
JVM-HotSpot虛擬機器-編譯原理、JIT、編譯優化--一篇全瞭解
Java編譯原理
什麼是位元組碼、機器碼、原生代碼?
位元組碼是指平常所瞭解的 .class 檔案,Java 程式碼通過 javac 命令編譯成位元組碼
機器碼和原生代碼都是指機器可以直接識別執行的程式碼,也就是機器指令
位元組碼是不能直接執行的,需要經過 JVM 解釋或編譯成機器碼才能執行
此時你要問了,為什麼 Java 不直接編譯成機器碼,這樣不是更快嗎?
1. 機器碼是與平臺相關的,也就是作業系統相關,不同作業系統能識別的機器碼不同,如果編譯成機器碼那豈不是和 C、C++差不多了,不能跨平臺,Java 就沒有那響亮的口號 “一次編譯,到處執行”;
2.之所以不一次性全部編譯,是因為有一些程式碼只執行一次,沒必要編譯,直接解釋執行就可以。而那些“熱點”程式碼,反覆解釋執行肯定很慢,JVM 在執行程式的過程中不斷優化,用JIT編譯器編譯那些熱點程式碼,讓他們不用每次都逐句解釋執行;
3.還有一方面的原因是後文講解的直譯器與編譯器共存的原因。
編譯步驟
java原始碼(符合語言規範)-->javac-->.class(二進位制檔案)-->jvm-->機器語言(不同平臺不同種類)
C語言和C++語言的編譯過程是把原始碼編譯生成機器語言。這樣機器可以直接執行,所有沒有“一次編譯,到處執行”特點,而Java是通過JVM把位元組碼翻譯成機器語言,而不同平臺安裝不同版本的JVM即可編譯成對應具有對應平臺特性的機器語言。
JAVA編譯步驟:

根據完成任務不同,可以將編譯器的組成部分劃分為前端(Front End)與後端(Back End)。
前端編譯
前端編譯主要指與源語言有關但與目標機無關的部分,包括詞法分析、語法分析、語義分析與中間程式碼生成。
- 我們所熟知的
javac的編譯就是前端編譯()。除了這種以外,我們使用的很多IDE,如eclipse,idea等,都內建了前端編譯器。主要功能就是把.java程式碼轉換成.class程式碼。 - 解析與填充符號表過程
- 語法、詞法分析
- 填充符號表
- 插入式註解處理器的註解處理過程
- 分析與位元組碼生成過程
- 標註檢查
- 資料及控制流分析
- 解語法糖
- 位元組碼生成


1、詞法分析
- 定義:詞法分析是將原始碼的字元流轉變為標記(Token)集合,單個字元是程式編寫的最小元素,而標記是編譯過程的最小元素。如:關鍵字、變數名、字面量、運算子都能成為標記。
- 解析類:com.sun.tools.javac.parser.Scanner
讀取原始碼,一個位元組一個位元組的讀取,找出其中我們定義好的關鍵字(如java中的if else for等關鍵字,識別哪些if是合法的關鍵字,哪些不是),這就是詞法分析器進行詞法分析的過程,其結果是從原始碼中找出規範化的Token流。
2、語法分析
- 定義:語法分析是根據Token序列構造抽象語法樹的過程,抽象語法樹(AST)是一種用來描述程式程式碼中的一個語法結構,如包、型別、修飾符、運算子、介面、返回值等。
- 解析類:com.sun.tools.javac.parser.JavacParser
通過語法分析器對詞法分析後Token流進行語法分析,這一步檢查這些關鍵字組合再一次是否符合java語言規範(如在if後面是不是緊跟著一個布林判斷表示式),詞法分析的結果是形成一個符合java語言規範的抽象語法樹。
3、填充符號表
(1)定義:符號表(Symbol Table)是一組符號地址與符號資訊構成的表格。
(2)符號表中記錄的資訊在編譯的不同階段都要用到,如:語義分析時,符號表中的內容用於語義檢查(名字與原先的說明是否一致)與生成中間程式碼;在目的碼生成階段,對地址名進行地址分配就是根據符號表的記錄。
(3)解析類:com.sun.tools.javac.comp.Enter
4、註解處理器
(1)JDK1.5,java語言提供了註解的支援,但當時只能在執行期發揮作用。
(2)JDK 1.6,提供了插入式註解處理器的標準API在編譯期間對註解進行處理。這些註解處理器能在處理註解期
間對語法樹進行修改,所以需要回到解析以及填充符號表的過程,這稱為一個Round。
(3)處理類:com.sun.tools.javac.processing.JavacProcessingEnvironment
5、語義分析:分析對結構正確的源程式進行上下文有關性質的審查:如型別審查
通過語義分析器進行語義分析。語音分析主要是將一些難懂的、複雜的語法轉化成更加簡單的語法,結果形成最簡單的語法(如將foreach轉換成for迴圈、註解等),最後形成一個註解過後的抽象語法樹,這個語法樹更為接近目標語言的語法規則。
(1)標註檢查
檢查內容:變數使用前是否被宣告、變數與賦值之間的資料型別是否能匹配等
常量摺疊:常量相加變為一個常量
例子:int a = 1 + 2; => int a = 3;
解析類:com.sun.tools.javac.comp.Attr、com.sun.tools.javac.comp.Check
(2)資料及控制流分析
資料及控制流分析是對程式上下文邏輯更進一步的驗證
驗證內容:區域性變數在使用前是否賦值、方法的每條路徑是否有返回值、是否所有的受檢異常被正確處理。
例子:final 只在編譯期間保證變數的不變性
解析類:com.sun.tools.javac.comp.Flow
(3)解語法糖
語法糖:JVM不支援的語法,但為了讓程式設計師程式設計簡單而新增的高階語法,所以編譯過程需要將高階語法還原
為簡單的基礎語法結構。
例子:增強for迴圈 => 迭代器迴圈
解析類:com.sun.tools.javac.comp.TransTypes 、com.sun.tools.javac.comp.Lower
6、中間程式碼生成
通過位元組碼生產器將經過註解的抽象語法樹轉化成符合jvm規範的位元組碼。
該中間表示有兩個重要的性質:
- 易於生成;
- 能夠輕鬆地翻譯為目標機器上的語言。
在Java中,javac執行的結果就是得到一個位元組碼,而這個位元組碼其實就是一種中間程式碼。
著名的解語法糖操作,也是在javac中完成的。
- 前面各個步驟的資訊(語法樹、符號表)轉化為位元組碼寫入磁碟
- 少量的新增和轉換工作
- 如:字串加法 => StringBuilder的append方法;
- 如:類構造器和例項構造器的生成(順序為父類的構造器先執行)
- 關聯類:com.sun.tools.javac.jvm.Gen、com.sun.tools.javac.jvm.ClassWriter
7、常見語法糖的奧祕
(1)泛型與型別擦除
Java的泛型基於型別擦除,在編譯期間就把泛型變為原來的裸型別。
List<String> list = new ArrayList<>();
list.add("hello");
list.add("world");
System.out.println(list.get(0));
============================>
List list = new ArrayList();
list.add("hello");
list.add("world");
System.out.println((String)list.get(0));(2)自動裝箱、拆箱與遍歷迴圈
List<Integer> list2 = Arrays.asList(1,2,3,4,5,6);
int sum = 0;
for (int i : list2)
sum += i;
============================>
List list2 = Arrays.asList(new Integer[] { Integer.valueOf(1), Integer.valueOf(2),
Integer.valueOf(3), Integer.valueOf(4), Integer.valueOf(5), Integer.valueOf(6) });
int sum = 0;
for (Iterator localIterator = list2.iterator(); localIterator.hasNext(); ) {
int i = ((Integer)localIterator.next()).intValue();
sum += i;
}
// 自動裝箱 int -> Integer
1 -> Integer.valueOf(1)
// 自動拆箱 Integer -> int
Integer::intValue()
// 增強for迴圈
for(int i : list)
->
for(Iterator localIterator = list.iterator(); localIterator.hasNext(); ){
int i = localIterator.next();
}
// 自動裝箱以及自動拆箱的陷阱
Integer a = 1;
Integer b = 2;
Integer c = 3;
Integer d = 3;
Integer e = 321;
Integer f = 321;
Long g = 3L;
System.out.println(c == d); // true
System.out.println(e == f); // false,==不遇到算術運算子不自動拆箱(即兩個Integer比較)
System.out.println(c == (a + b)); // true
System.out.println(c.equals(a + b)); // true
System.out.println(g == (a + b)); // true
System.out.println(g.equals(a + b)); // false
注意:equals方法不處理資料轉換,==方法不遇到算術運算子不會自動拆箱。
Integer a = Integer.valueOf(1);
Integer b = Integer.valueOf(2);
Integer c = Integer.valueOf(3);
Integer d = Integer.valueOf(3);
Integer e = Integer.valueOf(321);
Integer f = Integer.valueOf(321);
Long g = Long.valueOf(3L);
System.out.println(c == d);
System.out.println(e == f);
System.out.println(c.intValue() == a.intValue() + b.intValue());
System.out.println(c.equals(Integer.valueOf(a.intValue() + b.intValue())));
System.out.println(g.longValue() == a.intValue() + b.intValue());
System.out.println(g.equals(Integer.valueOf(a.intValue() + b.intValue()))); // Integer 與 Long比較(3)條件編譯:com.sun.tools.javac.comp.Lower完成
if (true){
System.out.println("true");
}else{
System.out.println("false");
}
===============================>
System.out.println("true");後端編譯
後端編譯主要指與目標機有關的部分,包括程式碼優化和目的碼生成等。
這部分編譯主要是將.class檔案翻譯成機器指令的編譯過程。
JIT(just in time)
簡介
- 概述:JIT編譯期能在JVM發現熱點程式碼時,將這些熱點程式碼編譯成與本地平臺相關的機器碼,並進行各個層次
- 的優化,從而提高熱點程式碼的執行效率。
- 熱點程式碼:某個方法或程式碼塊執行頻繁。
- JIT編譯器(Just In Time Compiler):即時編譯器。
- 目的:提高熱點程式碼的執行效率。
JVM通過解釋位元組碼將其翻譯成對應的機器指令,逐條讀入,逐條解釋翻譯。經過解釋執行,其執行速度必然會比可執行的二進位制位元組碼程式慢很多。這是傳統的JVM的直譯器(Interpreter)的功能。為解決效率問題,引入了 JIT 技術。
JAVA程式還是通過直譯器進行解釋執行,當JVM發現某個方法或程式碼塊執行特別頻繁的時候,就會認為這是“熱點程式碼”(Hot Spot Code)。然後JIT會把部分“熱點程式碼”翻譯成本地機器相關的機器碼,並進行優化,然後再把翻譯後的機器碼快取起來,以備下次使用。
HotSpot虛擬機器中內建了兩個JIT編譯器:Client Complier(編譯速度)和Server Complier(編譯質量),分別用在客戶端和服務端,目前主流的HotSpot虛擬機器中預設是採用直譯器與其中一個編譯器直接配合的方式工作。
當 JVM 執行程式碼時,它並不立即開始編譯程式碼。首先,如果這段程式碼本身在將來只會被執行一次,那麼從本質上看,編譯就是在浪費精力。因為將程式碼翻譯成 java 位元組碼相對於編譯這段程式碼並執行程式碼來說,要快很多。第二個原因是最優化,當 JVM 執行某一方法或遍歷迴圈的次數越多,就會更加了解程式碼結構,那麼 JVM 在編譯程式碼的時候就做出相應的優化。
OpenJDK HotSpot VM有兩個不同的編譯器,每個都有它自己的編譯臨界值:
- 客戶端或C1編譯器,它的編譯臨界值比較低,只是1500,這有助於減少啟動時間。
- 服務端或C2編譯器,它的編譯臨界值比較高,達到了10000,這有助於針對性能關鍵的方法生成高度優化的程式碼,這些方法由應用的關鍵執行路徑來判定是否屬於效能關鍵方法。
在機器上,執行java -version命令就可以看到自己安裝的JDK中JIT是哪種模式:
無論是Client Complier還是Server Complier,直譯器與編譯器的搭配使用方式都是混合模式,即上圖中的mixed mode
HotSpot虛擬機器要使用直譯器與編譯器並存的架構?
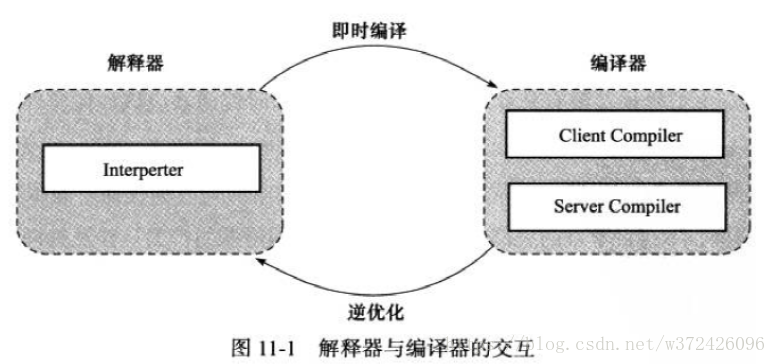
並存原因
儘管並不是所有的Java虛擬機器都採用直譯器與編譯器並存的架構,但許多主流的商用虛擬機器(如HotSpot),都同時包含直譯器和編譯器。直譯器與編譯器兩者各有優勢:當程式需要迅速啟動和執行的時候,直譯器可以首先發揮作用,省去編譯的時間,立即執行。在程式執行後,隨著時間的推移,編譯器逐漸發揮作用,把越來越多的程式碼編譯成原生代碼之後,可以獲取更高的執行效率。當程式執行環境中_記憶體資源限制較大_(如部分嵌入式系統中),可以使用直譯器執行節約記憶體,反之可以使用_編譯執行來提升效率_。此外,如果編譯後出現“罕見陷阱”,可以通過逆優化退回到解釋執行。
並存的優勢
- 程式需要迅速啟動和執行時,直譯器先發揮作用,省去編譯時間,且隨時間推移,編譯器將熱點程式碼編譯本
- 地程式碼,提高執行效率。
- 當執行環境記憶體資源限制較大(嵌入式)時,使用解釋執行節約記憶體,反之使用編譯執行提升效率。
- 直譯器能作為編譯器激進優化的逃生門,如:編譯優化出現問題,能退化為直譯器狀態執行 。
Hotspot虛擬機器內建的JIT編譯器
- C1編譯器(Client Compiler):更高的編譯速度
- C2編譯器(Server Compiler,Opto編譯器):更好的編譯質量
JVM的執行模式
- 混合模式(Mixed Mode):使用直譯器 + 其中一個JIT編譯器(-client / -server 指定使用哪個)
- 解釋模式(Interpreted Mode):只使用直譯器(-Xint 強制JVM使用解釋模式)
- 編譯模式(Compiled Mode):只使用編譯器(-Xcomp JVM優先使用編譯模式,解釋模式作為備用)
編譯層次:
- 第0層:程式解釋執行,直譯器不開啟效能監控功能,可觸發第1層編譯
- 第1層:C1編譯,將位元組碼編譯為原生代碼,進行簡單、可靠的優化,如有必要將加入效能監控邏輯
- 第2層:C2編譯,同1層優化,但啟動了一些編譯耗時較長的優化,甚至根據效能監控資訊進行不可靠的激進
- 優化
編譯的時間開銷
直譯器的執行,抽象的看是這樣的:輸入的程式碼 -> [ 直譯器 解釋執行 ] -> 執行結果
而要JIT編譯然後再執行的話,抽象的看則是:輸入的程式碼 -> [ 編譯器 編譯 ] -> 編譯後的程式碼 -> [ 執行 ] -> 執行結果
說JIT比解釋快,其實說的是“執行編譯後的程式碼”比“直譯器解釋執行”要快,並不是說“編譯”這個動作比“解釋”這個動作快。
JIT編譯再怎麼快,至少也比解釋執行一次略慢一些,而要得到最後的執行結果還得再經過一個“執行編譯後的程式碼”的過程。
所以,對“只執行一次”的程式碼而言,解釋執行其實總是比JIT編譯執行要快。
怎麼算是“只執行一次的程式碼”呢?粗略說,下面兩個條件同時滿足時就是嚴格的“只執行一次”
只被呼叫一次,例如類的構造器(class initializer,())
沒有迴圈
對只執行一次的程式碼做JIT編譯再執行,可以說是得不償失。
對只執行少量次數的程式碼,JIT編譯帶來的執行速度的提升也未必能抵消掉最初編譯帶來的開銷。
編譯的空間開銷
對一般的Java方法而言,編譯後代碼的大小相對於位元組碼的大小,膨脹比達到10x是很正常的。同上面說的時間開銷一樣,這裡的空間開銷也是,只有對執行頻繁的程式碼才值得編譯,如果把所有程式碼都編譯則會顯著增加程式碼所佔空間,導致“程式碼爆炸”。
這也就解釋了為什麼有些JVM會選擇不總是做JIT編譯,而是選擇用直譯器+JIT編譯器的混合執行引擎。
熱點檢測
編譯物件(熱點程式碼)
- 被多次呼叫的方法:整個方法為編譯物件
- 被多次執行的迴圈體(一個方法中):整個方法為編譯物件
迴圈體編譯優化發生在方法執行過程中,稱為棧上替換(On Stack Replacement,簡稱OSR編譯,機方法棧幀還在棧上,方法就被替換了)
熱點程式碼探測判定
- 基於取樣的熱點探測:週期檢查各個執行緒的棧頂,發現某個方法經常出現棧頂,即熱點方法。
- 實現簡單,高效
- 容易獲取方法呼叫關係(堆疊中展開即可)
- 但很難準備確定一個方法的熱度
- 基於計數器的熱點探測(Hotspot JVM採用):為每個方法(程式碼塊)建立計數器,統計方法的執行次數,次數超過閾值就認定為熱點方法。
- 實現複雜,每個方法維護一個計數器
- 不能直接獲取方法呼叫關係
- 但統計準確和嚴謹
基於計數器的熱點探測分類
- 方法呼叫計數器:統計方法呼叫次數
- 閾值修改:-XX:CompileThreshold
- 設定半衰週期(週期內沒有達到閾值將減半):-XX:CounterHalfLifeTime (單位 s)
- 關閉熱度衰減:-XX:-UseCounterDecay
- 回邊計數器:統計一個方法中的迴圈體程式碼執行次數,位元組碼中遇到控制流向後跳轉的執行稱為”回邊“。
- 閾值修改:-XX:BackEdgeThreshold
- 間接調整閾值: -XX:OnStackReplacePercentage
- Client模式下:方法呼叫計數器閾值 * OSR比率 / 100
- Server模式下:方法呼叫計數器閾值 * (OSR比率 - 直譯器監控比率<預設33>) / 100
處理邏輯
在HotSpot虛擬機器中使用的是第二種——基於計數器的熱點探測方法,因此它為每個方法準備了兩個計數器:方法呼叫計數器和回邊計數器。
- 方法計數器。顧名思義,就是記錄一個方法被呼叫次數的計數器。
執行過程如下:判斷是否已存在編譯版本,如已存在,則執行編譯版本;否則,方法計數器+1,判斷兩個計數器之和(注意:是方法計數器和回邊計數器的和)是否超過方法計數器閾值,超過則向編譯器提交編譯請求,然後和不超過閾值情況下的處理方式一樣,仍舊解釋執行該方法。
PS:該計數器並不是絕對次數,而是相對的執行次數,即在一段時間內的執行次數,當超過一定的時間限度,若還是沒有達到閾值,那麼它的計數器會減少一半,此過程被稱為熱度衰減。
- 回邊計數器。用於統計方法中迴圈體程式碼的執行次數,位元組碼中遇到控制流向後跳轉的指令稱為“回邊”。建立該計數器的目的就是為觸發OSR(On StackReplacement)編譯,即棧上替換。
和方法計數器執行過程不同的是:當兩個計數器之和超過閾值的時候,它向編譯器提交OSR編譯,並且調整回邊計數器值,然後仍舊以解釋方式執行下去。
PS:該計數器是絕對次數,沒有熱度衰減。
JIT編譯過程
什麼是編譯和解釋?
編譯器:把源程式的每一條語句都編譯成機器語言,並儲存成二進位制檔案,這樣執行時計算機可以直接以機器語言來執行此程式,速度很快;
直譯器:只在執行程式時,才一條一條的解釋成機器語言給計算機來執行,所以執行速度是不如編譯後的程式執行的快的;
通過javac命令將 Java 程式的原始碼編譯成 Java 位元組碼,即我們常說的 class 檔案。這是我們通常意義上理解的編譯。
位元組碼並不是機器語言,要想讓機器能夠執行,還需要把位元組碼翻譯成機器指令。這個過程是Java 虛擬機器做的,這個過程也叫編譯。是更深層次的編譯。(實際上就是解釋,引入 JIT 之後也存在編譯)
此時又有疑惑了,Java 不是解釋執行的嗎?
沒錯,Java 需要將位元組碼逐條翻譯成對應的機器指令並且執行,這就是傳統的 JVM 的直譯器的功能,正是由於直譯器逐條翻譯並執行這個過程的效率低,引入了 JIT 即時編譯技術。
必須指出的是,不管是解釋執行,還是編譯執行,最終執行的程式碼單元都是可直接在真實機器上執行的機器碼,或稱為原生代碼

分層編譯
- 通過引進分層編譯,OpenJDK HotSpot VM 使用者可以通過使用服務端編譯器改進啟動時間獲得好處。
- 當使用客戶端編譯時,程式碼在啟動期間通過客戶端編譯器予以優化,生成比解釋型程式碼更好的效能優化資訊。編譯的程式碼存在在一個稱為“程式碼快取”的快取裡。程式碼快取有固定的大小,如果滿了,JVM將停止方法編譯。
- 分層編譯可以針對每一層設定它自己的臨界值,比如-XX:Tier3MinInvocationThreshold, -XX:Tier3CompileThreshold, -XX:Tier3BackEdgeThreshold。第三層最低呼叫臨界值為100。而未分層的C1的臨界值為1500,與之對比你會發現會非常頻繁地發生分層編譯,針對客戶端編譯的方法生成了更多的效能分析資訊。於是用於分層編譯的程式碼快取必須要比用於不分層的程式碼快取大得多,所以在OpenJDK中用於分層編譯的程式碼快取預設大小為240MB,而用於不分層的程式碼快取大小預設只有48MB。
Hot Spot 編譯
- 當 JVM 執行程式碼時,它並不立即開始編譯程式碼。這主要有兩個原因:
1、JIT編譯器可以權衡程式碼的執行頻率,在java程式碼編譯為位元組碼檔案後,JIT可以將執行頻率高的位元組碼(熱點程式碼)直接編譯成及器指令並儲存供下一次使用以提高效能。
2、當 JVM 執行某一方法或遍歷迴圈的次數越多,就會更加了解程式碼結構,那麼 JVM 在編譯程式碼的時候就做出相應的優化,減少直譯器執行位元組碼檔案動態查詢的時間。
例子:equals() 這個方法存在於每一個 Java Object 中而且經常被覆寫。當直譯器遇到 b = obj1.equals(obj2) 這樣一句程式碼,它則會查詢 obj1 的型別從而得知到底執行哪一個 equals() 方法。
後臺執行編譯優化過程(-XX:BackgroudCompilation設定來禁止後臺編譯)
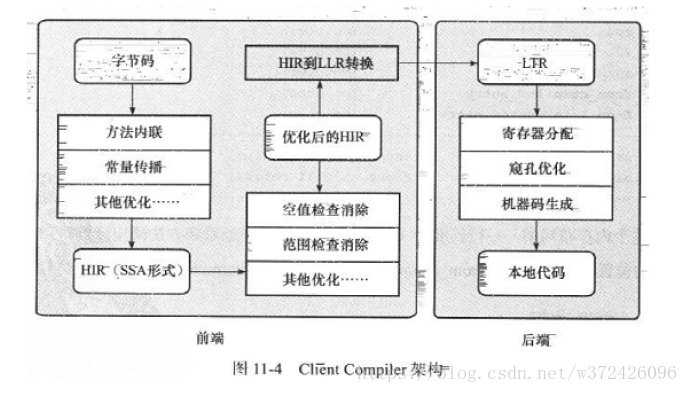
(1)一個平臺獨立的前端將位元組碼構造成一種高階中間程式碼(HIR,High Level Intermediate Representation)表示。HIR使用靜態單分配的形式代表程式碼值,使得HIR的構造過程中和之後進行優化動作更容易實現。在此之前會進行基礎優化,如:方法內聯、常量傳播等。
(2)一個平臺相關的後端從HIR中產生低階中間程式碼(LIR)表示,而在此之前進行HIR上的優化,如:空值檢查、範圍檢查消除等
(3)平臺相關的後端使用線性掃描演算法在LIR上分配暫存器,並在LIR上做窺孔優化,產生機器程式碼。
初級調優:客戶模式或伺服器模式
- JIT編譯器在執行程式的時候有兩種編譯模式,在執行時會使用其中一種以達到最優效能。
1、Server模式:
啟動時,速度較慢,但是一旦執行起來後,效能將會有很大的提升。使用的是一個代號為 C2 的編譯器。
2、Client模式:
使用的是一個代號為 C1 的輕量級編譯器。
3、C2 比 C1 編譯器編譯的相對徹底,服務起來之後,效能更高。通過 java -version 命令列可以直接檢視當前系統使用的編譯模式。
中級編譯器調優
- 優化程式碼快取
當 JVM 編譯程式碼時,它會將彙編指令集儲存在程式碼快取。程式碼快取具有固定的大小,並且一旦它被填滿,JVM 則不能再編譯更多的程式碼。
1、通過 –XX:ReservedCodeCacheSize=Nflag(N 就是之前提到的預設大小)來最大化程式碼快取大小。程式碼快取的管理類似於 JVM 中的記憶體管理:有一個初始大小(用-XX:InitialCodeCacheSize=N 來宣告)。程式碼快取的大小從初始大小開始,隨著快取被填滿而逐漸擴大。重定義程式碼快取的大小並不會真正影響效能。
2、程式碼快取並不是無限的,但是為程式碼快取設定一個很大的值並不會對應用程式本身造成影響,應用程式並不會記憶體溢位,這些額外的記憶體預定會被作業系統所接受的。 - 編譯閾值
在 JVM 中,編譯是基於兩個計數器的:一個是方法被呼叫的次數,另一個是方法中迴圈被回彈執行的次數。當 JVM 執行一個 Java 方法,它會檢查這兩個計數器的總和以決定這個方法是否有資格被編譯。
1、當方法裡有一個很長的迴圈或者是一個永遠都不會退出並提供了所有邏輯的程式,JVM會在每執行完一次迴圈,分支計數器都會自增和自檢。如果分支計數器計數超出其自身閾值,那麼這個迴圈將具有被編譯資格。
2、標準編譯是被-XX:CompileThreshold=Nflag 的值所觸發。Client 編譯器模式下,N 預設的值 1500,而 Server 編譯器模式下,N 預設的值則是 10000。改變 CompileThreshold 標誌的值將會使編譯器相對正常情況下提前(或推遲)編譯程式碼。 - 檢查編譯過程
1、啟用PrintCompilation,每次一個方法(或迴圈)被編譯,JVM 都會打印出剛剛編譯過的相關資訊。
2、用 jstat 命令檢查編譯,Jstat 有兩個選項可以提供編譯器資訊。其中,-compile 選項提供總共有多少方法被編譯的總結資訊(下面 6006 是要被檢查的程式的程序 ID): 程序詳情%jstat-compiler6006- CompiledFailedInvalidTimeFailedTypeFailedMethod
206 0 0 1.970
高階編譯器調優
當一個方法擁有編譯資格時,它就會排隊並等待編譯。這個佇列是由一個或很多個後臺執行緒組成。編譯是一個非同步的過程。並且這些佇列並不會嚴格的遵守先進先出原則:哪一個方法的呼叫計數器計數更高,哪一個就擁有優先權,這種優先權順序保證最重要的程式碼被優先編譯。
編譯優化
JIT除了具有快取的功能外,還會對程式碼做各種優化,例如:逃逸分析、鎖消除、鎖膨脹、方法內聯、資料邊界檢查、空值檢查消除、型別檢測消除、公共子表示式消除等。
優化技術概述
// 優化前
static class B{
int value;
final int get(){
return value;
}
}
public void foo(){
y = b.get();
// ...do stuff
z = b.get();
sum = y + z;
}
// 內聯優化後
public void foo(){
y = b.value;
// ...do stuff
z = b.value;
sum = y + z;
}
// 冗餘訪問消除或公共子表示式消除後
public void foo(){
y = b.value;
// ...do stuff
z = y;
sum = y + z;
}
// 複寫傳播後
public void foo(){
y = b.value;
// ...do stuff
y = y;
sum = y + y;
}
// 無用程式碼消除後
public void foo(){
y = b.value;
// ...do stuff
sum = y + y;
}逃逸分析
基本行為:分析物件的作用域
- 方法逃逸:當一個物件在方法裡面被定義後,它可能被外部方法所引用。如:作為呼叫引數傳遞到其他方法中。
- 執行緒逃逸:當一個物件在方法裡面被定義後,它可能被外部執行緒訪問到。如:類變數或可被訪問到例項變數
根據逃逸分析證明一個物件不會逃逸到方法或執行緒中,則進行高效的優化
- 棧上分配:JVM中,物件一般在堆中分配,堆是執行緒共享的,進行垃圾回收和整理記憶體都是消耗時間的。所有確定一個物件不會逃逸時,讓物件從棧上分配記憶體可以緩解垃圾回收的壓力。
- 同步消除:如果確定一個變數不會逃逸出執行緒,則消除掉變數的同步措施。
- 標量替換:聚合量 => 拆開 => 成員變數恢復為原始變數 => 標量。
- 標量是一個數據已經無法再分解成更小的資料,JVM中的原始資料型別(int、long等數值型別以及reference型別等)。反之為聚合量,如Java物件。
- 如果物件不會逃逸,則不建立該物件。方法執行時直接建立若干個相關的變數來替代。並且物件拆分後,物件的成員變數在棧上分配和讀寫,為進一步優化提供條件。
逃逸分析(Escape Analysis)是一種可以有效減少Java 程式中同步負載和記憶體堆分配壓力的跨函式全域性資料流分析演算法。通過逃逸分析,Java Hotspot編譯器能夠分析出一個新的物件的引用的使用範圍從而決定是否要將這個物件分配到堆上。
逃逸分析的基本行為就是分析物件動態作用域:當一個物件在方法中被定義後,它可能被外部方法所引用,這種行為被稱為方法逃逸。甚至還可能被外部執行緒訪問,這種行為被稱為執行緒逃逸。
public static StringBuffer craeteStringBuffer(String s1, String
StringBuffer sb = new StringBuffer();
sb.append(s1);
sb.append(s2);
return sb;
}StringBuffer sb是一個方法內部變數,上述程式碼中直接將sb返回,這樣這個StringBuffer有可能被其他方法所改變,這樣它的作用域就不只是在方法內部,雖然它是一個區域性變數,稱其逃逸到了方法外部
上述程式碼如果想要StringBuffer sb不逃出方法,可以這樣寫:
public static String createStringBuffer(String s1, String s2) {
StringBuffer sb = new StringBuffer();
sb.append(s1);
sb.append(s2);
return sb.toString();
}使用逃逸分析,編譯器可以對程式碼做如下優化:
同步省略。
如果一個物件被發現只能從一個執行緒被訪問到,那麼對於這個物件的操作可以不考慮同步。
將堆分配轉化為棧分配。
如果一個物件在子程式中被分配,要使指向該物件的指標永遠不會逃逸,物件可能是棧分配的候選,而不是堆分配。
分離物件或標量替換。
有的物件可能不需要作為一個連續的記憶體結構存在也可以被訪問到,那麼物件的部分(或全部)可以不儲存在記憶體,而是儲存在CPU暫存器中。
在Java程式碼執行時,通過JVM引數可指定是否開啟逃逸分析, -XX:+DoEscapeAnalysis : 表示開啟逃逸分析 -XX:-DoEscapeAnalysis : 表示關閉逃逸分析 從jdk 1.7開始已經預設開始逃逸分析,如需關閉,需要指定-XX:-DoEscapeAnalysis
物件的棧上記憶體分配
在一般情況下,物件和陣列元素的記憶體分配是在堆記憶體上進行的。但是隨著JIT編譯器的日漸成熟,很多優化使這種分配策略並不絕對。JIT編譯器就可以在編譯期間根據逃逸分析的結果,來決定是否可以將物件的記憶體分配從堆轉化為棧。
public static void main(String[] args) {
long a1 = System.currentTimeMillis();
for (int i = 0; i < 1000000; i++) {
alloc();
}
// 檢視執行時間
long a2 = System.currentTimeMillis();
System.out.println("cost " + (a2 - a1) + " ms");
// 為了方便檢視堆記憶體中物件個數,執行緒sleep
try {
Thread.sleep(100000);
} catch (InterruptedException e1) {
e1.printStackTrace();
}
}
private static void alloc() {
User user = new User();
}
static class User {
}其實程式碼內容很簡單,就是使用for迴圈,在程式碼中建立100萬個User物件。
我們在alloc方法中定義了User物件,但是並沒有在方法外部引用他。也就是說,這個物件並不會逃逸到alloc外部。經過JIT的逃逸分析之後,就可以對其記憶體分配進行優化。
我們指定以下JVM引數並執行:
-Xmx4G -Xms4G -XX:-DoEscapeAnalysis -XX:+PrintGCDetails -XX:+HeapDumpOnOutOfMemoryError
在程式打印出 cost XX ms 後,程式碼執行結束之前,我們使用[jmap]命令,來檢視下當前堆記憶體中有多少個User物件:
➜ ~ jps
2809 StackAllocTest
2810 Jps
➜ ~ jmap -histo 2809
num #instances #bytes class name
----------------------------------------------
1: 524 87282184 [I
2: 1000000 16000000 StackAllocTest$User
3: 6806 2093136 [B
4: 8006 1320872 [C
5: 4188 100512 java.lang.String
6: 581 66304 java.lang.Class從上面的jmap執行結果中我們可以看到,堆中共建立了100萬個StackAllocTest$User例項。
在關閉逃避分析的情況下(-XX:-DoEscapeAnalysis),雖然在alloc方法中建立的User物件並沒有逃逸到方法外部,但是還是被分配在堆記憶體中。也就說,如果沒有JIT編譯器優化,沒有逃逸分析技術,正常情況下就應該是這樣的。即所有物件都分配到堆記憶體中。
接下來,我們開啟逃逸分析,再來執行下以上程式碼。再來看看堆記憶體中有多少個User物件
➜ ~ jps
709
2858 Launcher
2859 StackAllocTest
2860 Jps
➜ ~ jmap -histo 2859
num #instances #bytes class name
----------------------------------------------
1: 524 101944280 [I
2: 6806 2093136 [B
3: 83619 1337904 StackAllocTest$User
4: 8006 1320872 [C
5: 4188 100512 java.lang.String
6: 581 66304 java.lang.Class從以上列印結果中可以發現,開啟了逃逸分析之後(-XX:+DoEscapeAnalysis),在堆記憶體中只有8萬多個StackAllocTest$User物件。也就是說在經過JIT優化之後,堆記憶體中分配的物件數量,從100萬降到了8萬。
除了以上通過jmap驗證物件個數的方法以外,還可以嘗試將堆記憶體調小,然後執行以上程式碼,根據GC的次數來分析,也能發現,開啟了逃逸分析之後,在執行期間,GC次數會明顯減少。正是因為很多堆上分配被優化成了棧上分配,所以GC次數有了明顯的減少。
鎖消除
通過對執行上下文的掃描,去除不可能存在共享資源競爭的鎖,通過鎖消除,可以節省毫無意義的請求鎖時間。
package com.winwill.lock;
public class TestLockEliminate {
public static String getString(String s1, String s2) {
StringBuffer sb = new StringBuffer();
sb.append(s1);
sb.append(s2);
return sb.toString();
}
public static void main(String[] args) {
long tsStart = System.currentTimeMillis();
for (int i = 0; i < 1000000; i++) {
getString("TestLockEliminate ", "Suffix");
}
System.out.println("一共耗費:" + (System.currentTimeMillis() - tsStart) + " ms");
}
}getString()方法中的StringBuffer數以函式內部的區域性變數,作用於方法內部,不可能逃逸出該方法,因此他就不可能被多個執行緒同時訪問,也就沒有資源的競爭,但是StringBuffer的append操作卻需要執行同步操作:
@Override
public synchronized StringBuffer append(String str) {
toStringCache = null;
super.append(str);
return this;
}逃逸分析和鎖消除分別可以使用引數-XX:+DoEscapeAnalysis和-XX:+EliminateLocks(鎖消除必須在-server模式下)開啟。使用如下引數執行上面的程式:
-XX:+DoEscapeAnalysis -XX:-EliminateLocks
結果:
一共耗費:233 ms
使用如下命令執行程式:
-XX:+DoEscapeAnalysis -XX:+EliminateLocks
結果:
一共耗費:192 ms
由上面的例子可以看出,關閉了鎖消除之後,StringBuffer每次append都會進行鎖的申請,浪費了不必要的時間,開啟鎖消除之後效能得到了提高。
公共子表示式消除
如果一個表示式E已經計算過了,並且從先前的計算到現在E中所有變數的值都沒有發生變化,那麼E的這次出現就成為了公共子表示式。 對於這種表示式,沒有必要花時間再對它進行計算,只需要直接用前面計算過的表示式結果代替E就可以了。
// 未優化前
int d = (c * b) * 12 + a + (a + b + c);
// 公共子表示式消除後
int E = c * b;
int d = E * 12 + a + (E + a);
// 代數化簡後
int d = 13 * E + 2 * a;方法內聯
該方法是針對Client而言的,方法呼叫本身是有代價的,要從常量池找到方法地址,然後儲存當前棧幀狀態,壓入新棧幀啟動呼叫過程,呼叫完彈出,並恢復呼叫者棧幀。而在執行期,如果方法很頻繁的執行,就會執行期把方法內聯到呼叫者方法內部,減少頻繁呼叫的開銷。-XX:+PringInlining來檢視方法內聯資訊,-XX:MaxInlineSize=35控制編譯後文件大小。
- 優點
- 去除呼叫方法的成本(如建立棧幀)
- 為其他優化建立基礎
- 涉及技術:用於解決多型特性。
- 型別繼承關係分析(CHA,Class Hierarchy Analysis)技術:用於確定目前的載入類中,某個介面是否有多個實現,某個類是否有子類和子類是否抽象等。
- 內聯快取:在未發生方法呼叫前,內聯快取為空,第一次呼叫後,快取下方法接收者的版本資訊,並且每次進行方法呼叫時都比較接收者版本,如果每次呼叫方法接收者版本一樣,那麼內聯快取可以繼續用。但發現不一樣時,即發生了虛擬函式的多型特性時,取消內聯,查詢虛方法表進行方法分派。
// 優化前
public static void foo(Object obj){
if(obj != null){
Sout("do something");
}
}
public static void testInline(String[] args){
Object obj = null;
foo(obj);
}
// 優化後
public static void testInline(String[] args){
Object obj = null;
if(obj != null){
Sout("do something");
}
}資料邊界檢查
jvm在陣列訪問過程中會檢查訪問的下標是否越界,這本來是一個為了安全性提供的功能,但是像下邊這段程式碼,在陣列訪問過程中,每次都去校驗,效能損耗也是很大的。jvm在執行期做了優化,只用校驗用來訪問陣列的起始下標在0到陣列最大長度-1之內那麼整個迴圈中就可以把陣列的上下界檢查消除掉,這可以節省很多次的條件判斷操作。通過資料流分析實現。
int [] arrs = new int[10000];
for(int i = 0;i < 10000;i++){
arrs[i] = i;
}Java即時編譯與C/C++編譯對比
Java的劣勢:
- JIT即時編譯器執行佔用使用者執行時間
- Java語言時動態的型別安全語言,JVM頻繁進行動態檢查,如:例項方法訪問時檢查空指標、陣列元素訪問檢查上下界、型別轉換時檢查繼承關係
- Java使用虛方法頻率高於C/C++,即多型選擇頻率大於C/C++。
- Java是可以動態拓展的語言,執行時載入新的類可能改變程式型別的繼承關係,即編譯器需要時刻注意型別變化並在執行時撤銷或重新進行一些優化。
- Java物件在堆上分配,垃圾回收比C/C++語言由使用者管理開銷大。
Java的優勢:
- 開發效率高
- C/C++編譯器屬於靜態優化,不能在執行期間進行優化。如:
- 呼叫頻率預測
- 分支頻率預測
- 裁剪未被選擇的