
演算法分析——排序演算法(歸併排序)複雜度分析(遞迴樹法)
前面對演算法分析的一些常用的 漸進符號 做了簡單的描述,這裡將使用歸併排序演算法做為一個實戰演練。
這裡首先假設讀者對歸併排序已經有了簡單的瞭解(如果不瞭解的同學可以自行百度下歸併排序的原理)。瞭解此演算法的同學應都知道,歸併排序的主要思想是分而治之(簡稱分治)。分治演算法的基本模式也基本上分為以下三大步驟:
1.問題分解成若干子問題,使子問題的解決起來足夠簡單,甚至達到常量級別θ(1)
2.子問題解決
3.合併
在演算法分析中也將會根據這三大步驟進行復雜度的分析和合並。下面將給出虛擬碼,並針對虛擬碼進行復雜度分析。
虛擬碼
// Merge Sort Code MergeSort(A,start,end){ if(start < end) then mid <- floor[(start-end)/2] MergeSort(A,start,mid); MergeSort(A,mid,end); Merge(A,start,mid,end); } // Merge Code Merge(A,start,mid,end){ // 建立左陣列 left <- mid - start + 1; create arrays L[1...left]; for i <- 1 to left L[i] = A[start + i -1]; // 建立右陣列 right = end - mid; create arrays R[1...right ]; for j <- 1 to right R[j] = A[mid + j]; // 合併 i <- 1; j <- 1; for k <- start to end do if L[i] <= R[j] then A[k] = L[i]; i++; if i > left then TailInsert(A,start + k,R,j) break; else A[k] = R[j]; j++; if j > right then TailInsert(A,start + k,L,i) break; } // 直接將B中的起始位置為q至結尾的元素插入到A陣列的p起始位置 TailInsert(A,p,B,q){ k <- 0; for i <- q to length(B) A[p + k] = B[i]; k++; }
空間複雜度
由虛擬碼可以看出,歸併排序實現的主要實現的原理是由上至下遞迴的二分原陣列,並由下至上遞迴的合併二分後的子陣列,由於每次陣列的分裂都需要建立兩個新的陣列,所以其實歸併排序的空間複雜度是較高的,可達到O(n)。可能有些小夥伴會在空間複雜度到底是O(n)還是O(nlogn)之間存在疑惑,因為由虛擬碼可以得出歸併演算法的整個過程會複製log(n)個大小為n的陣列,那為什麼空間複雜度不是O(nlog(n))呢?①
時間複雜度
通過虛擬碼可以看出,歸併排序通過分治和遞迴對陣列A進行不斷的問題分解和合並,而針對遞迴式的演算法分析, 演算法導論中講述了多種方法,例如代換法、遞迴樹法、主方法。下面將使用多種方式對歸併排序進行復雜度的增長量級進行分析。
由於代換法需要事先估測一個大致的值,然後才能做進一步的代換驗證,而遞迴樹法是比較適合預測一個估值,所以我們首先將使用遞迴樹法進行時間複雜度的分析。
遞迴樹法分析
假設輸入規模n時,歸併演算法的時間複雜度為T(n),由虛擬碼可知歸併演算法中分為兩步:子陣列排序、子數組合並,由此可得T(n)= 2T(n/2 )+ cn , c為大於0的一個常數。如果將該公式用樹形結構來表示的話,則如下所示:
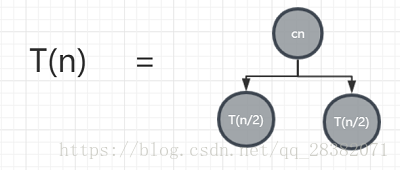
因為T(n)= 2T(n/2 )+ cn,可得T(n/2)= 2T(n/4)+ c(n/2),所以T(n)則可以推出下圖:
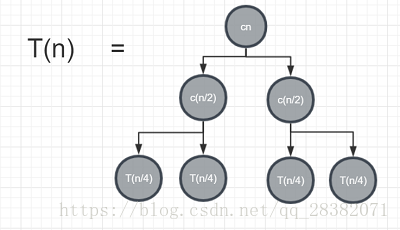
依次遞推可以得到一個深度為,葉子節點個數為n,值為T(1)的樹形圖。如下圖所示:
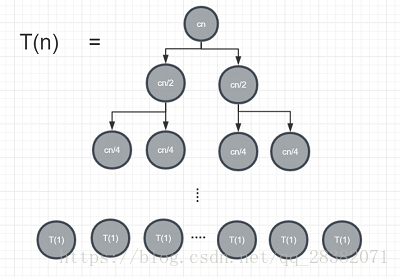
此時將樹形圖中所有的節點進行加和即可得到歸併排序的時間複雜度 ②
標註①
1.程式的執行是線上程棧中,一次方法的呼叫和返回代表著一個棧幀的入棧和出棧,棧幀出棧後,該棧幀中的臨時變數所佔用的空間都會得到釋放
2.copy陣列的操作都是在merge方法中執行,而merge方法的執行是在MergeSort的尾部,再加上程式執行的順序性和遞迴的特點,也就是說整個演算法所在的執行緒棧中只會存在一個merge方法,而merge方法從下往上依次歸併的時候,merge方法所需要的空間分別為2,4,8......n,直到return到第一層MergeSort方法時,merge方法所需要的空間才會達到最高n,由於遞迴從底層依次返回到上一層時,底層棧幀所佔用的空間就會得到釋放,所以歸併演算法的空間複雜度在遞迴返回到首層棧幀時最大,為O(n)。
標註②
相關推薦
演算法分析——排序演算法(歸併排序)複雜度分析(遞迴樹法)
前面對演算法分析的一些常用的 漸進符號 做了簡單的描述,這裡將使用歸併排序演算法做為一個實戰演練。 這裡首先假設讀者對歸併排序已經有了簡單的瞭解(如果不瞭解的同學可以自行百度下歸併排序的原理)。瞭解此演算法的同學應都知道,歸併排序的主要思想是分而治之(簡稱分治)。分治演算法
演算法分析——排序演算法(歸併排序)複雜度分析(代換法)
上篇文章中我們對歸併排序的時間複雜度使用遞迴樹法進行了簡答的分析,並得出了結果歸併排序的時間複雜度為,這裡將使用代換法再進行一次分析。使用代換法解遞迴式的時候,主要的步驟有兩步: 1)猜測解的結果 2)使用數學歸納法驗證猜測結果
演算法分析——排序演算法(歸併排序)複雜度分析(主定理法)
前兩篇文章中分別是要用遞迴樹、代換法對歸併排序的時間複雜度進行了簡單的分析和證明,經過兩次分析後,我們發現遞迴樹法的特點是:可以很直觀的反映出整個歸併排序演算法的各個過程,但因為要畫出遞迴樹所以比較麻煩,所以遞迴樹演算法更適合新手,因為它可以讓分析者更直觀、簡易
資料結構與演算法筆記(二)複雜度分析
2. 複雜度分析 2.1 什麼是複雜度分析 資料結構和演算法的本質:快和省,如何讓程式碼執行得更快、更省儲存空間。 演算法複雜度分為時間複雜度和空間複雜度,從執行時間和佔用空間兩個維度來評估資料結構和演算法的效能。 複雜度描述的是演算法執行時間(或佔用空間)與資料規模的增長關
資料結構與演算法(一)——複雜度分析(上)
資料結構與演算法(一)—— 複雜度分析(上) 基礎知識就像是一座大樓的地基,只有打好基礎,才能造成萬丈高樓。資料結構與演算法是一個程式設計師的內功,只有基礎足夠紮實,才能有效提高自己的技術能力,寫出更高效、擴充套件性更好的優秀程式碼。寫這個系列記錄一下自己學習的
資料結構與演算法(二)——複雜度分析(下)
資料結構與演算法(二)—— 複雜度分析(下) 除了前面記錄的複雜度的基礎知識,還有四個複雜度分析方面的知識點:最好情況時間複雜度、最壞情況時間複雜度、平均情況時間複雜度、均攤時間複雜度。 一、最好、最壞情況時間複雜度 最好情況時間複雜度,就是在最理想的情況下,
《資料結構與演算法之美》專欄閱讀筆記1——複雜度分析
蹭可愛的男朋友買的極客時間的專欄【資料結構與演算法之美】,作者讓大家定個學習的flag。o( ̄▽ ̄)o,好吧,最近喜歡做思維導圖(純粹因為好看!),所以flag就是每篇都要寫讀書筆記咯~ 文章目錄 1、如何抓住重點,系統
堆排序的JAVA實現及時間複雜度分析
堆排序是一個比較常用的排序方式,下面是其JAVA的實現: 1. 建堆 // 對輸入的陣列進行建堆的操作 private static void buildMaxHeap(int[] array, int length) { // 遍歷所有
二叉樹遍歷(四種方式、迭代及遞迴的實現)
二叉樹的常見遍歷方式主要有前序,中序和後序,以及層次遍歷(從上到下,從左到右)四種方法。 前、中、後遍歷分別順序如下: 分別通過遞迴和迴圈的方式實現(Python): # -*- coding:utf-8 -*- class TreeNode: def __
二叉樹的非遞迴遍歷(前序中序後序非遞迴C語言)
前兩天做資料結構實驗,要求用非遞迴演算法遍歷二叉樹。只知道用棧來儲存資料,具體演算法還不太清楚。經過兩天的搜尋,看到網上很多種解法,很多解法都是用C++來寫的演算法,一直找不到用C語言寫的演算法,所以就總結了一下,用C寫出了一個遍歷二叉樹的三種非遞迴演算法。 前
演算法 歸併排序的複雜度分析(含圖解流程和Master公式)
圖解流程 整體流程如下: 細節流程: 第一步: 第二步: 第三步: 第四步: 第五步: 第六步: 第七步: 第八步:
資料結構和演算法分析之排序篇--歸併排序(Merge Sort)和常用排序演算法時間複雜度比較(附贈記憶方法)
歸併排序的基本思想 歸併排序法是將兩個或以上的有序表合併成一個新的有序表,即把待排序序列分成若干個子序列,每個子序列是有序的。然後再把有序子序列合併為整體有序序列。注意:一定要是有序序列! 歸併排序例項: 合併方法: 設r[i……n]由兩個有序子表r
演算法導論 第二章:演算法入門 筆記 (插入排序、迴圈不變式、演算法分析、最好和最壞時間複雜度、選擇排序、分治法、合併排序)
插入排序: 排序問題的定義如下: 輸入:N個數{a1, a2,..., an }。 輸出:輸入序列的一個排列{a'1 ,a'1 ,...,a'n },使得a'n <=a' n<=...<
【Java】 大話資料結構(17) 排序演算法(4) (歸併排序) 資料結構與演算法合集 資料結構與演算法合集
本文根據《大話資料結構》一書,實現了Java版的堆排序。 更多:資料結構與演算法合集 基本概念 歸併排序:將n個記錄的序列看出n個有序的子序列,每個子序列長度為1,然後不斷兩兩排序歸併,直到得到長度為n的有序序列為止。 歸併方法:每次在兩個子序列中找到較小的那一個賦值給合併序列(通過指標進行操
O(n*logn)級別的演算法之一(歸併排序及其優化)
原理: 設兩個有序的子序列(相當於輸入序列)放在同一序列中相鄰的位置上:array[low..m],array[m + 1..high],先將它們合併到一個區域性的暫存序列 temp (相當於輸出序列)中,待合併完成後將 temp 複製回 array[low..high]中,從而完成排序。 在具體的合併過
O(n*logn)級別的演算法之一(歸併排序)
測試用例: #ifndef INC_02_MERGE_SORT_SORTTESTHELPER_H #define INC_02_MERGE_SORT_SORTTESTHELPER_H #include <iostream> #include <
排序演算法 (穩定性時間複雜度分析)
1、 選擇排序、快速排序、希爾排序、堆排序不是穩定的排序演算法, 氣泡排序、插入排序、歸併排序和基數排序是穩定的排序演算法。 2、研究排序演算法的穩定性有何意義? 首先,排序演算法的穩定性大家應該都知道,通俗地講就是能保證排序前兩個相等的資
常見比較排序演算法的實現(歸併排序、快速排序、堆排序、選擇排序、插入排序、希爾排序)
這篇部落格主要實現一些常見的排序演算法。例如: //氣泡排序 //選擇排序 //簡單插入排序 //折半插入排序 //希爾排序 //歸併排序 //雙向的快速排序(以及快速排序的非遞迴版本) //單向的快速排序 //堆排序 對於各個演算法的實現
演算法1:求逆序對數與顯著逆序對數(歸併排序)
寫在前面:由本文開始記錄本人的演算法刷題之路,日後會不定期更新,歡迎討論!本系列系本人原創,如需轉載或引用,請註明原作者及文章出處。 求逆序對數問題是歸併排序的基礎問題,顯著逆序對數則是逆序對數的升級
分治演算法(歸併排序、一維點對、HDU-1007)
分治演算法的基本思想是將一個規模為N的問題分解為K個規模較小的子問題,這些子問題相互獨立且與原問題性質相同。求出子問題的解,就可得到原問題的解。 分治法解題的一般步驟: 分解,將要解決的問題劃分成若干規模較小的同類問題; 求解,當子問題劃分得足夠小時,