用gensim對中文維基百科語料上的word2Vec相似度計算實驗
Word2vec 是Google在 2013年年中開源的一款將詞表徵為實數值向量的高效工具,其利用深度學習的思想,可以通過訓練,把對文字內容的處理簡化為 K 維向量空間中的向量運算,而向量空間上的相似度可以用來表示文字語義上的相似度。Word2vec輸出的詞向量可以被用來做很多 NLP相關的工作,比如聚類、找同義詞、詞性分析等等。如果換個思路,把詞當做特徵,那麼Word2vec就可以把特徵對映到 K 維向量空間,可以為文字資料尋求更加深層次的特徵表示。
Word2Vec對應的python版本是gensim(http://radimrehurek.com/gensim/)使用gensim可以來訓練LSI
Word2Vec的參考文章很多,可以查看我轉載的這篇文章,裡面的對word2Vec原理寫的很清楚。Gensim的話可以參考官網的實例,裡面的文件很全。
一、中文維基百科的Word2Vec測試
中文維基百科的資料不是很大,整個文件才1G多點
2、安裝gensim包,genism包安裝有點麻煩,因為gensim的包要依賴其他的包,對其他包的版本還有要求。直接使用python自帶的easy_install和pip install都會出現問題。我這邊是使用了Anaconda來進行安裝的。
3、資料預處理:首先將xml的wiki資料轉化成text格式,通過process_wiki.py進行處理:#!/usr/bin/env python # -*- coding: utf-8 -*- import logging import os.path import sys from gensim.corpora import WikiCorpus if __name__ == '__main__': program = os.path.basename(sys.argv[0]) logger = logging.getLogger(program) logging.basicConfig(format='%(asctime)s: %(levelname)s: %(message)s') logging.root.setLevel(level=logging.INFO) logger.info("running %s" % ' '.join(sys.argv)) # check and process input arguments if len(sys.argv) < 3: print globals()['__doc__'] % locals() sys.exit(1) inp, outp = sys.argv[1:3] space = " " i = 0 output = open(outp, 'w') wiki = WikiCorpus(inp, lemmatize=False, dictionary={}) for text in wiki.get_texts(): output.write(space.join(text) + "\n") i = i + 1 if (i % 10000 == 0): logger.info("Saved " + str(i) + " articles") output.close() logger.info("Finished Saved " + str(i) + " articles")
這裡利用了gensim裡的維基百科處理類WikiCorpus,通過get_texts將維基裡的每篇文章轉換位1行text文字,並且去掉了標點符號等內容,注意這裡“wiki = WikiCorpus(inp, lemmatize=False, dictionary={})”將lemmatize設定為False的主要目的是不使用pattern模組來進行英文單詞的詞幹化處理,無論你的電腦是否已經安裝了pattern,因為使用pattern會嚴重影響這個處理過程,變得很慢。
執行”pythonprocess_wiki.py enwiki-latest-pages-articles.xml.bz2 wiki.en.text”
結果大概有26萬多篇文章,最新的資料可能比這個更多。
4、進行中文分詞,這邊使用的是jieba的python分詞包。
#encoding=utf-8
import logging
import jieba
import sys
import os.path
reload(sys)
sys.setdefaultencoding( "utf-8" )
if __name__=='__main__':
program = os.path.basename(sys.argv[0])
logger = logging.getLogger(program)
logging.basicConfig(format='%(asctime)s: %(levelname)s: %(message)s')
logging.root.setLevel(level=logging.INFO)
logger.info("running %s" % ' '.join(sys.argv))
if len(sys.argv)<2:
print "please input input filename and output filename!"
sys.exit(1)
input_file = sys.argv[1]
output_file = sys.argv[2]
in_file=open(input_file)
out_file = open(output_file, 'w')
jieba.load_userdict("dict.txt.big.txt")
while True:
line=in_file.readline()
if line:
#print line
seg_list = jieba.cut(line)
outWrite=" ".join(seg_list)
out_file.write(outWrite)
else:
break
in_file.close()
out_file.close()
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import logging
import os.path
import sys
import multiprocessing
from gensim.corpora import WikiCorpus
from gensim.models import Word2Vec
from gensim.models.word2vec import LineSentence
if __name__ == '__main__':
program = os.path.basename(sys.argv[0])
logger = logging.getLogger(program)
logging.basicConfig(format='%(asctime)s: %(levelname)s: %(message)s')
logging.root.setLevel(level=logging.INFO)
logger.info("running %s" % ' '.join(sys.argv))
# check and process input arguments
if len(sys.argv) < 4:
print globals()['__doc__'] % locals()
sys.exit(1)
inp, outp1, outp2 = sys.argv[1:4]
model = Word2Vec(LineSentence(inp), size=400, window=5, min_count=5,
workers=multiprocessing.cpu_count())
# trim unneeded model memory = use(much) less RAM
#model.init_sims(replace=True)
model.save(outp1)
model.save_word2vec_format(outp2, binary=False)執行 “pythontrain_word2vec_model.py wiki.en.text wiki.en.text.model wiki.en.text.vector”生成最後的模型。
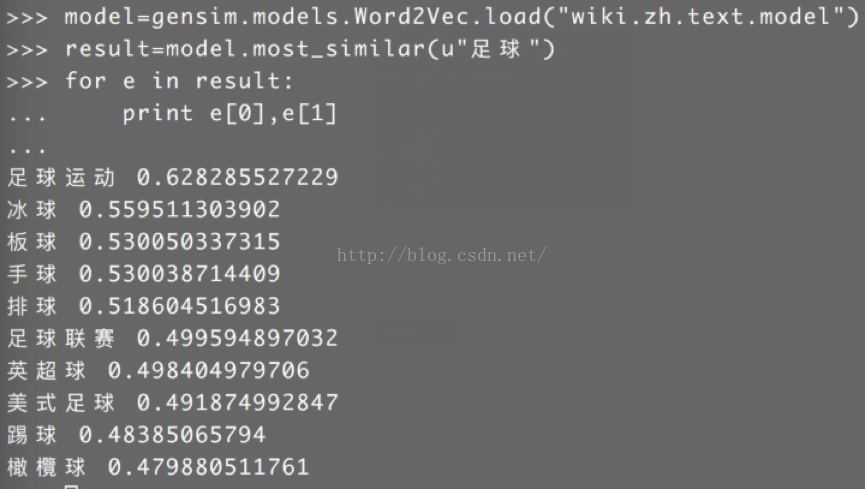
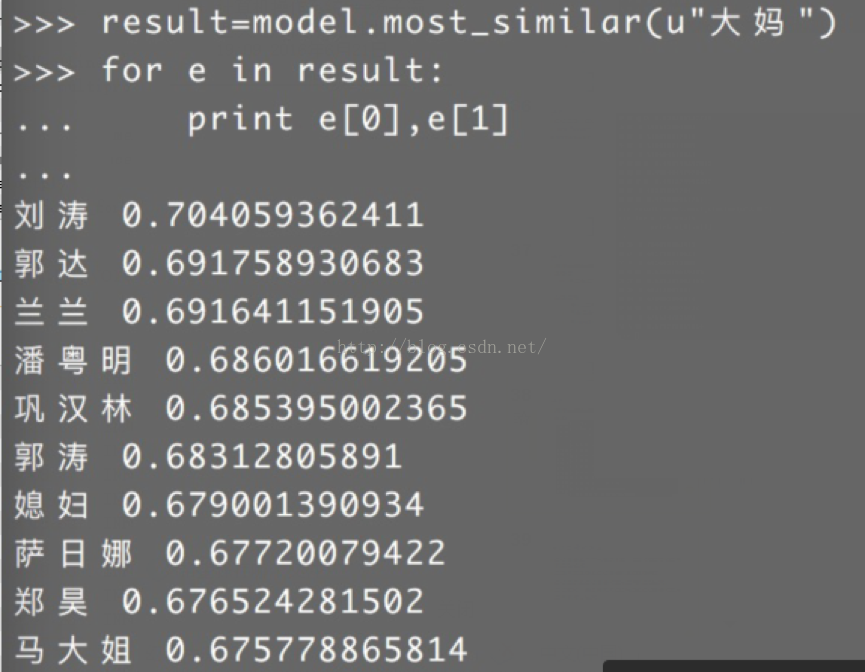
6、測試模型:
import gensim
model = gensim.models.Word2Vec.load("wiki.zh.text.model")