
python利用cookie登入網站進行訪問
阿新 • • 發佈:2019-01-23
在寫爬蟲的時候遇到需要登入才能訪問的網站往往很令人頭疼,偽裝成瀏覽器訪問神馬的也許又會遇到網站採取的加密措施,不勝麻煩!然而,如果換一種思路,先用瀏覽器登入你想訪問的網站,再在瀏覽器的控制檯裡找到該網站的cookie,然後利用這個cookie進行帶cookie的訪問,無疑是短時間內解決此問題的好辦法。但是我們都知道cookie的有效期並不長,所以可能第二天你就必須重新檢視新的cookie。
下面以登入豆瓣為例。。。
- #coding=gbk
- import urllib2
- HEADERS = {"cookie": ''}#裡面寫你在www.douban.com的cookie
- url = 'http://www.douban.com/'
- req = urllib2.Request(url, headers=HEADERS)
- text = urllib2.urlopen(req).read()
- if "首頁設定".decode("gbk").encode("utf8") in text and "說句話".decode("gbk").encode("utf8") in text:
- print "登陸成功!"
- else:
- print "登入失敗!"
關於cookie怎麼檢視,請看下圖:
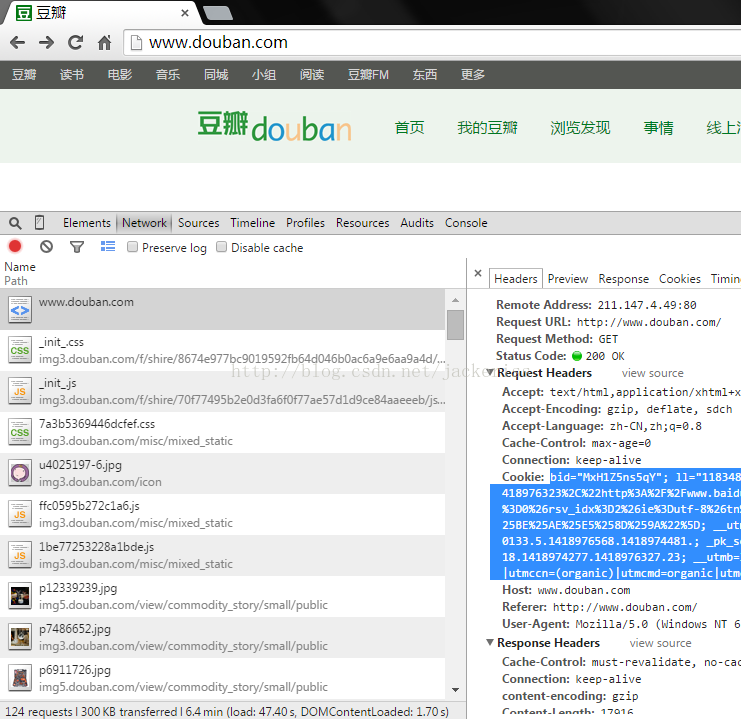
首先登入豆瓣首頁,然後按F12調出瀏覽器的控制檯,點選Network這一項。這時候你按F5重新整理一下頁面,就會發現有好多東西在傳來傳去的。到最上面找到www.douban.com這一項,會發現裡面就有cookie這一項(就是藍色的我選中的部分,這些資訊有些是隱私,絕對不能洩露),將這些複製到你的程式中即可。(我使用的是Chrome瀏覽器,其他瀏覽器檢視cookie的方式可能都大同小異)