究領域非常流行,使用上非常方便易於定義複雜的模型。Tensorflow 的API 非常類似於Theano。我在今年北京的QCon 大會上也分享過關於Theano 的話題。
- Jupyter notebook 是一個很強大的基於ipython的python程式碼編輯器,部署在網頁上,可以非常方便的進行互動式的處理,很適合進行演算法研究合數據處理。
- Torch 是一個非常出色的機器學習的庫。它是由一個比較小眾的lua語言實現的。但是因為LuaJIT 的使用,程式的效率非常出色。Facebook在人工智慧領域主打Torch,甚至現在推出了自己的升級版框架Torchnet。
深度學習的框架非常之多,是不是有一種亂花漸欲迷人眼的感覺?我今天向各位程式設計師重點介紹的是將是TensorFlow。這是2015年穀歌推出的開源的面向機器學習的開發框架,這也是Google第二代的深度學習的框架。很多公司都使用了TensorFlow開發了很多有意思的應用,效果很好。
用TensorFlow可以做什麼?答案是它可以應用於迴歸模型、神經網路以深度學習這幾個領域。在深度學習方面它集成了分散式表示、卷積神經網路(CNN)、遞迴神經網路(RNN) 以及長短期記憶人工神經網路(Long-Short Term Memory, LSTM)。關於Tensorflow 首先要理解的概念就是Tensor。在辭典中對於這個詞的定義是張量,是一個可用來表示在一些向量、標量和其他張量之間的線性關係的多線性函式。實際上這個表述很難理解,用我自己的語言解釋Tensor 就是“N維陣列”而已。

使用 TensorFlow, 作為程式設計師必須明白 TensorFlow這樣幾個基礎概念:它使用圖 (Graph) 來表示計算任務;在被稱之為 會話 (Session) 的上下文 (context) 中執行圖;使用 Tensor 表示資料;通過 變數 (Variable) 維護狀態;使用 feed 和 fetch 可以為任意的操作(arbitrary operation) 賦值或者從其中獲取資料。
一句話總結就是,TensorFlow 就是有狀態圖的資料流圖計算環境,每個節點就是在做資料操作,然後提供依賴性和指向性,提供完整資料流。
TensorFlow安裝非常簡單,但官網提供下載的安裝包所支援的CUDA 的版本是7.5。考慮到CUDA 8 的讓人心動的新特以及不久就要正式釋出的現狀。或許你想會考慮立即體驗CUDA 8,那麼就只能通過編譯Tensorflow原始碼而獲得。目前TensorFlow已經支援了Python2.7、3.3+。此外,對於使用Python 語言的程式設計師還需要安裝所需要的一些庫,例如:numpy、protobuf等等。對於卷積處理而言,cuDNN是公認的效能最好的開發庫,請一定要安裝上。常規的Tensorsorflow的安裝很簡單,一條命令足矣:
$ pip3 install —upgrade https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-0.11.0rc0-cp35-cp35m-linux_x86_64.whl
如果想評估一下或者簡單學習一下,還可以通過Docker進行安裝,安裝的命令如下:
$ docker run -it -p 8888:8888 gcr.io/tensorflow/tensorflow
TensorFlow有很多優點。首先,目前為止,深度學習的開發框架裡面TensorFlow的文件做的最好,對程式設計師學習而言是非常好的一點。第二,TensorFlow有豐富的參考例項,作為參考學習起來非常容易。第三,開發者社群活躍,在任何一個深度學習的社群裡,都有大量關於TensorFlow的討論。第四,谷歌的支援力度非常大,從2015年到現在升級速度非常快,這是其他開源框架遠遠達不到的結果。
參考TensorFlow的白皮書,我們會看到未來TensorFlow還將會有巨大的發展潛力。讓我特別感興趣是這兩個方向。第一,支援跨多臺機器的 parallelisation。儘管在0.8版本中推出了並行化的能力,但是目前還不完善。隨著未來不斷髮展,依託雲端計算的處理能力的提升這個特性將是非常讓人振奮的。第二,支援更多的開發語言,對於開發者來說這是一個絕大的利好,通過使用自己擅長的語言使用TensorFlow應用。這些開發語言將會擴充套件到Java、Lua以及R 等。
在這裡我想給大家展示一個應用Tensorflow 的例子。這個例子的程式碼託管在這個網址上 https://github.com/anishathalye/neural-style。白俄羅斯的現代印象派藝術家Leonid Afremov善於用濃墨重彩來表現都市和風景題材,尤其是其雨景系列作品。他習慣用大色塊的鋪陳來營造光影效果,對反光物體和環境色的把握非常精準。於是我就找到了一張上海東方明珠電視塔的一張攝影作品,我希望通過Tensorflow 去學習一下Leonid Afremov 的繪畫風格,並將這張東方明珠的照片處理成那種光影色彩豐富的作品風格。利用Tensorflow 以及上面提到的那個專案的程式碼,在一個AWS 的p2型別的例項上進行了一個一千次的迭代,於是就得到了下圖這樣的處理結果。

這個處理的程式碼只有350行裡,模型使用了一個成名於2014年ImageNet比賽中的明星 VGG。這個模型非常好,特點就是“go depper”。
TensorFlow 做出這樣的作品,並不僅僅作為娛樂供大家一笑,還可以做更多有意思的事情。將剛才的處理能力推廣到視訊當中,就可以看到下圖這樣的效果,用梵高著名的作品”星月夜“的風格就加工成了這樣新的視訊風格。

可以想象一下,如果這種處理能力在更多領域得以應用,它會產生什麼樣的神奇的結果?前景是美好的,讓我們有無限遐想。事實上我們目前所從事的很多領域的應用開發都可以通過使用神經網路和深度學習來加以改變。對於深度學習而言,掌握它並不是難事。每一個程式設計師都可以很容易的掌握這種技術,利用所具備的資源,讓我們很快成為深度學習的程式開發人員。
結束語
未來究竟是什麼樣,我們沒有辦法預言。有位作家Ray Kurzweil在2005年寫了《奇點臨近》一書。在這本書裡面他明確告訴我們,那個時代很快到來。作為那個時代曙光前的人群,我們是不是有能力加速這個過程,利用我們學習的能力實現這個夢想呢?

作者介紹:

費良巨集
亞馬遜AWS首席雲端計算技術顧問,擁有超過20年在IT行業以及軟體開發領域的工作經驗。在此之前他曾經任職於Microsoft、Apple等知名企業,任職架構師、技術顧問等職務,參與過多個大型軟體專案的設計、開發與專案管理。目前專注於雲端計算以及網際網路等技術領域,致力於幫助中國的開發者構建基於雲端計算的新一代的網際網路應用。
相關推薦
程式設計師的深度學習入門指南
本文根據費良巨集在2016QCon全球軟體開發大會(上海)上的演講整理而成。 今天我想跟大家分享的話題與深度學習有關。事實上,深度學習本身是一個非常龐大的知識體系。今天的內容,不會涉及深度學習的理論知識,更多想從程式設計師的視角出發,讓大家觀察一下深度學習對我們程式設計師意味
switch語句與三種迴圈語句,JAVA程式設計師程式設計新手入門基礎學習筆記
Java是一種可以撰寫跨平臺應用軟體的面向物件的程式設計語言。Java 技術具有卓越的通用性、高效性、平臺移植性和安全性,廣泛應用於PC、資料中心、遊戲控制檯、科學超級計算機、行動電話和網際網路,同時擁有全球最大的開發者專業社群。 自己整理了-份201 8最全面前端學習資料,從最基礎的HTML+
深度學習入門1
ont gin 語音識別 告訴 min 重要 orf 模型 獲得 發布這個系列,一來是為了總結自己的學習,二來也是希望給深度學習初學者一些入門的指導。好廢話不多說了,我們直接進入主題,這一節先說一下,深度學習發展歷程。 1958,感知器(相當於生物的神經元) 1969,M
深度學習入門和學習書籍
cer 書籍資源 ews iam 圖像 php eas 平臺 連接 深度學習書籍推薦: 深度學習(Deep Learning) by Ian Goodfellow and Yoshua Bengio and Aaron Courville 中文版下載地址:h
《深度學習入門:基於Python的理論與實現》高清中文版PDF+源代碼
mark 原理 col 外部 tps follow src term RoCE 下載:https://pan.baidu.com/s/1nk1IHMUYbcuk1_8tj6ymog 《深度學習入門:基於Python的理論與實現》高清中文版PDF+源代碼 高清中文版PDF,3
資深程式設計師的Metal入門教程總結
歡迎大家前往騰訊雲+社群,獲取更多騰訊海量技術實踐乾貨哦~ 本文由落影發表於雲+社群專欄 正文 本文介紹Metal和Metal Shader Language,以及Metal和OpenGL ES的差異性,也是實現入門教程的心得總結。 一、Metal Metal 是一個和 OpenGL ES
2019年Java程式設計師的學習計劃,收藏明年用
寫在前面(為什麼要制定計劃):一轉眼2018已過大半,時間飛逝,有時候你有沒有常常在想,我這段時間都學了什麼,做了什麼呢?我認為這就是計劃的好處,心中有一個這一階段的目標,並且有目的的去執行他,可以很清晰的知道自己這段時間大概是做了哪些事,並且可以有效的去總結它,總結是一件重要的事。執行計劃還會給自
分享《深度學習入門:基於Python的理論與實現 》中文版PDF和原始碼
下載:(https://pan.baidu.com/s/1agBctMG7HF45VwhYpQHDSQ) 《深度學習入門:基於Python的理論與實現》高清中文版PDF+原始碼 高清中文版PDF,314頁,帶目錄標籤,可複製貼上,高清晰。配套原始碼。 深度學習真正意義上的入門書,深入淺出地剖析了深度學習
php程式設計師的學習路線,以及進階篇
# PHP interview best practices in China 如果你現在處於以下幾種狀態,本資料非常適合你: * 準備換工作,不知道從哪開始準備 * 技術遇到瓶頸,不知道該學什麼 * 準備學 PHP,但不知道領域有多深 ## 基礎篇 * 瞭解大部分陣列處理函式 * 字串處
《深度學習入門:基於Python的理論與實現》高清中文版PDF+原始碼
下載:https://pan.baidu.com/s/1nk1IHMUYbcuk1_8tj6ymog 《深度學習入門:基於Python的理論與實現》高清中文版PDF+原始碼 高清中文版PDF,314頁,帶目錄標籤,可複製貼上,高清晰。配套原始碼。 深度學習真正意義上的入門書,深入淺出地剖析了深度學習的原
深度學習入門-基於Python的理論與實現 感知機
目錄 感知機 感知機是什麼 權重和偏置的含義 單層感知機的侷限性 多層感知機 感知機 感知機是什麼 就是人工神經元 權重越大,對應該權重的訊號的重要性就越高。 權重和偏置的含義 權重是控制輸入訊號重要性的引數,偏置是調整神經元被
SonarQube學習入門指南
1. 什麼是SonarQube? SonarQube 官網:https://www.sonarqube.org/ SonarQube®是一種自動程式碼審查工具,用於檢測程式碼中的錯誤,漏洞和程式碼異味。它可以與您現有的工作流程整合,以便在專案分支和拉取請求之間進行連續的程式碼檢查。
《深度學習入門:基於Python的理論與實現》高清中文版PDF+原始碼 下載
本書是深度學習真正意義上的入門書,深入淺出地剖析了深度學習的原理和相關技術。書中使用Python3,儘量不依賴外部庫或工具,從基本的數學知識出發,帶領讀者從零建立一個經典的深度學習網路,使讀者在此過程中逐步理解深度學習。書中不僅介紹了深度學習和神經網路的概念、特徵等基礎知識,對誤差反向傳播法、
深度學習入門專案完整流程——圖片製作資料集、訓練網路、測試準確率(TensorFlow+keras)
首先將訓練的圖片和標籤製作成資料集,我用的是numpy庫裡的savez函式,可以將numpy陣列儲存為.npz檔案(無壓縮,所以檔案較大)。 import cv2 as cv import numpy as np import os import glob #調整影象的大小、製作資
#大神的分享:Java程式設計師的學習生涯中各個階段的建議
每一個新手在學習程式設計的時候,都會有一個迷茫期,不知道學這些知識能夠幹什麼,對於未來應該從事什麼樣的工作也很迷茫,所以作者特意寫了這一篇文章來給大家解釋。 如果有想學習java的程式設計師,可來我們的java學習扣qun:79979,2590免費送java的視訊教程噢!我整理了一份適合18年學
分享《深度學習入門:基於Python的理論與實現》+PDF+源碼+齋藤康毅+陸宇傑
過程 經典的 text proc log 使用 網絡 其中 itil 下載:https://pan.baidu.com/s/1FYcvG1tB__ooitilMpJC7w 更多資料分享:http://blog.51cto.com/14087171 《深度學習入門:基於Pyt
非科班Java程式設計師的學習過程和社招經歷總結
個人發展目標 首先我覺得個人今後想做什麼方向也是比較重要的,除了資料結構常用演算法、作業系統、網路、資料庫這些常用基礎外,國內網際網路公司基本上雖然說刷題也是必須的,但光刷題肯定是不夠的,多少還是有方向重點的。雖然說後端語言不是關鍵,要轉也問題不大,但是畢竟時間有限,又要去把c++的stl原始碼
深度學習入門:基於Python的理論與實現 高清中文版PDF電子版下載附原始碼
本書特色1.日本深度學習入門經典暢銷書,原版上市不足2年印刷已達100 000冊。長期位列日亞“人工智慧”類圖書榜首,超多五星好評。2.使用Python 3,儘量不依賴外部庫或工具,從零建立一個深度學習模型。3.示例程式碼清晰,原始碼可下載,需要的執行環境非常簡單。讀者可以一邊讀書一邊執行程式,簡單易上手。4
深度學習入門:基於Python的理論與實現 高清中文版PDF電子版下載附源代碼
圖形 alexnet 1.7 法則 門電路 版本 求解 ·· 訪問 本書特色1.日本深度學習入門經典暢銷書,原版上市不足2年印刷已達100 000冊。長期位列日亞“人工智能”類圖書榜首,超多五星好評。2.使用Python 3,盡量不依賴外部庫或工具,從零創建一個深度學習模型