
MySQL系列教程(五)
MyCAT
MyCat是基於阿里開源的Cobar產品而研發,Cobar的穩定性、可靠性、優秀的架構和效能以及眾多成熟的使用案例使得MYCAT一開始就擁有一個很好的起點,站在巨人的肩膀上,我們能看到更遠。業界優秀的開源專案和創新思路被廣泛融入到MYCAT的基因中,使得MYCAT在很多方面都領先於目前其他一些同類的開源專案,甚至超越某些商業產品。
MYCAT背後有一支強大的技術團隊,其參與者都是5年以上資深軟體工程師、架構師、DBA等,優秀的技術團隊保證了MYCAT的產品質量。MYCAT並不依託於任何一個商業公司,因此不像某些開源專案,將一些重要的特性封閉在其商業產品中,使得開源專案成了一個擺設。
因此,MyCat你可以認為是從Amoeba->Cobar一路過來的最終版升級者。
由於MyCat和Corba都是Amoeba框架上發展而來的,如果一個具有Amoeba配置經驗的開發者可以幾乎不用看任何文件而可以直接使用MyCat來實現mySQL的讀寫分離更重要的是,基於myCat你可以實現資料的垂直和水平切割,它使得了mySQL據有了真正的“叢集”的能力,併為去IOE做好了最終的準備。
myCAT開源專案維護很頻繁,目前最新版已經到了1.5 Release(23天前剛維護過)。因此它的維護性、穩定性是得到了保證的。同時myCat的文件極其豐富,參於開發的人員又很多,所以它可以應付很多在以往的Amoeba以及Corba上未能解決的問題,它是一個可以真正被應用在生產環境上的資料庫中介軟體。在下面的章節我們將使用myCat來實現mySQL的讀寫分離和垂直水平折分的具體案例。
myCat介紹
什麼是MyCAT?簡單的說,MyCAT就是:
- 一個徹底開源的,面向企業應用開發的“大資料庫叢集” 支援事務、ACID、可以替代Mysql的加強版資料庫
- 一個可以視為“Mysql”叢集的企業級資料庫,用來替代昂貴的Oracle叢集
- 一個融合記憶體快取技術、Nosql技術、HDFS大資料的新型SQL Server
- 結合傳統資料庫和新型分散式資料倉庫的新一代企業級資料庫產品
- 一個新穎的資料庫中介軟體產品
關鍵特性
支援 SQL 92標準 支援Mysql叢集,可以作為Proxy使用 支援JDBC連線ORACLE、DB2、SQL Server,將其模擬為MySQL Server使用 支援galera for mysql叢集,percona-cluster或者mariadb cluster,提供高可用性資料分片叢集,自動故障切換,高可用性 ,支援讀寫分離,支援Mysql雙主多從,以及一主多從的模式 ,支援全域性表,資料自動分片到多個節點,用於高效表關聯查詢 ,支援獨有的基於E-R 關係的分片策略,實現了高效的表關聯查詢多平臺支援,部署和實施簡單。
優勢
基於阿里開源的Cobar產品而研發,Cobar的穩定性、可靠性、優秀的架構和效能,以及眾多成熟的使用案例使得MyCAT一開始就擁有一個很好的起點,站在巨人的肩膀上,我們能看到更遠。廣泛吸取業界優秀的開源專案和創新思路,將其融入到MyCAT的基因中,使得MyCAT在很多方面都領先於目前其他一些同類的開源專案,甚至超越某些商業產品。MyCAT背後有一隻強大的技術團隊,其參與者都是5年以上資深軟體工程師、架構師、DBA等,優秀的技術團隊保證了MyCAT的產品質量。 MyCAT並不依託於任何一個商業公司,因此不像某些開源專案,將一些重要的特性封閉在其商業產品中,使得開源專案成了一個擺設。
長期規劃
在支援Mysql的基礎上,後端增加更多的開源資料庫和商業資料庫的支援,包括原生支援PosteSQL、FireBird等開源資料庫,以及通過JDBC等方式間接支援其他非開源的資料庫如Oracle、DB2、SQL Server等實現更為智慧的自我調節特性,如自動統計分析SQL,自動建立和調整索引,根據資料表的讀寫頻率,自動優化快取和備份策略等實現更全面的監控管理功能與HDFS整合,提供SQL命令,將資料庫裝入HDFS中並能夠快速分析整合優秀的開源報表工具,使之具備一定的資料分析的能力。
MyCat架構
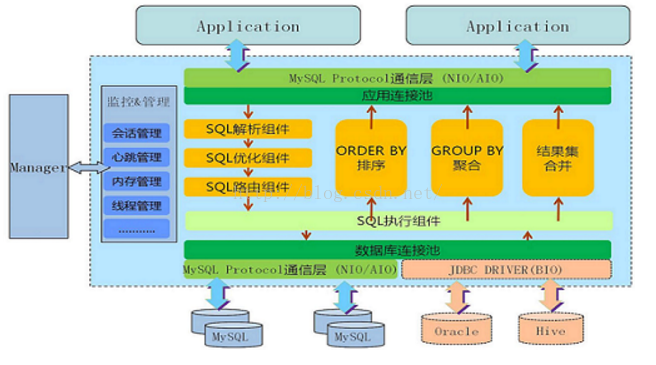
安裝myCat
通過myCat的官方原始碼網站獲得(https://github.com/MyCATApache/Mycat-download)本教程中使用的是myCat 8月出的穩定版:Mycat-server-1.5.1-RELEASE-20160810140521。

下載後解壓至一個目錄如:

配置myCat
myCat的核心配置檔案有如下幾個: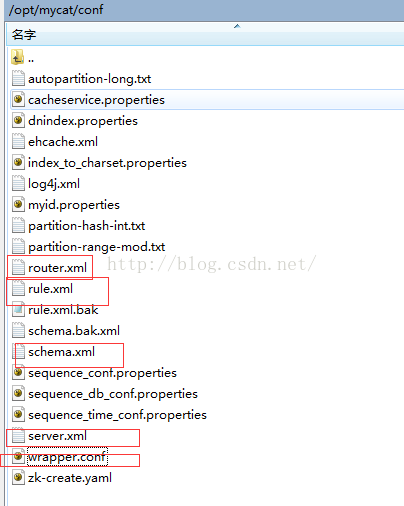
- wrapper.conf – 系統環境配置
- server.xml – mycat主配置檔案,用於配置mycat對外資料庫表、使用者名稱、訪問許可權等
- schema.xml – 用於配置讀寫分離、水平垂直折分叢集
- rule.xml – 用於配置資料水平垂直折分規則
- router.xml – 配合rule.xml檔案使用,當資料折分不符合規則時的走向,類似switch中的default作用
myCat配置讀寫分離
請看下面這組讀寫分離,我們就用myCat來配置出這個例項吧。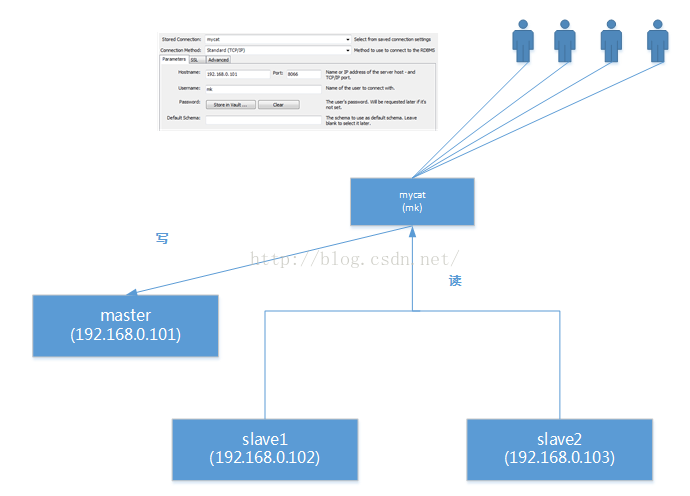
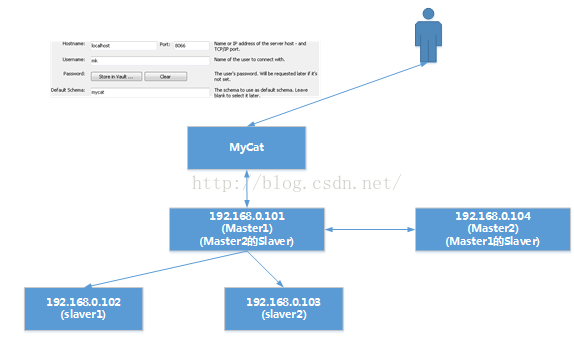
先在物理上構建主從配置
先按照“Mysql主從配置”把:- 192.168.0.101 配成master
- 192.168.0.102 為 192.168.0.101的slave1
- 192.168.0.103 為 192.168.0.103的slave3
配置myCat讀寫分離
修改server.xml檔案開啟server.xml檔案,你會發覺好大一陀,全部刪了吧,改成下面這個配置:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:server SYSTEM "server.dtd">
<mycat:server xmlns:mycat="http://org.opencloudb/">
<system>
<property name="defaultSqlParser">druidparser</property>
</system>
<user name="mk">
<property name="password">aaaaaa</property>
<property name="schemas">mycat</property>
<property name="readOnly">false</property>
</user>
</mycat:server>
上述配置定義了這麼一件事:
- 定義了一個可供外部訪問的myCat的虛擬資料庫
- 它的埠為8806
- schema名為mycat
- 客戶端訪問時的使用者名稱為mk,密碼為aaaaaa(六個a)
開啟後也是很大的一陀,全刪了吧,改成下面這一段:
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://org.opencloudb/" >
<schema name="mycat" checkSQLschema="false" sqlMaxLimit="100" dataNode="dn1"/>
<dataNode name="dn1" dataHost="virtualHost" database="mk" />
<dataHost name="virtualHost" maxCon="50" minCon="5" balance="3"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" >
<heartbeat>select 1</heartbeat>
<writeHost host="m1" url="192.168.0.101:3306" user="mk" password="aaaaaa">
<readHost host="s1" url="192.168.0.102:3306" user="mk" password="aaaaaa" />
<readHost host="s2" url="192.168.0.103:3306" user="mk" password="aaaaaa" />
</writeHost>
</dataHost>
</mycat:schema>
這裡有三處需要注意:
balance="1"與writeType="0" ,switchType=”1”
balance 屬性負載均衡型別,目前的取值有 4 種:
- balance="0", 不開啟讀寫分離機制,所有讀操作都發送到當前可用的writeHost 上。
- balance="1",全部的 readHost 與 stand by writeHost 參與 select 語句的負載均衡,簡單的說,當雙主雙從模式(M1 ->S1 , M2->S2,並且 M1 與 M2 互為主備),正常情況下, M2,S1,S2 都參與 select 語句的負載均衡。
- balance="2",所有讀操作都隨機的在 writeHost、 readhost 上分發。
- balance="3", 所有讀請求隨機的分發到 wiriterHost 對應的 readhost 執行,writerHost 不負擔讀壓力,注意 balance=3 只在 1.4 及其以後版本有, 1.3 沒有。
- writeType="0", 所有寫操作傳送到配置的第一個 writeHost,第一個掛了切到還生存的第二個writeHost,重新啟動後已切換後的為準,切換記錄在配置檔案中:dnindex.properties .
- writeType="1",所有寫操作都隨機的傳送到配置的 writeHost。
- writeType="2",沒實現。
- -1 表示不自動切換
- - 1 預設值,自動切換
- 2 基於MySQL 主從同步的狀態決定是否切換
<writeHost host="m1" url="192.168.0.101:3306" user="mk" password="aaaaaa">
<readHost host="s1" url="192.168.0.102:3306" user="mk" password="aaaaaa" />
<readHost host="s2" url="192.168.0.103:3306" user="mk" password="aaaaaa" />
</writeHost>
這裡是配置的我們的myCat後臺連線的真實的 1主2從伺服器以及它們的連線資訊。
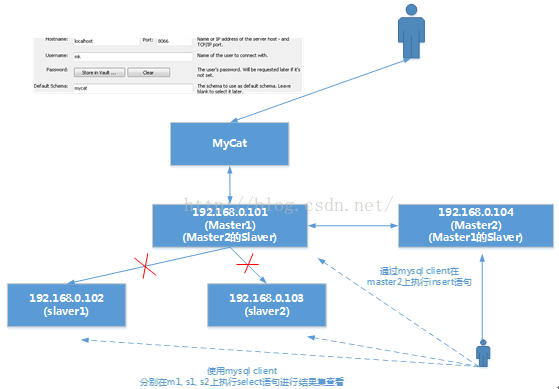
測試讀寫分離
1. 我們把mycat啟動起來./mycat start看wrapper.log檔案中的內容
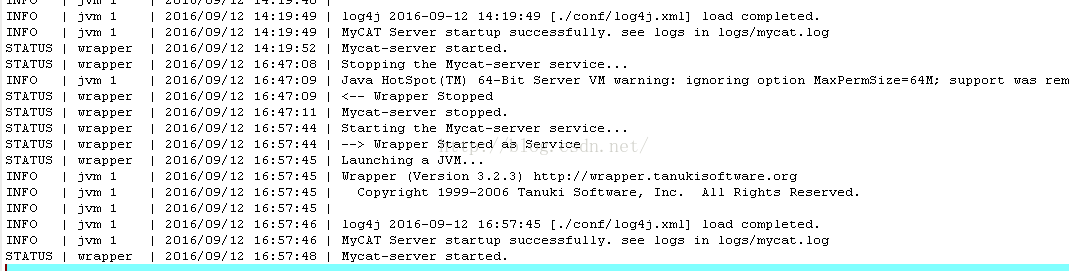
看到mycat已經被啟動了。‘
2. 於是我們開啟一個mysql客戶端使用如下方式連線進入mycat
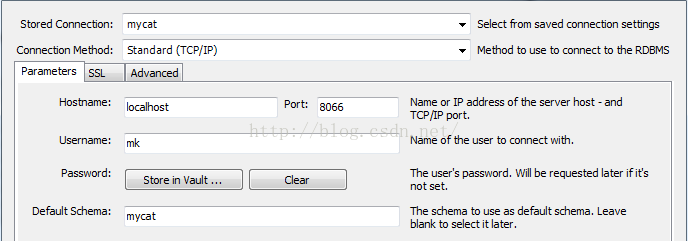
3. 我們往mycat裡插入4條資料
insert into user_info(user_name)values(@@hostname);
insert into user_info(user_name)values(@@hostname);
insert into user_info(user_name)values(@@hostname);
insert into user_info(user_name)values(@@hostname);
commit;
單獨連上ymklinux和ymklinux2以及ymklinux3分別作
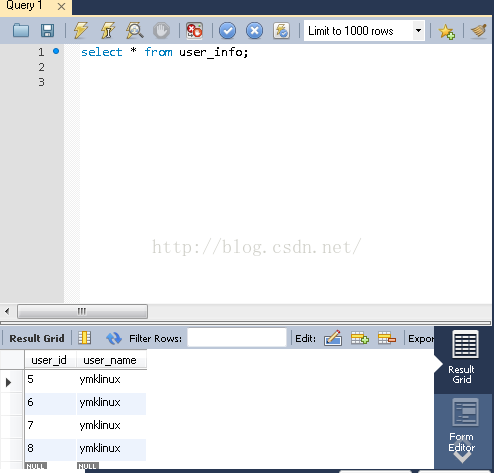
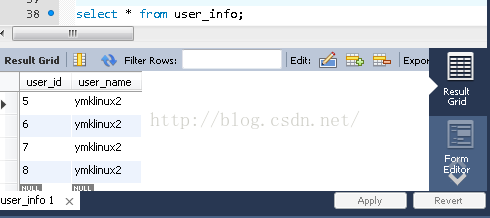
我們可以看到,由於102,103為101的slaver所以當下面這種模式:
<writeHost host="m1" url="192.168.0.101:3306" user="mk" password="aaaaaa">
<readHost host="s1" url="192.168.0.102:3306" user="mk" password="aaaaaa" />
<readHost host="s2" url="192.168.0.103:3306" user="mk" password="aaaaaa" />
</writeHost>
writeHost為192.168.0.101(Master)被寫入資料時,而又因為192.168.0.101與102, 103為Master-Slaver的關係因此102與103會自動同步192.168.0.101上被insert進入的資料。如下圖演示那樣。
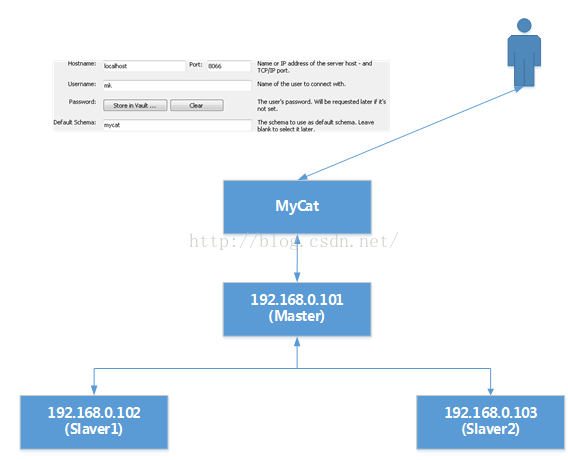
考慮多Master的場景
我們回到上棕這個場景來看,為什麼説需要多Master?<writeHost host="m1" url="192.168.0.101:3306" user="mk" password="aaaaaa">
<readHost host="s1" url="192.168.0.102:3306" user="mk" password="aaaaaa" />
<readHost host="s2" url="192.168.0.103:3306" user="mk" password="aaaaaa" />
</writeHost>
上述這個應用,有一個非致命的缺點:
即定義的writeHost一旦發生宕機那麼其相應對的readHost全部為不可用,換而言之即整個myCat群宕機。
熊掌與魚兼得法
按照myCat的配置我們可以配置多個writeHost並把writeType這個值設為“0”。來看writeType=”0”的含議:
writeType="0", 所有寫操作傳送到配置的第一個 writeHost,第一個掛了切到還生存的第二個writeHost,重新啟動後已切換後的為準,切換記錄在配置檔案中:dnindex.properties .
第一種配置:
於是我們來考慮下面這樣的配置:
<writeHost host="m1" url="192.168.0.101:3306" user="root" password="aaaaaa">
</writeHost>
<writeHost host="m2" url="192.168.0.104:3306" user="root" password="aaaaaa"/>
MyCat群會在Master1發生宕機時自動探尋Master2是否還存活,如果Master2存活那麼把資料的讀和寫全部轉向以Master2為代表的讀寫群。
但是,這也帶來了一個問題。
如果此時Master1宕機了,Master2被頂了上來,那麼資料全部跑入了Master2群內了。
當:
Master1再次恢復時。。。對於通過myCat客戶端呼叫者來説這一切是秀明的,資料依然還是那些資料,可是此時,再來一次Master2宕機(剛才是Master1宕機),此時myCat會把Master1作為讀寫群。
於是,客戶端再次通過myCat代理呼叫後,會發覺資料有差異了。
為什麼?
因為Master2內的資料和Master1內的資料沒有同步。
第二種配置:於是:
第一步:
我們保留第一種配置即
<writeHost host="m1" url="192.168.0.101:3306" user="root" password="aaaaaa">
</writeHost>
<writeHost host="m2" url="192.168.0.104:3306" user="root" password="aaaaaa"/>
第二步:我們把Master1和Master2在物理上做成MySQL的主-備結構,現在來看場景推演。
Master1發生宕機,Master2頂上同時同步了Master1宕機前的資料,對於myCat使用者群來説資料everything is ok。
Master1恢復,Master2宕機客戶端發覺通過myCat得到的資料(來自於Master1)有異常,為什麼?
因為Master2是Master1的Slaver,因此它只會“正向同步Master1的資料”,而不能逆向,因此這種配置和第一種配置完全沒有區別。
那麼有人説我們把Master1作成Master2的Slaver呢?那無非上第二種情況的場景推演倒一倒而己,還是不能保證任何一點宕機並且在恢復後如何保證資料的強一致性。
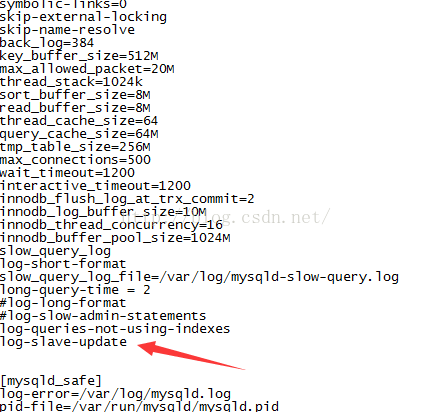
第三種配置:於是,我們想到了一個辦法,這個辦法來源於Master和Slaver在作配置時my.cnf配置檔案 中的一個引數,它就是“log-slave-update”。
對於這個引數的解釋,mySQL官方是如下解釋的:當你的Master同時又是其它Master’的slaver 時,你需要設定此引數。
單從上述描述來看這段語句念起來有些晦澀,我們還是實際來看一個架構圖吧。
這種結構被稱為“雙主結構”或者又稱為“互為主備”結構。
- Master1是Master2的Slaver;
- Master2是Master1的Slaver;
- 同時,他們又是彼此下面如:Master1拖的S1, S2的Master
基於互為主備結構的myCat群搭建方法
第一步(一定要設log-slave-update)
把Master1作成Master2的Slaver,在Master1配置檔案my.cnf中設定log-slave-update。如果不設會發生下面這種情況
1)通過Master2 insert資料
2)在Master1上檢視,資料被從Master2上同步過來了
3)通過Master1下掛載的它本身的幾個Slaver連入並進行檢視,結果發覺沒有同步Master1的資料
4)通過Master1 insert資料
5)在Master2上檢視,資料被從Master1上同步過來了
6)通過Master2下掛載的它本身的幾個Slaver連入並進行檢視,結果發覺沒有同步Master2的資料
第二步
把Master2作成Master1的Slaver,在Master2配置檔案my.cnf中設定log-slave-update。對於Master1或者是Master2下再外掛的其本身的s1,s2上不需要再設log-slave-update這個開關了。
如果Master1或者是Master2本身下面還有掛Slaver,請記得此時在其本身的Slaver1上再同步一下它們與Master之間的bin-log。
因為Master一旦作成了另一個Master的Slaver,因此它的bin-log也改變了,你可以直接在其本身的Slaver上使用change master命令。
第三步
在myCat的配件檔案中作如下設定:<dataHost name="virtualHost" maxCon="50" minCon="5" balance="3"
writeType="0" dbType="mysql" dbDriver="native" switchType="2" slaveThreshold="100">
<heartbeat>show slave status</heartbeat>
<writeHost host="m1" url="192.168.0.101:3306" user="root" password="aaaaaa">
<readHost host="s1" url="192.168.0.102:3306" user="root" password="aaaaaa"/>
<readHost host="s2" url="192.168.0.103:3306" user="root" password="aaaaaa"/>
</writeHost>
<writeHost host="m2" url="192.168.0.104:3306" user="root" password="aaaaaa"/>
</dataHost>
於是,我們就有了這樣的結構了
測試
1) 我們連上myCat,對myCat群傳送2條insert語句
2) 我們單獨連上m1, s1, s2, m2檢視,發覺各個mysql例項中的資料一致
3) 直接在m1上執行service mysqld stop
4) 再次連上myCat群,對myCat群再發送2條insert語句
5) 我們單獨連上m2進行檢視,現在m2上為4條資料
6) 我們分別連上s1和s2進行檢視,發現s1和s2上還是2條資料
7) 我們把m1的mysql例項重新啟動起來使用命令service mysqld start
8) 單獨連上m1進行檢視,發覺m1此時資料條資料為4條
9)我們分別連上s1和s2進行檢視,發現s1和s2上已經從原來的2條資料變為了4條資料一個高可用的讀寫分離的叢集就此搭建完畢,絕逼完美!
mySQL的垂直與水平折分
在本書系統的《mySQL叢集(cluster)》中,我們詳細介紹和對比了幾種叢集的方案,並且在該章節中我詳細描述過使用mySQL的分片原則是可以取代叢集方案的。並且它比起叢集方案來説擁有著更多的優點:- 廉價,軟體免費並且可以使用廉價PC
- 可以大規模鋪設不受License的束縛
- 穩定可監控
- 對於已有應用程式來説,它是透明的
什麼是分片
一般的replication具有一個限制,即一旦資料庫過於龐大,尤其是當寫入過於頻繁,很難由一臺主機支撐的時候,我們還是會面臨到擴充套件瓶頸。
所謂資料分片(sharding)即是通過某種特定的條件,將我們存放在同一個資料庫中的資料分散存放到多個數據庫(主機)上面,以達到分散單臺裝置負載的效果。。資料的切分同時還可以提高系統的總體可用性,因為單臺裝置Crash之後,只有總體資料的某部分不可用,而不是所有的資料。
資料的切分(Sharding)模式
一種是按照不同的表(或者Schema)來切分到不同的資料庫(主機)之上,這種切可以稱之為資料的垂直(縱向)切分;另外一種則是根據表中的資料的邏輯關係,將同一個表中的資料按照某種條件拆分到多臺資料庫(主機)上面,這種切分稱之為資料的水平(橫向)切分。垂直切分
一個架構設計較好的應用系統,其總體功能肯定是由很多個功能模組所組成的,而每一個功能模組所需要的資料對應到資料庫中就是一個或者多個表。而在架構設計中,各個功能模組相互之間的互動點越統一越少,系統的耦合度就越低,系統各個模組的維護性以及擴充套件性也就越好。這樣的系統,實現資料的垂直切分也就越容易。
一般來說,如果是一個負載相對不是很大的系統,而且表關聯又非常的頻繁,那可能資料庫讓步,將幾個相關模組合併在一起減少應用程式的工作的方案可以減少較多的工作量,這是一個可行的方案。一個垂直拆分的例子:
1.使用者模組表:user,user_profile,user_group,user_photo_album
2.群組討論表:groups,group_message,group_message_content,top_message
3.相簿相關表:photo,photo_album,photo_album_relation,photo_comment
4.事件資訊表:event群組討論模組和使用者模組之間主要存在通過使用者或者是群組關係來進行關聯。一般關聯的時候都會是通過使用者的id或者nick_name以及group的id來進行關聯,通過模組之間的介面實現不會帶來太多麻煩;
相簿模組僅僅與使用者模組存在通過使用者的關聯。這兩個模組之間的關聯基本就有通過使用者id關聯的內容,簡單清晰,介面明確;
事件模組與各個模組可能都有關聯,但是都只關注其各個模組中物件的ID資訊,同樣可以做到很容易分拆。
垂直切分的優點
- 資料庫的拆分簡單明瞭,拆分規則明確;
- 應用程式模組清晰明確,整合容易;
- 資料維護方便易行,容易定位;
- 部分表關聯無法在資料庫級別完成,需要在程式中完成;
- 對於訪問極其頻繁且資料量超大的表仍然存在效能瓶頸,不一定能滿足要求;
- 事務處理相對更為複雜;
- 切分達到一定程度之後,擴充套件性會遇到限制;
- 過度切分可能會帶來系統過渡複雜而難以維護。
水平切分
將某個訪問極其頻繁的表再按照某個欄位的某種規則來分散到多個表之中,每個表中包含一部分資料。對於上面的例子:所有資料都是和使用者關聯的,那麼我們就可以根據使用者來進行水平拆分,將不同使用者的資料切分到不同的資料庫中。
現在網際網路非常火爆的Web2.0型別的網站,基本上大部分資料都能夠通過會員使用者資訊關聯上,可能很多核心表都非常適合通過會員ID來進行資料的水平切分。而像論壇社群討論系統,就更容易切分了,非常容易按照論壇編號來進行資料的水平切分。切分之後基本上不會出現各個庫之間的互動。
水平切分的優點
表關聯基本能夠在資料庫端全部完成;
不會存在某些超大型資料量和高負載的表遇到瓶頸的問題;
應用程式端整體架構改動相對較少;
事務處理相對簡單;
只要切分規則能夠定義好,基本上較難遇到擴充套件性限制;
水平切分的缺點
切分規則相對更為複雜,很難抽象出一個能夠滿足整個資料庫的切分規則;
後期資料的維護難度有所增加,人為手工定位資料更困難;
應用系統各模組耦合度較高,可能會對後面資料的遷移拆分造成一定的困難。
兩種切分結合用
一般來說,我們資料庫中的所有表很難通過某一個(或少數幾個)欄位全部關聯起來,所以很難簡單的僅僅通過資料的水平切分來解決所有問題。而垂直切分也只能解決部分問題,對於那些負載非常高的系統,即使僅僅只是單個表都無法通過單臺數據庫主機來承擔其負載。我們必須結合“垂直”和“水平”兩種切分方式同時使用
每一個應用系統的負載都是一步一步增長上來的,在開始遇到效能瓶頸的時候,大多數架構師和DBA都會選擇先進行資料的垂直拆分,因為這樣的成本最先,最符合這個時期所追求的最大投入產出比。然而,隨著業務的不斷擴張,系統負載的持續增長,在系統穩定一段時期之後,經過了垂直拆分之後的資料庫叢集可能又再一次不堪重負,遇到了效能瓶頸。
如果我們再一次像最開始那樣繼續細分模組,進行資料的垂直切分,那我們可能在不久的將來,又會遇到現在所面對的同樣的問題。而且隨著模組的不斷的細化,應用系統的架構也會越來越複雜,整個系統很可能會出現失控的局面。
這時候我們就必須要通過資料的水平切分的優勢,來解決這裡所遇到的問題。而且,我們完全不必要在使用資料水平切分的時候,推倒之前進行資料垂直切分的成果,而是在其基礎上利用水平切分的優勢來避開垂直切分的弊端,解決系統複雜性不斷擴大的問題。而水平拆分的弊端(規則難以統一)也已經被之前的垂直切分解決掉了,讓水平拆分可以進行的得心應手。
myCat實現資料分片

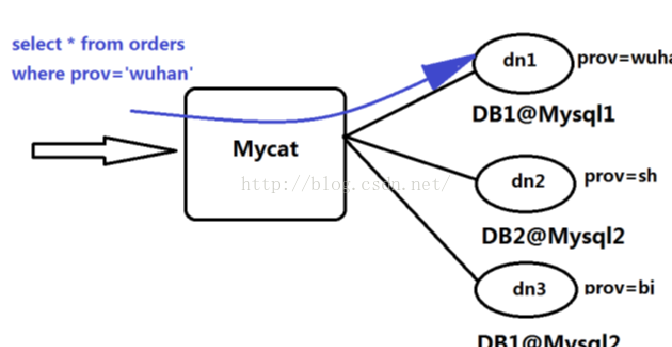
在資料切分處理中,特別是水平切分中,中介軟體最終要的兩個處理過程就是資料的切分、資料的聚合。
選擇合適的切分規則,至關重要,因為它決定了後續資料聚合的難易程度,甚至可以避免跨庫的資料聚合
處理。
myCAT資料分片拆分原則:
- 避免或減少跨庫join。
- 選擇最合適的拆分維度。
- MYCAT 全域性表
- ER關係
- 表拆分
--主鍵分片vs 非主鍵分片
myCAT對於後端多個mySQL的資料折分和折分後的聚合,對於myCAT前端呼叫來説是透明的。
以實際例子來操作分片
在分片前,我們需要事先了解一個重要的知識點,也算是一個需要引起重視的問題。
A和B互為主從,我們按照userID來實施分片,userID為1,3,5的插入到一臺mysql例項,userID為2,4,6的插入到另一個mysql例項中去。然後在mycat前端select時mycat會自動進行聚合,即它會從2個mysql例項中選擇資料併合併成1,2,3,4,5,6…這樣的資料顯示給呼叫的客戶端。
1. 先往A上插入 一條資料(id:1 name: tom, gender: m),於是B上也馬上會REPLI(同步)一條資料,因此你在A和B上做SELECT查詢,都可以看到兩邊記錄一樣
2. 往B上插入 一條資料(id:2 name: tom, gender: m),於是A上也馬上會REPLI一條資料,因此你在A和B上做SELECT查詢,都可以看到兩邊記錄一樣
3. 使用MYCAT讀寫分離,A為寫,B為讀,一切OK
4. 使用MYCAT做水平拆分,拆分規則為(id % 2 case 0 then Server A; case 1 then Server B;),於是,規則開始起效。
- 當插入id: 2的資料時,它會被insert到A上,接下去由於A和B互為主備,因此B馬上會同步一條資料。
- 接下去再插入一條id:3的資料,由於id為3的資料根據我們預先配置後的規則會被插入到Server B上, 然後A馬上也會被REPLI一條資料id為3,此時, 此時A和B兩個MYSQL上就都有了同樣的記錄集,都為1,2,3,即:
| Server A | Server B |
| 1 | 1 |
| 2 | 2 |
| 3 | 3 |
Mysql –u root –p aaaaaa –P8066 –h 192.168.0.1
Select * from person
此時你得到的結果集為:
1
2
3
1
2
3
或者你的ReadServer始終為一臺,那你會得到正確的1,2,3這樣的結果集。但是,原先所需要的資料的sharding功能。。。其實沒有做到。
myCAT分片前置條件(極其重要)
因此:如果要考慮後期的水平和垂直折分,被折分的資料庫不可以在其本身已經做了主從結構,而是需要把這個主從結構交由mycat來做。
實際分片演示
我們只需要修改rule.xml這個檔案即可實現myCat的資料分片定義了。但是按照前面小節的重要提示,在做分片前,我們一定要讓我們參於分片規則的mySQL例項保持獨立執行狀態,即多個mySQL例項間不要做任何的“主備”結構。
實驗前準備
我們拿192.168.0.101與192.168.0.102兩臺機器來做分片實驗
在192.168.0.101上禁用binlog,關閉master slaver的關聯,同時斷開與原有192.168.0.104的master slaver關聯。
別忘了把“log-slave-update”也註釋掉。
重啟後登入192.168.0.101,輸入以下命令
stop slave;
change master to master_host=' ';
在192.168.0.104上禁用binlog,關閉master slaver的關聯,同時斷開與原有192.168.0.101的master slaver關聯。
別忘了把“log-slave-update”也註釋掉。
重啟後登入192.168.0.104,輸入以下命令
stop slave;
change master to master_host=' ';
配置資料分片
我們有一張T_PERSON表,結構如下:CREATE TABLE `t_person` (
`person_id` int(11) NOT NULL,
`person_name` varchar(20) DEFAULT NULL,
PRIMARY KEY (`person_id`)
) ENGINE=MyISAM DEFAULT CHARSET=latin1;
show slave status;
資料分片按照PERSON_ID的奇偶來分。
配置mycat的rule.xml檔案
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mycat:rule SYSTEM "rule.dtd">
<mycat:rule xmlns:mycat="http://org.opencloudb/">
<tableRule name="mod-long">
<rule>
<columns>person_id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<function name="mod-long" class="org.opencloudb.route.function.PartitionByMod">
<!-- how many data nodes -->
<property name="count">2</property>
</function>
</mycat:rule>
通過配置可以看到我們按照person_id會把該表資料分在2個物理庫內,分片資料包括通過mycat的mysql client端insert時自動分片以及select時自動聚合。
應用分片
rule.xml檔案定義後還需要應用它裡面的規則,才能夠最終讓資料分片在mycat中起效,為此,我們更改schema.xml檔案,増加如下一段配置:
<schema name="split" checkSQLschema="false" sqlMaxLimit="100">
<table name="t_person" dataNode="splitNode1,splitNode2" rule="mod-long"/>
</schema>
<dataNode name="splitNode1" dataHost="host1" database="mk" />
<dataNode name="splitNode2" dataHost="host2" database="mk" />
<dataHost name="host1" maxCon="20" minCon="5" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" >
<heartbeat>select 1</heartbeat>
<writeHost host="m1" url="192.168.0.101:3306" user="mk" password="aaaaaa"/>
</dataHost>
<dataHost name="host2" maxCon="20" minCon="5" balance="0"
writeType="0" dbType="mysql" dbDriver="native" switchType="1" >
<heartbeat>select 1</heartbeat>
<writeHost host="s1" url="192.168.0.104:3306" user="mk" password="aaaaaa"/>
</dataHost>
接著我們更改server.xml檔案,増加如下一段配置:
<user name="split">
<property name="password">aaaaaa</property>
<property name="schemas">split</property>
<property name="readOnly">false</property>
</user>
測試分片
我們使用split/aaaaaa使用者連上mycat例項
我們插入5條資料
insert into t_person(person_id,person_name)values('1','michael');
insert into t_person(person_id,person_name)values('2','tom');
insert into t_person(person_id,person_name)values('3','tonny');
insert into t_person(person_id,person_name)values('4','marry');
insert into t_person(person_id,person_name)values('5','jack');
commit;
然後我們接著做一次查詢
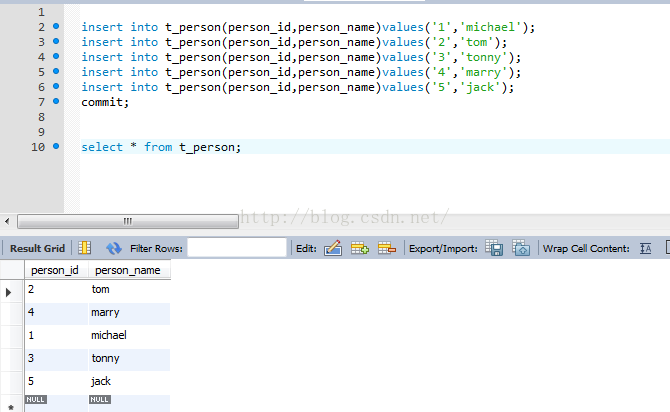
連入192.168.0.101上進行檢視,我們可以得到2條資料,person_id為偶數倍。
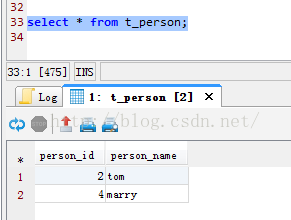
連入192.168.0.104上進行檢視,我們可以得到3條資料,person_id為奇數倍。
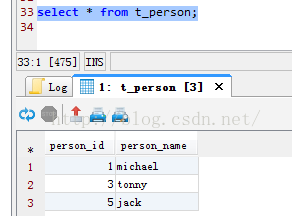
分片成功!!!
myCAT的分片功能相當的強大,完全可以應付億萬級的資料,如果再結合適當的讀寫分離機制是完全可以讓你的網站飛起來的。
myCAT的分片規則還有很多,文後的附件中會給出一個myCAT分片規則大全。
附件 myCAT分片規則大全
常用的根據主鍵或非主鍵的分片規則配置:
1. 列舉法
通過在配置檔案中配置可能的列舉id,自己配置分片,使用規則:'
<tableRule name="sharding-by-intfile">
<rule>
<columns>user_id</columns>
<algorithm>hash-int</algorithm>
</rule>
</tableRule>
<function name="hash-int" class="org.opencloudb.route.function.PartitionByFileMap">
<property name="mapFile">partition-hash-int.txt</property>
<property name="type">0</property>
<property name="defaultNode">0</property>
</function>
partition-hash-int.txt 配置:
10000=0
10010=1
DEFAULT_NODE=1
上面columns 標識將要分片的表字段,algorithm 分片函式,
其中分片函式配置中,mapFile標識配置檔名稱,type預設值為0,0表示Integer,非零表示String,
所有的節點配置都是從0開始,及0代表節點1
/**
* defaultNode 預設節點:小於0表示不設定預設節點,大於等於0表示設定預設節點
*
預設節點的作用:列舉分片時,如果碰到不識別的列舉值,就讓它路由到預設節點
* 如果不配置預設節點(defaultNode值小於0表示不配置預設節點),碰到
* 不識別的列舉值就會報錯,
* like this:can't find datanode for sharding column:column_name val:ffffffff
*/
2. 固定分片hash演算法
<tableRule name="rule1">
<rule>
<columns>user_id</columns>
<algorithm>func1</algorithm>
</rule>
</tableRule>
<function name="func1" class="org.opencloudb.route.function.PartitionByLong">
<property name="partitionCount">2,1</property>
<property name="partitionLength">256,512</property>
</function>
配置說明:
上面columns 標識將要分片的表字段,algorithm 分片函式,
partitionCount 分片個數列表,partitionLength 分片範圍列表
分割槽長度:預設為最大2^n=1024 ,即最大支援1024分割槽
約束 :
count,length兩個陣列的長度必須是一致的。
1024 = sum((count[i]*length[i])). count和length兩個向量的點積恆等於1024
用法例子:
本例的分割槽策略:希望將資料水平分成3份,前兩份各佔25%,第三份佔50%。(故本例非均勻分割槽)
// |<---------------------1024------------------------>|
// |<----256--->|<----256--->|<----------512---------->|
// | partition0 | partition1 | partition2 |
// | 共2份,故count[0]=2 | 共1份,故count[1]=1 |
int[] count = new int[] { 2, 1 };
int[] length = new int[] { 256, 512 };
PartitionUtil pu = new PartitionUtil(count, length);
// 下面程式碼演示分別以offerId欄位或memberId欄位根據上述分割槽策略拆分的分配結果
int DEFAULT_STR_HEAD_LEN = 8; // cobar預設會配置為此值
long offerId = 12345;
String memberId = "qiushuo";
// 若根據offerId分配,partNo1將等於0,即按照上述分割槽策略,offerId為12345時將會被分配到partition0中
int partNo1 = pu.partition(offerId);
// 若根據memberId分配,partNo2將等於2,即按照上述分割槽策略,memberId為qiushuo時將會被分到partition2中
int partNo2 = pu.partition(memberId, 0, DEFAULT_STR_HEAD_LEN);
如果需要平均分配設定:平均分為4分片,partitionCount*partitionLength=1024
<function name="func1" class="org.opencloudb.route.function.PartitionByLong">
<property name="partitionCount">4</property>
<property name="partitionLength">256</property>
</function>
3. 範圍約定
<tableRule name="auto-sharding-long">
<rule>
<columns>user_id</columns>
<algorithm>rang-long</algorithm>
</rule>
</tableRule>
<function name="rang-long" class="org.opencloudb.route.function.AutoPartitionByLong">
<property name="mapFile">autopartition-long.txt</property>
</function>
# range start-end ,data node index
# K=1000,M=10000.
0-500M=0
500M-1000M=1
1000M-1500M=2
或
0-10000000=0
10000001-20000000=1
配置說明:
上面columns 標識將要分片的表字段,algorithm 分片函式,
rang-long 函式中mapFile代表配置檔案路徑
所有的節點配置都是從0開始,及0代表節點1,此配置非常簡單,即預先制定可能的id範圍到某個分片
4. 求模法
<tableRule name="mod-long">
<rule>
<columns>user_id</columns>
<algorithm>mod-long</algorithm>
</rule>
</tableRule>
<function name="mod-long" class="org.opencloudb.route.function.PartitionByMod">
<!-- how many data nodes -->
<property name="count">3</property>
</function>
配置說明:
上面columns 標識將要分片的表字段,algorithm 分片函式,
此種配置非常明確即根據id進行十進位制求模預算,相比方式1,此種在批量插入時需要切換資料來源,id不連續
5. 日期列分割槽法
<tableRule name="sharding-by-date">
<rule>
<columns>create_time</columns>
<algorithm>sharding-by-date</algorithm>
</rule>
</tableRule>
<function name="sharding-by-date" class="org.opencloudb.route.function.PartitionByDate">
<property name="dateFormat">yyyy-MM-dd</property>
<property name="sBeginDate">2014-01-01</property>
<property name="sPartionDay">10</property>
</function>
上面columns 標識將要分片的表字段,algorithm 分片函式,
配置中配置了開始日期,分割槽天數,即預設從開始日期算起,分隔10天一個分割槽
Assert.assertEquals(true, 0 == partition.calculate("2014-01-01"));
Assert.assertEquals(true, 0 == partition.calculate("2014-01-10"));
Assert.assertEquals(true, 1 == partition.calculate("2014-01-11"));
Assert.assertEquals(true, 12 == partition.calculate("2014-05-01"));
6. 通配取模
<tableRule name="sharding-by-pattern">
<rule>
<columns>user_id</columns>
<algorithm>sharding-by-pattern</algorithm>
</rule>
</tableRule>
<function name="sharding-by-pattern" class="org.opencloudb.route.function.PartitionByPattern">
<property name="patternValue">256</property>
<property name="defaultNode">2</property>
<property name="mapFile">partition-pattern.txt</property>
</function>
partition-pattern.txt
# id partition range start-end ,data node index
###### first host configuration
1-32=0
33-64=1
65-96=2
97-128=3
######## second host configuration
129-160=4
161-192=5
193-224=6
225-256=7
0-0=7
配置說明:
上面columns 標識將要分片的表字段,algorithm 分片函式,patternValue 即求模基數,defaoultNode 預設節點,如果配置了預設,則不會按照求模運算
mapFile 配置檔案路徑
配置檔案中,1-32 即代表id%256後分布的範圍,如果在1-32則在分割槽1,其他類推,如果id非資料,則會分配在defaoultNode 預設節點
String idVal = "0";
Assert.assertEquals(true, 7 == autoPartition.calculate(idVal));
idVal = "45a";
Assert.assertEquals(true, 2 == autoPartition.calculate(idVal));
7. ASCII碼求模通配
<tableRule name="sharding-by-prefixpattern">
<rule>
<columns>user_id</columns>
<algorithm>sharding-by-prefixpattern</algorithm>
</rule>
</tableRule>
<function name="sharding-by-pattern" class="org.opencloudb.route.function.PartitionByPattern">
<property name="patternValue">256</property>
<property name="prefixLength">5</property>
<property name="mapFile">partition-pattern.txt</property>
</function>
partition-pattern.txt
# range start-end ,data node index
# ASCII
# 48-57=0-9
# 64、[email protected]、A-Z
# 97-122=a-z
###### first host configuration
1-4=0
5-8=1
9-12=2
13-16=3
###### second host configuration
17-20=4
21-24=5
25-28=6
29-32=7
0-0=7
配置說明:
上面columns 標識將要分片的表字段,algorithm 分片函式,patternValue 即求模基數,prefixLength ASCII 擷取的位數
mapFile 配置檔案路徑
配置檔案中,1-32 即代表id%256後分布的範圍,如果在1-32則在分割槽1,其他類推
此種方式類似方式6只不過採取的是將列種獲取前prefixLength位列所有ASCII碼的和進行求模sum%patternValue ,獲取的值,在通配範圍內的
即 分片數,
/**
* ASCII編碼:
* 48-57=0-9阿拉伯數字
* 64、[email protected]、A-Z
* 97-122=a-z
*
*/
如
String idVal="gf89f9a";
Assert.assertEquals(true, 0==autoPartition.calculate(idVal));
idVal="8df99a";
Assert.assertEquals(true, 4==autoPartition.calculate(idVal));
idVal="8dhdf99a";
Assert.assertEquals(true, 3==autoPartition.calculate(idVal));
8. 程式設計指定
<tableRule name="sharding-by-substring">
<rule>
<columns>user_id</columns>
<algorithm>sharding-by-substring</algorithm>
</rule>
</tableRule>
<function name="sharding-by-substring" class="org.opencloudb.route.function.PartitionDirectBySubString">
<property name="startIndex">0</property> <!-- zero-based -->
<property name="size">2</property>
<property name="partitionCount">8</property>
<property name="defaultPartition">0</property>
</function>
配置說明:
上面columns 標識將要分片的表字段,algorithm 分片函式
此方法為直接根據字元子串(必須是數字)計算分割槽號(由應用傳遞引數,顯式指定分割槽號)。
例如id=05-100000002
在此配置中代表根據id中從startIndex=0,開始,擷取siz=2位數字即05,05就是獲取的分割槽,如果沒傳預設分配到defaultPartition
9. 字串拆分hash解析
<tableRule name="sharding-by-stringhash">
<rule>
<columns>user_id</columns>
<algorithm>sharding-by-stringhash</algorithm>
</rule>
</tableRule>
<function name="sharding-by-substring" class="org.opencloudb.route.function.PartitionDirectBySubString">
<property name=length>512</property> <!-- zero-based -->
<property name="count">2</property>
<property name="hashSlice">0:2</property>
</function>
配置說明:
上面columns 標識將要分片的表字段,algorithm 分片函式
函式中length代表字串hash求模基數,count分割槽數,hashSlice hash預算位
即根據子字串 hash運算
hashSlice : 0 means str.length(), -1 means str.length()-1
/**
* "2" -> (0,2)<br/>
* "1:2" -> (1,2)<br/>
* "1:" -> (1,0)<br/>
* "-1:" -> (-1,0)<br/>
* ":-1" -> (0,-1)<br/>
* ":" -> (0,0)<br/>
*/
例子:
String idVal=null;
rule.setPartitionLength("512");
rule.setPartitionCount("2");
rule.init();
rule.setHashSlice("0:2");
// idVal = "0";
// Assert.assertEquals(true, 0 == rule.calculate(idVal));
// idVal = "45a";
// Assert.assertEquals(true, 1 == rule.calculate(idVal));
//last 4
rule = new PartitionByString();
rule.setPartitionLength("512");
rule.setPartitionCount("2");
rule.init();
//last 4 characters
rule.setHashSlice("-4:0");
idVal = "aaaabbb0000";
Assert.assertEquals(true, 0 == rule.calculate(idVal));
idVal = "aaaabbb2359";
Assert.assertEquals(true, 0 == rule.calculate(idVal));
10. 一致性hash
<tableRule name="sharding-by-murmur">
<rule>
<columns>user_id</columns>
<algorithm>murmur</algorithm>
</rule>
</tableRule>
<function name="murmur" class="org.opencloudb.route.function.PartitionByMurmurHash">
<property name="seed">0</property><!-- 預設是0-->
<property name="count">2</property><!-- 要分片的資料庫節點數量,必須指定,否則沒法分片-->
<property name="virtualBucketTimes">160</property><!-- 一個實際的資料庫節點被對映為這麼多虛擬節點,預設是160倍,也就是虛擬節點數是物理節點數的160倍-->
<!--
<property name="weightMapFile">weightMapFile</property>
節點的權重,沒有指定權重的節點預設是1。以properties檔案的格式填寫,以從0開始到count-1的整數值也就是節點索引為key,以節點權重值為值。所有權重值必須是正整數,否則以1代替 -->
<!--
<property name="bucketMapPath">/etc/mycat/bucketMapPath</property>
用於測試時觀察各物理節點與虛擬節點的分佈情況,如果指定了這個屬性,會把虛擬節點的murmur hash值與物理節點的對映按行輸出到這個檔案,沒有預設值,如果不指定,就不會輸出任何東西 -->
</function>
一致性hash預算有效解決了分散式資料的擴容問題,前1-9中id規則都多少存在資料擴容難題,而10規則解決了資料擴容難點
關於一致性hash詳細:
一致性雜湊演算法在1997年由麻省理工學院提出的一種分散式雜湊(DHT)實現演算法,設計目標是為了解決因特網中的熱點(Hot spot)問題,初衷和CARP十分類似。一致性雜湊修正了CARP使用的簡 單雜湊演算法帶來的問題,使得分散式雜湊(DHT)可以在P2P環境中真正得到應用。
一致性hash演算法提出了在動態變化的Cache環境中,判定雜湊演算法好壞的四個定義:
1、平衡性(Balance):平衡性是指雜湊的結果能夠儘可能分佈到所有的緩衝中去,這樣可以使得所有的緩衝空間都得到利用。很多雜湊演算法都能夠滿足這一條件。
2、單調性(Monotonicity):單調性是指如果已經有一些內容通過雜湊分派到了相應的緩衝中,又有新的緩衝加入到系統中。雜湊的結果應能夠保證原有已分配的內容可以被對映到原有的或者新的緩衝中去,而不會被對映到舊的緩衝集合中的其他緩衝區。
3、分散性(Spread):在分散式環境中,終端有可能看不到所有的緩衝,而是隻能看到其中的一部分。當終端希望通過雜湊過程將內容對映到緩衝上時,由於不同終端所見的緩衝範圍有可能不同,從而導致雜湊的結果不一致,最終的結果是相同的內容被不同的終端對映到不同的緩衝區中。這種情況顯然是應該避免的,因為它導致相同內容被儲存到不同緩衝中去,降低了系統儲存的效率。分散性的定義就是上述情況發生的嚴重程度。好的雜湊演算法應能夠儘量避免不一致的情況發生,也就是儘量降低分散性。
4、負載(Load):負載問題實際上是從另一個角度看待分散性問題。既然不同的終端可能將相同的內容對映到不同的緩衝區中,那麼對於一個特定的緩衝區而言,也可能被不同的使用者對映為不同 的內容。與分散性一樣,這種情況也是應當避免的,因此好的雜湊演算法應能夠儘量降低緩衝的負荷。
在分散式叢集中,對機器的新增刪除,或者機器故障後自動脫離叢集這些操作是分散式叢集管理最基本的功能。如果採用常用的hash(object)%N演算法,那麼在有機器新增或者刪除後,很多原有的資料就無法找到了,這樣嚴重的違反了單調性原則。接下來主要講解一下一致性雜湊演算法是如何設計的:
環形Hash空間
按照常用的hash演算法來將對應的key雜湊到一個具有2^32次方個桶的空間中,即0~(2^32)-1的數字空間中。現在我們可以將這些數字頭尾相連,想象成一個閉合的環形。如下圖
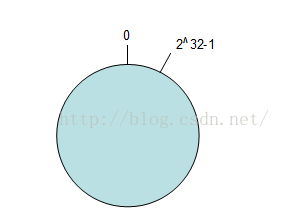
把資料通過一定的hash演算法處理後對映到環上
現在我們將object1、object2、object3、object4四個物件通過特定的Hash函式計算出對
應的key值,然後雜湊到Hash環上。如下圖:
Hash(object1) = key1;
Hash(object2) = key2;
Hash(object3) = key3;
Hash(object4) = key4;
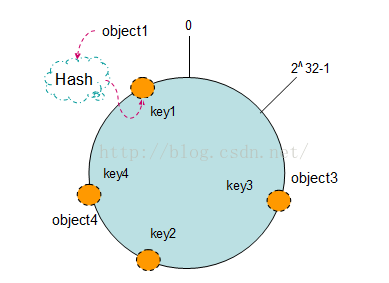
將機器通過hash演算法對映到環上
在採用一致性雜湊演算法的分散式叢集中將新的機器加入,其原理是通過使用與物件儲存一樣的Hash演算法將機器也對映到環中(一般情況下對機器的hash計算是採用機器的IP或者機器唯一的別名作為輸入值),然後以順時針的方向計算,將所有物件儲存到離自己最近的機器中。
假設現在有NODE1,NODE2,NODE3三臺機器,通過Hash演算法得到對應的KEY值,對映到環中,其示意圖如下:
Hash(NODE1) = KEY1;
Hash(NODE2) = KEY2;
Hash(NODE3) = KEY3;
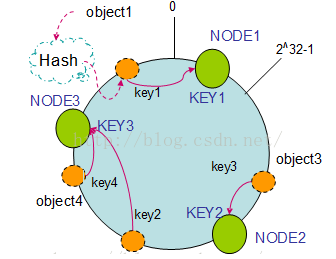
通過上圖可以看出物件與機器處於同一雜湊空間中,這樣按順時針轉動object1儲存到了NODE1中,object3儲存到了NODE2中,object2、object4儲存到了NODE3中。在這樣的部署環境中,hash環是不會變更的,因此,通過算出物件的hash值就能快速的定位到對應的機器中,這樣就能找到物件真正的儲存位置了。
機器的刪除與新增
普通hash求餘演算法最為不妥的地方就是在有機器的新增或者刪除之後會照成大量的物件儲存位置失效,這樣就大大的不滿足單調性了。下面來分析一下一致性雜湊演算法是如何處理的。
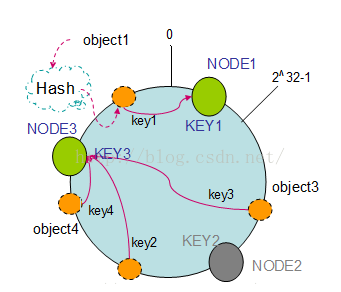
1. 節點(機器)的刪除
以上面的分佈為例,如果NODE2出現故障被刪除了,那麼按照順時針遷移的方法,object3將會被遷移到NODE3中,這樣僅僅是object3的對映位置發生了變化,其它的物件沒有任何的改動。如下圖:
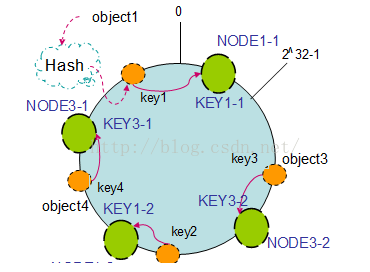
2. 節點(機器)的新增
如果往叢集中新增一個新的節點NODE4,通過對應的雜湊演算法得到KEY4,並對映到環中,如下圖:
通過按順時針遷移的規則,那麼object2被遷移到了NODE4中,其它物件還保持這原有的儲存位置。通過對節點的新增和刪除的分析,一致性雜湊演算法在保持了單調性的同時,還是資料的遷移達到了最小,這樣的演算法對分散式叢集來說是非常合適的,避免了大量資料遷移,減小了伺服器的的壓力。
平衡性
根據上面的圖解分析,一致性雜湊演算法滿足了單調性和負載均衡的特性以及一般hash演算法的分散性,但這還並不能當做其被廣泛應用的原由,因為還缺少了平衡性。下面將分析一致性雜湊演算法是如何滿足平衡性的。hash演算法是不保證平衡的,如上面只部署了NODE1和NODE3的情況(NODE2被刪除的圖),object1儲存到了NODE1中,而object2、object3、object4都儲存到了NODE3中,這樣就照成了非常不平衡的狀態。在一致性雜湊演算法中,為了儘可能的滿足平衡性,其引入了虛擬節點。
——“虛擬節點”( virtual node )是實際節點(機器)在 hash 空間的複製品( replica ),一實際個節點(機器)對應了若干個“虛擬節點”,這個對應個數也成為“複製個數”,“虛擬節點”在 hash 空間中以hash值排列。
以上面只部署了NODE1和NODE3的情況(NODE2被刪除的圖)為例,之前的物件在機器上的分佈很不均衡,現在我們以2個副本(複製個數)為例,這樣整個hash環中就存在了4個虛擬節點,最後物件對映的關係圖如下:
根據上圖可知物件的對映關係:object1->NODE1-1,object2->NODE1-2,object3->NODE3-2,object4->NODE3-1。通過虛擬節點的引入,物件的分佈就比較均衡了。那麼在實際操作中,正真的物件查詢是如何工作的呢?物件從hash到虛擬節點到實際節點的轉換如下圖:
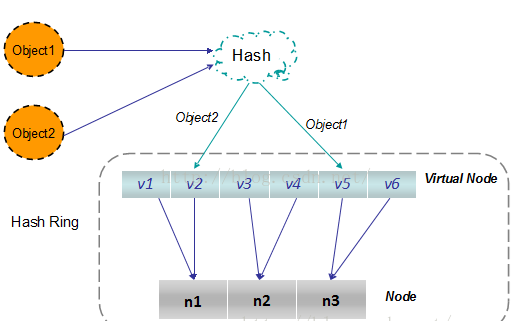
“虛擬節點”的hash計算可以採用對應節點的IP地址加數字字尾的方式。例如假設NODE1的IP地址為192.168.1.100。引入“虛擬節點”前,計算 cache A 的 hash 值:
Hash(“192.168.1.100”);
引入“虛擬節點”後,計算“虛擬節”點NODE1-1和NODE1-2的hash值:
Hash(“192.168.1.100#1”); // NODE1-1
Hash(“192.168.1.100#2”); // NODE1-2
以上所有規則每種都有特定使用場景,可以選擇性使用!
相關推薦
MySQL系列教程(五)
MyCATMyCat是基於阿里開源的Cobar產品而研發,Cobar的穩定性、可靠性、優秀的架構和效能以及眾多成熟的使用案例使得MYCAT一開始就擁有一個很好的起點,站在巨人的肩膀上,我們能看到更遠。業界優秀的開源專案和創新思路被廣泛融入到MYCAT的基因中,使得MYCAT在
Python入門系列教程(五)函數
st3 python入門 test print 缺省 .com 教程 技術 log 全局變量 修改全局變量 a=100 def test(): global a a=200 print a 多個返回值 缺省參數 d
JXLS 2.4.0系列教程(五)——更進一步的應用和bug修復
erl dir 問題 create sna 過程 idl es2017 cal 註:本文代碼建立於前面寫的代碼。不過不看也不要緊。 前面的文章把JXLS 2.4.0 的基本使用寫了一遍,現在講講一些更進一步的使用方法。我只寫一些我用到過的方法,更多的高級使用方法請參
Linux系列教程(五)——Linux鏈接命令和權限管理命令
密碼 mission pos link 掩碼 Owner 最大的 linux系統 passwd 前一篇博客我們講解了Linux文件和目錄處理命令,還是老生常淡,對於新手而言,我們不需要完全記住命令的詳細語法,記住該命令能完成什麽功能,然後需要的時候去查就好了,用的多了我
Java NIO系列教程(五) 通道之間的資料傳輸
作者:Jakob Jenkov 譯者:郭蕾 校對:周泰 在Java NIO中,如果兩個通道中有一個是FileChannel,那你可以直接將資料從一個channel(譯者注:channel中文常譯作通道)傳輸到另外一個channel。 transferFrom() FileChan
OAuth 2.0系列教程(五) 授權
作者:Jakob Jenkov 譯者:林浩 校對:郭蕾 當一個客戶端應用想要訪問擁有者託管在資源伺服器的資源時,它必須先獲得授權,本節將講述客戶端如何獲取授權。 客戶端標識,客戶端金鑰和重定向URI 在客戶端應用能請求訪問資源伺服器的資源之前,客戶端應用程式,必須先在資源伺服器相關
資料探勘入門系列教程(五)之Apriori演算法Python實現
資料探勘入門系列教程(五)之Apriori演算法Python實現載入資料集獲得訓練集頻繁項的生成生成規則獲得support獲得confidence獲得Lift進行驗證總結參考 資料探勘入門系列教程(五)之Apriori演算法Python實現 在上一篇部落格中,我們介紹了Apriori演算法的演算法流
android studio gradle 多版本多apk打包(打包系列教程之五)
當然從截圖也可以看出,配置多apk打包和上一篇文章配置多渠道打包是一樣的,都是在productFlavors中配置的。如上圖,我們在productFlavors中配置了兩種flavor的apk資訊一種是Beta版,一種是Releases版,同時每個flavor中我們都重新配置applicationId這個屬性
GuozhongCrawler系列教程 (1) 三大PageDownloader
特點 string null 瀏覽器兼容 ror down odi 系列 lan GuozhongCrawler QQ群 202568714 教程源代碼下載地址:http://pan.baidu.com/s/1pJBmerL GuozhongCrawl
GuozhongCrawler系列教程 (5) TransactionRequest具體解釋
crawler 是個 回調 指定 ng- shc util line page 為了實現和維護並發抓取的屬性信息提供線程安全的事務請求。TransactionRequest是一個抽象類自己不能設置Processor,卻須要實現 TransactionCallBac
Python入門系列教程(二)
字符 小寫 無符號 bsp div width raw_input abc body 字符串 1.字符串輸出 name = ‘xiaoming‘ print("姓名:%s"%name) 2.字符串輸入 userName = raw_input(‘請輸
java教程(五)SSH框架-配置
jar 集成 相同 onf -i ret 順序 cati lin 前言:從這篇博客開始我將繼續講述Java教程:SSH篇。主要內容環繞SSH框架分析與搭建,今天先簡介一下SSH的配置。 SSH配置順序是: spring-->hibern
微信公眾平臺開發教程(五)自定義菜單
打開鏈接 delete toolbar 推送 優化 pcl reader 接口查詢 robot 應大家強烈要求,將自定義菜單功能課程提前。 一、概述: 如果只有輸入框,可能太簡單,感覺像命令行。自定義菜單,給我們提供了很大的靈活性,更符合用戶的操作習慣。在一個小小的微信對話
python基礎教程(五)
() 文件名 nal cnblogs 文件 求長 元素 fin 查詢 字符串基本操作 所有標準的序列操作(索引、分片、乘法、判斷成員資格、求長度、取最小值和最大值)對字符串同樣適用,前面已經講述的這些操作。但是,請註意字符串都是不可變的。 字符串的方法: 字符串從s
JXLS 2.4.0系列教程(二)——循環導出一個鏈表的數據
教程 super 最簡 com arraylist port 至少 ron mod 請務必先看上一篇文章,本文在上一篇文章的代碼基礎上修改而成。 JXLS 2.4.0系列教程(一)——最簡單的模板導出 上一篇文章我們介紹了JXLS和模板導出最簡單的應用,現在我們要更進一
JXLS 2.4.0系列教程(四)——多sheet是怎麽做到的
while director write 教程 == 模板 phy sheet ack 註:本文代碼在第一篇文章基礎上修改而成,請務必先閱讀第一篇文章。 http://www.cnblogs.com/foxlee1024/p/7616987.html 本文也不會過多的講解模
JXLS 2.4.0系列教程(四)——拾遺 如何做頁面小計
進行 line http spa shee shel nes 默認 閱讀 註:閱讀本文前,請先閱讀第四篇文章。 http://www.cnblogs.com/foxlee1024/p/7619845.html 前面寫了第四篇教程,發現有些東西忘了講了,這裏補
Spring Boot參考教程(五)Spring Boot配置使用之配置類用法
expr web程序 成功 驗證 pan hub parameter lan fix 4.2. SpringBoot配置使用之配置類使用 Spring Boot的大部分自動配置都可以滿足應用要求,但如果想精確的控制應用,或者想覆蓋自動配置,使用配置類是另一種很好的選擇,強調
Linux系列教程(六)——Linux文件搜索命令
www. 講解 -i linux鏈接 /tmp 任務 html 幫助文檔 大於 前一篇博客我們講解了Linux鏈接命令和權限管理命令, 通過 ln -s 鏈接名 表示創建軟鏈接,不加-s表示創建硬鏈接;還有三個更改權限的命令,chmod命令可以更改文件或目錄權限,ch
Linux系列教程(九)——Linux常用命令之網絡和關機重啟命令
route 註意 端口號 post rac pos 名稱 window ebo 前一篇博客我們講解了Linux壓縮和解壓縮命令,使用的最多的是tar命令,因為現在很多源碼包都是.tar.gz的格式,通過 tar -zcvf 能完成解壓。然後對於.zip格式的文件,使用g