
kudu和hbase的區別和聯絡
前提
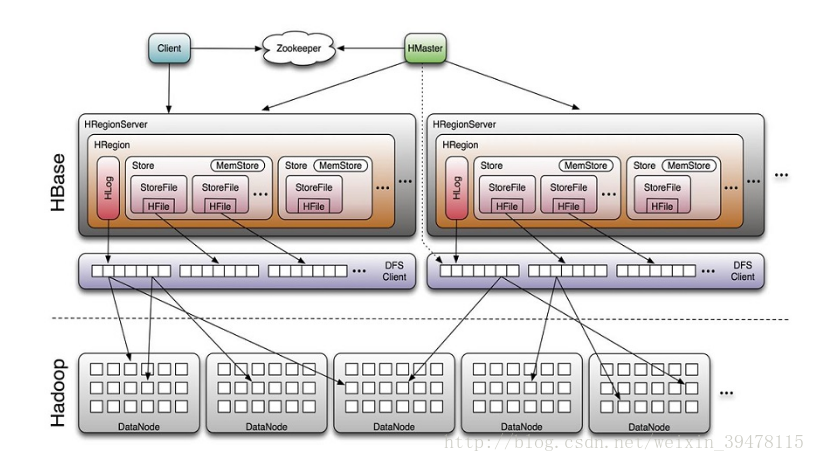
- hbase的物理模型是master和regionserver,regionserver儲存的是region,region裡邊很有很多store,一個store對應一個列簇,一個store中有一個memstore和多個storefile,store的底層是hfile,hfile是hadoop的二進位制檔案,其中HFile和HLog是hbase兩大檔案儲存格式,HFile用於儲存資料,HLog保證可以寫入到HFile中;
- kudu的物理模型是master和tserver,其中table根據hash和range分割槽,分為多個tablet儲存到tserver中,tablet分為leader和follower,leader負責寫請求,follower負責讀請求,總結來說,一個ts可以服務多個tablet,一個tablet可以被多個ts服務(基於tablet的分割槽,最低為2個分割槽);
聯絡
- 1、設計理念和想法是一致的;
- 2、kudu的思想是基於hbase的,之前cloudera公司向對hbase改造,支援大資料量更新,可是由於改動原始碼太大,所以todd直接開發了kudu;
- 3、hbase基於rowkey查詢和kudu基於主鍵查詢是很快的;
整體架構

Kudu結構看上去跟HBase差別並不大,主要的區別包括:
Kudu將HBase中zookeeper的功能放進了TMaster內,Kudu中TMaster的功能比HBase中的Master任務要多一些,kudu所有叢集的配置資訊均儲存在本地磁碟中,hbase的叢集配置資訊是儲存在zookeeper中;
Hbase將資料持久化這部分的功能交給了Hadoop中的HDFS,最終組織的資料儲存在HDFS上。Kudu自己將儲存模組整合在自己的結構中,內部的資料儲存模組通過Raft協議來保證leader Tablet和replica Tablet內資料的強一致性,和資料的高可靠性。為什麼不像HBase一樣利用HDFS來實現資料儲存,所以Kudu自己重新完成了底層的資料儲存模組,並將其整合在TServer中,但是kudu對磁碟的IO要求很高,它是以寫的效能換取讀的效能;
資料儲存方式

- HBase是面向列族式的儲存,每個列族都是分別存放的,HBase表設計時,很少使用設計多個列族,大多情況下是一個列族。這個時候的HBase的儲存結構已經與行式儲存無太大差別了。而Kudu,實現的是一個真正的面向列的儲存方式,表中的每一列都是單獨存放的;所以HBase與Kudu的差異主要在於類似於行式儲存的列族式儲存方式與典型的面向列式的儲存方式的差異;
- HBase是一款NoSQL型別的資料庫,對錶的設計主要在於rowkey與列族的設計,列的型別可以不指定,因為HBase在實際儲存中都會將所有的value欄位轉換成二進位制的位元組流。因為不需要指定型別,所以在插入資料的時候可以任意指定列名(列限定名),這樣相當於可以在建表之後動態改變表的結構。Kudu因為選擇了列式儲存,為了更好的提高列式儲存的效果,Kudu要求在建表時指定每一列的型別,這樣的做法是為了根據每一列的型別設定合適的編碼方式,實現更高的資料壓縮比,進而降低資料讀入時的IO壓力;
- HBase對每一個cell資料中加入了timestamp欄位,這樣能夠實現記錄同一rowkey和列名的多版本資料,另外HBase將資料更新操作、刪除操作也是作為一條資料寫入,通過timestamp來標記更新時間,type來區分資料是插入、更新還是刪除。HBase寫入或者更新資料時可以指定timestamp,這樣的設定可以完成某些特定的操作;
Kudu也在資料儲存中加入了timestamp這個欄位,不像HBase可以直接在插入或者更新資料時設定特殊的timestamp值,Kudu的做法是由Kudu內部來控制timestamp的寫入。不過Kudu允許在scan的時候設定timestamp引數,使得客戶端可以scan到歷史資料; - 相對於HBase允許多版本的資料存在,Kudu為了提高批量讀取資料時的效率,要求設計表時提供一列或者多列組成一個主鍵,主鍵唯一,不允許多個相同主鍵的資料存在。這樣的設定下,Kudu不能像HBase一樣將更新操作直接轉換成插入一條新版本的資料,Kudu的選擇是將寫入的資料,更新操作分開儲存;
- 當然還有一些其他的行式儲存與列式儲存之間在不同應用場景下的效能差異。
- hbase中,同一個主鍵資料是可以存在多個storefile裡的,為了讓mutation和磁碟的存在的key組合在一起,hbase需要基於rowkey執行merge。Rowkey可以是任意長度的字串,因此對比rowkey是非常耗效能的。另外,在一個查詢中,即使key列沒有被使用(例如聚合計算),它們也要被讀取出來,這導致了額外的IO。複合主鍵在hbase應用中很常見,主鍵的大小可能比你關注的列大一個數量級,特別是查詢的列被壓縮的情況下;
kudu中,讀取一條資料或者執行非排序查詢,不需要merge操作。例如,聚合一定範圍內的key可以獨立的查詢每個RowSet(甚至可以並行的),然後執行求和,因為key的順序是不重要的,顯然查詢的效率更高,kudu中,mutation是與rowid繫結的。所以merge會更加高效,通過維護計數器的方式,給定下一個需要儲存的mutation,我們可以簡單的相減,就可以得到從base data到當前版本有多少個mutation。或者,直接定址可以用來高效的獲取最新版本的資料。獲取block也非常的高效,因為mutation直接指向了block的索引地址; - hbase的系統中,每個cell的timstamp都是暴露給使用者的,本質上組成了這個cell的一個符合主鍵。意味著,這種方式可以高效的直接訪問指定版本的cell,且它儲存了一個cell的整個時間序列的所有版本;
而Kudu卻不高效(需要執行多個mutation),它的timestamp是從MVCC實現而來的,它不是主鍵的另外一個描述; - hbase採用的LSM(LogStructured Merge,很難對資料進行特殊編碼,所以處理效率不高),hbase會將多條更新記錄先後Flush到不同的Storefile中,所以讀取時需要掃描多個檔案,比較rowkey,比較版本等,然後進行更新操作,特別是major compaction操作的時候,會佔用大量的效能;
Kudu對同一行的資料更新記錄的合併工作,不是在查詢的時候發生的,而是在更新的時候進行,在Kudu中一行資料只會存在於一個DiskRowSet中,避免讀操作時的比較合併工作。對於列式儲存的資料檔案,要原地變更一行資料是很困難的,所以在Kudu中,對於Flush到磁碟上的DiskRowSet(DRS)資料,實際上是分兩種形式存在的,一種是Base的資料,按列式儲存格式存在,一旦生成,就不再修改,另一種是Delta檔案,儲存Base資料中有變更的資料,一個Base檔案可以對應多個Delta檔案(Kudu用MVCC(多版本併發控制)來實現資料的刪改功能。更新、刪除操作需要記錄到特殊的資料結構裡,儲存在記憶體中的DeltaMemStore或磁碟上的DeltaFIle裡面。DeltaMemStore是B-Tree實現的,因此速度快,而且可修改。磁碟上的DeltaFIle是二進位制的列式的塊,和base資料一樣都是不可修改的。因此當資料頻繁刪改的時候,磁碟上會有大量的DeltaFiles檔案,Kudu借鑑了Hbase的方式,會定期對這些檔案進行合併),這種方式意味著,插入資料時相比HBase,需要額外走一次檢索流程來判定對應主鍵的資料是否已經存在。因此,Kudu是犧牲了寫效能來換取讀取效能的提升。另外,如果在查詢中沒有指定key,那執行計劃就不會查閱key,除了需要確定key邊界情況; - hbase中insert和mutation是相同的操作,直接儲存到storefile中。
kudu中insert和mutation是不同的操作:insert寫入資料至MemRowSet,而mutation(delete、update)寫入存在這條資料的RowSet的DeltaMemStore裡,寫入時必須確定這是一條新資料。這會產生一個bloom filter查詢所有RowSet。如果布隆過濾器得到一個可能的match(即計算出可能在一個RowSet裡),接著為了確定是否是insert還是update,一個定址就必須被執行。 假設,只要RowSet足夠小,bloom filter的結果就會足夠精確,那麼大部分插入將不需要物理磁碟定址。另外,如果插入的key是有序的,例如timeseries+“_”+xxx,由於頻繁使用,key所在的block可能會被儲存在資料塊快取中。Update時,需要確定key在哪個RowSet。與上雷同,需要執行bloom filter。 這有點類似於關係型資料庫RDBMS,當插入一條主鍵存在的資料時會報錯,且不會更新這條資料。類似的,更新一條資料時,如果這條資料不存在也會報錯。hbase的語法卻不是這樣,它不存在主鍵的概念;
寫入和讀取過程
寫過程
- HBase寫的時候,不管是新插入一條資料還是更新資料,都當作插入一條新資料來進行;而Kudu將插入新資料與更新操作分別看待;
- Kudu表結構中必須設定一個唯一鍵,插入資料的時候必須判斷一些該資料的主鍵是否唯一,所以插入的時候其實有一個讀的過程;而HBase沒有太多限制,待插入資料將直接寫進memstore;
- HBase實現資料可靠性是通過將落盤的資料寫入HDFS來實現,而Kudu是通過將資料寫入和更新操作同步在其他副本上實現資料可靠性;
- 結合以上幾點,可以看出Kudu在寫的效能上相對HBase有一定的劣勢;
讀過程
- 在HBase中,讀取的資料可能有多個版本,所以需要結合多個storefile進行查詢;Kudu資料只可能存在於一個DiskRowset或者MemRowset中,但是因為可能存在還未合併進原資料的更新,所以Kudu也需要結合多個DeltaFile進行查詢;
- HBase寫入或者更新時可以指定timestamp,導致storefile之間timestamp範圍的規律性降低,增加了實際查詢storefile的數量;Kudu不允許人為指定寫入或者更新時的timestamp值,DeltaFile之間timestamp連續,可以更快的找到需要的DeltaFile;
- HBase通過timestamp值可以直接取出資料;而Kudu實現多版本是通過保留UNDO records(已經合併過的操作)和REDO records(未合併過的操作)完成的,在一些情況下Kudu需要將base data結合UNDO records進行回滾或者結合REDO records進行合併然後才能得到真正所需要的資料;
- 結合以上三點可以得出,不管是HBase還是Kudu,在讀取一條資料時都需要從多個檔案中搜尋相關資訊。相對於HBase,Kudu選擇將插入資料和更新操作分開,一條資料只可能存在於一個DiskRowset或者memRowset中,只需要搜尋到一個rowset中存在指定資料就不用繼續往下找了,使用者不能設定更新和插入時的timestamp值,減少了在rowset中DeltaFile的讀取數量。這樣在scan的情況下可以結合列式儲存的優點實現較高的讀效能,特別是在更新數量較少的情況下能夠有效提高scan效能;
- 另外,本文在描述HBase讀寫過程中沒有考慮讀寫中使用的優化技術如Bloomfilter、timestamp range等。其實Kudu中也有使用類似的優化技術來提高讀寫效能,本文只是簡單的分析,因此就不再詳細討論讀寫過程;
其他差異
- HBase:使用的java,記憶體的釋放通過GC來完成,在記憶體比較緊張時可能引發full GC進而導致服務不穩定;
- Kudu:核心模組用的C++來實現,沒有full gc的風險;
總結
- Kudu通過要求完整的表結構設定,主鍵的設定,以列式儲存作為資料在磁碟上的組織方式,更新和資料分開等技巧,使得Kudu能夠實現像HBase一樣實現資料的隨機讀寫之外,在HBase不太擅長的批量資料掃描(scan)具有較好的效能。而批量讀資料正是olap型應用所關注的重點,正如Kudu官網主頁上描述的,Kudu實現的是既可以實現資料的快速插入與實時更新,也可以實現資料的快速分析。Kudu的定位不是取代HBase,而是以降低寫的效能為代價,提高了批量讀的效能,使其能夠實現快速線上分析。
相關推薦
淺談Hive和HBase區別
但是 hql 應該 hdf 目前 http 返回 最重要的 hadoop基礎 出處: http://www.cnblogs.com/zlslch/p/5659641.html . 兩者分別是什麽? Apache Hive是一個構建在Hadoop基礎設施之上的數
KEIL、uVision和MDK區別和聯絡
--------------------------------------------- -- 時間:2018-11-26 -- 建立人:Ruo_Xiao -- 郵箱:[email protected] ----------------------------------------
Java 的equals()方法 和 == 的區別和聯絡
淺談Java中的equals和== 在初學Java時,可能會經常碰到下面的程式碼: String str1 = new String("hello"); String str2 = new String("hello"); System.out.print
關於union和join區別和聯絡
union和join是需要聯合多張表時常見的關聯詞,具體概念我就不說了,想知道上網查就行,因為我也記不準確。 先說差別:union對兩張表的操作是合併資料條數,等於是縱向的,要求是兩張表字段必須是相同的(Schema of both sidesof union should match.)。也就
Python pip 和pip3區別 聯絡
python 有python2和python3的區別 那麼pip也有pip和pip3的區別 大概是這樣的 pip是python的包管理工具,pip和pip3版本不同,都位於Scripts\目錄下: 如果
後端---Java中ArrayList和LinkedList區別和聯絡
ArrayList和LinkedList的區別和聯絡 在一個多月之前,我曾寫過一篇部落格想要迅速簡潔的瞭解Java中所有的集合型別(List、Set、Map),然後一個月多後的我不得已又抱起《Java核心卷I 》仔細研讀,這是為什麼呢??? 是因為“溫故而知新”還是因為“書讀百遍其
C#中結構體和類區別和聯絡
結構體 結構體定義 結構體是一種值型別,通常用來封裝小型相關變數組。例如座標或者商品的特徵。 結構體是一種自定義的資料型別,相當於一個複合容器,可以儲存多種型別。 結構體由結構體成員構成,結構體成員包含欄位,屬性與方法 結構體建
HIVE和HBASE區別
Hive中的表是純邏輯表,就只是表的定義等,即表的元資料。Hive本身不儲存資料,它完全依賴HDFS和MapReduce。這樣就可以將結構化的資料檔案對映為為一張資料庫表,並提供完整的SQL查詢功能,並將SQL語句最終轉換為MapReduce任務進行執行。 而HBase表是
Bagging演算法和Boosting區別和聯絡
參考文章連結:http://www.cnblogs.com/liuwu265/p/4690486.html Bagging和Boosting都是將弱分類器組裝成強分類器的方法 備註:弱分類器也是有一定限制的起碼分類效果要比隨機分類效果好,即準確率要大於50%, 否則即使
PCA和SVD區別和聯絡
前言: PCA(principal component analysis)和SVD(Singular value decomposition)是兩種常用的降維方法,在機器學習等領域有廣泛的應用。本文主要介紹這兩種方法之間的區別和聯絡。 一、PCA
Filter、Servlet和Listener區別與聯絡
1. Servlet 可以用來建立並返回一個包含基於客戶請求性質的動態內容的完整的html頁面;可以建立可嵌入到現有的html頁面中的一部分html頁面(html片段);可以讀取客戶端發來的隱藏資料;可以 讀取客戶端發來的顯示資料;可以與其他伺服器資源(包括資料庫和jav
知識點 - python 裝飾器@staticmethod和@classmethod區別和使用
定義 整潔 參數 sel spa elf pri Go assm 1.通常來說,我們使用一個類的方法時,首先要實例化這個類,再用實例化的類來調用其方法 class Test(object): """docstring for Test""" def
hashCode() 和equals() 區別和作用(轉)
person set集合 static out fin 解決 詳細 返回 art 出處:https://www.jianshu.com/p/5a7f5f786b75 本章的內容主要解決下面幾個問題: 1 equals() 的作用是什麽? 2 equal
Java之JSONObject存取值以及和HashMap區別, optString()和getString()區別和他的遍歷方式
結論: 1.JSONObject和HashMap用法上是一樣的,用put()方法存對於的Key-values鍵值對,取可用optString(key)和getString(key),get(key),存入的是什麼型別,取出來的時候就是什麼型別 2**.optString()在沒找到k
spring classpath:和classpath*:區別和實際應用
classpath:和classpath*:的含義 classpath: :表示從類路徑中載入資源,classpath:和classpath:/是等價的,都是相對於類的根路徑。資原始檔庫標準的在檔案系統中,也可以在JAR或ZIP的類包中。 classpath*::假設多個JAR包或檔
Mybatis和Hibernate區別和應用場景
hibernate: 是一個標準的ORM框架(物件關係對映)。入門門檻較高,不需要程式寫sql語句,sql語句自動生產了。 特點: 對sql的優化比較困難。 Hibernate對物件的維護和快取要比MyBatis好,對增刪改查的物件的維護要方便。 Hibernate資料庫移植性很好,MyB
Service和IntentService 區別和使用
背景 最近開發遇到一個小小的問題,因為沒怎麼用過IntentService ,所以對其生命週期也不很瞭解,還有工作原理。 intentService 詳解 intentService ——>> StartService 第一次 intent
G++和C++區別和評測注意事項
G++和C++的區別和評測注意事項 下面摘抄自網際網路 G++ 首先更正一個概念,C++是一門計算機程式語言,G++不是語言,是一款編譯器中編譯C++程式的命令而已。 那麼他們之間的區別是什麼? 在提交題目中的語言選項裡,G++和C++都代表編譯的方式。準確地說
BTC和BCH 區別和聯系?
升級問題 fff 手續費 升級 現在 風險 個人電腦 電網 pan 在比特幣剛剛出現的時期,中本聰對區塊的大小限制在1M。這種限制既保障性能較弱的個人電腦能夠參與其中,同時也起到了防止攻擊者讓比特幣網絡超載的風險發生,畢竟那時系統還很脆弱。在1M的限制下,10分鐘一個區塊最
SparkSQL(8):DataSet和DataFrame區別和轉換
1.概念: (1)DataSet和RDD 大資料的框架許多都要把記憶體中的資料往磁盤裡寫,所以DataSet取代rdd和dataframe。因為,現階段底層序列化機制使用的是java的或者Kryo的形式。但是,java序列化出來的資料很大,影響儲存Kryo對於小資料量