
使用requests+BeautifulSoup的簡單爬蟲練習
爬取網站:貓眼電影top100。這個網站也挺容易的,所以大家可以先自己爬取下,遇到問題再來看下這篇文章哈。
這篇文章主要是練習而已,別無用處,大佬請繞道哈!
1、本文用到的庫及網站
requests
BeautifulSoup
目標網站:http://maoyan.com/board/4
2、分析目標網站
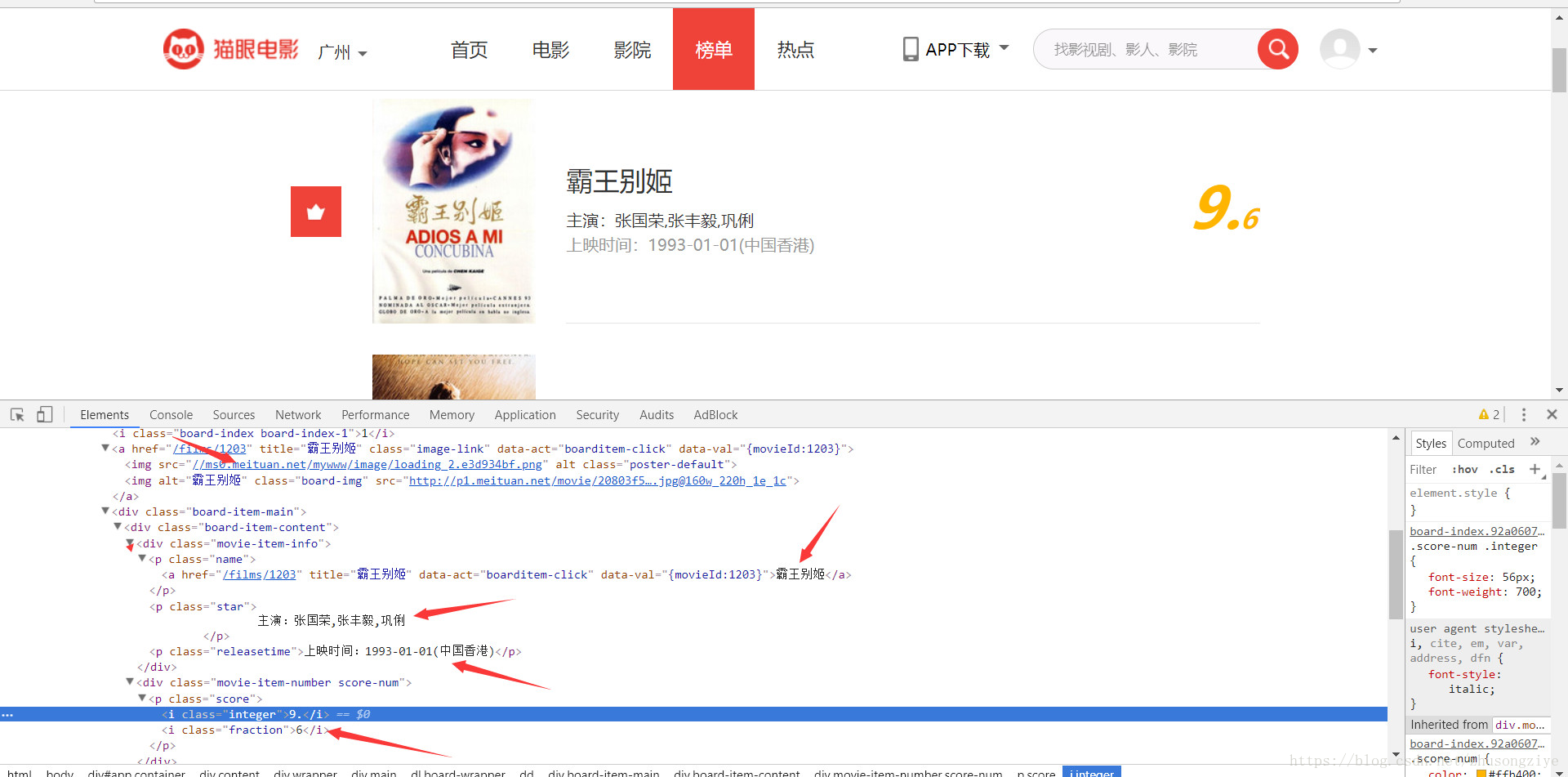
很容易找到我們想要的資訊,上面的5的箭頭都是我們想要的資訊,分別是電影圖片地址、電影名字、主演、上演時間和評分。內容有了,接下來就是獲取下一頁的連結。
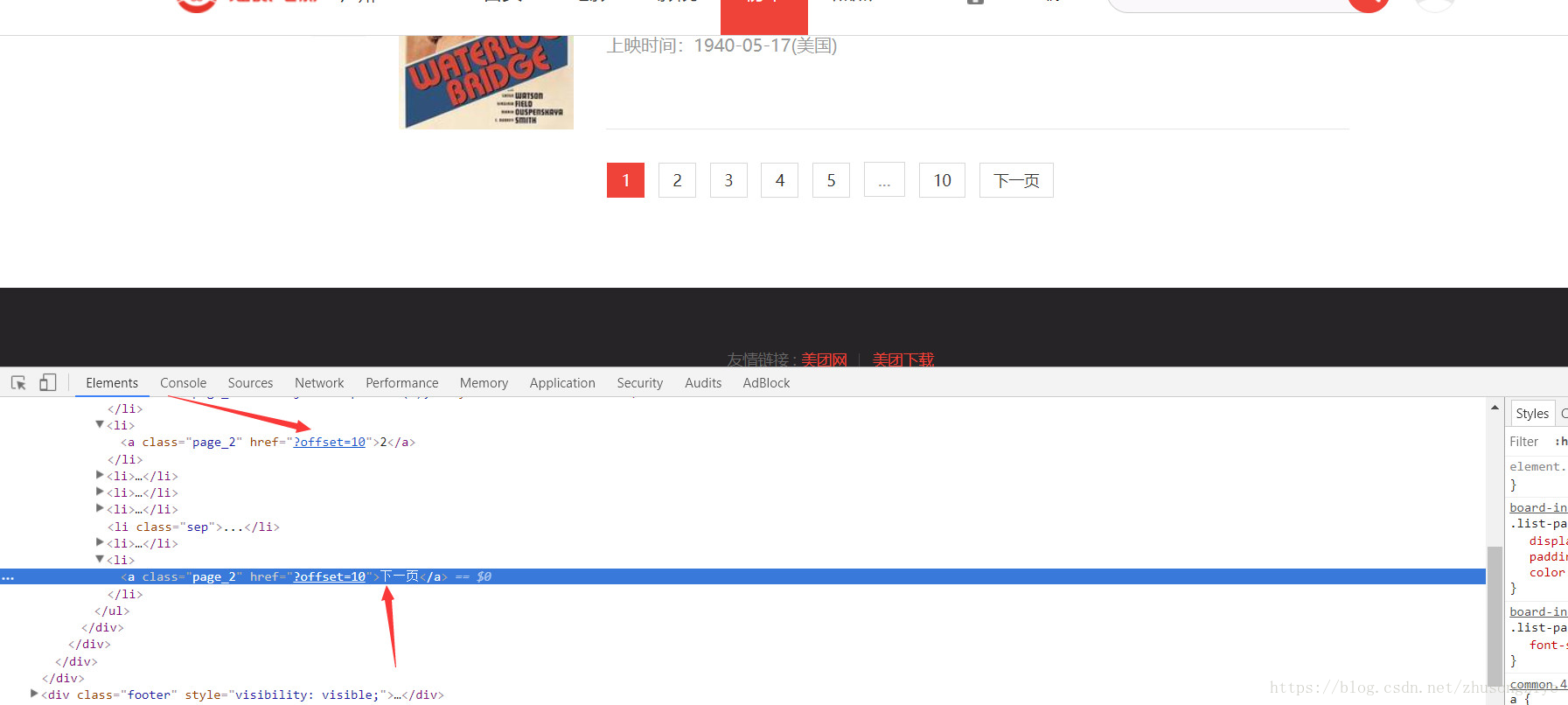
這裡有兩種方法,第一種就是在首頁獲取所有頁的連結,第二種方法就是獲取每個頁面的下一頁的連結。在這裡由於只是給了部分頁面的連結出來,所以我們獲取的是下一頁的連結,這樣子方便點。
好了,分析完畢,接下來程式碼擼起。
3.敲程式碼
什麼都不管,立即來個get請求
import requests
from bs4 import BeautifulSoup
url_start = 'http://maoyan.com/board/4'
response = requests.get(url_start)
if response.status_code == 200:
soup = BeautifulSoup(response.text, 'lxml')
print(response.text)
輸出結果:
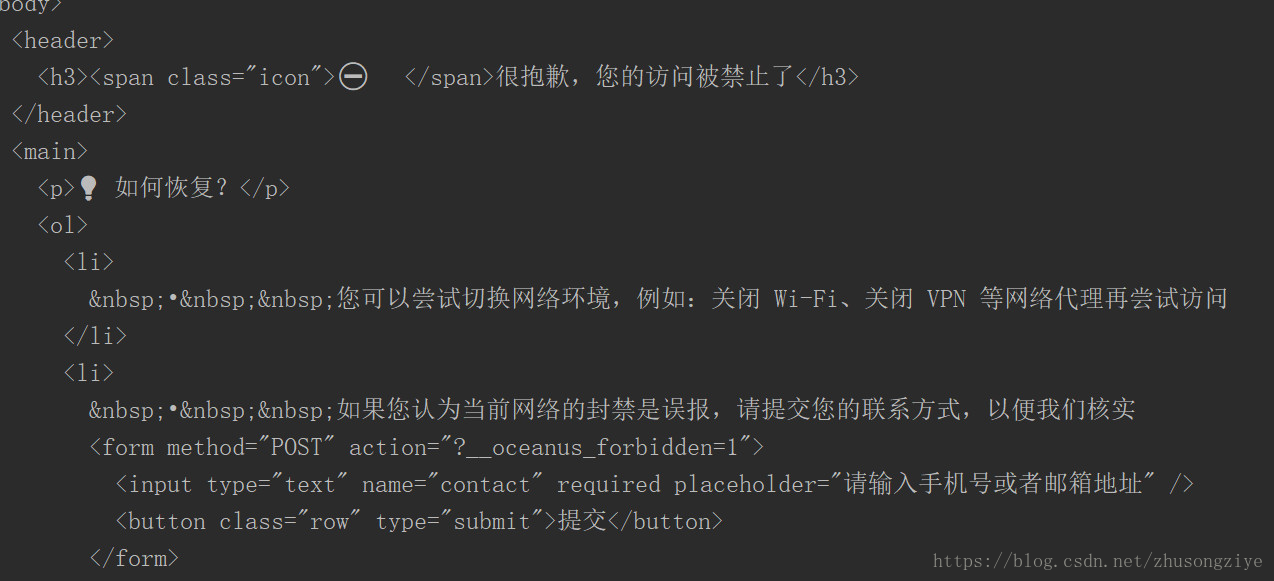
驚不驚喜,意不意外?如果你經常玩爬蟲的,這個就見怪不怪了,我們被反爬了。我們試下加個請求頭試試。
url_start = 'http://maoyan.com/board/4'
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36'}
response = requests.get(url_start, headers=headers)
這樣就可以正常返回了,因為一般的網站都會在請求頭上加個反爬的,所以遇到了反爬也不要著急,加個請求頭試試?
接下來用BeautifulSoupL來獲取內容
imgs = soup.select('dd .board-img'
titles = soup.select('dd .board-item-main .name') # 這是獲取電影名字
starses = soup.select('dd .board-item-main .movie-item-info .star') # 這是獲取電影主演
times = soup.select('dd .board-item-main .movie-item-info .releasetime') # 這是獲取電影上映時間
scores = soup.select('dd .board-item-main .score-num') # 這是獲取評分
這裡每個獲取的語句都包含了每個不同電影的資訊,這樣就不能和正則那樣一次把每個電影的資訊都在同一個字元裡面了。就比如我獲取的圖片,一個語句獲取的是這個頁面的所有電影圖片的連結,我們儲存的時候就要分別取出來了。這裡我用到的是for迴圈0到9把相同的座標的資訊存進同一個字典裡面。
films = [] # 儲存一個頁面的所有電影資訊
for x in range(0, 10):
# 這個是獲取屬性的連結
img = imgs[x]['data-src']
# 下面的都是獲取標籤的內容並去掉兩端空格
title = titles[x].get_text().strip()
stars = starses[x].get_text().strip()[3:] # 使用切片是去掉主演二字
time = times[x].get_text().strip()[5:] # 使用切片是去掉上映時間二字
score = scores[x].get_text().strip()
film = {'title': title, 'img': img, 'stars': stars, 'time': time, 'score': score}
films.append(film)
接下來就是獲取每一頁的連結
pages = soup.select('.list-pager li a') # 可以看到下一頁的連結在最後一個a標籤
page = pages[len(pages)-1]['href']
後面的就簡單了,就是利用迴圈把所有頁面的內容都去取出來就可以了,程式碼就不貼出來了。
寫在最後
這個就是BeautifulSoup庫的小練習,用到昨天的內容不多,只是用到了選擇器部分和獲取文字內容和屬性部分,感覺還是正則比較好用點哈,我一個正則就可以獲取每個電影的詳細內容了,如下:
<dd>.*?board-index.*?>([\d]{1,3})</i>.*?title="(.*?)".*?class="star">(.*?)</p>.*?class="releasetime">(.*?)</p>.*?class="integer">(.*?)</i>.*?class="fraction">(.*?)</i>
還需要用到個匹配模式哈:re.S就可以了。所以本人推薦使用正則表示式哈。
需要完整程式碼的請檢視github哈!
github:https://github.com/SergioJune/gongzhonghao_code/blob/master/python3_spider/index.py
相關推薦
使用requests+BeautifulSoup的簡單爬蟲練習
爬取網站:貓眼電影top100。這個網站也挺容易的,所以大家可以先自己爬取下,遇到問題再來看下這篇文章哈。這篇文章主要是練習而已,別無用處,大佬請繞道哈!1、本文用到的庫及網站requestsBeautifulSoup目標網站:http://maoyan.com/board/
分析並爬取美團美食資訊的一個簡單爬蟲練習。
閒來無聊,感覺美團資訊可能會爬取有點難度,so,我就想來試一試爬取一下美團的美食的資訊,不過,經過搜尋,也有大佬做過了,但是我自己做的呢,還是寫下來分享一下吧,畢竟是自己寫出來的程式碼。 依然用到的是Python3,Request,bs4裡面的Beauti
python簡單爬蟲練習
開始學爬蟲了,記錄一下這兩天的瞎鼓搗 抓取一個網頁 先從最簡單的來,指定一個url,把整個網頁程式碼抓下來,這裡就拿csdn的主頁實驗 # -*- coding: UTF-8 -*- from urllib import request url = 'h
python 爬蟲(一) requests+BeautifulSoup 爬取簡單網頁代碼示例
utf-8 bs4 rom 文章 都是 Coding man header 文本 以前搞偷偷摸摸的事,不對,是搞爬蟲都是用urllib,不過真的是很麻煩,下面就使用requests + BeautifulSoup 爬爬簡單的網頁。 詳細介紹都在代碼中註釋了,大家可以參閱。
小白練習-使用BeautifulSoup庫簡單的爬蟲練習
from bs4 import BeautifulSoup import requests url = 'http://www.tripadvisor.cn/Attractions-g60763-Activities-New_York_City_New_York.html#
python 爬蟲 requests+BeautifulSoup 爬取巨潮資訊公司概況代碼實例
pan 字符 selenium 5.0 target 自我 color list tails 第一次寫一個算是比較完整的爬蟲,自我感覺極差啊,代碼low,效率差,也沒有保存到本地文件或者數據庫,強行使用了一波多線程導致數據順序發生了變化。。。 貼在這裏,引以為戒吧。 #
簡單爬蟲之requests的使用
Requests庫的用法 安裝 pip install requests 基本請求 response=requests.get(引數) response=requests.post(引數) response=requests.put(
爬蟲--BeautifulSoup簡單案例
1.以爬取簡書首頁標題為例 # coding:utf-8 import requests from bs4 import BeautifulSoup # 簡書首頁title爬取 class SoupSpider: def __init__(self): self.ses
Python爬蟲實戰 requests+beautifulsoup+ajax 爬取半次元Top100的cos美圖
1.Python版本以及庫說明 Python3.7.1 Python版本urlencode 可將字串以URL編碼,用於編碼處理bs4 解析html的利器re 正則表示式,用於查詢頁面的一些特定內容requests 得到網頁html、jpg等資源的
python3 requests簡單爬蟲以及分詞並製作詞雲
現在學的東西很雜,很多時候要學的東西其實以前都寫過,但是都忘了。現在回想起來,很多以前寫的程式碼基本上就都沒有儲存下來,感覺有些可以。一方面不便於以後的查詢和複習,另一方面也丟失了很多記錄。所以打算以後的程式碼片段都盡力儲存下來,並寫在部落格裡。 這個是好幾天
爬蟲系統基礎框架 & 何時使用爬蟲框架?& requests庫 + bs4來實現簡單爬蟲
www ica try 藍色 scrapy 定時 調度器 find use 轉載請註明出處https://www.jianshu.com/p/88f920936edc,謝謝! 一、 爬蟲用途和本質: 網絡爬蟲顧名思義即模仿???在網絡上爬取數據,網絡爬蟲的本質是一段自動抓
爬蟲requests庫簡單抓取頁面資訊功能實現(Python)
import requests import re, json,time,random from requests import RequestException UserAgentList = [ "Mozilla/5.0 (Windows NT 6.1; WO
[Python][爬蟲03]requests+BeautifulSoup例項:抓取圖片並儲存
上一篇中,安裝和初步使用了requests+BeautifulSoup,感受到了它們的便捷。但之前我們抓取的都是文字資訊,這次我們準備來抓取的是圖片資訊。 >第一個例項 首先,審查網頁元素: 因此其結構就為: <di
用BeautifulSoup,urllib,requests寫twitter爬蟲(1)
在github上找到了一個twitter的爬蟲,試了下,修改了其中一個有關編碼的問題,可以抓取一定數量的twitter 程式碼如下 from bs4 import BeautifulSoup, NavigableString from urllib2 import url
【Python爬蟲】requests+Beautifulsoup存入資料庫
本次記錄使用requests+Beautiful+pymysql的方法將大學排名的資料存入本地MySQL資料庫。 這是一篇學習性文章,希望能夠分享在學習過程中遇到的坑與學到的新技術,試圖用最簡單的話來闡述我所記錄的Python爬蟲筆記。 一、爬取結果
Python開發簡單爬蟲(二)---爬取百度百科頁面數據
class 實例 實例代碼 編碼 mat 分享 aik logs title 一、開發爬蟲的步驟 1.確定目標抓取策略: 打開目標頁面,通過右鍵審查元素確定網頁的url格式、數據格式、和網頁編碼形式。 ①先看url的格式, F12觀察一下鏈接的形式;② 再看目標文本信息的
python爬蟲練習1:豆瓣電影TOP250
import ria fff python top font beautiful code pen 項目1:實現豆瓣電影TOP250標題爬取: 1 from urllib.request import urlopen 2 from bs4 import Beaut
為什麽要使用scrapy而不是requests+beautifulsoup?
網絡 soup quest nodejs cnblogs 總結 scrapy 效率 http 總結起來,有倆點最重要: 1)scrapy使用twisted異步網絡框架,類似nodejs,性能高; 2)scrapy內置的selector比beautifulsoup效率要高很
python實現簡單爬蟲功能
我們 目錄 size .com all 本地文件 使用 url alt 在我們日常上網瀏覽網頁的時候,經常會看到一些好看的圖片,我們就希望把這些圖片保存下載,或者用戶用來做桌面壁紙,或者用來做設計的素材。 我們最常規的做法就是通過鼠標右鍵,選擇另存為。但有些圖片鼠標右
爬蟲基礎知識與簡單爬蟲實現
春秋 屬性 str 版本 page 2017年 light install defaults css規則:選擇器,以及一條或者多條生命。 selector{declaration1;,,,;desclarationN} 每條聲明是由一個屬性和一個值組成 propert