
【若澤大資料實戰第七天】MySQL在DBeaver上的使用
一、建立一張表:
create table 資料庫名.表名(欄位 型別,……) 例如:create table ruozedata( id int, name varchar(100), age int, createtime timestamp, createuser varchar(100), updatetime varchar(100), updateuser varchar(100) );注意:在建立表的時候,必須有createtime和updatetime
在DBeaver表示如下:
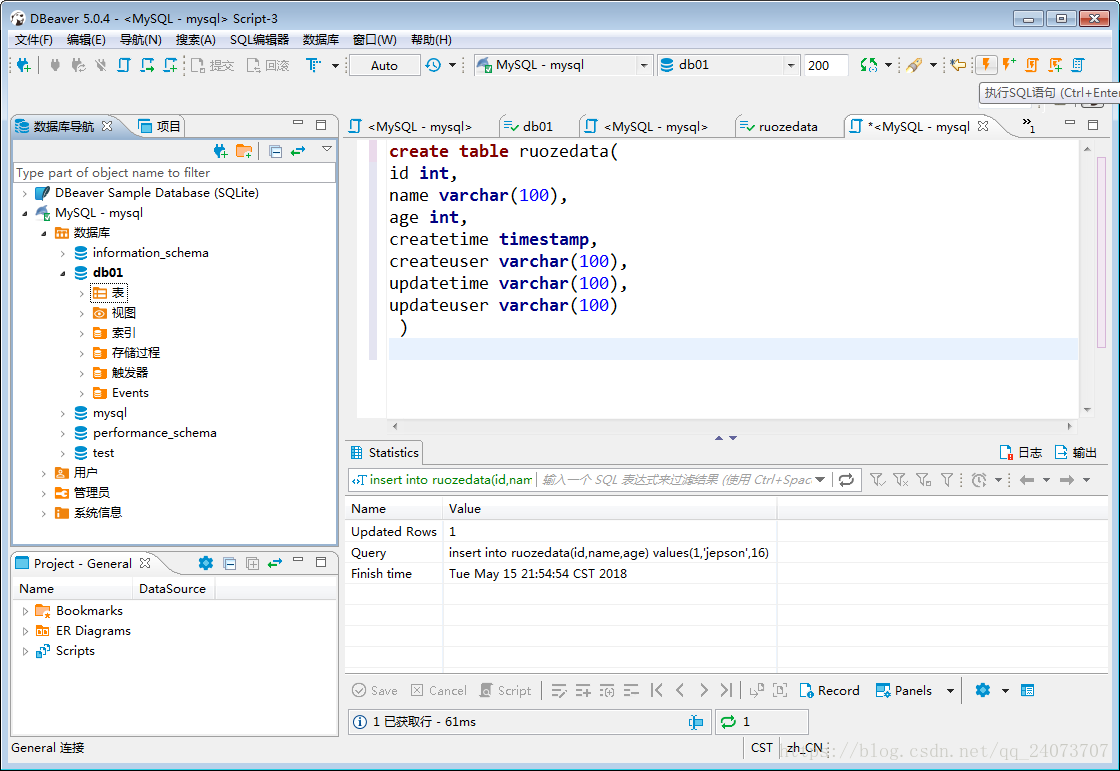
點選表 ruozedata 我們能檢視相關資訊:

二、刪除一張表:
drop table ruozedata;
執行刪除操作:
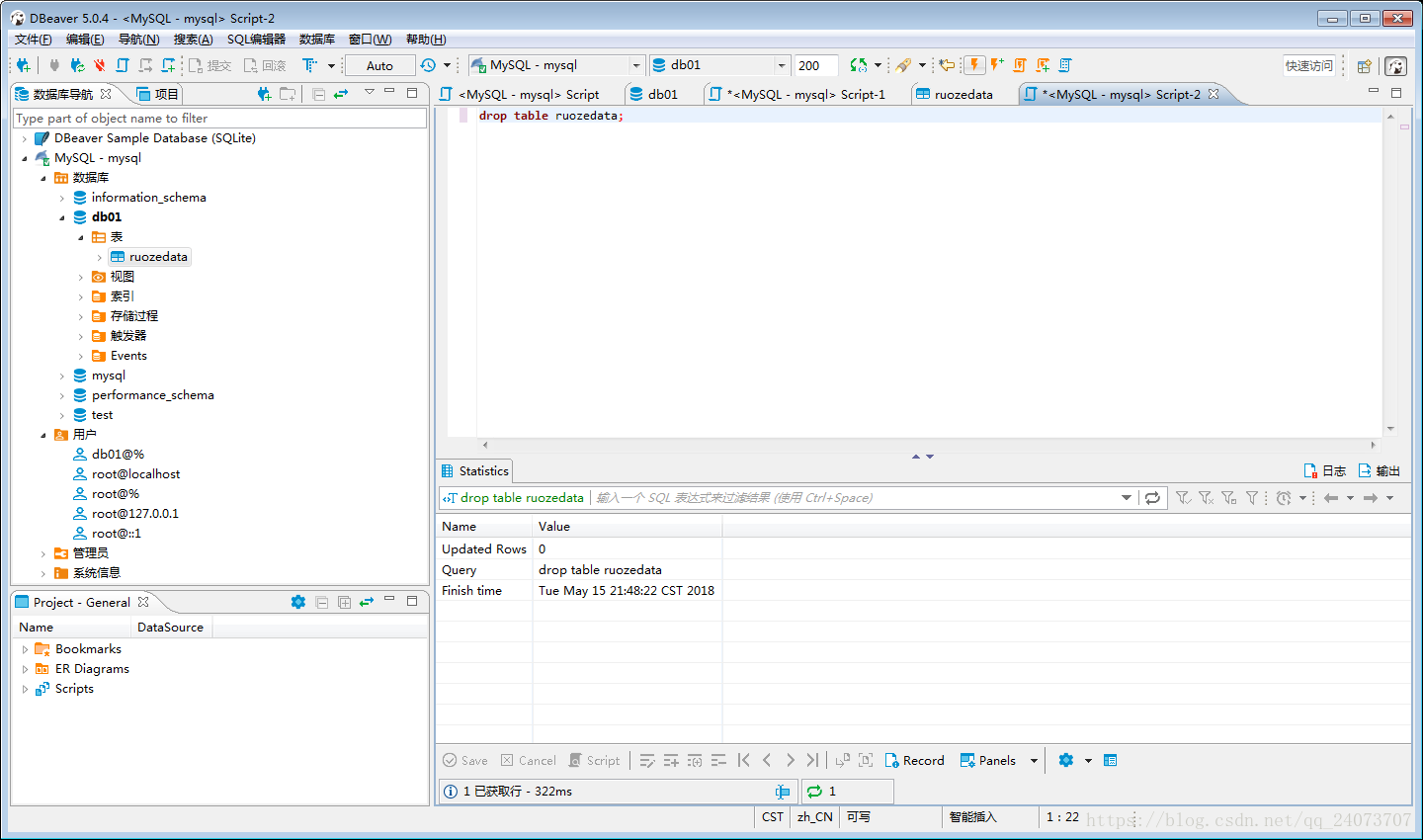
點左邊的表重新整理後,發現表ruozedata已經刪除:

三、插入一條資料:
insert into ruozedata(id,name,age) values(1,'jepson',16);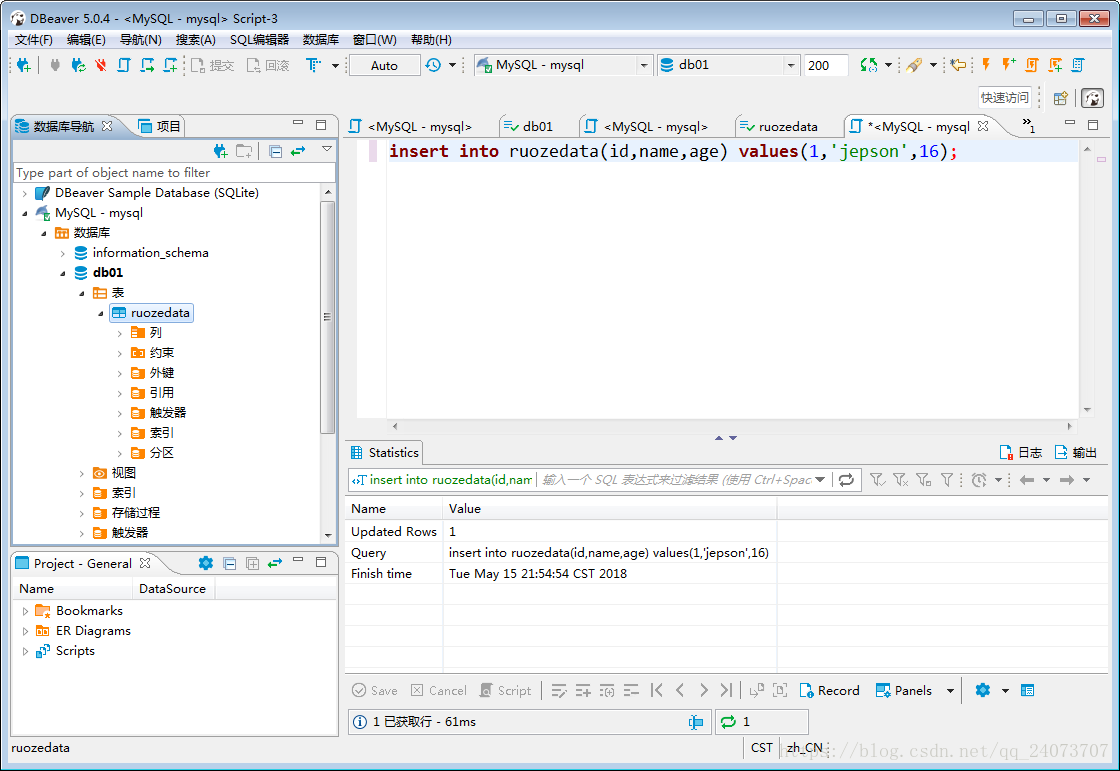
點選ruozedata右邊的資料,就會顯示我們剛剛插入的一條資料:
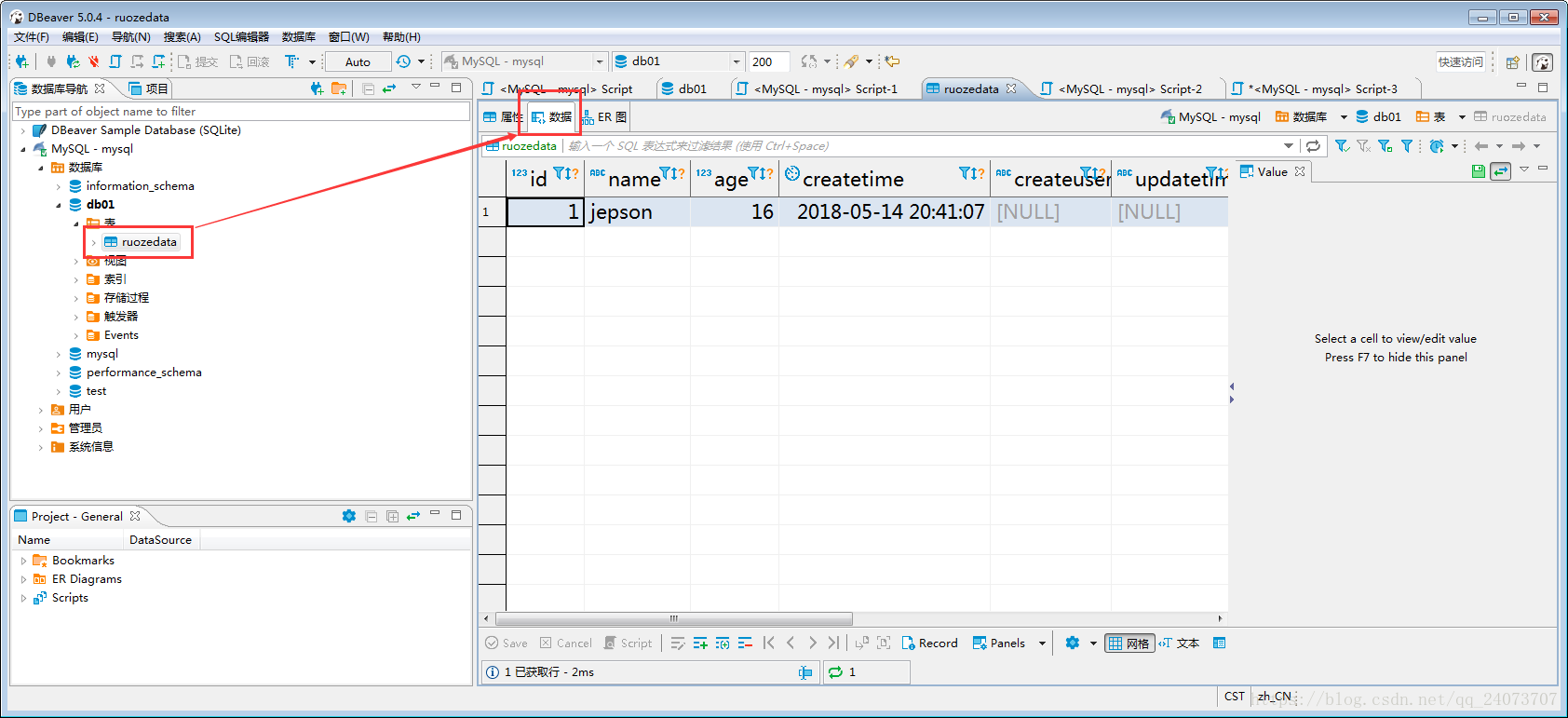
四、更新一條資料:
update ruozedata set age=22 where name='jepson';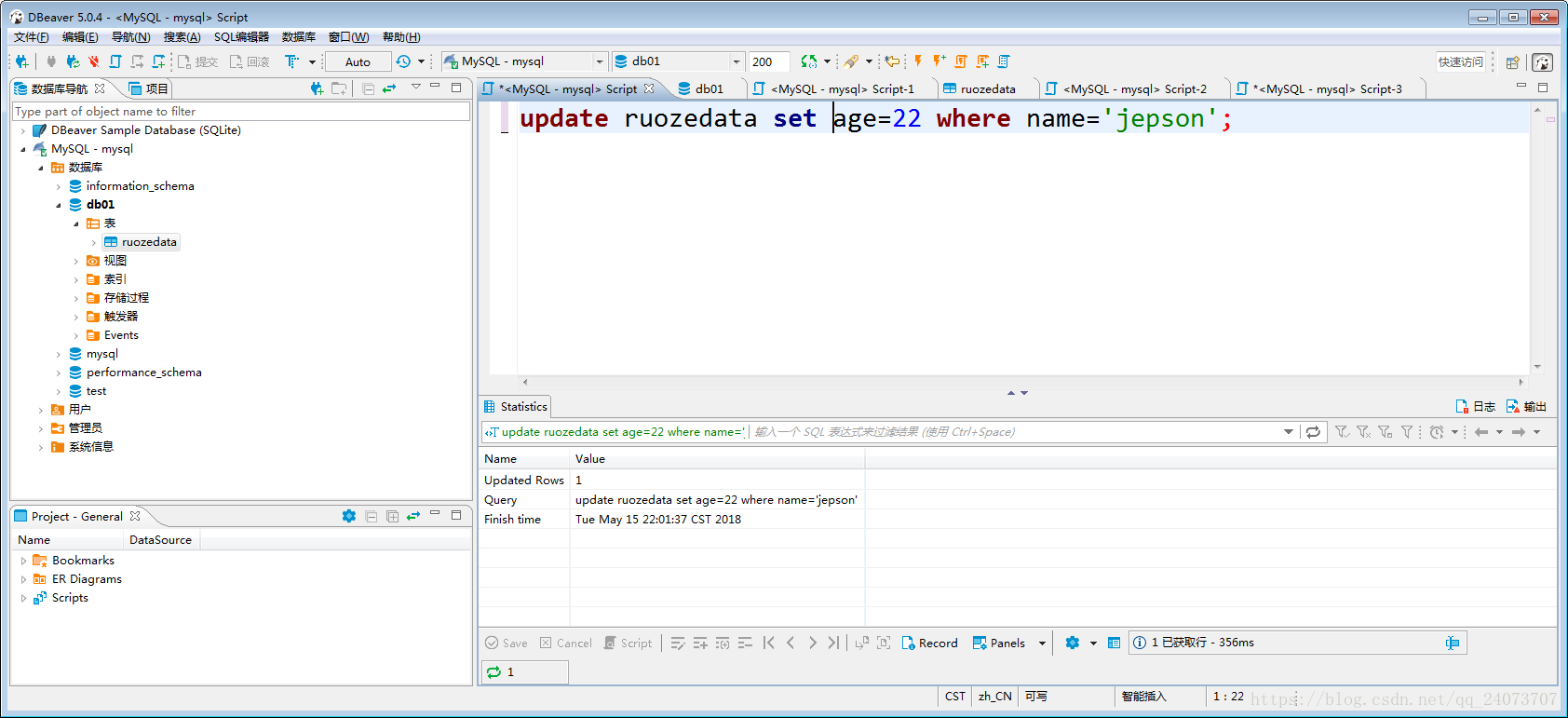
右邊有個重新整理,點選重新整理後,年齡從16歲就更新到22歲:

五、刪除一條資料:
delete from ruozedata where name='jepson'
刪除資料執行後,重新整理完,發現數據確實刪除了:
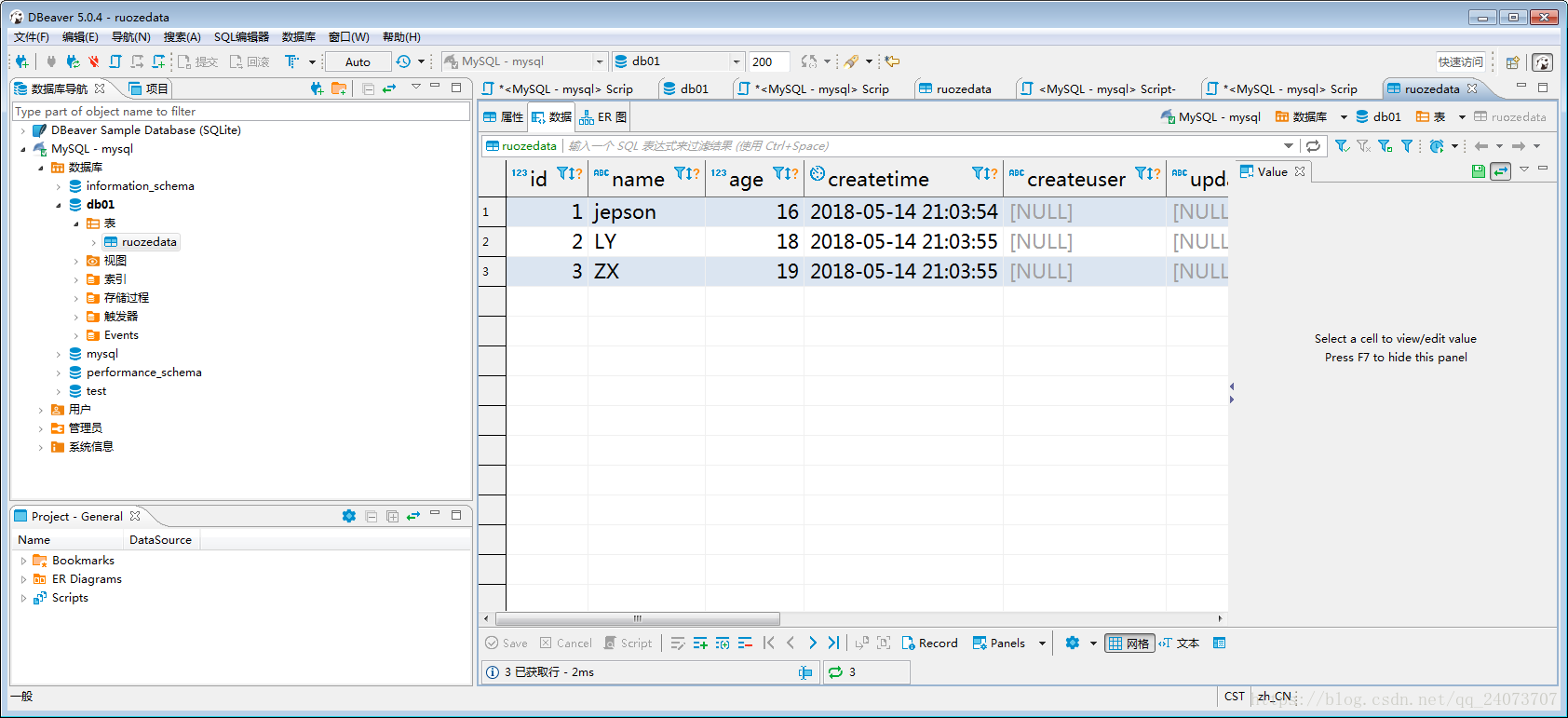
插入三條語句測試:
當插入三條語句的時候,我們要點選右邊的,執行指令碼,這樣三條語句就都執行了。

檢視結果:
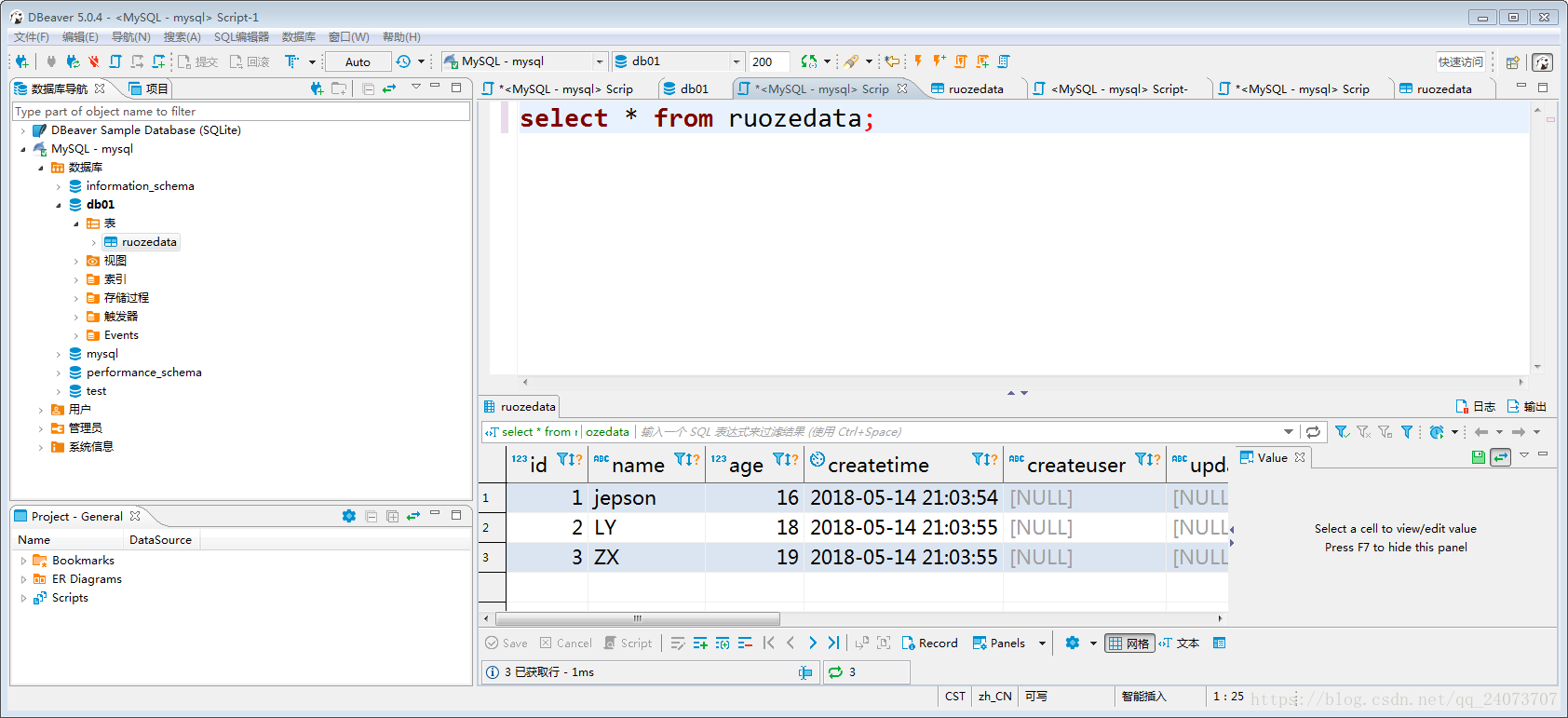
六、查詢資料:
select * from ruozedata;
七、插入的內容沒有指定列,就需要補全所需的列:
insert into ruozedata
values(4,'ZX1',119,'2017-10-10 00:00:00','xxx','2017-12-10 00:00:00','xxx1');

檢視結果:
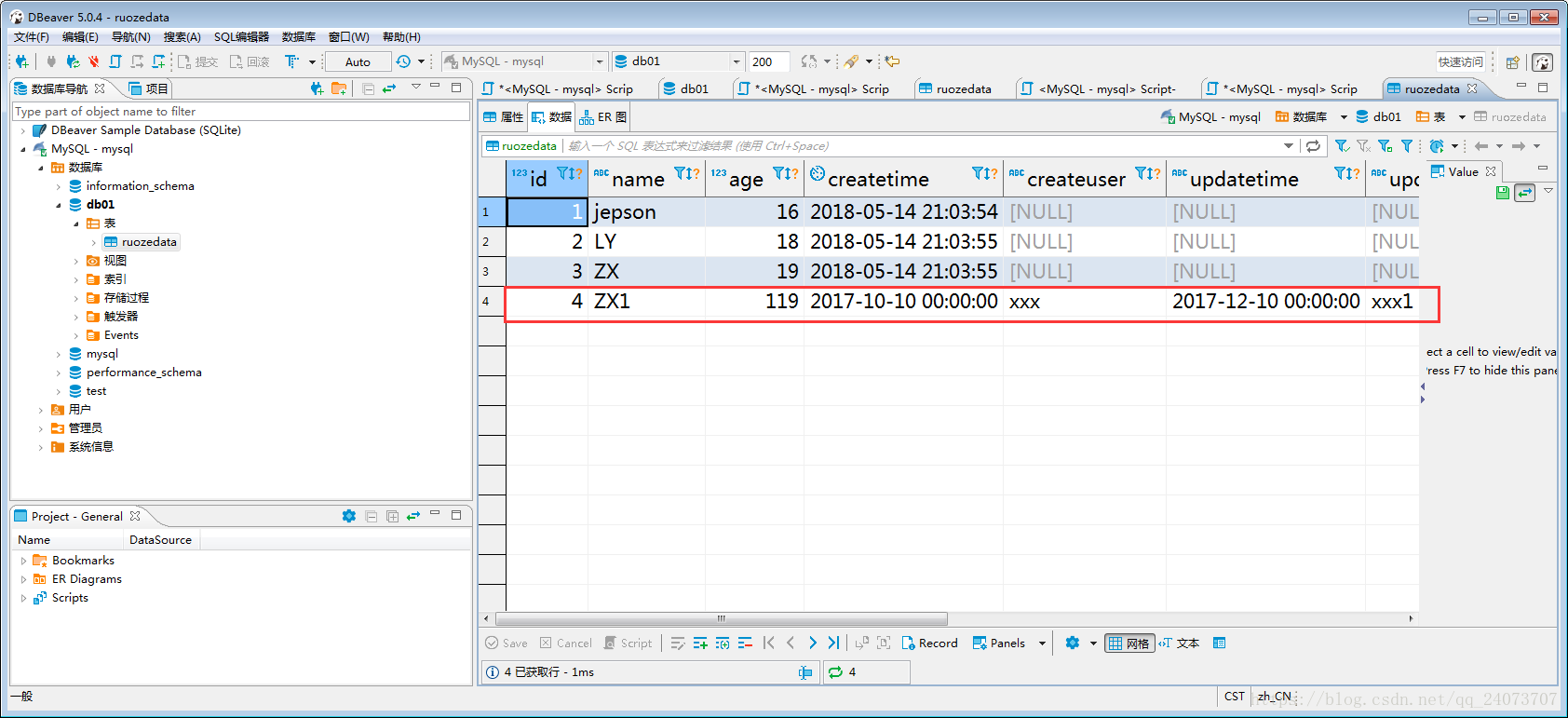
八、update insert等操作後面的where條件要加好,如果不加好會導致更新整個列:
原表資訊:

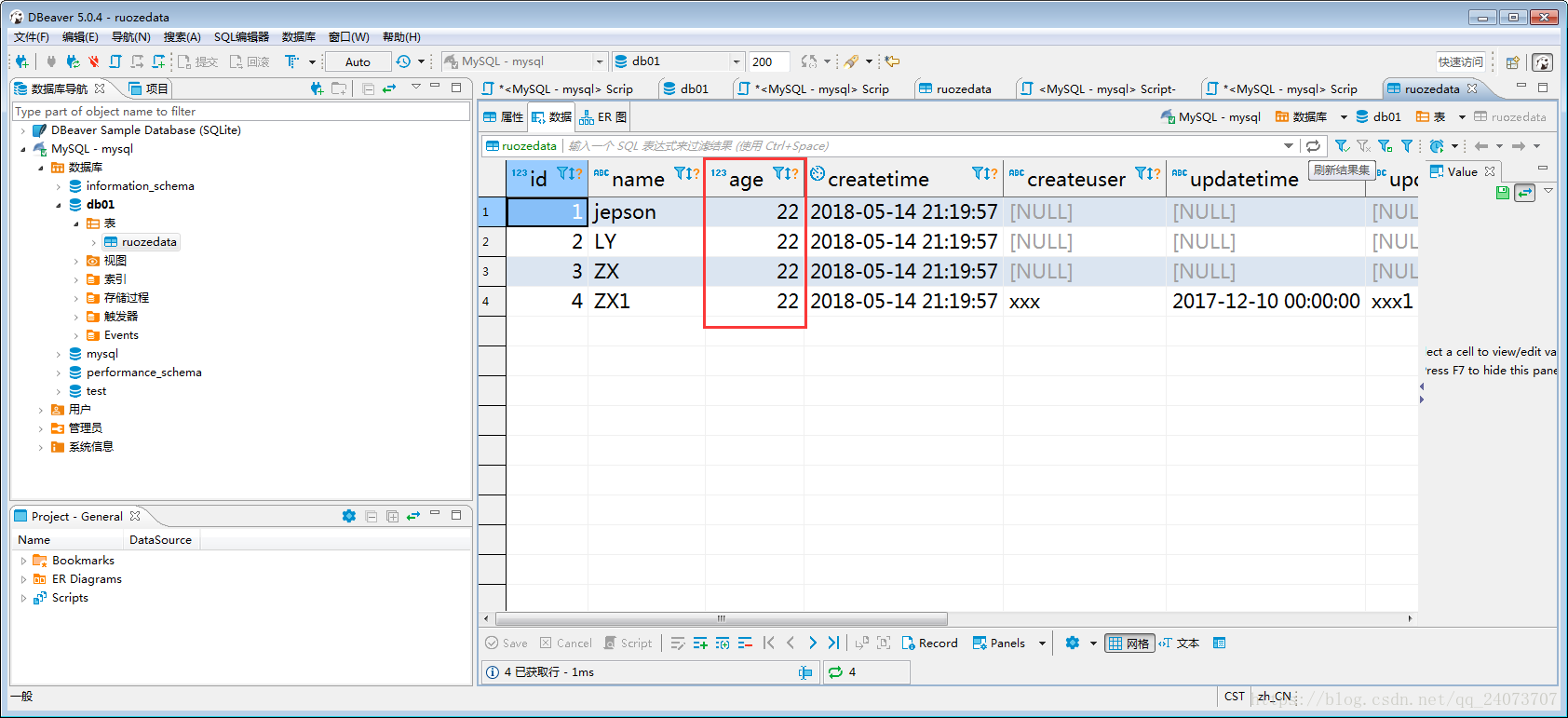
更新不加where條件資訊提示:
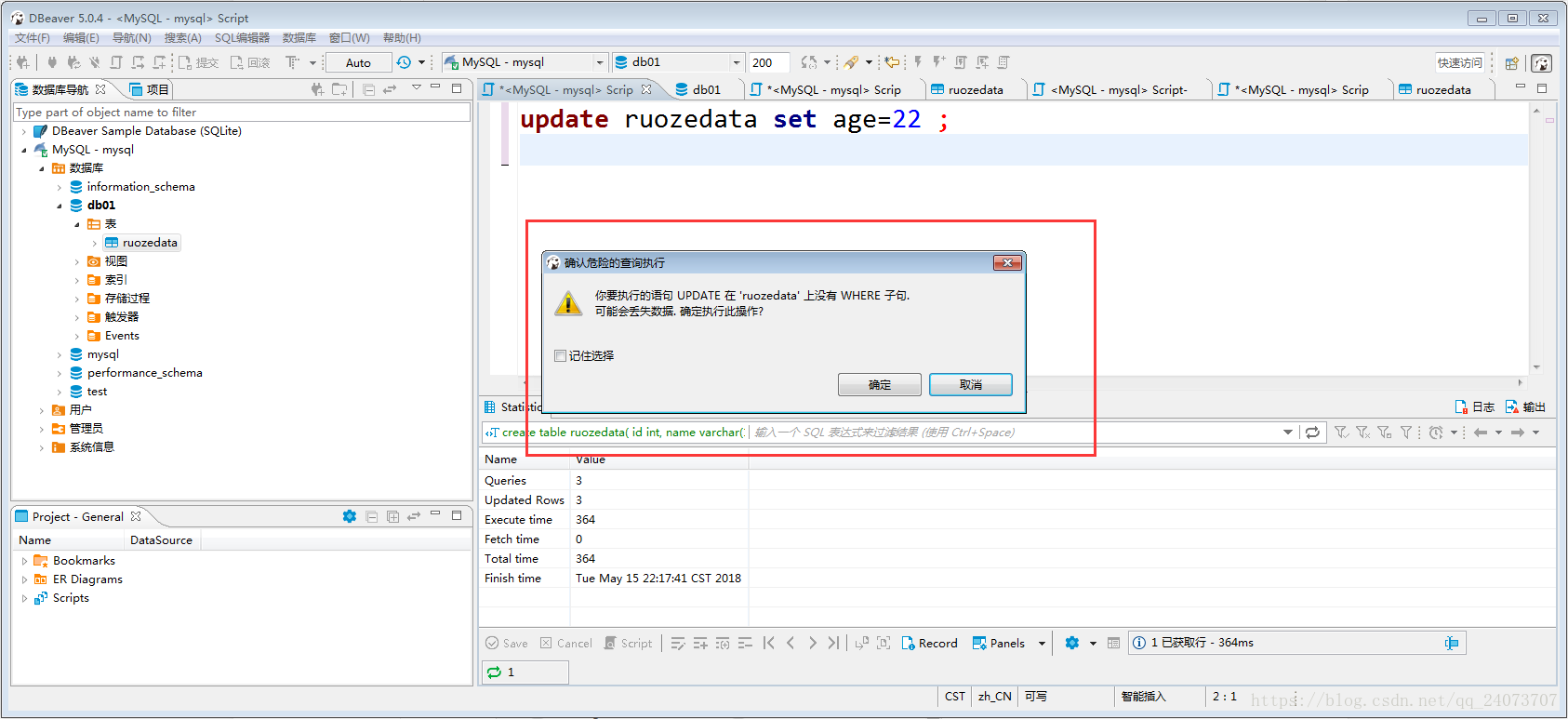
生產中禁止不加where條件的操作!!!
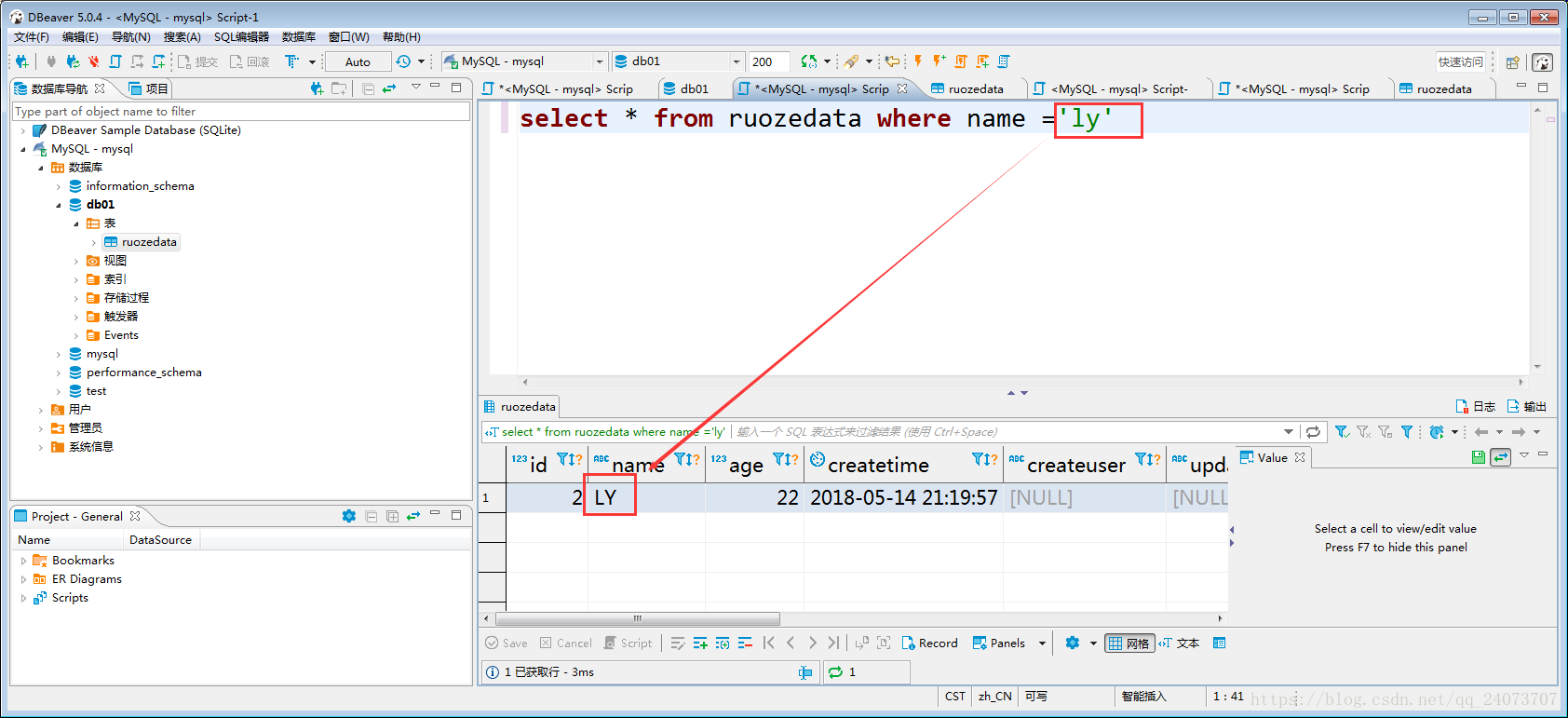
八、MySQL預設不區分大小寫測試:
select * from ruozedata where name ='ly';
九、建立一張表讓 id自增長測試:
create table ruozedata(
id int AUTO_INCREMENT primary key, (再這裡設為主鍵加了自增長)
name varchar(100),
age int,
createtime timestamp,
creuser varchar(100),
updatetime timestamp,
updateuser varchar(100)
)

然後往表裡面插入一些資料,不帶id這列:
insert into ruozedata(name,age) values('jepson',16);
insert into ruozedata(name,age) values('LY',18);
insert into ruozedata(name,age) values('ZX',19);
insert into ruozedata(name,age) values('ZX1',119);

檢視結果,自動增長ID這一列:
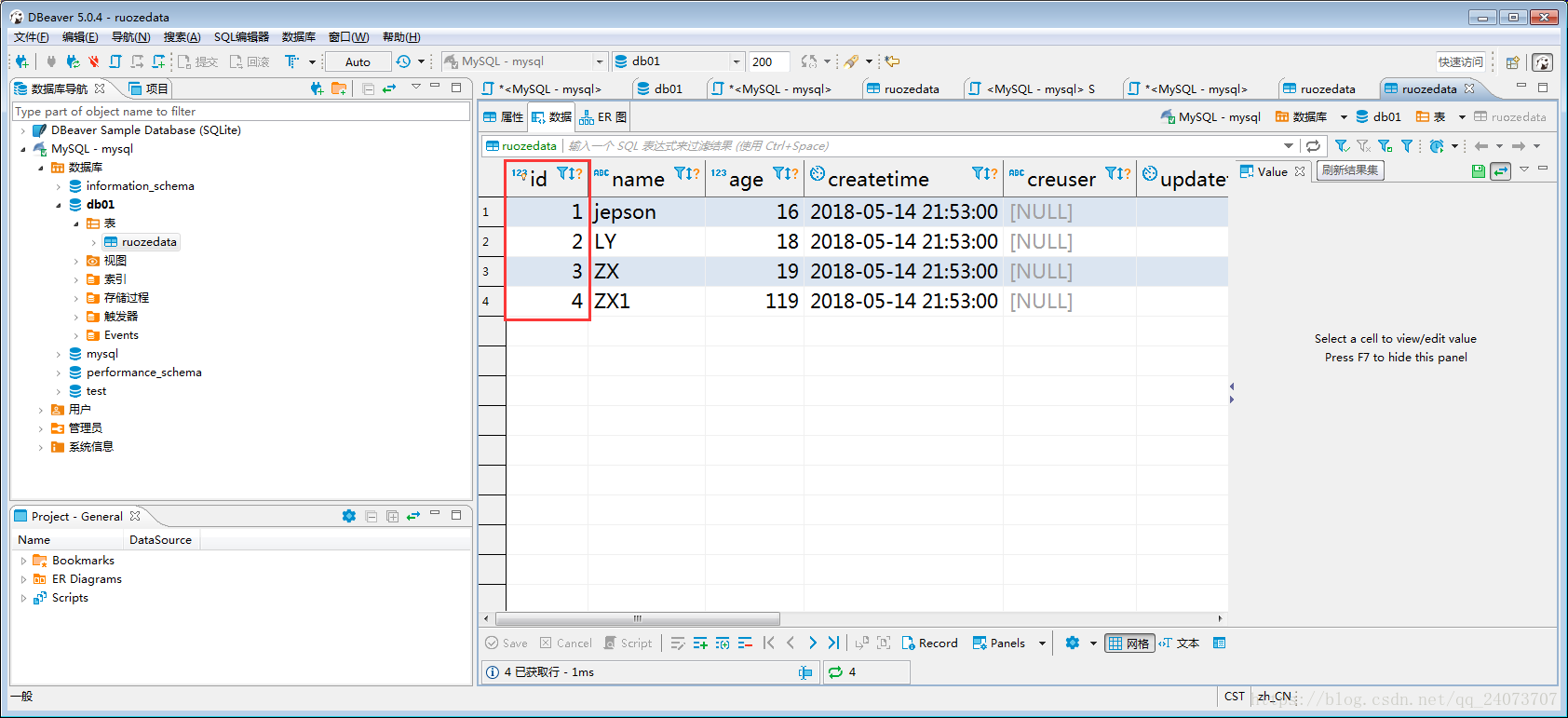
十、在生產環境建立一張表需要注意哪些事項:
create table ruozedata(
id int AUTO_INCREMENT primary key,(再這裡設為主鍵加了自增長)
(這裡會寫一下根據建表的需求寫一些其他的列的值和內容)
name varchar(100),
age int,
createtime timestamp DEFAULT CURRENT_TIMESTAMP, (建立時間用的是預設的當前時間)
creuser varchar(100),
updatetime timestamp DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,(更新的時間要從建立的時間加更新當前時間)
updateuser varchar(100)
)

插入一條資訊測試:
本條資料不帶ID列:
insert into ruozedata(name,age) values('jepson',16);
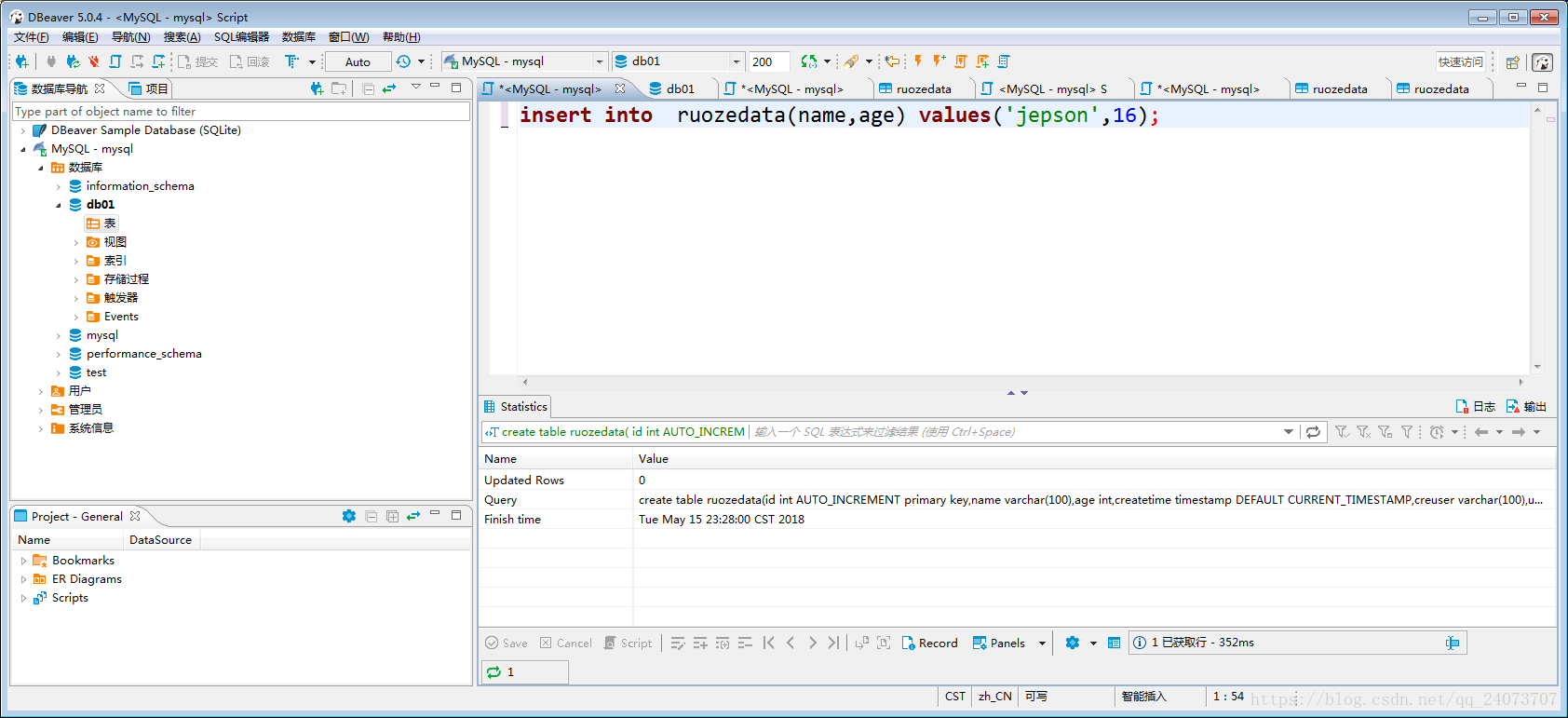
注意建立表和更新表的時間都有了,都是一樣的,因為我們這張測試表沒有做過更新的操作,
所以createtimie和updatetime的時間是一樣的:

做一次更新操作,讓更新的時間不同於建立的時間:
update ruozedata set age=22 where name='jepson';
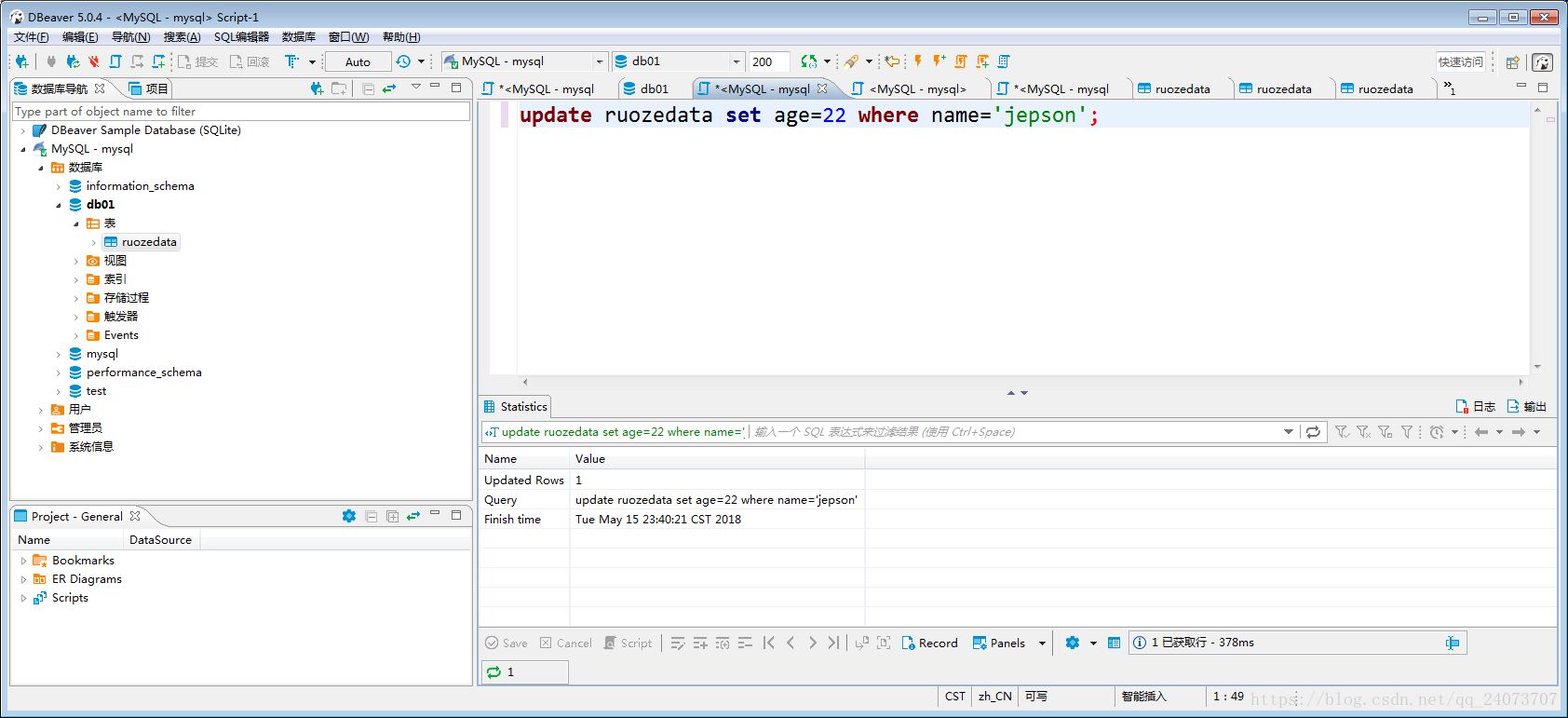
檢視更新後的表,updatetime時間更新了:

通過DDL檢視建立表的資訊:
最後一行我標記了1、2、3
1:MySQL引擎從5.7以後都使用的是innoDB,預設的也是使用innoDB引擎
2:關於自增長,如果是delete table停留在之前的,並不會初始化為0
新的資料匯入進來,自增長會有問題,不是從1開始,要考慮當場的業務場景,
如果是 drop 表的話,從新建立,表的自增長是從1開始的。
create table ruozedata(
id int AUTO_INCREMENT primary key,
name varchar(100),
age int,
createtime timestamp DEFAULT CURRENT_TIMESTAMP,
creuser varchar(100),
updatetime timestamp DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP,
updateuser varchar(100)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=Latin1;
1 2 3

3:字符集:
當前我們可以看資料庫字符集,拉丁字符集
Server拉丁字符集
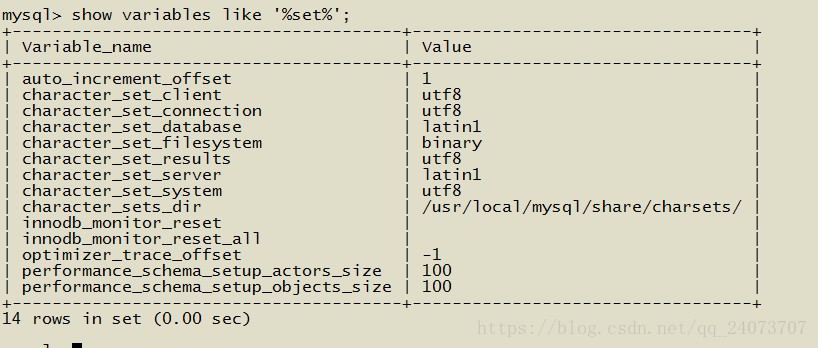
檢視建立資料庫時的字符集,建立的時候預設沒有選字符集:

字符集不是utf8測試:
insert into ruozedata(name,age) values('若澤',16);
測試下來發現不是utf8不支援中文
一、建立一張表: create table 資料庫名.表名(欄位 型別,……)
例如:
create table ruozedata(
id int,
Hadoo官網檢視單節點安裝步驟:1.登入Hadoop主頁,http://hadoop.apache.org/2.找到左側的Documentation,點選下拉箭頭找到我們現在正在使用的Hadoop版本3.若澤大資料課程的Hadoop版本為Release 2.8.3,單擊進入
前言:有很多小夥伴對這幾個東西的概念有些模糊,這裡我做一個總結,希望大家能一篇看懂。一、HDFSHDFS是分散式檔案系統,有高容錯性的特點,可以部署在價格低廉的伺服器上,主要包含namenode和dat
前言: 上期課程J哥給我們講了很多有關於HDFS內部的namenode,datanode,secondary的各種分析,下面的課程涉及到了讀流程和寫流程。我也將詳細的梳理清楚。HDFS寫流程1.檔案寫流程 --> FSDataOutputStream (面試題)
1、MySQL預設配置檔案是在哪裡?/etc/my.cnf
2、賦予許可權的最後一個命令flush privileges
3、允許所有IP可以訪問,用什麼表示%
4、插入一條語句的語法insert i
MySQL的基本概念database db :資料庫
table : 表
db1:t1, t2, t3
db2:t2, t3, t4
欄位型別整數型:int
小數型:float/double
字元:ch
1、如何判斷一個Linux上的xxx服務是否存活
# ps -ef | grep xxx 檢視程序
2、埠號哪個命令去看看通不通
# telnet
3、檢視Linux的ip哪些途徑
# ifconfig
# hostname -i
4、對
1、pwd表示什麼
# 當前目錄
2、隱藏目錄什麼標識開始,怎麼看
# 隱藏檔案或者資料夾以.開頭
# ll -a
3、檢視檔案的大小哪兩組命令
# ll -h
# du -sh xx
4、怎樣測試埠通不通
# telnet
5、檢視程序和埠號命令分別是
1、級聯建立資料夾的命令引數
# mkdir -p xxx xxx
2、建立檔案有哪幾種方法
# touch vi echo mv cp
3、重新命名一般用哪個命令
# mv
4、說說大R引數的命令有哪些
# chown chmod
5、說說小r引數的
配置檔案設定 vi /etc/my.cnf[client]#user=root#password=123456socket=/var/lib/mysql/mysql.sock[mysqld]########basic settings########server-id = 1
問題:安裝mysql過程中出現的依賴
[[email protected] mysql-5.7.16]# rpm -ivh mysql-community-devel-5.7.16-1.el7.x86_64.rpm
warning: mysql-community
今天,是學習Linux的第三天了,也是最後一天。
重要的內容不少,所以不能掉以輕心哦。
好了,廢話不多說,進入正題。
1. 系統服務的基本操作
1.chkconfig
列出當前系統的常駐服務
2.service 服務名 start/stop/status/restart mod func kconfig currency rem .gz ... lin profile 下載mysql並檢查MD5
[root@hadoop-01 ~]# cd /usr/local
[root@hadoop-01 local]# wget https://do 計算平臺追求目標:目前內部 MaxCompute 叢集上有 200 多萬個任務,每天儲存資源、計算資源消耗都很大。 如何降低計算資源的消耗,提高任務執行的效能,提升任務產出的時間。
1.系統優化
(1)HBO (History-Based Optimiz町, 基於歷史的優化器 arch email handlers app som == await href started MVC框架
使用模板
MVC的全名是Model View Controller,是模型-視圖-控制器的縮寫,是一種軟件設計典範。使用MVC的目的是使M和V的代碼分離,從而使一
1.檢視當前路徑
pwd
2.家目錄
linux系統中分為普通使用者和超級使用者,超級使用者擁有所有的許可權,普通使用者擁有部分許可權。
超級管理員對應的家目錄是:/root ,而一般使用者的家目錄是在/home/下的
3.切換目錄
cd
1.切換使用者和臨時獲取root使用者最大許可權的命令分別是什麼
su
sudo
2.想要用sudo命令,我們需要配置無密碼的臨時root最大許可權,修改哪個檔案,新增一行什麼語句?
/etc/sudoers
新增一句
xxx ALL=(root)
第014講:Scala中Map和HashMap原始碼剖析及程式碼實踐/**
* A generic trait for immutable maps. Concrete classes have to provide
* functionality for the abs
第七天 自定義資料型別&ArrayList集合【悟空教程】
第07天 自定義資料型別、Arraylist集合
第1章 自定義資料型別
1.1 自定義資料型別概述
任何程式語言都需要將現實生活中的事物抽象成程式碼。這時可以使用自定義的資料型別(類)來描述(對
流失客戶分類模型
1 資料預處理
如果動手做過的人可能面臨的第一個問題就是,這資料讀進pandas怎麼弄編碼結果都是錯的。如果你存在這樣的問題,那麼我建議你使用NotePad++載入檔案以後,改成無BOM的UTF-8編碼,然後就可以正常讀取了。
資料預處理部 相關推薦
【若澤大資料實戰第七天】MySQL在DBeaver上的使用
【若澤大資料實戰第十天】Hadoo官網使用教程
【若澤大資料實戰第十五天】關於HDFS、YARN及MapReduce的總結
【若澤大資料實戰第十二天】HDFS課程 讀流程-寫流程
【若澤大資料MySQL實戰】MySQL知識點
【若澤大資料MySQL實戰】MySQL基礎語法
【若澤大資料早課】day4--20180913
【若澤大資料早課】day5--20180914
【若澤大資料早課】day7--20181009
【若澤大資料】生產環境mysql5.6-my.cnf 配置檔案 for linux
大資料學習第2天----------------linux 安裝mysql 出現安裝依賴問題解決(centos7)
大資料學習第三天 Linux完結篇
【若澤大數據MySQL實戰】MySQL5.6 二進制部署
【阿里巴巴大資料實踐筆記】第13章:計算管理
廖大python實戰教程第七天
【若澤資料第二天】linux基本命令一
【若澤資料零基礎班9月12日早課】總結
第014講:Scala中Map和HashMap原始碼剖析及程式碼實踐(從1000個程式碼案例中學習人工智慧和大資料實戰)
第七天 自定義資料型別&ArrayList集合【悟空教程】
python資料分析與挖掘實戰 第七章 拓展思考