
在iOS平臺上使用TensorFlow教程(上)
在利用深度學習網路進行預測性分析之前,我們首先需要對其加以訓練。目前市面上存在著大量能夠用於神經網路訓練的工具,但TensorFlow無疑是其中極為重要的首選方案之一。

大家可以利用TensorFlow訓練自己的機器學習模型,並利用這些模型完成預測性分析。訓練通常由一臺極為強大的裝置或者雲端資源完成,但您可能想象不到的是,TensorFlow亦可以在iOS之上順利起效——只是存在一定侷限性。
在今天的博文中,我們將共同瞭解TensorFlow背後的設計思路、如何利用其訓練一套簡單的分類器,以及如何將上述成果引入您的iOS應用。
TensorFlow是什麼,我們為何需要加以使用?
TensorFlow是一套用於構建計算性圖形,從而實現機器學習的軟體資源庫。
其它一些工具往往作用於更高級別的抽象層級。以Caffe為例,大家需要將不同型別的“層”進行彼此互連,從而設計出一套神經網路。而iOS平臺上的BNNS與MPSCNN亦可實現類似的功能。
在TensorFlow當中,大家亦可處理這些層,但具體處理深度將更為深入——甚至直達您演算法中的各項計算流程。
大家可以將TensorFlow視為一套用於實現新型機器學習演算法的工具集,而其它深度學習工具則用於幫助使用者使用這些演算法。
當然,這並不是說使用者需要在TensorFlow當中從零開始構建一切。TensorFlow擁有一整套可複用的構建元件,同時囊括了Keras等負責為TensorFlow使用者提供大量便捷模組的資源庫。
因此TensorFlow在使用當中並不強制要求大家精通相關數學專業知識,當然如果各位願意自行構建,TensorFlow也能夠提供相應的工具。
利用邏輯迴歸實現二元分類
在今天的博文當中,我們將利用邏輯迴歸(logistic regression)演算法建立一套分類器。沒錯,我們將從零開始進行構建,因此請大家做好準備——這可是項有點複雜的任務。所謂分類器,其基本工作原理是獲取輸入資料,而後告知使用者該資料所歸屬的類別——或者種類。在本專案當中,我們只設定兩個種類:男聲與女聲——也就是說,我們需要構建的是一套二元分類器(binary classifier)。
備註:二元分類器屬於最簡單的一種分類器,但其基本概念與設計思路同用於區分成百上千種不同類別的分類器完全一致。因此,儘管我們在本份教程中不會太過深入,但相信大家仍然能夠從中一窺分類器設計的門徑。
在輸入資料方面,我們將使用包含20個數字朗讀語音、囊括多種聲學特性的給定錄音。我將在後文中對此進行詳盡解釋,包括音訊頻率及其它相關資訊。
在以下示意圖當中,大家可以看到這20個數字全部接入一個名為sum的小框。這些連線擁有不同的weights(權重),對於分類器而言代表著這20個數字各自不同的重要程度。
以下框圖展示了這套邏輯分類器的起效原理:
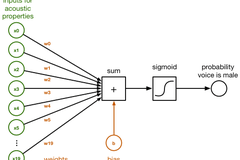
在sum框當中,輸入資料區間為x0到x19,且其對應連線的權重w0到w19進行直接相加。以下為一項常見的點積:
sum = x[0]*w[0] + x[1]*w[1] + x[2]*w[2] + ... + x[19]*w[19] + b
我們還在所謂bias(偏離)項的末尾加上了b。其僅僅代表另一個數字。
陣列w中的權重與值b代表著此分類器所學習到的經驗。對該分類器進行訓練的過程,實際上是為了幫助其找到與w及b正確匹配的數字。最初,我們將首先將全部w與b設定為0。在數輪訓練之後,w與b則將包含一組數字,分類器將利用這些數字將輸入語音中的男聲與女聲區分開來。為了能夠將sum轉化為一條概率值——其取值在0與1之間——我們在這裡使用logistic sigmoid函式:
y_pred = 1 / (1 + exp(-sum))
這條方程式看起來很可怕,但做法卻非常簡單:如果sum是一個較大正數,則sigmoid函式返回1或者概率為100%; 如果sum是一個較大負數,則sigmoid函式返回0。因此對於較大的正或者負數,我們即可得出較為肯定的“是”或者“否”預測結論。
然而,如果sum趨近於0,則sigmoid函式會給出一個接近於50%的概率,因為其無法確定預測結果。當我們最初對分類器進行訓練時,其初始預期結果會因分類器本身訓練尚不充分而顯示為50%,即對判斷結果並無信心。但隨著訓練工作的深入,其給出的概率開始更趨近於1及0,即分類器對於結果更為肯定。
現在y_pred中包含的預測結果顯示,該語音為男聲的可能性更高。如果其概率高於0.5(或者50%),則我們認為語音為男聲; 相反則為女聲。
這即是我們這套利用邏輯迴歸實現的二元分類器的基本設計原理。輸入至該分類器的資料為一段對20個數字進行朗讀的音訊記錄,我們會計算出一條權重sum並應用sigmoid函式,而我們獲得的輸出概率指示朗讀者應為男性。
然而,我們仍然需要建立用於訓練該分類器的機制,而這時就需要請出今天的主角——TensorFlow了。在TensorFlow中實現此分類器要在TensorFlow當中使用此分類器,我們需要首先將其設計轉化為一套計算圖(computational graph)。一項計算圖由多個負責執行計算的節點組成,且輸入資料會在各節點之間往來流通。
我們這套邏輯迴歸演算法的計算圖如下所示:

看起來與之前給出的示意圖存在一定區別,但這主要是由於此處的輸入內容x不再是20個獨立的數字,而是一個包含有20個元素的向量。在這裡,權重由矩陣W表示。因此,之前得出的點積也在這裡被替換成了一項矩陣乘法。
另外,本示意圖中還包含一項輸入內容y。其用於對分類器進行訓練並驗證其執行效果。我們在這裡使用的資料集為一套包含3168條example語音記錄的集合,其中每條示例記錄皆被明確標記為男聲或女聲。這些已知男聲或女聲結果亦被稱為該資料集的label(標籤),並作為我們交付至y的輸入內容。
為了訓練我們的分類器,這裡需要將一條示例載入至x當中並允許該計算圖進行預測:即語音到底為男聲抑或是女聲?由於初始權重值全部為0,因此該分類器很可能給出錯誤的預測。我們需要一種方法以計算其錯誤的“具體程度”,而這一目標需要通過loss函式實現。Loss函式會將預測結果y_pred與正確輸出結果y進行比較。
在將loss函式提供給訓練示例後,我們利用一項被稱為backpropagation(反向傳播)的技術通過該計算圖進行回溯,旨在根據正確方向對W與b的權重進行小幅調整。如果預測結果為男聲但實際結果為女聲,則權重值即會稍微進行上調或者下調,從而在下一次面對同樣的輸入內容時增加將其判斷為“女聲”的概率。
這一訓練規程會利用該資料集中的全部示例進行不斷重複再重複,直到計算圖本身已經獲得了最優權重集合。而負責衡量預測結果錯誤程度的loss函式則因此隨時間推移而變低。
反向傳播在計算圖的訓練當中扮演著極為重要的角色,但我們還需要加入一點數學手段讓結果更為準確。而這也正是TensorFlow的專長所在:我們只要將全部“前進”操作表達為計算圖當中的節點,其即可自動意識到“後退”操作代表的是反向傳播——我們完全無需親自進行任何數學運算。太棒了!
Tensorflow到底是什麼?
在以上計算圖當中,資料流向為從左至右,即代表由輸入到輸出。而這正是TensorFlow中“流(flow)”的由來。不過Tensor又是什麼?
Tensor一詞本義為張量,而此計算圖中全部資料流皆以張量形式存在。所謂張量,其實際代表的就是一個n維陣列。我曾經提到W是一項權重矩陣,但從TensorFlow的角度來看,其實際上屬於一項二階張量——換言之,一個二組陣列。
-
一個標量代表一個零階張量。
-
一個向量代表一個一階張量。
-
一個矩陣代表一個二階張量。
-
一個三維陣列代表一個三階張量。
之後以此類推……
這就是Tensor的全部含義。在卷積神經網路等深度學習方案當中,大家會需要與四維張量打交道。但本示例中提到的邏輯分類器要更為簡單,因此我們在這裡最多隻涉及到二階張量——即矩陣。
我之前還提到過,x代表一個向量——或者說一個一階張量——但接下來我們同樣將其視為一個矩陣。y亦採用這樣的處理方式。如此一來,我們即可將資料庫組視為整體對其loss進行計算。
一條簡單的示例(example)語音內包含20個數據元素。如果大家將全部3168條示例載入至x當中,則x會成為一個3168 x 20的矩陣。再將x與W相乘,則得出的結果y_pred為一個3168 x 1的矩陣。具體來講,y_pred代表的是為資料集中的每條語音示例提供一項預測結論。
通過將我們的計算圖以矩陣/張量的形式進行表達,我們可以一次性對多個示例進行預測。
安裝TensorFlow
好的,以上是本次教程的理論基礎,接下來進入實際操作階段。
我們將通過Python使用TensorFlow。大家的Mac裝置可能已經安裝有某一Python版本,但其版本可能較為陳舊。在本教程中,我使用的是Python 3.6,因此大家最好也能安裝同一版本。
安裝Python 3.6非常簡單,大家只需要使用Homebrew軟體包管理器即可。如果大家還沒有安裝homebrew,請點選此處參閱相關指南。
接下來開啟終端並輸入以下命令,以安裝Python的最新版本:
brew install python3
Python也擁有自己的軟體包管理器,即pip,我們將利用它安裝我們所需要的其它軟體包。在終端中輸入以下命令:
pip3 install numpy pip3 install scipy pip3 install scikit-learn pip3 install pandas pip3 install tensorflow
除了TensorFlow之外,我們還需要安裝NumPy、SciPy、pandas以及scikit-learn:
NumPy是一套用於同n級陣列協作的庫。聽起來耳熟嗎?NumPy並非將其稱為張量,但之前提到了陣列本身就是一種張量。TensorFlow Python API就建立在NumPy基礎之上。
SciPy是一套用於數值計算的庫。其它一些軟體包的起效需要以之為基礎。
pandas負責資料集的載入與清理工作。
scikit-learn在某種意義上可以算作TensorFlow的競爭對手,因為其同樣是一套用於機器學習的庫。我們之所以在本專案中加以使用,是因為它具備多項便利的功能。由於TensorFlow與scikit-learn皆使用NumPy陣列,因為二者能夠順暢實現協作。
實際上,大家無需pandas與scikit-learn也能夠使用TensorFlow,但二者確實能夠提供便捷功能,而且每一位資料科學家也都樂於加以使用。
如大家所知,這些軟體包將被安裝在/usr/local/lib/python3.6/site-packages當中。如果大家需要檢視部分未被公佈在其官方網站當中的TensorFlow原始碼,則可以在這裡找到。
備註:pip應會為您的系統自動安裝TensorFlow的最佳版本。如果大家希望安裝其它版本,則請點選此處參閱官方安全指南。另外,大家也可以利用原始碼自行構建TensorFlow,這一點我們稍後會在面向iOS構建TensorFlow部分中進行說明。
下面我們進行一項快速測試,旨在確保一切要素都已經安裝就緒。利用以下內容建立一個新的tryit.py檔案:
import tensorflow as tf a = tf.constant([1, 2, 3]) b = tf.constant([4, 5, 6]) sess = tf.Session(config=tf.ConfigProto(log_device_placement=True)) print(sess.run(a + b))
而後通過終端執行這套指令碼:
python3 tryit.py
其會顯示一些與TensorFlow執行所在裝置相關的除錯資訊(大多為CPU資訊,但如果您所使用的Mac裝置配備有英偉達GPU,亦可能提供GPU資訊)。最終結果顯示為:
[5 7 9]
這裡代表的是兩個向量a與b的加和。另外,大家可能還會看到以下資訊:
W tensorflow/core/platform/cpu_feature_guard.cc:45] The TensorFlow library wasn't compiled to use SSE4.1 instructions, but these are available on your machine and could speed up CPU computations.
如果出現上述內容,則代表您在系統當中安裝的TensorFlow並非當前CPU的最優適配版本。修復方法之一是利用原始碼自行構建TensorFlow,因為這允許大家對全部選項加以配置。但在本示例當中,由於其不會造成什麼影響,因此直接忽略即可。深入觀察訓練資料集
要訓練分類器,我們自然需要資料。
在本專案當中,我們使用來自Kory Becker的“根據語音判斷性別”資料集。為了能夠讓這份教程能夠與TensorFlow指南上的MNIST數字化識別有所不同,這裡我決定在Kaggle.com上尋找資料集,並最終選定了這一套。
那麼我們到底該如何立足音訊實現性別判斷?下載該資料集並開啟voice.csv檔案之後,大家會看到其中包含著一排排數字:

我們首先需要強調這一點,這裡列出的並非實際音訊資料!相反,這些數字代表著語音記錄當中的不同聲學特徵。這些屬性或者特徵由一套指令碼自音訊記錄中提取得出,並被轉化為這個CSV檔案。具體提取方式並不屬於本篇文章希望討論的範疇,但如果大家感興趣,則可點選此處查閱其原始R原始碼。
這套資料集中包含3168項示例(每項示例在以上表格中作為一行),且基本半數為男聲錄製、半數為女聲錄製。每一項示例中存在20項聲學特徵,例如:
-
以kHz為單位的平均頻率
-
頻率的標準差
-
頻譜平坦度
-
頻譜熵
-
峰度
-
聲學訊號中測得的最大基頻
-
調製指數
-
等等……
別擔心,雖然我們並不瞭解其中大多數條目的實際意義,但這不會影響到本次教程。我們真正需要 關心的是如何利用這些資料訓練自己的分類器,從而立足於上述特徵確保其有能力區分男性與女性的語音。
如果大家希望在一款應用程式當中使用此分類器,從而通過錄音或者來自麥克風的音訊資訊檢測語音性別,則首先需要從此類音訊資料中提取聲學特徵。在擁有了這20個數字之後,大家即可對其分類器加以訓練,並利用其判斷語音內容為男聲還是女聲。
因此,我們的分類器並不會直接處理音訊記錄,而是處理從記錄中提取到的聲學特徵。
備註:我們可以以此為起點了解深度學習與邏輯迴歸等傳統演算法之間的差異。我們所訓練的分類器無法學習非常複雜的內容,大家需要在預處理階段提取更多資料特徵對其進行幫助。在本示例的特定資料集當中,我們只需要考慮提取音訊記錄中的音訊資料。
深度學習最酷的能力在於,大家完全可以訓練一套神經網路來學習如何自行提取這些聲學特徵。如此一來,大家不必進行任何預處理即可利用深度學習系統採取原始音訊作為輸入內容,並從中提取任何其認為重要的聲學特徵,而後加以分類。
這當然也是一種有趣的深度學習探索方向,但並不屬於我們今天討論的範疇,因此也許日後我們將另開一篇文章單獨介紹。
建立一套訓練集與測試集
在前文當中,我提到過我們需要以如下步驟對分類器進行訓練:
-
向其交付來自資料集的全部示例。
-
衡量預測結果的錯誤程度。
-
根據loss調整權重。
事實證明,我們不應利用全部資料進行訓練。我們只需要其中的特定一部分資料——即測試集——從而評估分類器的實際工作效果。因此,我們將把整體資料集拆分為兩大部分:訓練集,用於對分類器進行訓練; 測試集,用於瞭解該分類器的預測準確度。
為了將資料拆分為訓練集與測試集,我建立了一套名為split_data.py的Python指令碼,其內容如下所示:
import numpy as np # 1 import pandas as pd df = pd.read_csv("voice.csv", header=0) #2 labels = (df["label"] == "male").values * 1 # 3 labels = labels.reshape(-1, 1) # 4 del df["label"] # 5 data = df.values # 6 from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(data, labels, test_size=0.3, random_state=123456) np.save("X_train.npy", X_train) # 7 np.save("X_test.npy", X_test) np.save("y_train.npy", y_train) np.save("y_test.npy", y_test)
下面我們將分步驟瞭解這套指令碼的工作方式:
-
首先匯入NumPy與pandas軟體包。Pandas能夠輕鬆實現CSV檔案的載入,並對資料進行預處理。
-
利用pandas從voice.csv載入資料集並將其作為dataframe。此物件在很大程度上類似於電子表格或者SQL表。
-
這裡的label列包含有該資料集的各項標籤:即該示例為男聲或者女聲。在這裡,我們將這些標籤提取進一個新的NumPy陣列當中。各原始標籤為文字形式,但我們將其轉化為數字形式,其中1=男聲,0=女聲。(這裡的數字賦值方式可任意選擇,在二元分類器中,我們通常使用1表示‘正’類,或者說我們試圖檢測的類。)
-
這裡建立的新labels陣列是一套一維陣列,但我們的TensorFlow指令碼則需要一套二維張量,其中3168行中每一行皆對應一列。因此我們需要在這裡對陣列進行“重塑”,旨在將其轉化為二維形式。這不會對記憶體中的資料產生影響,而僅變化NumPy對資料的解釋方式。
-
在完成label列之後,我們將其從dataframe當中移除,這樣我們就只剩下20項用於描述輸入內容的特徵。我們還將把該dataframe轉換為一套常規NumPy陣列。
-
這裡,我們利用來自scikit-learn的一項helper函式將data與labels陣列拆分為兩個部分。這種對資料集內各示例進行隨機洗牌的操作基於random_state,即一類隨機生成器。無論具體內容為何,但只要青筋相同內容,我們即創造出了一項可重複進行的實驗。
-
最後,將四項新的陣列儲存為NumPy的二進位制檔案格式。現在我們已經擁有了一套訓練集與一套測試集!
大家也可以進行額外的一些預處理對指令碼中的資料進行調整,例如對特徵進行擴充套件,從而使其擁有0均值及相等的方差,但由於本次示例專案比較簡單,所以並無深入調整的必要。
利用以下命令在終端中執行這套指令碼:
python3 split_data.py
這將給我們帶來4個新檔案,其中包含有訓練救命(X_train.npy)、這些示例的對應標籤(y_train.npy)、測試示例(X_test.npy)及其對應標籤(y_test.npy)。
備註:大家可能想了解為什麼這些變數名稱為何有些是大寫,有些是小寫。在數學層面來看,矩陣通常以大寫表示而向量則以小寫表示。在我們的指令碼中,X代表一個矩陣,y代表一個向量。這是一種慣例,大部分機器學習程式碼中皆照此辦理。
建立計算圖
現在我們已經對資料進行了梳理,而後即可編寫一套指令碼以利用TensorFlow對這套邏輯分類器進行訓練。這套指令碼名為train.py。為了節省篇幅,這裡就不再列出指令碼的具體內容了,大家可以點選此處在GitHub上進行檢視。
與往常一樣,我們首先需要匯入需要的軟體包。在此之後,我們將訓練資料載入至兩個NumPy陣列當中,即X_train與y_train。(我們在本指令碼中不會使用測試資料。)
import numpy as np import tensorflow as tf X_train = np.load("X_train.npy") y_train = np.load("y_train.npy")
現在我們可以建立自己的計算圖。首先,我們為我們的輸入內容x與y定義所謂placeholders(佔位符):
num_inputs = 20 num_classes = 1 with tf.name_scope("inputs"): x = tf.placeholder(tf.float32, [None, num_inputs], name="x-input") y = tf.placeholder(tf.float32, [None, num_classes], name="y-input")
其中tf.name_scope("...")可用於對該計算圖中的不同部分按不同範圍進行分組,從而簡化對計算圖內容的理解。我們將x與y新增至“inputs”範圍之內。我們還將為其命名,分別為“x-input”與“y-input”,這樣即可在隨後輕鬆加以引用。
大家應該還記得,每條輸入示例都是一個包含20項元素的向量。每條示例亦擁有一個標籤(1代表男聲,0代表女聲)。我之前還提到過,我們可以將全部示例整合為一個矩陣,從而一次性對其進行全面計算。正因為如此,我們這裡將x與y定義為二維張量:x擁有[None, 20]維度,而y擁有[None, 1]維度。
其中的None代表第一項維度為靈活可變且目前未知。在訓練集當中,我們將2217條示例匯入x與y; 而在測試集中,我們引入951條示例。現在,TensorFlow已經瞭解了我們的輸入內容,接下來對分類器的parameters(引數)進行定義:
with tf.name_scope("model"): W = tf.Variable(tf.zeros([num_inputs, num_classes]), name="W") b = tf.Variable(tf.zeros([num_classes]), name="b")
其中的張量W包含有分類器將要學習的權重(這是一個20 x 1矩陣,因為其中包含20條輸入特徵與1條輸出結果),而b則包含偏離值。這二者被宣告為TensorFlow變數,意味著二者可在反向傳播過程當中實現更新。
在一切準備就緒之後,我們可以對作為邏輯迴歸分類器核心的計算流程進行聲明瞭:
y_pred = tf.sigmoid(tf.matmul(x, W) + b)
這裡將x與W進行相乘,同時加上偏離值b,而後取其邏輯型成長曲線(logistic sigmoid)。如此一來,y_pred中的結果即根據x內音訊資料的描述特性而被判斷為男聲的概率。
備註:以上程式碼目前實際還不會做出任何計算——截至目前,我們還只是構建起了必要的計算圖。這一行單純是將各節點新增至計算圖當中以作為矩陣乘法(tf.matmul)、加法(+)以及sigmoid函式(tf.sigmoid)。在完成整體計算圖的構建之後,我們方可建立TensorFlow會話並利用實際資料加以執行。
到這裡任務還未完成。為了訓練這套模型,我們需要定義一項loss函式。對於一套二元邏輯迴歸分類器,我們需要使用log loss,幸運的是TensorFlow本身內建有一項log_loss()函式可供直接使用:
with tf.name_scope("loss-function"): loss = tf.losses.log_loss(labels=y, predictions=y_pred) loss += regularization * tf.nn.l2_loss(W)
其中的log_loss計算圖節點作為輸入內容y,我們會獲取與之相關的示例標籤並將其與我們的預測結果y_pred進行比較。以數字顯示的結果即為loss值。
在剛開始進行訓練時,所有示例的預測結果y_pred皆將為0.5(或者50%男聲),這是因為分類器本身尚不清楚如何獲得正確答案。其初始loss在經-1n(0.5)計算後得出為0.693146。而在訓練的推進當中,其loss值將變得越來越小。
第二行用於計算loss值與所謂L2 regularization(正則化)的加值。這是為了防止過度擬合阻礙分類器對訓練資料的準確記憶。這一過程比較簡單,因為我們的分類器“記憶體”只包含20項權重值與偏離值。不過正則化本身是一種常見的機器學習技術,因此在這裡必須一提。
這裡的regularization值為另一項佔位符:
with tf.name_scope("hyperparameters"): regularization = tf.placeholder(tf.float32, name="regularization") learning_rate = tf.placeholder(tf.float32, name="learning-rate")
我們還將利用佔位符定義我們的輸入內容x與y,不過二者的作用是定義hyperparameters。
Hyperparameters允許大家對這套模型及其具體訓練方式進行配置。其之所以被稱為“超”引數,是因為與常見的W與b引數不同,其並非由模型自身所學習——大家需要自行將其設定為適當的值。
其中的learning_rate超引數負責告知優化器所應採取的調整幅度。該優化器(optimizer)負責執行反向傳播:其會提取loss值並將其傳遞迴計算圖以確定需要對權重值與偏離值進行怎樣的調整。這裡可以選擇的優化器方案多種多樣,而我們使用的為ADAM:
with tf.name_scope("train"): optimizer = tf.train.AdamOptimizer(learning_rate) train_op = optimizer.minimize(loss)
其能夠在計算圖當中建立一個名為train_op的節點。我們稍後將執行此節點以訓練分類器。為了確定該分類器的執行效果,我們還需要在訓練當中偶爾捕捉快照並計算其已經能夠在訓練集當中正確預測多少項示例。訓練集的準確性並非分類器執行效果的最終檢驗標準,但對其進行追蹤能夠幫助我們在一定程度上把握訓練過程與預測準確性趨勢。具體來講,如果越是訓練結果越差,那麼一定是出了什麼問題!
下面我們為一個計算圖節點定義計算精度:
with tf.name_scope("score"): correct_prediction = tf.equal(tf.to_float(y_pred > 0.5), y) accuracy = tf.reduce_mean(tf.to_float(correct_prediction), name="accuracy")
我們可以執行其中的accuracy節點以檢視有多少個示例得到了正確預測。大家應該還記得,y_pred中包含一項介於0到1之間的概率。通過進行tf.to_float(y_pred > 0.5),若預測結果為女聲則返回值為0,若預測結果為男聲則返回值為1。我們可以將其與y進行比較,y當中包含有正確值。而精度值則代表著正確預測數量除以預測總數。
在此之後,我們將利用同樣的accuracy節點處理測試集,從而瞭解這套分類器的實際工作效果。
另外,我們還需要定義另外一個節點。此節點用於對我們尚無對應標籤的資料進行預測:
with tf.name_scope("inference"): inference = tf.to_float(y_pred > 0.5, name="inference")
為了將這套分類器引入應用,我們還需要記錄幾個語音文字詞彙,對其進行分析以提取20項聲學特徵,而後再將其交付至分類器。由於處理內容屬於全新資料,而非來自訓練或者測試集的資料,因此我們顯然不具備與之相關的標籤。大家只能將資料直接交付至分類器,並希望其能夠給出正確的預測結果。而inference節點的作用也正在於此。
好的,我們已經投入了大量精力來構建這套計算圖。現在我們希望利用訓練集對其進行實際訓練。
訓練分類器
訓練通常以無限迴圈的方式進行。不過對於這套簡單的邏輯分類器,這種作法顯然有點誇張——因為其不到一分鐘即可完成訓練。但對於深層神經網路,我們往往需要數小時甚至數天時間進行指令碼執行——直到其獲得令人滿意的精度或者您開始失去耐心。
以下為train.py當中訓練迴圈的第一部分:
with tf.Session() as sess: tf.train.write_graph(sess.graph_def, checkpoint_dir, "graph.pb", False) sess.run(init) step = 0 while True: # here comes the training code
我們首先建立一個新的TensorFlow session(會話)物件。要執行該計算圖,大家需要建立一套會話。呼叫sess.run(init)會將W與b全部重設為0。
我們還需要將該計算圖寫入一個檔案。我們將之前建立的全部節點序列至/tmp/voice/graph.pb檔案當中。我們之後需要利用此計算圖定義以立足測試集進行分類器執行,並嘗試將該訓練後的分類器引入iOS應用。
在while True:迴圈當中,我們使用以下內容:
perm = np.arange(len(X_train)) np.random.shuffle(perm) X_train = X_train[perm] y_train = y_train[perm]
首先,我們對訓練示例進行隨機洗牌。這一點非常重要,因為大家當然不希望分類器根據示例的具體順序進行判斷——而非根據其聲學特徵進行判斷。
接下來是最重要的環節:我們要求該會話執行train_op節點。其將在計算圖之上執行一次訓練:
feed = {x: X_train, y: y_train, learning_rate: 1e-2, regularization: 1e-5} sess.run(train_op, feed_dict=feed)
在執行sess.run()時,大家還需要提供一套饋送詞典。其將負責告知TensorFlow當前佔位符節點的實際值。
由於這只是一套非常簡單的分類器,因此我們將始終一次性對全部訓練集進行訓練,所以這裡我們將X_train陣列引入佔位符x並將y_train陣列引入佔位符y。(對於規模更大的資料集,大家可以先從小批資料內容著手,例如將示例數量設定為100到1000之間。)
到這裡,我們的操作就階段性結束了。由於我們使用了無限迴圈,因此train_op節點會反覆再反覆加以執行。而在每一次迭代時,其中的反向傳播機制都會對權重值W與b作出小幅調整。隨著時間推移,這將令權重值逐步趨近於最優值。
我們當然有必要了解訓練進度,因此我們需要經常性地輸出進度報告(在本示例專案中,每進行1000次訓練即輸出一次結果):
if step % print_every == 0: train_accuracy, loss_value = sess.run([accuracy, loss], feed_dict=feed) print("step: %4d, loss: %.4f, training accuracy: %.4f" % (step, loss_value, train_accuracy))
這一次我們不再執行train_op節點,而是執行accuracy與loss兩個節點。我們使用同樣的饋送詞典,這樣accuracy與loss都會根據訓練集進行計算。正如之前所提到,訓練集中的較高預測精度並不代表分類器能夠在處理測試集時同樣擁有良好表現,但大家當然希望隨著訓練的進行其精度值不斷提升。與此同時,loss值則應不斷下降。
另外,我們還需要時不時儲存一份checkpoint:
if step % save_every == 0: checkpoint_file = os.path.join(checkpoint_dir, "model") saver.save(sess, checkpoint_file) print("*** SAVED MODEL ***")
其會獲取分類器當前已經學習到的W與b值,並將其儲存為一個checkpoint檔案。此checkpoint可供我們參閱,並判斷分類器是否已經可以轉而處理測試集。該checkpoinit檔案同樣被儲存在/tmp/voice/目錄當中。
使用以下命令在終端中執行該訓練指令碼:
python3 train.py
輸出結果應如下所示:
Training set size: (2217, 20) Initial loss: 0.693146 step: 0, loss: 0.7432, training accuracy: 0.4754 step: 1000, loss: 0.4160, training accuracy: 0.8904 step: 2000, loss: 0.3259, training accuracy: 0.9170 step: 3000, loss: 0.2750, training accuracy: 0.9229 step: 4000, loss: 0.2408, training accuracy: 0.9337 step: 5000, loss: 0.2152, training accuracy: 0.9405 step: 6000, loss: 0.1957, training accuracy: 0.9553 step: 7000, loss: 0.1819, training accuracy: 0.9594 step: 8000, loss: 0.1717, training accuracy: 0.9635 step: 9000, loss: 0.1652, training accuracy: 0.9666 *** SAVED MODEL *** step: 10000, loss: 0.1611, training accuracy: 0.9702 step: 11000, loss: 0.1589, training accuracy: 0.9707 . . .
當發現loss值不再下降時,就稍等一下直到看到下一條*** SAVED MODEL ***資訊,這時按下Ctrl+C以停止訓練。
在超引數設定當中,我選擇了正規化與學習速率,大家應該會看到其訓練集的準確率已經達到約97%,而loss值則約為0.157。(如果大家在饋送詞典中將regularization設定為0,則loss甚至還能夠進一步降低。)
上半部分到此結束,下半部分我們將察看訓練的實際效果,以及如何在iOS上使用TensorFlow,最後討論一下iOS上使用TensorFlow的優劣。
相關推薦
在iOS平臺上使用TensorFlow教程(上)
在利用深度學習網路進行預測性分析之前,我們首先需要對其加以訓練。目前市面上存在著大量能夠用於神經網路訓練的工具,但TensorFlow無疑是其中極為重要的首選方案之一。 大家可以利用TensorFlow訓練自己的機器學習模型,並利用這些模型完成預測性分析。訓練
在iOS平臺上使用TensorFlow教程(下)
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow 也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
iOS底層原理班實戰視訊教程(上)-李明傑-專題視訊課程
iOS底層原理班實戰視訊教程(上)—448人已學習 課程介紹 iOS底層開發班實戰視訊培訓課程:APP逆向實戰、加殼脫殼、資料安全、編譯原理、iOS底層開發實現、iOS底層開發機制 iOS進階課程,實用技術不斷的更新和升級,更快幫助職場人士在開發領域脫穎而出。
網際網路架構多執行緒併發程式設計高階教程(上)
#基礎篇幅:執行緒基礎知識、併發安全性、JDK鎖相關知識、執行緒間的通訊機制、JDK提供的原子類、併發容器、執行緒池相關知識點 #高階篇幅:ReentrantLock原始碼分析、對比兩者原始碼,更加深入理解讀寫鎖,JAVA記憶體模型、先行發生原則、指令重排序 #環境說明:idea、ja
互聯網架構多線程並發編程高級教程(上)
並發 取模 守護 事務 分段 喚醒 提升 程序 服務 #基礎篇幅:線程基礎知識、並發安全性、JDK鎖相關知識、線程間的通訊機制、JDK提供的原子類、並發容器、線程池相關知識點? #高級篇幅:ReentrantLock源碼分析、對比兩者源碼,更加深入理解讀寫鎖,JAVA內存模
Laravel Telescope入門教程(上)
Laravel Telescope是Laravel的新應用型debug助手,由Mohamed Said和Taylor Otwell編寫。它是開源的,在GitHub上免費,並將在下週釋出。 您將通過Composer將Telescope作為第三方依賴項引入您的應用程式。 安
SciPyCon 2018 sklearn 教程(上)
一、Python 機器學習簡介 什麼是機器學習? 機器學習是自動從資料中提取知識的過程,通常是為了預測新的,看不見的資料。一個典型的例子是垃圾郵件過濾器,使用者將傳入的郵件標記為垃圾郵件或非垃圾郵件。然後,機器學習演算法從資料“學習”預測模型,資料區分垃圾郵件
Jupyter notebook入門教程(上)
本文將分上下兩部分簡單介紹Jupyter notebook的入門教程,英文原文出處: Jupyter notebook(又稱IPython notebook)是一個互動式的筆記本,支援執行超過40種程式語言。本文中,我們將介紹Jupyter notebook的主要特點,
Java例項教程(上)
第一個Java程式 Java 列舉 Java註釋 Java建立物件 Java訪問例項變數和方法 Java區域性變數例項 Java編譯錯誤 J
IOS 初級開發入門教程(二)第一個HelloWorld工程及StoryBoard使用
前言 在IOS開發之路的博文第一章:(IOS開發入門介紹http://blog.csdn.net/csdn_aiyang)我大致系統介紹了有關IOS的一些基礎認識,如果不完全都記住沒關係,以後我們開發之路還很長,慢慢的自然而然就明白是怎麼回事了。這一篇我將手把手教大家完成第
iOS 經典全部面試題(上)
索引 @implementation Son : Father - (id)init { self = [super init]; if (self) { NSLog(@"%@", NS
MongoDB教程(上)
一 安裝mongoDB nosql資料庫 1.MongoDB 提供了可用於 32 位和 64 位系統的預編譯二進位制包,你可以從MongoDB官網下載安裝,MongoDB 預編譯二進位制包下載地址:https://www.mongodb.com/download-center#com
IOS 初級開發入門教程(一)介紹篇
導讀 目前移動端開發市場上引導開發者追求技多不壓身,一個全棧開發者至少要懂後臺伺服器、資料庫、Android、web、ios開發等。“一超多強”是指開發者先成為一門技術的專家然後掌握瞭解多門技術,這是一種好的發展趨勢,另外,這種技多不壓身我認為當開發者更適合發
IOS 初級開發入門教程(五)TextField與ReturnKey實戰練習
前言看完前面4章的內容,基本對IOS開發有一些認識了,這章我們繼續動手去實踐一下,學習文字和鍵盤的相關知識,以及通過一個互動式的案例演示文字與鍵盤的使用。系列文章:UIKit繼承結構我們通過這個UIKit繼承結構圖,我們試著找到本章要學習的TextFiled與TextView
github 教程(上)
作為一個萌新,我翻遍了網上的Git Bash教程,可能因為我理解力比較差,經常看不懂教程上在說什麼。 (。-`ω´-)所以我決定自己一邊摸索一邊記錄,寫教程造福那些理解力跟我一樣差的人……第一篇教程會涉及如下內容(按照一般人的使用流程):下載、登入Git Bash如何在Git Bash中進入或者退出資料夾
MySQL Connector/C++入門教程(上)
翻譯: DarkBull(www.darkbull.net) 譯者注:該教程是一篇介紹如何使用C++操作MySQL的入門教程,內容簡單易用。我對原文中的一些例子進行了修改,並新添加了部分例子,主要目標是更簡單明瞭的向讀者介紹如何操作MySQL資料庫。本人也是MySQL
【深度學習】CentOS 7 安裝GPU版Tensorflow教程(一)
之前一直在玩cpu版的tensorflow,這些天突然心血來潮,想搞個gpu版的tensorflow來嚐嚐鮮,沒想到把所有能夠踩的坑幾乎全部踩了一遍,在這裡把自己踩的坑和一些安裝細節拿出來分享給大家,
IOS 初級開發入門教程(四)基礎控制元件使用小練習
前言看完前面3章的內容,基本對IOS開發有一些認識了,這章我們開始動手去實踐做點小練習,學習如何建立並設定標籤和按鈕(Label & Button)的相關屬性,以及通過一個互動式的案例演示動作和輸出口的使用。系列文章:建立Swift新專案使用Label和Button1
IOS 初級開發入門教程(三)探究應用及檢視的生命週期變化
導讀 作業系統都會根據應用的生命週期狀態來管理和處理邏輯,這一點在Android開發上現的就已經非常好了,耳熟能詳的就是應用狀態影響記憶體回收級別和活動的生命週期。同樣,在IOS上也會充分利用應用的檢視的生命週期來進行管理應用。首先,我們先知道IOS應用在程式中的五種狀
深入學習:Windows下Git新手教程(上)
linux 正在 五步 -m 一起 撤銷 pub 使用命令 clas 版權聲明:本文為博主原創文章,未經博主同意不得轉載。 https://blog.csdn.net/huangyabin