
用Spark Streaming+Kafka實現訂單數和GMV的實時更新
前言
在雙十一這樣的節日,很多電商都會在大螢幕上顯示實時的訂單總量和GMV總額。由於訂單數量巨大,不可能每隔一秒就到資料庫裡進行一次SQL的資料統計,這時候就需要用到流式計算。本文將介紹一個簡單的Demo,講解如何通過Spark Stream消費來自Kafka中訂單資訊,然後計算訂單的數量和金額。
總體流程
一個完整的流程大概如下圖所示。
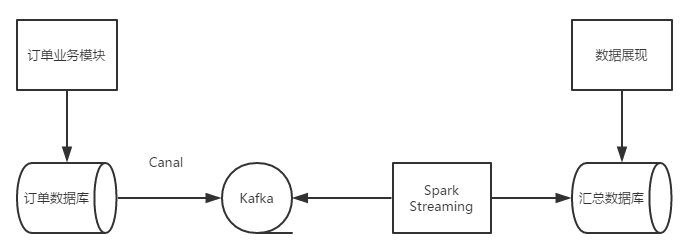
使用者下單之後,一筆訂單資訊會被訂單模組寫入到關係資料庫中,通過監聽binlog的變化(可以通過Canal實現),可以解析出資料庫的變化,並把剛才剛才新產生的記錄寫入到kafka的訊息佇列中。Spark Streaming作為kafka的的一個消費端從卡夫卡中讀取訂單資料,彙總計算訂單的總量和金額的總和,寫入到一個特定的彙總資料庫中,資料展現層程式碼從彙總資料庫中讀取彙總資料進行實施的訂單量和GMV總量的展示。
在這個例子中,為了簡單起見,會直接寫一個Kafka的Producer程式直接往kafka中傳送訂單資訊,同時也把寫入彙總資料庫的動作用System.out.println來代替(進而也就沒有 資料展現層的程式碼了)
程式碼實現
首先實現一個Order類來表示一筆訂單,在這個Demo中,Order類非常簡單,就是兩個欄位(name,price),分別表示訂單中商品的名稱和價格。
public class Order {
private String name;
private Float price;
public Order() {
}
public Order(String name, Float price) {
this.name = name;
this.price = price;
}
######省略getter,setter和toString
}
然後是一個向kafka佇列中傳送訂單資訊的Producer。這個類也非常簡單,只不過是把訂單物件轉換成Json格式的字串然後發往Kafka。
public class Producer {
public static void main(String[] args) throws IOException {
// set up the producer
KafkaProducer<String, String> producer = null;
ObjectMapper mapper = new ObjectMapper();
try {
InputStream props = Resources.getResource("producer.props").openStream();
Properties properties = new Properties();
properties.load(props);
producer = new KafkaProducer<String, String>(properties);
} catch (Exception e) {
e.printStackTrace();
System.exit(-1);
}
try {
for (int i = 0; i < 100; i++) {
// send lots of messages
Order order = new Order("name" + i, Float.valueOf("" + i));
producer.send(new ProducerRecord<String, String>("spark-test", mapper.writeValueAsString(order)));
System.out.println("message send " + i);
Thread.sleep(2000);
}
} catch (Throwable throwable) {
System.out.printf("%s", throwable.getStackTrace());
} finally {
producer.close();
}
}
}
然後Spark Streaming作為kafka的Consumer從佇列中消費資料,然後對每一個DDR進行轉換和統計。程式碼中進行了詳細的註釋,應該比較清楚。
public class OrderStreaming {
private static AtomicLong orderCount = new AtomicLong(0);
private static AtomicDouble totalPrice = new AtomicDouble(0);
public static void main(String[] args) {
SparkConf config = new SparkConf()
.setAppName("A spark streaming demo with Kafka resource");
JavaStreamingContext context = new JavaStreamingContext(config, new Duration(5 * 1000));
// context.checkpoint("/tmp/order-analyzer-streaming");
//使用1個程序來處理topic
Map<String, Integer> topicMap = new HashMap<String, Integer>();
topicMap.put("spark-test", 1);
//建立來自Kafka資料來源的DStream
JavaPairReceiverInputDStream<String, String> orderMsgStream = KafkaUtils.createStream(context,
"ddw-test-3:2181,ddw-test-4:2181,ddw-test-5:2181", //ZooKeeper的地址
"spark-streaming-order", //Consumer的Group ID
topicMap);
//第一次map,將JSON字串對映為Order物件
final ObjectMapper mapper = new ObjectMapper();
JavaDStream<Order> orderDStream = orderMsgStream.map(new Function<Tuple2<String, String>, Order>() {
@Override
public Order call(Tuple2<String, String> t2) throws Exception {
Order order = mapper.readValue(t2._2, Order.class);
return order;
}
}).cache();
//對DStream中的每一個RDD進行操作
orderDStream.foreachRDD(new VoidFunction<JavaRDD<Order>>() {
@Override
public void call(JavaRDD<Order> orderJavaRDD) throws Exception {
long count = orderJavaRDD.count();
if (count > 0) {
//累加訂單總數
orderCount.addAndGet(count);
//對RDD中的每一個訂單,首先進行一次Map操作,產生一個包含了每筆訂單的價格的新的RDD
//然後對新的RDD進行一次Reduce操作,計算出這個RDD中所有訂單的價格眾合
Float sumPrice = orderJavaRDD.map(new Function<Order, Float>() {
@Override
public Float call(Order order) throws Exception {
return order.getPrice();
}
}).reduce(new Function2<Float, Float, Float>() {
@Override
public Float call(Float a, Float b) throws Exception {
return a + b;
}
});
//然後把本次RDD中所有訂單的價格總和累加到之前所有訂單的價格總和中。
totalPrice.getAndAdd(sumPrice);
//資料訂單總數和價格總和,生產環境中可以寫入資料庫
System.out.println("Total order count : " + orderCount.get() + " with total price : " + totalPrice.get());
}
}
});
context.start(); // Start the computation
context.awaitTermination(); // Wait for the computation to terminate
}
}
執行程式
安裝有Spark的環境中執行 spark-submit --class "com.wjm.streaming.kafka.OrderStreaming" --master local[4] ./spark-1.0-SNAPSHOT.jar
然後在啟動producer類,然後我們可以在控制檯中看到 Total order count : 33 with total price : 1671.0 這樣的輸出。