
【collection】集合學習——Set 之 HashSet
前言
jdk 版本 jdk1.8.0_161
UML結構圖
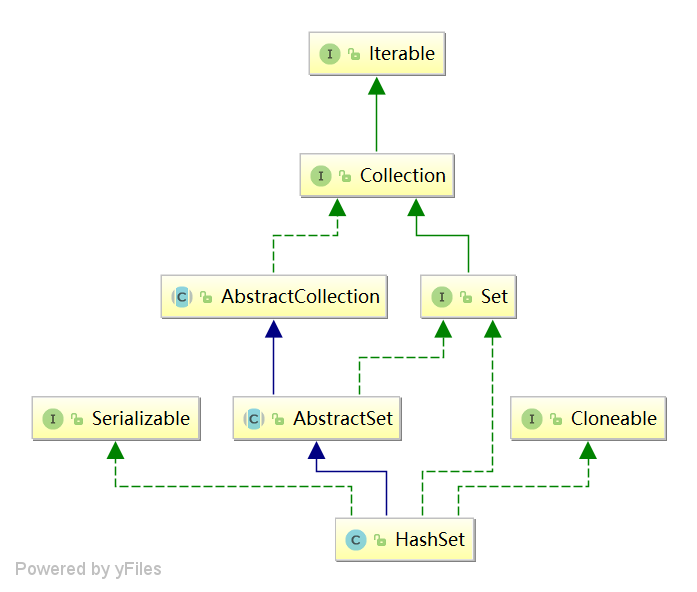
說明:結構 和 前面的 ArrayList 以及 LinkedList 很類似。
Set:不包含重複元素的 集合 ,從 它的名字可以看出,該介面的模型是 數學上的 Set (集合)抽象。數學上的集合 的特性是 無序性,確定性,互異性。
AbstractSet:Set 介面的骨架實現;
HashSet:實現了 Set 介面,由 雜湊表( hash table ) 支援(內部資料結構實際上是一個 HashMap 例項,值儲存在HashMap例項的 key 中)。不能保證集合的迭代順序,支援 null 值,不包含重複的元素。
假設 雜湊函式將 元素 正確地分散在 桶(buckets)中, 那麼該類的 add , remove , contains, size 方法 均為 常量時間。在這個集合上迭代的時間 和 HashSet 例項的 size(即元素數量) 加上 支援 HashMap 例項 容量 (桶的數量)的總和 是成比例的。因此,如果對迭代要求比較高的,不要設定太大的初始化容量,也不要設定太低的 載入因子。
原始碼分析
建構函式:
private transient HashMap<E,Object> map; /** * 構造一個新的,空的集合 * HashMap 例項有預設的初始化容量16 以及 預設的載入因子 0.75 */ public HashSet() { map = new HashMap<>(); } /** *構造一個包含指定集合元素的集合 * HashMap 使用預設的載入因子 * 以及足以容納元素的初始容量的初始化容量初始化 */ public HashSet(Collection<? extends E> c) { map = new HashMap<>(Math.max((int) (c.size()/.75f) + 1, 16)); //計算最小容量 addAll(c); } /** * 制定初始化容量 和 載入因子 */ public HashSet(int initialCapacity, float loadFactor) { map = new HashMap<>(initialCapacity, loadFactor); } /** * 指定初始化容量,使用預設的載入因子 0.75 */ public HashSet(int initialCapacity) { map = new HashMap<>(initialCapacity); } /** * 構造一個新的, 空的 LinkedHashSet * 作用域為 預設的,即包內可見 */ HashSet(int initialCapacity, float loadFactor, boolean dummy) { map = new LinkedHashMap<>(initialCapacity, loadFactor); }
內部資料結構
HashMap 例項:相關方法 均來自於 HashMap 類中的 實現方法
private transient HashMap<E,Object> map;增刪原始碼
增加一個元素:
/** * 如果指定元素不存在的話,將元素新增到 Set 集合中. * 如果 集合中已經存在該元素,集合保持不變,並且返回 false */ public boolean add(E e) { return map.put(e, PRESENT)==null; } private transient HashMap<E,Object> map; // map 中 鍵 的對應值 均為 該物件 private static final Object PRESENT = new Object();
刪除元素:
public boolean remove(Object o) {
return map.remove(o)==PRESENT;
}相關推薦
【collection】集合學習——Set 之 HashSet
前言 jdk 版本 jdk1.8.0_161 UML結構圖 說明:結構 和 前面的 ArrayList 以及 LinkedList 很類似。 Set:不包含重複元素的 集合 ,從 它的名字可以看出,該介面的模型是 數學上的 Set (集合
【java】集合學習——Map 之 LinkedHashMap
前言 jdk 版本 jdk1.8.0_161 UML結構圖 LinkedHashMap:Map 介面的 雜湊表 和 連結列表的 實現。 相對於 HashMap 的特性是:有序性(插入元素的順序有序),因為內部使用了 雙向連結串列實現。 原始碼 建構函式 主要
java集合系列——Set之HashSet和TreeSet介紹(十)
最大 ... gpo 鏈表 key 同步 中大 nds set接口 一.Set的簡介Set是一個不包含重復元素的 collection。更確切地講,set 不包含滿足 e1.equals(e2) 的元素。對 e1 和 e2,並且最多包含一個為 null 的元素。 Set的類
【轉】Java學習---HashMap和HashSet的內部工作機制
link 實踐 離散 val 數據結構 結構 通過 如何 factor 【原文】https://www.toutiao.com/i6593863882484220430/ HashMap和HashSet的內部工作機制 HashMap 和 HashSet 內部是如何工作的?散
【原】javascript學習筆記之this用法
javascript中的this學習起來相對複雜,最近花了點時間研究,總結起來大概這隻有5種情況,相信只要熟悉這5種用法,基本是可以解決所有的this問題,文字不介紹this設計原理,只介紹用法,閱讀本文,你需要了解javascript執行上下文環境,博主寫這種文章的目的,主要還是給自己做下筆記,後續也會輸出
【python】機器學習實戰之樸素貝葉斯分類
一,引言 前兩章的KNN分類演算法和決策樹分類演算法最終都是預測出例項的確定的分類結果,但是,有時候分類器會產生錯誤結果;本章要學的樸素貝葉斯分類演算法則是給出一個最優的猜測結果,同時給出猜測的概率估計值。 1 準備知識:條件概率公式 相信學過概率論的同學對於概
【原創】Selenium學習系列之(七)—ConnectDB和複用測試方法
一篇來說一下Webdriver中連線DB合複用測試方法。 兩個完全不搭邊的東西怎麼說明呢,既然不好說那就不多說,通過例子來理解。 需求我們要實現一個這樣的測試情境: 登入系統時,若loginID正確,但密碼錯誤,連續三次密碼輸入錯誤後,系統會lock user。 怎麼實現呢
JAVASE之集合(二)【Collection】
Collection在官方API文件中,被叫做集合的根介面。(the root interface in the collection hierarchy)最後一個單詞我不認識 但是讀起來挺好聽的 海爾ragei 層次的意思。應該是說明了Collection的地位比較重。
【java】java學習之路-01-Linux基礎(一)
x文件 字母 at命令 超過 用戶登錄 創建刪除 軟連接 nbsp tail linux學習方法: 你的程序要在服務器(linux)上執行,服務器沒有桌面系統,學習linux就是學習命令。 一、Linux介紹 1、芬蘭大學生,名字叫Linux,因為個人興趣,編寫了一個類Un
【轉】Java學習---Java核心數據結構(List,Map,Set)使用技巧與優化
系統資源 .get 兩種 這樣的 his java學習 com 都是 索引 【原文】https://www.toutiao.com/i6594587397101453827/ Java核心數據結構(List,Map,Set)使用技巧與優化 JDK提供了一組主要的數據結構實現
【ML2】機器學習之線性迴歸
【知識儲備】 線性迴歸: 1: 函式模型(Model): 假設有訓練資料 那麼為了方便我們寫成矩陣的形式 2: 損失函式(cost): 現在我們需要根據給定的X求解W的值,這裡採用最小二乘法。
【ML1】機器學習之EM演算法(含演算法詳細推導過程)
寫在前面的話:對於EM演算法(Expectation Maximization Algorithm, 最大期望演算法), 大家如果僅僅是為了使用,則熟悉演算法流程即可。此處的演算法推導過程,僅提供給大家進階 之用。對於其應用,
【python3】爬蟲學習日記(一)之概述
python3爬蟲學習日記(一)之概述 在學習了python3的基本語法知識後,小白要正式入門python啦,由於個人需要,所以從爬蟲入門。在學習中持續更新,如有不足,請指教。 爬蟲的定義及構成 什麼是爬蟲? 網路爬蟲是一個自動提取網頁的程式,它為搜尋引擎
【JAVA】JTable學習之使用AbstractTableModel (二) 完結
在上一篇的文章中 我們知道,JTable的表格和資料是分開的,每一個Jtable都會有自己的TableModel,在其內部都有一個二維 的Vector(假如是Vector TableData)用來存放二維的表格資料,每個表格都與這個二維的Vector形成對映關係,當表格Table顯示的時候通過Tab
【JAVA】JTable學習之使用AbstractTableModel (一)
Note : 本例項中涉及到了Java中的Vector的使用,建議先了解Vector的使用方法, [不想看我白話的話,就直接跳到後面看程式碼與貼圖,程式碼註釋很詳細] 我表示寫這篇文章很糾結、、因為我是比較熱衷於C++的,在Java方面的理解還不是那麼的深刻,萬一理解片面了,誤
【福利】日語學習資料大集合!6G資源!
留下來以備不時只需 另外補充一點:看漫畫有聲學日語 http://anime-manga.jp/,支援四國語言+世界語。 Heart Water---- 這是我去年發在豆瓣“自學日語中”小組和“JLPT-日語能力測試”小組的帖子,陸陸續續更新了7次,發了43個資源,總計
【2】機器學習之兄弟連:K近鄰和K-means
關鍵詞:從K近鄰到最近鄰,監督學習,資料帶lable,效率優化(從線性搜尋到kd樹搜尋),缺點是需要儲存所有資料,空間複雜度大。可以利用kd數來優化k-means演算法。 學習了kNN和K-means演算法後,仔細分析比較了他們之間的異同以及應用場景總結成此文供讀者參
【十】機器學習之路——logistic迴歸python實現
前面一個部落格機器學習之路——logistic迴歸講了logistic迴歸的理論知識,現在咱們來看一下logistic迴歸如何用python來實現,程式碼、資料參考《機器學習實戰》。 首先看下我們要處理的資料, 我們要做的就是通過logistic
【七】機器學習之路——訓練集、測試集及如何劃分
上一個部落格講了一個簡單的例子,根據手頭的房子大小和房價的資料來擬合房子大小和房價的關係曲線,當然這是一個非常簡單的一元一次方程,y=ax+b。但是最後咱們還少了一樣東西,不知道細心的同學有沒有發現,那就是咱們擬合曲線的準確度到底有多少呢?怎麼來檢測咱們擬合
【收藏】機器學習的Pytorch實現資源集合【附下載連結】
該專案用pytorch實現了從最基本的機器學習演算法:迴歸、聚類,到深度學習、強化學習等。該專案