
Python爬蟲之百度貼吧
目標:
1、對百度貼吧的任意帖子進行爬取
2、爬取帖子指定內容
3、將爬取內容儲存到檔案
1、分析url
https://tieba.baidu.com/p/3138733512?see_lz=1&pn=1
分析:
https:傳輸協議
tieba.baidu.com:百度二級域名
p/3138733512:資源定位
see_lz=1&pn=1:引數see_lz:樓主 pn=1:第一頁
2、頁面抓取
上程式碼:
# coding=utf-8
import urllib
import urllib2
import re
#百度貼吧爬蟲類
class print(result)這句是輸出原始碼
執行程式:
3、 提取相關資訊
提取貼吧標題
谷歌瀏覽器按F12,查詢標題的html程式碼
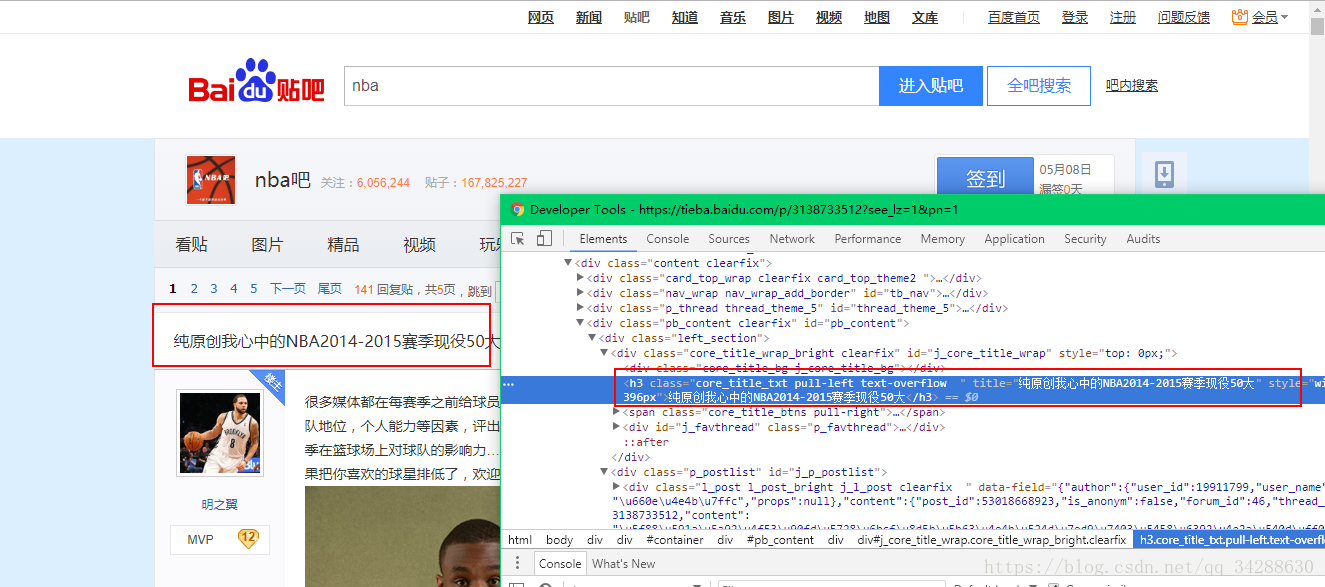
<h3 class="core_title_txt pull-left text-overflow " title="純原創我心中的NBA2014-2015賽季現役50大" style="width: 396px">純原創我心中的NBA2014-2015賽季現役50大</h3>所以我們想提取 h1標籤中的內容,同時還要指定這個class確定唯一,因為h1標籤實在太多啦。
正則表示式如下:
<h3 class="core_title_txt.*?>(.*?)</h3>獲取標題程式碼
#獲取帖子標題
def getTitle(self):
page = self.getPage(1)
pattern = re.compile('<h3 class="core_title_txt.*?>(.*?)</h3>',re.S)
result = re.search(pattern,str(page))
if result:
print result.group(1) # 測試輸出
return result.group(1).strip()
else:
return None完整程式碼:
# coding=utf-8
import urllib
import urllib2
import re
#百度貼吧爬蟲類
class BDTB:
#初始化,傳入基地址,是否看樓主的引數
def __init__(self, baseUrl, seeLZ):
self.baseURL = baseUrl
self.seeLZ = '?see_lz='+str(seeLZ)
#傳入頁碼,獲取該頁帖子的程式碼
def getPage(self,pageNum):
try:
url = self.baseURL+self.seeLZ+'&pn'+str(pageNum)
request = urllib2.Request(url)
response = urllib2.urlopen(request)
result = response.read()
return result
except urllib2.URLError,e:
if hasattr(e,"reason"):
print u"連線百度貼吧失敗,錯誤原因",e.reason
return None
#獲取帖子標題
def getTitle(self):
page = self.getPage(1)
pattern = re.compile('<h3 class="core_title_txt.*?>(.*?)</h3>',re.S)
result = re.search(pattern,str(page))
if result:
print result.group(1) # 測試輸出
return result.group(1).strip()
else:
return None
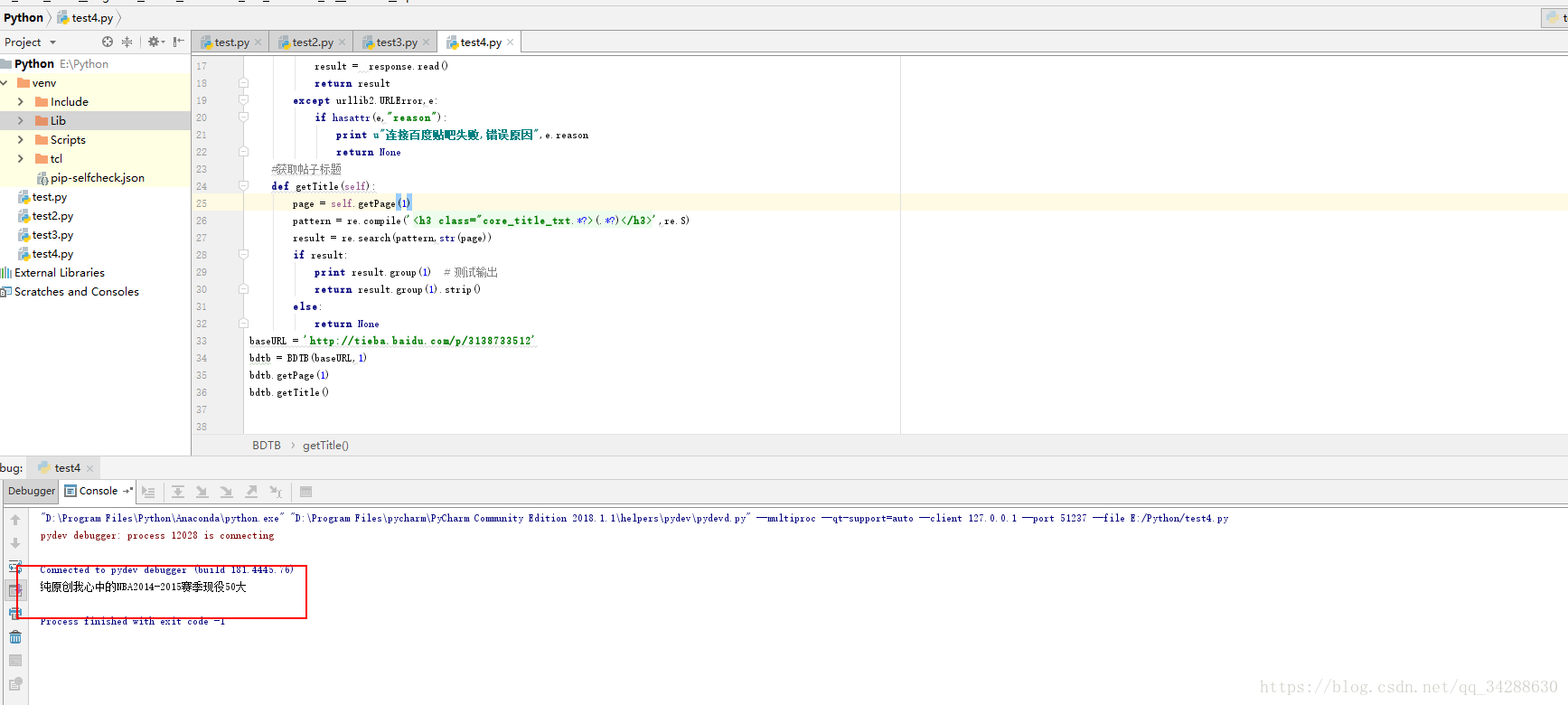
baseURL = 'http://tieba.baidu.com/p/3138733512'
bdtb = BDTB(baseURL,1)
bdtb.getPage(1)
bdtb.getTitle()
執行:
相關推薦
Python爬蟲之百度貼吧
目標: 1、對百度貼吧的任意帖子進行爬取 2、爬取帖子指定內容 3、將爬取內容儲存到檔案 1、分析url https://tieba.baidu.com/p/3138733512?se
Python爬蟲 -下載百度貼吧圖片
先放上程式的程式碼 import urllib.request import os import easygui as g import re def url_open(url): req = urllib.request.Request(url)
Python爬蟲系列之百度貼吧爬取
今天給的一個爬蟲小事例,貼吧段子爬取這樣一個小功能,資料呢僅僅娛樂,沒有惡意想法 若有侵權,請私信刪除 此次用到的一個解析庫Beautiful Soup,更輕量簡單地對資料進行解析,已獲得目標資料 貼吧做的還是比較好,有一定的反爬機制,所以我們也應該有一定的應對措施
Python爬取百度貼吧數據
utf-8 支持我 family encode code word keyword 上一條 時間 本渣除了工作外,在生活上還是有些愛好,有些東西,一旦染上,就無法自拔,無法上岸,從此走上一條不歸路。花鳥魚蟲便是我堅持了數十年的愛好。 本渣還是需要上班,才能支持我的
爬蟲10-百度貼吧
""" __title__ = '' __author__ = 'Thompson' __mtime__ = '2018/8/21' # code is far away from bugs with the god animal protecting I love animals. The
python爬取百度貼吧指定內容
環境:python3.6 1:抓取百度貼吧—linux吧內容 基礎版 抓取一頁指定內容並寫入檔案 萌新剛學習Python爬蟲,做個練習 貼吧連結: http://tieba.baidu.com/f?kw=linux&ie=utf-8&pn=0 解析原始碼使用的是B
【Python3爬蟲】百度貼吧爬蟲
1 import requests 2 import time 3 import re 4 from selenium import webdriver 5 6 headers = { 7 "user-agent": "Mozilla/5.0 (Windows NT 6.
Python爬取百度貼吧標題
# -*- coding: utf-8 -*- """ Created on Sun Nov 4 10:22:07 2018 @author: wangf """ from urllib.request import urlopen import codecs from
Python爬取百度貼吧圖片指令碼
新手,以下是爬取百度貼吧制定帖子的圖片指令碼,因為指令碼主要是解析html程式碼,因此一旦百度修改頁面前端程式碼,那麼指令碼會失效,權當爬蟲入門練習吧,後續還會嘗試更多的爬蟲。 # coding=ut
Python爬取百度貼吧回帖中的微訊號(基於簡單http請求)
作者:草小誠 轉載請注原文地址:https://blog.csdn.net/cxcjoker7894/article/details/85685115 前些日子媳婦兒有個需求,想要一個任意貼吧近期主題帖的所有回帖中的微訊號,用來做一些微商的操作,你懂的。因為有些貼吧專門就是
Python爬取百度貼吧的圖片
Python是一個弱型別的動態語言 下面是我的第一個簡單的爬蟲指令碼程式 #coding=gbk #匯入re和urlLib兩個庫 import re import urllib #定義一個有參的獲得圖片的方法,方法名為getImg def getImg(url):
Python簡易爬蟲爬取百度貼吧圖片
decode works 接口 def 讀取 min baidu 得到 internal 通過python 來實現這樣一個簡單的爬蟲功能,把我們想要的圖片爬取到本地。(Python版本為3.6.0) 一.獲取整個頁面數據 def getHtml(url)
Python爬蟲實例(一)爬取百度貼吧帖子中的圖片
選擇 圖片查看 負責 targe mpat wid agent html headers 程序功能說明:爬取百度貼吧帖子中的圖片,用戶輸入貼吧名稱和要爬取的起始和終止頁數即可進行爬取。 思路分析: 一、指定貼吧url的獲取 例如我們進入秦時明月吧,提取並分析其有效url如下
python 爬蟲 百度貼吧簽到小工具
sca window user con lee post use wow64 搜索 import requests,re,timeheader ={ "Cookie":"登陸過賬號後的cookie 必須填寫", "User-Agent":"Mozilla/5.
Python實現簡單爬蟲功能--批量下載百度貼吧裡的圖片
在上網瀏覽網頁的時候,經常會看到一些好看的圖片,我們就希望把這些圖片儲存下載,或者使用者用來做桌面桌布,或者用來做設計的素材。 我們最常規的做法就是通過滑鼠右鍵,選擇另存為。但有些圖片滑鼠右鍵的時候並沒有另存為選項,還有辦法就通過就是通過截圖工具擷取下來,但這樣就降低圖片的清晰度
Python爬蟲-爬取百度貼吧
方法 eba style name urlopen for pri url pen 爬取百度貼吧 ===================== ===== 結果示例: ===================================== 1 ‘‘‘ 2 爬去百
Python爬蟲教程:爬取百度貼吧
貼吧爬取 寫程式碼前,構思需要的功能塊;寫程式碼時,把各個功能模組名提前寫好 初始化 初始化必要引數,完成基礎設定 爬取百度貼吧lol吧:爬取地址中的get引數須傳遞(可以指定不同主題的貼吧和頁碼) 主題名 初始網址 請求頭 生成網址 生成每一頁的路由
Python爬蟲例項:從百度貼吧下載多頁話題內容
上週網路爬蟲課程中,留了一個實踐:從百度貼吧下載多頁話題內容。我完成的是從貼吧中一個帖子中爬取多頁內容,與老師題目要求的從貼吧中爬取多頁話題還是有一定區別的,況且,在老師講評之後,我瞬間就發現了自己跟老師程式碼之間的差距了,我在程式碼書寫上還是存在很多不規範不嚴謹的地方,而且
Python爬蟲--- 1.5 爬蟲實踐: 獲取百度貼吧內容
原文連結:https://www.fkomm.cn/article/2018/7/22/21.html 經過前期大量的學習與準備,我們重要要開始寫第一個真正意義上的爬蟲了。本次我們要爬取的網站是:百度貼吧,一個非常適合新人練手的地方,那麼讓我們開始吧。 本次要爬的貼吧是<< 西
實戰python 爬蟲爬取百度貼吧圖片
#!/usr/bin/python import urllib,urllib2import re def getHtml(url): page = urllib2.urlopen(url) return page.read() def getImage(html): re_img = re.compil