
Kaggle專案案例分析 泰坦尼克號生存預測
阿新 • • 發佈:2019-01-23
 一、資料來源及說明 1.1 資料來源 來自Kaggle的非常經典資料專案 Titanic:Machine Learning1.2 資料說明 資料包含train.csv 和test.csv 兩個檔案資料集,一個訓練用,一個測試用。train文件資料是用來分析和建模,包含泰坦尼克號乘 客的各項基本資訊變數和生存情況;test資料是用來最終預測其生存情況並生成結果檔案。
一、資料來源及說明 1.1 資料來源 來自Kaggle的非常經典資料專案 Titanic:Machine Learning1.2 資料說明 資料包含train.csv 和test.csv 兩個檔案資料集,一個訓練用,一個測試用。train文件資料是用來分析和建模,包含泰坦尼克號乘 客的各項基本資訊變數和生存情況;test資料是用來最終預測其生存情況並生成結果檔案。二、分析思路 本專案主要根據train資料的分析並建立模型,預測test資料中乘客在沉船事件中的生存情況。思路如下:(1)資料整理分析(2)資料清洗,為建模做準備(如變數整合,建立新變數,填補缺失值空白值)(3)建立模型並預測,提交網站排名 三、
train<-read.csv("train.csv")
test <- read.csv("test.csv")
library('dplyr')
binddata<-bind_rows(train,test) #合併train和test資料
str(binddata)
summary(binddata)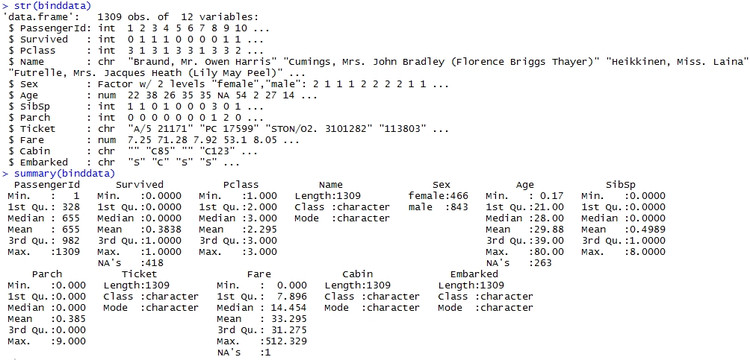
binddata$Survived <- factor(binddata$Survived) library(ggplot2) library(ggthemes) ggplot(data = binddata[1:nrow(train),],aes(x = Pclass, y = ..count.., fill=Survived)) +geom_bar(stat = "count", position='dodge') + xlab('客艙等級') + ylab('乘客數量') + ggtitle('不同客艙等級對存活率的影響') + scale_fill_manual(values = c("red","green")) +theme_economist(base_size=16)+ geom_text(stat = "count", aes(label = ..count..), position=position_dodge(width=1), vjust=-0.5)
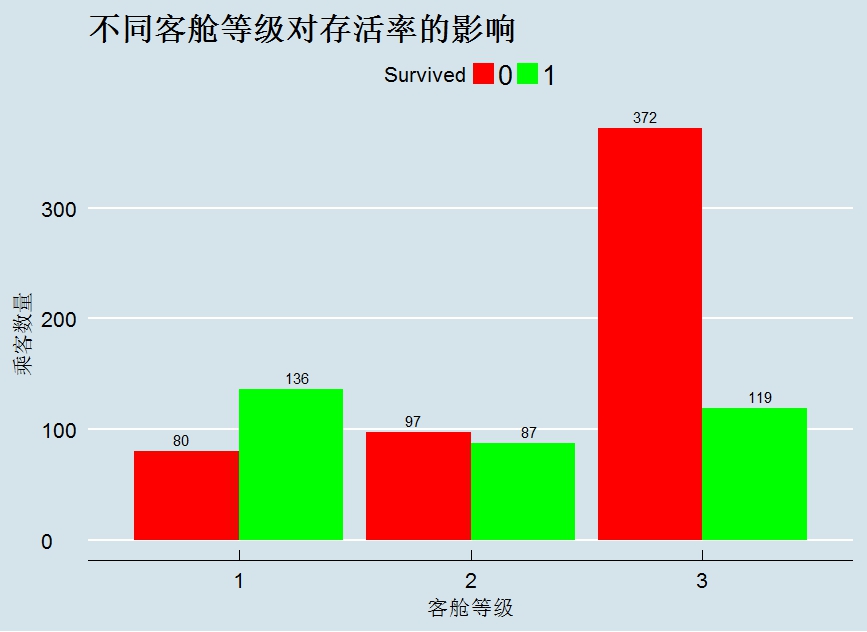 圖中可見 Pclass=1的乘客大部分倖存,Pclass=2的倖存乘客接近一半,Pclass=3的乘客不到25%。建模前,為了對自變數進行篩選,可用WOE和IV值來衡量Pclass的預測能力。從結果可以看出,Pclass的IV為0.5009497,且“Highly Predictive”。由此可以暫時將Pclass作為預測模型的特徵變數之一。
圖中可見 Pclass=1的乘客大部分倖存,Pclass=2的倖存乘客接近一半,Pclass=3的乘客不到25%。建模前,為了對自變數進行篩選,可用WOE和IV值來衡量Pclass的預測能力。從結果可以看出,Pclass的IV為0.5009497,且“Highly Predictive”。由此可以暫時將Pclass作為預測模型的特徵變數之一。library(InformationValue)
WOETable(X=factor(binddata$Pclass[1:nrow(train)]), Y=binddata$Survived[1:nrow(train)])
IV(X=factor(binddata$Pclass[1:nrow(train)]), Y=binddata$Survived[1:nrow(train)])
從結果可以看出,Pclass的IV為0.5009497,且“Highly Predictive”。由此可以暫時將Pclass作為預測模型的特徵變數之一。同理,其它變數(Name,Sex,Age,SibSp,Parch,Ticket,Fare,Cabin,Embarked)可參照以上方法,做圖表視覺化和計算出InformationValue,從而協助篩選部分變數來建立預測模型。這裡省略顯示。
四、資料清洗,變數整合4.1 通過提取變數Name,新建變數TitleName本身沒有辨識意義,但是Name中含有諸如Mr. Miss類的稱呼,將其提取出來。
binddata$Title <- gsub('(.*, )|(\\..*)', '', binddata$Name)
table(binddata$Title)
binddata$Title[binddata$Title == 'Ms'] <- 'Miss'
rare_title <- c('Dona', 'Lady', 'the Countess','Capt', 'Col', 'Don',Dr', 'Major', '
Rev', 'Sir', 'Jonkheer') #把較少的稱呼擡頭整合一起
binddata$Title[binddata$Title == 'Mlle'] <- 'Miss' #把稱呼Melle歸入Miss,下同
binddata$Title[binddata$Title == 'Ms'] <- 'Miss'
binddata$Title[binddata$Title == 'Mme'] <- 'Mrs'
binddata$Title[binddata$Title %in% rare_title] <- 'Rare Title'binddata$Fsize <- binddata$SibSp + binddata$Parch + 1 # 新建變數“Fsize”,意思是家庭規模
binddata$Surname <- sapply(binddata$Name, FUN=function(x) {strsplit(x, split='[,.]')[[1]][1]}) #從Name中提取出Surname
binddata$FamilyID <- paste(as.character(binddata$FSize), binddata$Surname, sep="") #形成新變數”FamilyID“,
binddata$FamilyID[binddata$Fsize <= 2] <- 'Small' #對”FamilyID“賦值,對於Fsize小於等於2的標記為Small
famIDs <- data.frame(table(binddata$FamilyID)) #刪除錯誤的famIDs
famIDs <- famIDs[famIDs$Freq <= 2,]
FamilyID[binddata$FamilyID %in% famIDs$Var1] <- 'Small'4.3 新建TicketCount變數,並賦值
binddatat <- binddata %>% #通過票號進行分組,儲存為單獨的資料框binddatat
group_by(Ticket) %>%
count()
table(binddatat$n)
說明1309個人中,713種票號是不重複的,132種票號出現了2次,佔264人,以此類推……
binddatat <- as.data.frame(binddatat)
binddata$TicketCount <- apply(binddata, 1, function(x)binddatat[which(binddatat['Ticket'] == x['Ticket']), 2]) #對binddata資料集的TicketCount賦值
binddata$TicketCount[binddata$TicketCount != 1] <-'share'
binddata$TicketCount[binddata$TicketCount == 1] <-'unique' #根據標識不為1的賦值為share,否則賦值為uniquecolSums(sapply(binddata,is.na))
sapply(binddata,function(x)sum(x==""))
which(is.na(binddata$Fare))
結果發現Age有263個缺失值,Fare中NA的行號是1044
binddata[1044,]$Fare <- 8.05 #通過binddata[1044,]觀察資訊,可得到他的Pclass和Embarked,彙總分析並賦值
binddata$Embarked[c(62, 830)] <- 'S' #Embarked也同樣,得到基本資訊,找到大類,彙總分析並賦值然後就是通過mice函式對變數Age進行插補
library('mice')
library('lattice')
newdata <- bind_rows(train,test)
imp <- mice(newdata[,-2],m=5,method = 'rf',maxit = 500,seed = 5514)
miceout <- complete(imp)
binddata$Age <- miceout$Age五、建立模型並預測
library(randomForest)
library('party')
library('zoo')
binddata$Age <- factor(binddata$Age) #將變數轉化為factor格式,下同
binddata$Embarked <- factor(binddata$Embarked)
binddata$Title <- factor(binddata$Title)
binddata$Fsize <- factor(binddata$Fsize)
binddata$FamilyID <- factor(binddata$FamilyID)
binddata$TicketCount <- factor(binddata$TicketCount)先把合併的資料再分開
train1 <- binddata[1:891,]
test1 <- binddata[892:1309,]然後建立隨機森林模型
model <- cforest(Survived ~ Pclass +Sex + Age + Fare + Embarked + Title + Fsize +
FamilyID + TicketCount, data = train1,controls = cforest_unbiased(ntree=2000,mtry=3))
Prediction <- predict(model, test1, OOB=TRUE, type = "response")
submit <- data.frame(PassengerId = test$PassengerId, Survived = Prediction)
write.csv(submit,file = "G:/forest.csv",row.names = FALSE)