
hadoop 簡單入門與streaming常用配置引數說明
阿新 • • 發佈:2019-01-22
1. Hadoop包含兩核心部分
- hdfs
- Hadoop distribute file system -- hadoop分散式檔案系統,儲存資料
- Namenode、Datanode
- 常用命令形式:hadoop fs -ls / hadoop fs -mkdir
- MapReduce
- 分而治之;map:實現分治;reduce:實現合併
- 解決資料可分割的計算問題
- 程式設計介面:常用Streaming;組成:Job配置檔案、map函式,reduce函式
2. hdfs結構圖
- Namenode儲存元資料,資料資訊,資料備份資訊
- Datanode 資料備份:本機架備份、異地備份

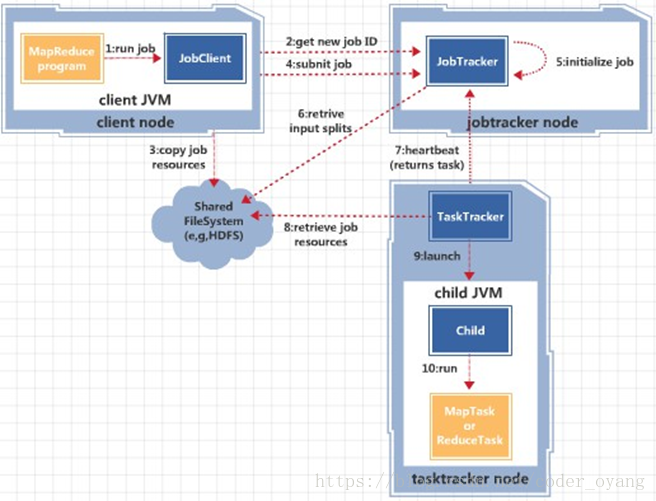
3. MapReduce排程框架
- JobClient: 負責根據使用者指定引數生成一個mapreduce作業,提交到JobTracker
- JobTracker: 單Master節點,將Job所有task排程到TaskTracker
- TaskTracker: 部署在每臺計算機節點的一個service
4. MapReduce 執行層
- Map階段,讀入資料,通過partition聚集相同key資料,並寫到本機磁碟
- Reduce階段,不同reduce,讀入Map階段各maps的相應輸出

5. streaming 作業
- streaming mapper
- 先啟動使用者提交作業時指定的一個外部程式,一般是指令碼
- 這個外部程式作為streaming mapper的子程序,streaming mapper讀取使用者輸入後,不再是呼叫map函式處理,而是通過管道寫到子程序的標準輸入
- 從子程序的標準輸出讀取資料,寫到磁碟上
- streaming 作業資料流向
- 父程序是Java,負責讀取資料通過管道傳送給子程序
- 通過管道把結果再讀取回來
一份資料在兩個不同程序中傳遞兩次
6 mapreduce – shuffle
- map --> shuffle –> reduce
- shuffle 從多個節點傳遞到多個節點,而不是多個節點到一個節點
- shuffle 包含partition、combiner
- partition : 資料歸併,分割map每個節點的結果,按照key分別對映給不同的reduce,預設是HashPartition,which reducer == (key.hashCode & Integer.MAX_VALUE)% numReduceTasks
- 作用:計算(key, value)所屬分割槽 ; 把同一分割槽資料合併、聚集
- combiner: combiner屬於優化方案,由於頻寬限制,應該儘量map和reduce之間的資料傳輸數量。它在Map端把同一個key的鍵值對合並在一起並計算,計算規則與reduce一致,所以combiner也可以看作特殊的Reducer
7. streaming 常用配置項
- stream.map.output.field.separator // 該引數屬於streaming作業引數,設定map輸出的欄位分隔符,預設為“\t”,該分隔符只對下面的stream.num.map.output.key.fields引數生效
- stream.num.map.output.key.fields // 設定map輸出的前幾個欄位作為key,一般與第二項stream.map.output.field.separator 結合使用
- mapred.text.key.partitioner.options // 設定key內某個欄位或者某個欄位範圍用做partition
- mapred.text.key.comparator.options // 設定key中需要比較的欄位或位元組範圍
- partitioner // 主要用於對鍵值進行劃分,負責將map的輸出結果根據key進行分割。Key用於確定不同的key落到不同的reduce上,通常對key進行Hash以後對reduce取mod,該key對應的紀錄最終將根據mod值落到對應的reduce上進行處理。HashPartitioner, IndexUpdatePartitioner, KeyFieldBasedPartitioner, SleepJob,預設的為 HashPartitioner,即對key直接進行hash分到對應的reduce,具體見第6部分。更高階一點的為 KeyFieldBasedPartitioner,該partitioner可以指定key中前幾個欄位用於分割
- HashPartition 最基本的Partitioner,如果不指定Partitioner的話則預設使用該類。輸出格式為最基本的key”\t“value
- KeyFieldBasedPartitioner 可以看做HashPartitioner的擴充套件,他將原有的對單欄位Key的hash擴充套件到可以靈活地對多欄位key進行分桶並排序,對應配置引數如下:
- -partitioner org.apache.hadoop.mapred.lib.KeyFieldBasedPartitioner // 該引數表示作業啟用KeyFieldBasedParitioner
- -D map.ouput.key.field.separator // 該引數屬於KeyFieldBasedPartitioner引數,只有當啟用KeyFieldBasedParititioner時,該引數才會生效;該引數指明map輸出結果中欄位之間的分隔符(該分隔符只對下面的num.key.fields.for.partition引數生效);
- -D num.key.fields.for.partition // 該引數同樣屬於KeyFieldBasedPartitioner引數;該引數指明map輸出結果的key按上述分隔符切分後,前幾個欄位將用來做partition;該引數不能與mapred.text.key.partitioner.options共用;
- -D mapred.text.key.partitioner.options // 該引數同樣屬於KeyFieldBasedPartitioner引數; 該引數指明map輸出結果的key按上述分隔符切分後,使用哪些欄位用來做partition;該引數不能與num.key.fields.for.partition共用,一起使用則以num.key.fields.for.partition為準;
- KeyFieldBaseComparator // 可以靈活設定比較位置的高階比較器,但是它和沒有自己獨有的比較邏輯,而是使用預設Text的基於字典序或者通過-n來基於數字比較,直觀來說,partition指定key中的分割槽元素,KeyFieldBaseComparator用作指定key排序欄位以及排序規則,引數配置如下:
- -D mapred.output.key.comparator.class=org.apache.hadoop.mapred.lib.KeyFieldBasedComparator // 該引數表示作業啟用KeyFieldBasedComparator
- -D mapred.text.key.comparator.options="-k3,3 -k4nr" // 以key中第三個欄位正序,第四個欄位逆序比較排序
- stream.memory.limit // 任務記憶體限制
- mapred.reduce.tasks // 指定reducer個數
- cmdenv //傳遞給streaming命令的環境變數
- -input //HDFS目錄或檔案路徑, Mapper的輸入資料,檔案要在任務提交前手動上傳到HDFS
- -output // reducer輸出結果的HDFS存放路徑, 不能已存在,但指令碼中一定要配置,多次-input,指定多個輸入檔案
- -mapper // 可執行命令,mapper程式
- -reducer // 可執行命令, reduce程式,不需要reduce處理就不指定
- -file //本地mapper、reducer程式檔案、程式執行需要的其他檔案,將本地檔案分發給計算節點;檔案作為作業的一部分,一起被打包並提交,所有分發的檔案最終會被放置在datanode該job的同一個專屬目錄下:jobcache/job_xxx/jar
- -cacheFile //分發HDFS檔案
- -cacheArchive // 分發HDFS壓縮檔案、壓縮檔案內部具有目錄結構
- mapred.job.priority //作業優先順序
- mapred.job.map.capacity // 最多同時執行map任務數
- mapred.job.reduce.capacity //最多同時執行reduce任務數
- mapred.job.name // job name
8. key-partition 例項
- key 不等於 partition,也就是說,分桶規則跟map階段的key有可能不是一回事
- 假設,檔案A中內容如下:
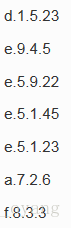
- 第一種作業方式(部分引數):
./hadoop streaming
-D stream.map.output.field.separator=.
-D stream.num.map.output.key.fields=2

只是將map的輸出結果按兩個欄位切分成了key和value;再分桶上我們可以看出,它是以前兩個欄位作為一個整體來進行分桶的,e.5與e.9沒有分在一個reduce
- 第二種作業:
./hadoop streaming
-D stream.map.output.field.separator=.
-D stream.num.map.output.key.fields=2
-D map.output.key.field.separator=.
-D num.key.fields.for.partition=1
-partitioner org.apache.hadoop.mapred.lib.KeyFieldBasedPartitioner\

這裡啟用了KeyFieldBasedPartitioner,並且制定分桶以key的第一個欄位為準;我們可以看出mapred依然採用的是前兩個欄位為key,但是在分桶上只對第一個欄位做了雜湊函式,因此這次e.5和e.9分到了一個reducer內
- 第三種作業
./hadoop streaming
-D stream.map.output.field.separator=.
-D stream.num.map.output.key.fields=3
-D map.output.key.field.separator=.
-D num.key.fields.for.partition=1
-D mapred.text.key.partitioner.options=-k2,3
-partitioner org.apache.hadoop.mapred.lib.KeyFieldBasedPartitioner這次將key的長度改成3個欄位,分桶標準也變成key的第2、3個欄位,可以看出e.5.1被分在了一起,而第三個欄位不同的e.5.9被分到了其他的reducer中
- 第四種作業
./hadoop streaming \
-partitioner org.apache.hadoop.mapred.lib.KeyFieldBasedPartitioner \
-D mapred.output.key.comparator.class=org.apache.hadoop.mapred.lib.KeyFieldBasedComparator \
-D stream.num.map.output.key.fields=4 \
-D stream.map.output.field.separator=. \
-D map.output.key.field.separator=. \
-D mapred.text.key.partitioner.options=-k1,2 \
-D mapred.text.key.comparator.options="-k3,3 -k4nr" \

這次key的長度為4,分桶標準為key的第一、二個欄位,可以看出,e.5被分到一個桶內,而輸出結果,按照key的第三個欄位的正序,第四個欄位的逆序排列輸出