
spark環境構建及示例
spark提供了三種叢集模式:standalone、yarn以及Mesos,三種模式裡面standalone模式是一個基礎,本篇先從standalone模式講解一個基礎的spark叢集搭建過程,並且基於這個叢集我們再介紹一下spark-shell的使用、spark提供的例子如何執行,以及開發一個簡單的例子通過任務提交的方式執行起來。
Spark叢集搭建(standalone模式)
安裝
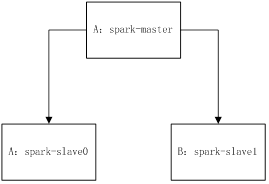
我們以兩臺機器作為叢集搭建,其中spark-master作為master,同時也作為slave,名稱為spark-slave0,另外一臺機器作為slava,名稱為spark-slave1,他們的網路架構如下圖所示:
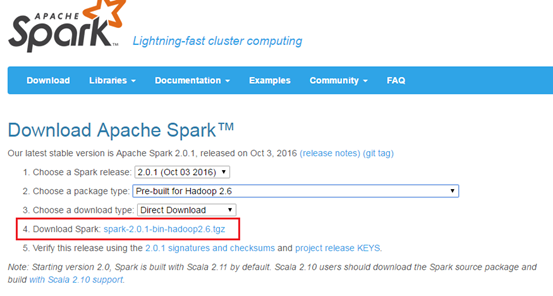
步驟2:tar -xvf spark-2.0.1-bin-hadoop2.6
步驟3:cd ./spark-2.0.1-bin-hadoop2.6/conf
步驟4:cp slaves.template slaves
步驟5:cp spark-env.sh.template spark-env.sh
步驟6:修改啟動環境變數指令碼vim spark-env.sh,新增
export JAVA_HOME="/usr/local/java" export SCALA_HOME="/usr/local/scala" export SPARK_HOME="/data/spark-2.0.1-bin-hadoop2.6" export SPARK_MASTER_HOST=spark-master export SPARK_WORKER_CORES=1 export SPARK_WORKER_INSTANCES=1 export SPARK_MASTER_PORT=7077 export SPARK_WORKER_MEMORY=1g export MASTER=spark://${SPARK_MASTER_IP}:${SPARK_MASTER_PORT}
步驟7:修改slaves配置,vim slaves,新增
spark-slave0
spark-slave1
步驟8:系統環境變數配置(假設系統已安裝jdk及scala),vim /etc/profile,新增
export JAVA_HOME="/usr/local/java"
export SPARK_HOME="/data/spark-2.0.1-bin-hadoop2.6"
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib
步驟9:source /etc/profile
步驟10:修改host配置 vim /etc/hosts 新增
A-host-ip spark-master
A-host-ip spark-slave0
B-host-ip spark-slave1
注:此處請務必注意,A-host-ip一定要寫的是A機器的IP,而不是127.0.0.1,如果是寫了後者,master啟動後會只監聽本地迴環地址127.0.0.1,而導致其他slave例如B機器連線被拒絕。
步驟11:B機器配置按照A機器配置完全一樣複製一份即可。
配置ssh叢集間無密登入
步驟1:確保A,B機器之間ping通
步驟2:關閉防火牆限制
2.1、重啟後生效
開啟: chkconfigiptables on
關閉: chkconfigiptables off
2.2、即時生效,重啟後失效
開啟: service iptablesstart
關閉: service iptables stop
步驟3:使用root使用者在各個節點建立金鑰對
[[email protected] ~]$ ssh-keygen -t rsa
[[email protected] ~]$ ssh-keygen -t rsa
如下所示:
[[email protected] conf]# ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/root/.ssh/id_rsa):
/root/.ssh/id_rsa already exists.
Overwrite (y/n)? y
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /root/.ssh/id_rsa.
Your public key has been saved in /root/.ssh/id_rsa.pub.
The key fingerprint is:
c5:54:cf:ee:3b:43:19:9d:63:72:11:83:d5:84:b6:ad [email protected]
The key's randomart image is:
+--[ RSA 2048]----+
| ... o*+|
| o +o.o|
| o .o+o|
| . oo=o|
| S =+.|
| .E |
| .. |
| o. |
| .o |
+-----------------+
這樣執行之後就在/root/.ssh/目錄下生成了一對ssh的公私鑰。id_rsa 以及id_rsa.pub
步驟4:切換到spark-master節點合併節點公鑰。
[[email protected]]$ ssh spark-slave1cat /root/.ssh/id_rsa.pub>>authorized_keys
[[email protected]]$ ssh spark-slave0cat /root/.ssh/id_rsa.pub>>authorized_keys
兩臺slave的公鑰在master上合併完成。
注:本例採用的是root賬號執行,如果你採用的是hadoop賬號執行以上所有安裝操作就需要修改authorized_keys檔案的屬性(.ssh目錄為700,authorized_keys檔案為600,用chmod命令修改),不然ssh登入的時候還需要密碼。
步驟5:驗證一下ssh無密是否成功:[[email protected] .ssh]$ ssh spark-slave1 date
啟動standalone叢集
cd /data/spark-2.0.1-bin-hadoop2.6/sbin
./start-all.sh
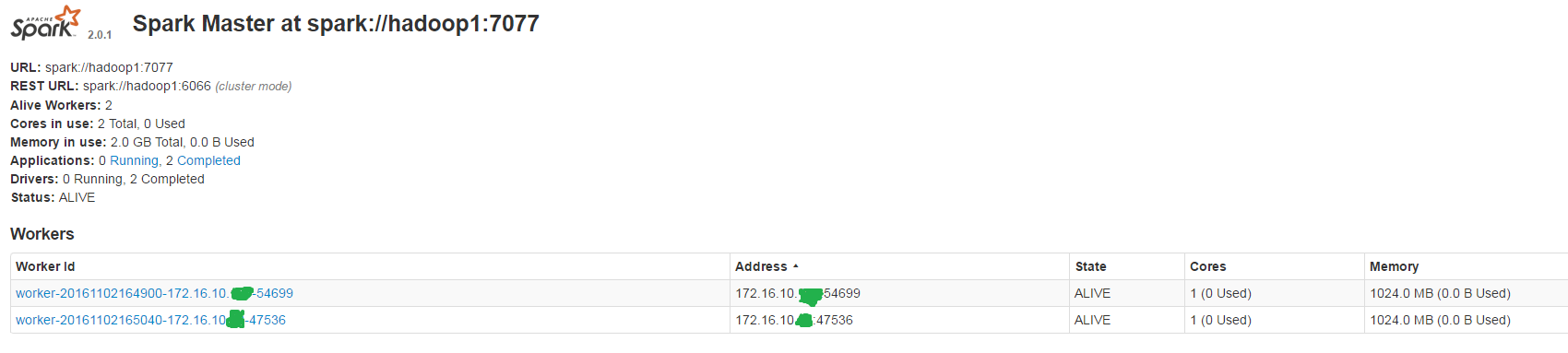
啟動之後,master有一個webui介面,訪問如下地址:http://A:8080如下
Spark-shell使用
Spark-shell提供了基於scala語言的指令碼執行環境,在啟動的時候會自動建立一個名為sc的sparkContext上下文,具體啟動方式
cd /data/spark-2.0.1-bin-hadoop2.6/bin
./spark-shell
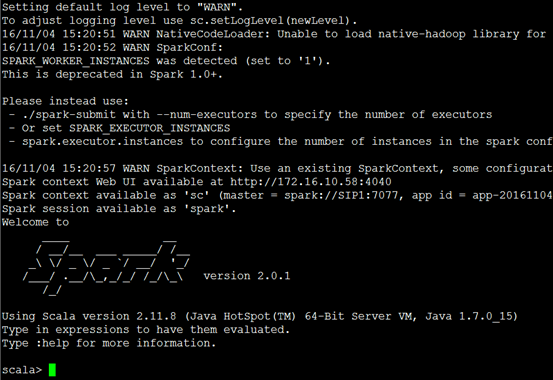
執行一條簡單的陣列各元素累加的scala命令
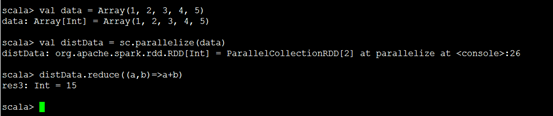
另外spark-shell還可以提交任務來允許,如下幾種模式:
本地master4核執行
$ ./bin/spark-shell --master local[4]新增jar包載入到classpath執行
$ ./bin/spark-shell --master local[4] --jars code.jar還可以新增maven的dependency執行
$ ./bin/spark-shell --master local[4] --packages "org.example:example:0.1"任務提交
我們首先編寫一個RDD(spark的儲存檔案型別,後續章節我們重點介紹下RDD的結構)測試小程式,通過這個小程式打包jar提交到我們剛才搭建的環境中執行。Spark任務提交是通過spark-submit來提交的,一個典型的spark-submit的引數解釋如下:
./bin/spark-submit \
--class <main-class> \
--master <master-url> \
--deploy-mode <deploy-mode> \
--conf <key>=<value> \
... # other options
<application-jar> \
[application-arguments]
--class 要執行的類
--master sparkmaster的地址,一般的寫法是spark://host:port
--deploy-model 部署模式叢集執行cluster:叢集各節點分散式執行client:本地執行
請注意cluster執行的時候master一定要寫它的rest地址,這個可以再master的webui上檢視具體地址。
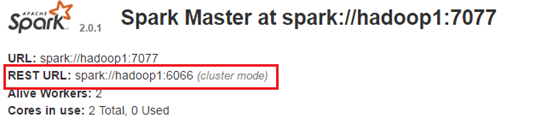
--conf spark的配置引數,鍵值對形式
Application-jar 所需要執行的jar包路徑
我們編寫的小例項:
Pom.xml檔案如下
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>spark.test</groupId>
<artifactId>rdd</artifactId>
<version>1.0</version>
<dependencies>
<dependency> <!-- Spark dependency -->
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.10</artifactId>
<version>1.6.1</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_2.10</artifactId>
<version>1.6.1</version>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>commons-cli</groupId>
<artifactId>commons-cli</artifactId>
<version>1.2</version>
</dependency>
</dependencies>
</project>
package rdd;
import java.util.Arrays;
import java.util.HashMap;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.Function2;
/**
*
* @author flyking
*
*/
public class TestRDD {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setMaster("spark://master:port").setAppName("SimpleRDD");
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<Integer> rdd = sc.parallelize(Arrays.asList(1, 2, 3 ,3), 2);
System.out.println("rdd collect" + rdd.collect());
System.out.println("rdd count" + rdd.count());
System.out.println("rdd countByValue" + rdd.countByValue());
System.out.println("rdd take" + rdd.take(2));
System.out.println("rdd top" + rdd.top(2));
System.out.println("rdd takeOrdered" + rdd.takeOrdered(2));
System.out.println("rdd map "+ rdd.map(new Function<Integer, HashMap<String,Integer>>() {
public HashMap<String,Integer> call(Integer v1) throws Exception {
return (HashMap<String, Integer>) new HashMap().put(String.valueOf(v1), v1);
}
}));
System.out.println("rdd reduce" + rdd.reduce(new Function2<Integer, Integer, Integer>() {
public Integer call(Integer v1, Integer v2) throws Exception {
return v1+v2;
}
}));
}
}
把檔案上傳到master伺服器/data/rdd-1.0.jar,我們採取本地模式提交任務執行
cd /data/spark-2.0.1-bin-hadoop2.6/bin
./spark-submit --class rdd.TestRDD --master local[2] --executor-memory 2G --num-executors 5 /data/rdd-1.0.jar
執行後的結果如下:
rdd collect[1, 2, 3, 3]
rdd count4
rdd countByValue{2=1, 1=1, 3=2}
rdd take[1, 2]
rdd top[3, 3]
rdd takeOrdered[1, 2]
rdd map MapPartitionsRDD[6] at map at TestRDD.java:26
rdd reduce9
相關推薦
spark環境構建及示例
spark提供了三種叢集模式:standalone、yarn以及Mesos,三種模式裡面standalone模式是一個基礎,本篇先從standalone模式講解一個基礎的spark叢集搭建過程,並且基於這個叢集我們再介紹一下spark-shell的使用、spark提供的例子
基於VS2013 MFC的OPENCV3.1環境構建及測試
frame 向導 tla else 通知 -c .cpp null erp 1. 創建OPENCV工程 1)打開VS2013,點擊新建項目->MFC應用程序,並選擇保存名稱及路徑,如下圖, 2) 點擊確定進入MFC應用程序向導,設
spark 環境搭建及幾種模式測試
spark 環境搭建及幾種模式測試 spark安裝部署spark安裝前的環境準備 需要安裝jdk、scala、hadoop作為前提環境。 1、安裝jdk1.7 先解除安裝自帶的jdk,防止自帶的jdk和安裝的出現衝突。而且自帶的版本較低不能滿足現在軟體對jdk的要求。 使用
Spark編程環境搭建及WordCount實例
enter 默認 自己 apache block 編程 mar compile edi 基於Intellij IDEA搭建Spark開發環境搭建 基於Intellij IDEA搭建Spark開發環境搭——參考文檔 ● 參考文檔h
spark JAVA 開發環境搭建及遠程調試
soft 匯總 bubuko tab 2.7 cati builder hadoop2.7 本地 spark JAVA 開發環境搭建及遠程調試 以後要在項目中使用Spark 用戶昵稱文本做一下聚類分析,找出一些違規的昵稱信息。以前折騰過Hadoop,於是看了下Spark官網
spark JAVA 開發環境搭建及遠端除錯
spark JAVA 開發環境搭建及遠端除錯 以後要在專案中使用Spark 使用者暱稱文字做一下聚類分析,找出一些違規的暱稱資訊。以前折騰過Hadoop,於是看了下Spark官網的文件以及 github 上 官方提供的examples,看完了之後決定動手跑一個文字聚類的demo,於是有了下文。 1. 環境
Kylin OLAP 綜合解決方案環境部署及雙引擎切換實踐-Spark商業應用實戰
本套技術專欄是作者(秦凱新)平時工作的總結和昇華,通過從真實商業環境抽取案例進行總結和分享,並給出商業應用的調優建議和叢集環境容量規劃等內容,請持續關注本套部落格。版權宣告:禁止轉載,歡迎學習。QQ郵箱地址:[email protected],如有任何商業交流,可隨時聯絡。
Spark教程(3)-開發環境配置及單詞計數
1.開發環境準備 安裝scala windows下安裝scala-2.11.8 jdk jdk版本為1.8 安裝eclipse-scala外掛 下載eclipse開發scala的外掛,也可以下載scala專用的eclipse版本. 建立mave
Spark學習記錄(一)Spark 環境搭建以及worldCount示例
安裝Spark ------------------- 首先,安裝spark之前需要先安裝scala,並且安裝scala的版本一定要是將要安裝的spark要求的版本。比如spark2.1.0 要求scala 2.11系列的版本,不能多也不能少 1.下載spark-2.1.0-bin-hadoop
計算利器Spark——Spark的Standalone環境搭建及使用
轉載請註明出處:http://blog.csdn.net/dongdong9223/article/details/84836391 本文出自【我是幹勾魚的部落格】 Ingredients: Java:Java SE Development Kit 8u1
Spark環境安裝部署及詞頻統計例項
Spark是一個高效能的分散式計算框架,由於是在記憶體中進行操作,效能比MapReduce要高出很多. 具體的我就不介紹了,直接開始安裝部署並進行例項測試 首先在官網下載http://spark.ap
Spark 入門之 Scala 語言解釋及示例講解
Scala 語言衍生自 Funnel 語言。Funnel 語言嘗試將函數語言程式設計和 Petri 網結合起來,而 Scala 的預期目標是將面向物件、函數語言程式設計和強大的型別系統結合起來,同時讓人要能寫出優雅、簡潔的程式碼。本文希望通過一系列 Java 與
Spark各種模式的環境搭建及相關工作流程介紹
1前言 本篇部落格主要記錄的是Spark的3種執行模式及對應的模式環境搭建過程和流程介紹。3種模式都是經過實踐記錄詳細的操作過程和注意事項。 在進行環境的配置過程中,建議先理解每個模式下的工作流程,然後再進行環境搭建,這樣容易加深理解。由於Spark on
【MyBatis】3:MyBatis環境搭建及入門程式示例
MyBatis開發環境搭建: 1 建立Java Project 使用什麼IDE無所謂,eclipse、myeclipse、idea等等都可以,jdk版本好像也沒什麼限制,只是有些東西低版本的不支援,比如MyBatis的核心xml
Spark+ECLIPSE+JAVA+MAVEN windows開發環境搭建及入門例項【附詳細程式碼】
前言 本文旨在記錄初學Spark時,根據官網快速入門中的一段Java程式碼,在Maven上建立應用程式並實現執行。 首先推薦一個很好的入門文件庫,就是CSDN的Spark知識庫,裡面有很多spark的從入門到精通的形形色色的資料, 1.開發軟體恭喜你,拿到spark駕考
Java SE 9(JDK9)環境安裝及互動式程式設計環境Jshell使用示例
目的 安裝JDK 9, 練習Jshell工具的使用, 體驗Java的互動式程式設計環境。 什麼是Jshell 其實就是一個命令列工具,安裝完JDK9後,可以在bin目錄下找到該工具,與Python的直譯器極其相似,用過Python直譯器的人應該會非常熟悉。 它可以讓你體驗互
用java編寫spark程式,簡單示例及執行
最近因為工作需要,研究了下spark,因為scala還不熟,所以先學習了java的spark程式寫法,下面是我的簡單測試程式的程式碼,大部分函式的用法已在註釋裡面註明。 我的環境:hadoop 2.2.0 spark-0.9.0
《深入理解SPARK:核心思想與原始碼分析》——SparkContext的初始化(仲篇)——SparkUI、環境變數及排程
《深入理解Spark:核心思想與原始碼分析》一書第一章的內容請看連結《第1章 環境準備》 《深入理解Spark:核心思想與原始碼分析》一書第二章的內容請看連結《第2章 SPARK設計理念與基本架構》 由於本書的第3章內容較多,所以打算分別開闢四篇隨筆分別展現。 本文展現第3章第二部分的內容:
Windows下Python開發環境搭建及 Python的HelloWorld示例
最近較忙,都麼時間更新部落格了。本文介紹Windows下Python開發環境的搭建。一、從連結http://www.python.org/downloads/ 下載安裝包,注意32位和64位安裝包區別。我下載的是32位 2.7.6的,. 然後就是安裝,預設安裝到目錄C:\Py
linux+apache+mysql+php平臺構建及環境配置
1.我使用的centos6。安裝時已經選擇安裝apach、mysql,其實在執行下列兩行命令的時候又對其進行了更新,所以說裝的時候可以不安裝,免得浪費時間。 yum install php-mysql yum install mysql-devel 這兩項執行完以後,PHP就已經裝上了,這是因為它們存在