
java白開水之 —— 執行緒池的一點理解
目錄
1、前面
2、java執行緒池
3、c++執行緒池
4、區別
5、寫一個
6、使用
7、其它
內容
1、前面
執行緒池主要用於減少應用程式執行緒的數量並提供工作執行緒的管理。應用程式可以排隊工作項,將工作與可執行的控制代碼關聯起來,根據定時器自動排隊,並與I / O繫結。像 Android裡面就很多地方用到了執行緒池,如 AsyncTask 等等。
說到執行緒池,就先說下享元模式。
享元模式
享元模式:一組物件的集合,對於全域性的物件建立,通過物件共享池的方式減少物件的建立
單例模式:保證一個類只有一個物件
和單例模式區別:享元模式並不是為了提供唯一的物件訪問
但兩者都是為了減少記憶體消耗,提升效能
java 和 android 中用到享元模式的例子有以下等等:
a、android 系統 drawable 全域性快取
在 android.content.res 包 的 ResourcesImpl.java 中,如下
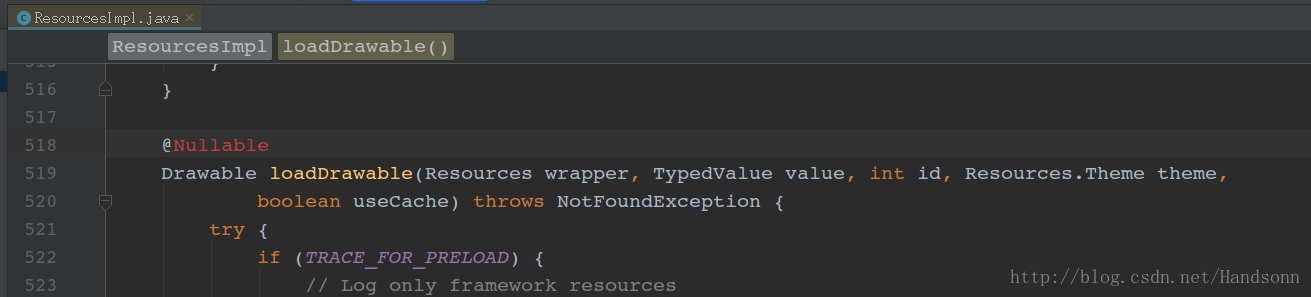
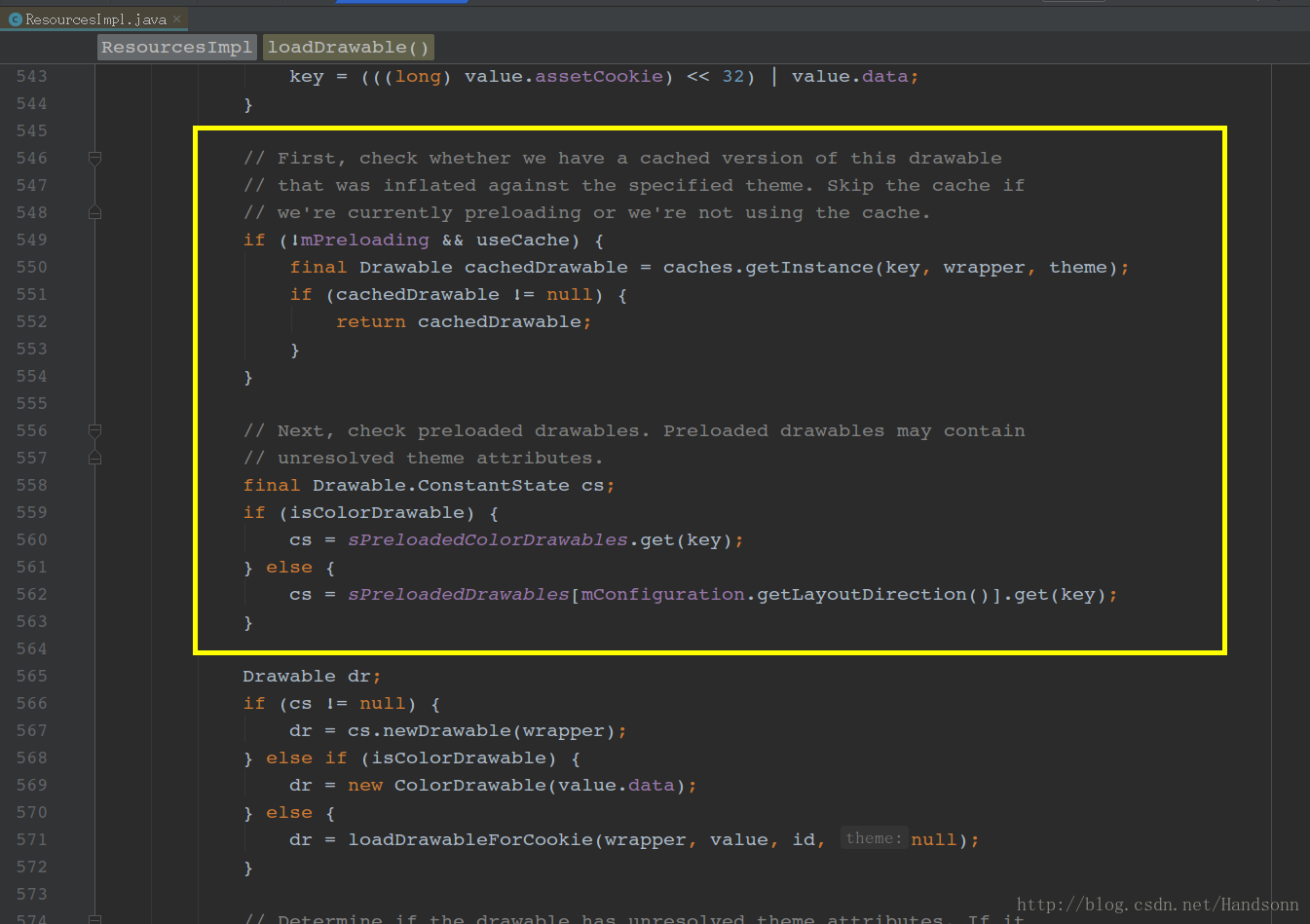
可以看到,系統有一份全域性的快取 sPreloadedDrawables ,每次獲取 drawable 時,系統會從快取中取出這個 bitmap 然後構造 drawable 。
( pS: 這裡也有一些坑,如果我們使用這個獲取複用的 bitmap ,執行 recycle 之類的操作,就會報錯 “trying to use a recycled bitmap android.graphics.Bitmap”, 在之前 使用過 Glide 處理大頭像的過程中也遇到過這種情況,具體解決方法是 :忽略 Glide 的快取
b、String字串常量池
常量池是不同於堆和棧的獨立記憶體,常量池中最多隻有一份相同的字串物件
c、資料型別快取
Integer : -128 到 127
Boolean:全部快取
Byte:全部快取
Character : <= 127
Short : -128 到 127
Long : -128 到 127
d、rxjava的Schedulers
該執行緒池提供了多種執行緒 Schedulers.io() 、 Schedulers.computation() 、 Schedulers.newThread() 等
e、rxjava的zip操作符
f、IPC裡面的Binder連線池
具體可以參考 《Android開發藝術探索》 一書介紹
g、資料庫連線池
。。。
另外,執行緒池還涉及到了 生產者-消費者 模式等等,這裡就不贅述。
2、java執行緒池
我的是 JDK 1.8 的版本
1)、JDK1.7 以前常用這4種
a、newSingleThreadExecutor
b、newFixedThreadPool
c、newCachedThreadPool
d、newScheduledThreadPool
對於以上四種,
a、b、c 內部都呼叫了 new ThreadPoolExecutor()
d 內部呼叫了 new ScheduledThreadPoolExecutor(),而 ScheduledThreadPoolExecutor() 是 ThreadPoolExecutor() 的子類
所以只需看看 ThreadPoolExecutor()

具體的引數說明在文件裡註釋有解釋 :
a、corePoolSize: 核心執行緒數,預設情況下,核心執行緒會一直線上程池中存活,即使處於閒置狀態。如果將 ThreadPoolExecutor 的 allowCoreThreadTimeOut 設定為 true,那麼閒置的核心新城在等待心任務到來是也會有超時策略,具體時間由keepalivetime 決定。
b、maximumPoolSize:執行緒池所能容納的最大執行緒數,當活動執行緒超過到達這個數值後,後續的新任務將會被阻塞
c、keepAliveTime: 非核心執行緒超時時長,超過這個間隔非核心執行緒就會被回收
d、unit: 用於指定 keepAliveTime 的時間單位,這是一個列舉
e、workQueue: 通過 execute 提交的runnable 會儲存在這裡
f、handler:
關於 handler 有 四種 飽和策略:預設是AbortPolicy,會直接丟擲 RejectedExecutionException

ThreadPoolExecutor.AbortPolicy: 丟棄任務並丟擲RejectedExecutionException異常。
ThreadPoolExecutor.DiscardPolicy:也是丟棄任務,但是不丟擲異常。
ThreadPoolExecutor.DiscardOldestPolicy:丟棄佇列最前面的任務,然後重新嘗試執行任務(重複此過程)
ThreadPoolExecutor.CallerRunsPolicy:由呼叫執行緒處理該任務
關於這四種常用的執行緒池使用的佇列
newFixedThreadPool 如下圖:

newSingleThreadExecutor 如下圖:

newCachedThreadPool 如下圖:

newScheduledThreadPool 如下圖:
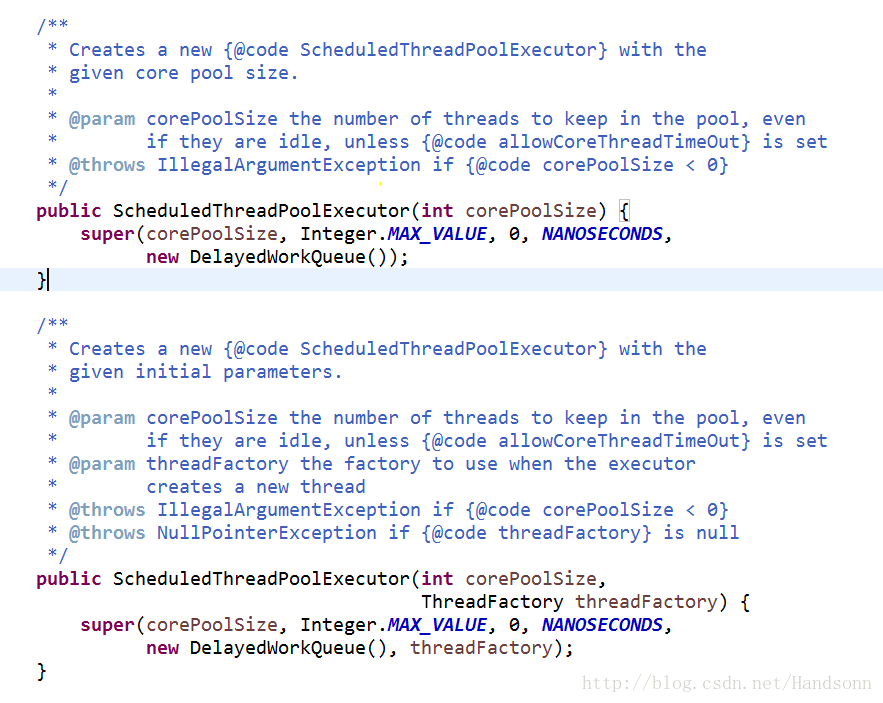
可以看到
a、newSingleThreadExecutor 和 newFixedThreadPool 使用的都是 LinkedBlockingQueue,連結串列佇列,通過 Node 節點構造連結串列,具體可以看程式碼實現,( HashMap 中也是用 Node 節點構造連結串列 )

b、newCachedThreadPool 使用的是 SynchronousQueue
這是一個同步佇列,佇列的長度永遠為0,每個插入操作必須等待另一個相應的刪除操作執行緒,它不會儲存提交的任務,而是將直接新建一個執行緒來執行新來的任務。
如下圖:
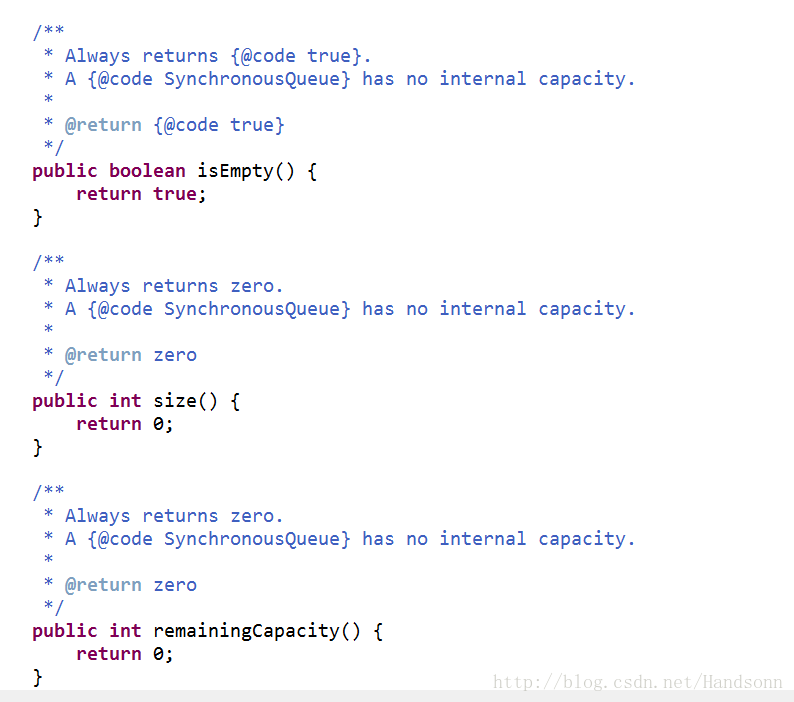
更多可以看程式碼具體實現
同步佇列非常適合於切換設計,為了交付一些資訊,事件或任務,在一個執行緒中執行的物件必須與在另一個執行緒中執行的物件同步。
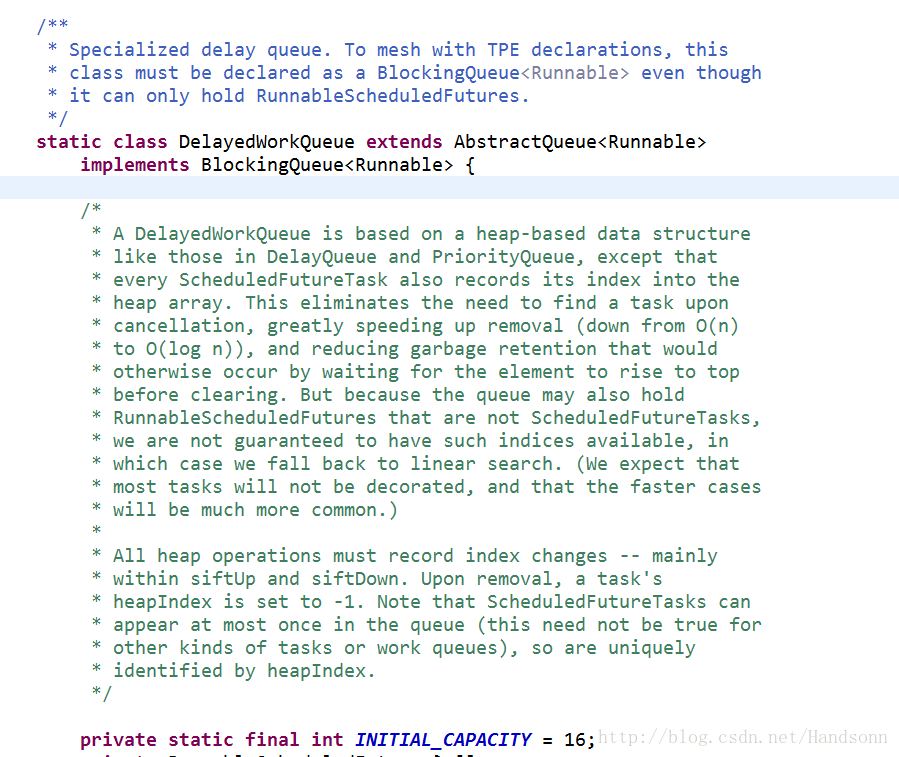
c、newScheduledThreadPool 使用的是 DelayedWorkQueue
看英文意思就是延時的佇列,初始大小是16
關於 LinkedBlockingQueue ,與之對應的還有一個 ArrayBlockingQueue,後者是定長的,在一些情況下使用 ArrayBlockingQueue 比較好,個人理解:如有一個場景,假如伺服器出問題,從資料庫查詢的資料需要通過執行緒池的 LinkedBlockingQueue,而這個時候出問題了導致阻塞,那麼新來的任務就會由於阻塞讓 LinkedBlockingQueue 無限增加,最後都有可能記憶體溢位,影響系統性能,進而影響系統使用。
2)、JDK 1.7 添加了 ForkJoinPool (PS:newWorkStealingPool 內部也是呼叫了 ForkJoinPool)
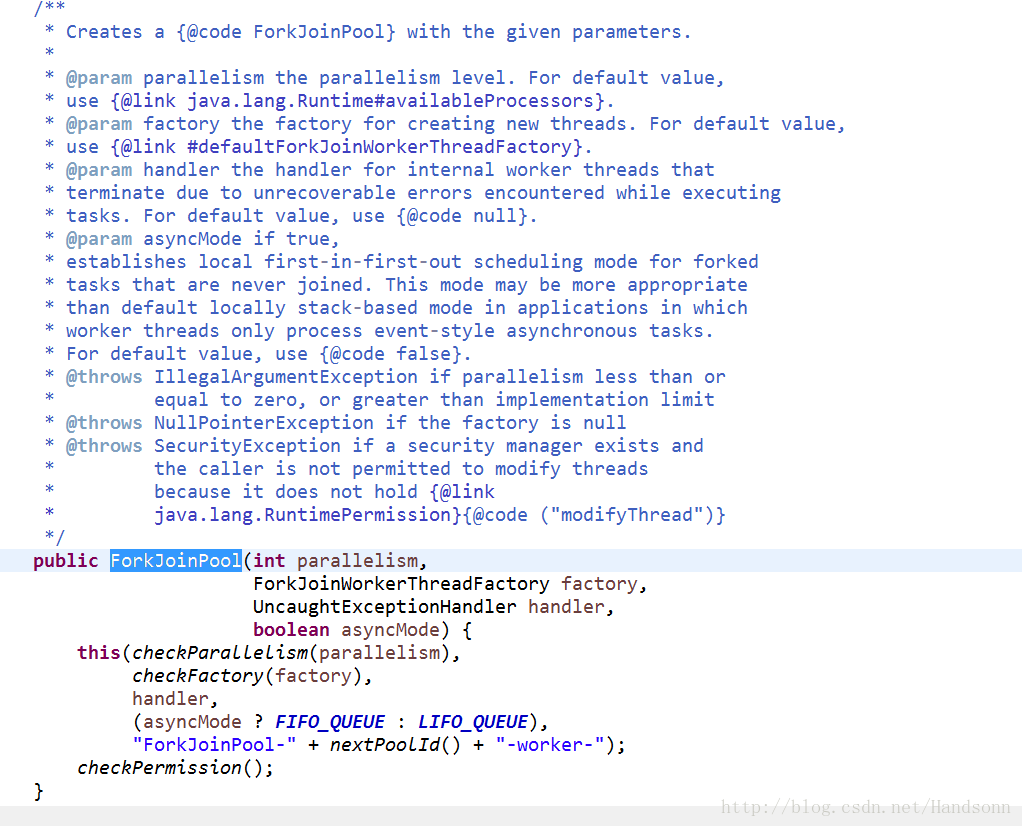
而 Java 8 為ForkJoinPool添加了一個通用執行緒池 CommomPool,具體可以看程式碼搜尋,這個執行緒池用來處理那些沒有被顯式提交到任何執行緒池的任務,它是ForkJoinPool中一個靜態元素,它擁有的預設執行緒數量等於執行計算機上的處理器數量。
ForkJoinPool 使用了 一種任務竊取演算法 ( Work-Stealing Algorithm ) ,這是一種有效的負載均衡排程策略,在平行計算中的一種排程演算法,當一個任務佇列執行完任務處於空閒時,就會從還沒執行完任務的任務佇列中“竊取”任務來執行,
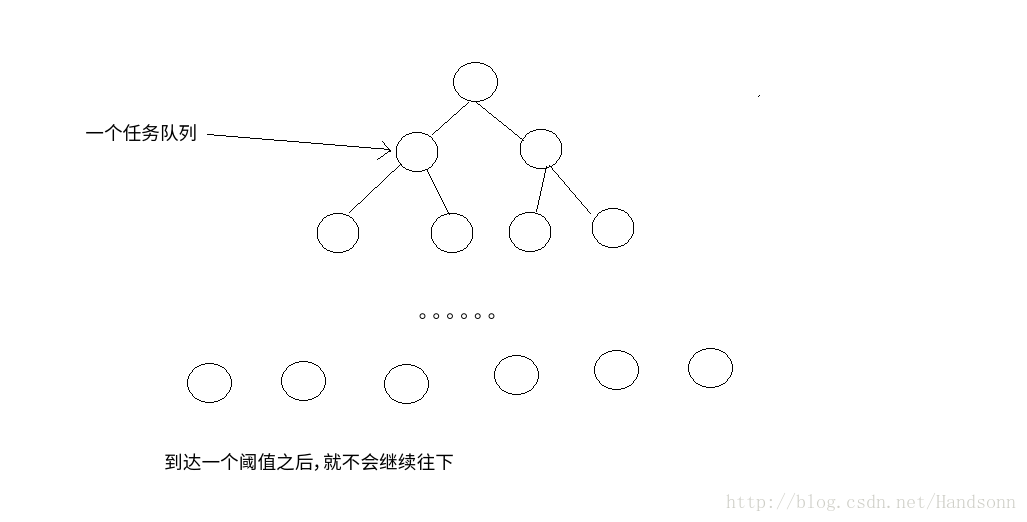
ForJoinPool 是根據 分治法 的思想來進行任務分配,如 有 100萬個任務,會被分為多個子任務,反覆遞迴,一直到一個閾值就會終止,因此,很重要的一點,這個閾值的取值會影響該執行緒池的執行效能 。
而關於任務的分發基本是“揹包問題”,每個佇列應該採取相同的時間量
比如有10個任務,每個任務時間長度不同,那麼需要類似揹包問題一樣,通過時間量來進行分配,而不是簡單的進行任務個數的平分。
俺們畫個二叉樹的圖應該可以看出來:
ForkJoinPool 預設的執行緒數是處理器的數量 Runtime.getRuntime().availableProcessors(),如下圖

在ForkJoinPool的執行過程中,會建立大量的子任務。而當它們執行完畢之後,會被垃圾回收,ThreadPoolExecutor則不會建立任何的子任務,因此不會導致任何的GC操作。所以在 gc 方面的時間也是需要考慮的,這個和 閾值的選取也有關。
另外,ForkJoinTask 提供了兩個介面:
a、RecursiveAction 無返回值。
b、RecursiveTask 有返回值。
ForkJoinPool 由ForkJoinTask陣列和ForkJoinWorkerThread陣列組成,ForkJoinTask陣列負責存放程式提交給ForkJoinPool
的任務,而ForkJoinWorkerThread陣列負責執行這些任務。
更多具體說明可以參考 ForkJoinTask 類裡面的呼叫和註釋
ForkJoinPool 使用可以參考其它程式碼,例如,我們要兩個數相加,可以一直分割成若干個小任務進行相加等等:
ForkJoinPool 類中注意的幾個 單詞:
1、WorkQueues
2、Management
3、Joining Tasks
4、Common Pool
對於 java 執行緒池,還有兩個可以注意的單詞:
workercount

state

這裡解釋了各種情況下對應的 runState 。執行緒池的 runState 是 volitale 的,這個可以保證可見性,即保證修改的值會立即被更新到主存,當有其他執行緒需要讀取時,它會去記憶體中讀取新值。關於可見性,可以與 記憶體模型、原子性、有序性、happens-before原則 進行比較理解
執行緒池調整:
關於執行緒池容量的調整可以通過 setCorePoolSize 和 setMaximumPoolSize 來進行操作。
3、windows/c++執行緒池
c++ 11 的標準庫並沒有自帶執行緒池
windows 提供了一個執行緒池機制,語法是通過 c++ 呼叫,有如以下 API:
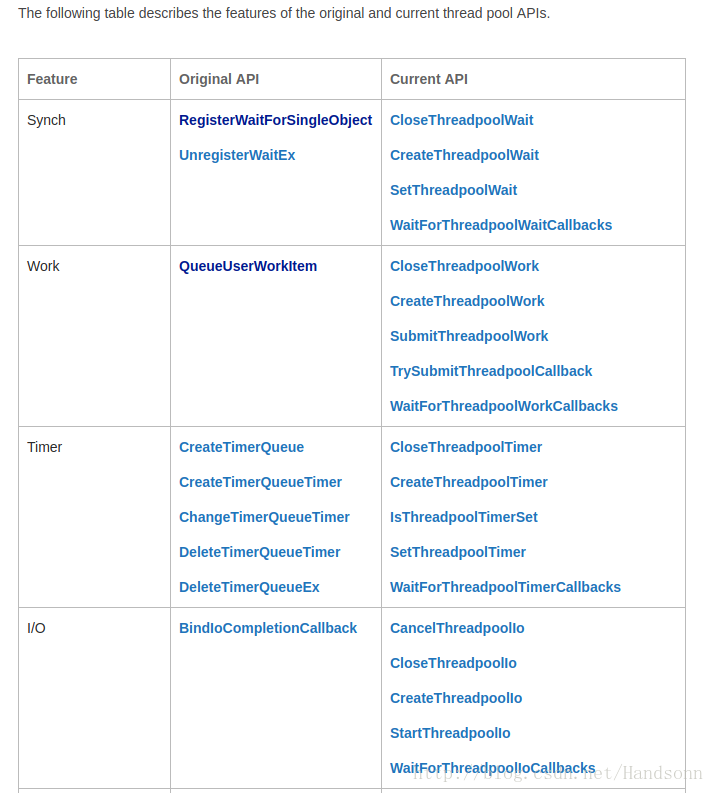
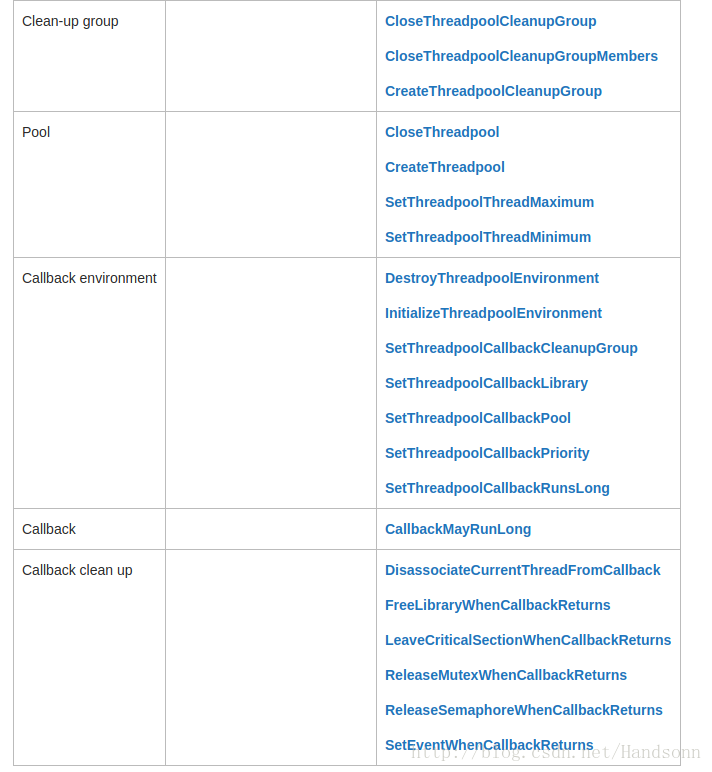
這些 API 可以有什麼功能?
a、以非同步的方式呼叫一個函式。 ———– 和 work 相關
b、每隔一段時間呼叫一個函式。———— 和 timer 相關
c、當核心物件觸發時呼叫一個函式。—— 和 wait 相關
d、當非同步IO請求完成時呼叫一個函式。— 和 I / O 相關
另外,清理組 clean up 關聯每個 callback 物件,可以用於 釋放 或者 等待,方便系統跟蹤所建立的各種物件。
咱們自己通過畫圖來梳理它們之間的關聯:
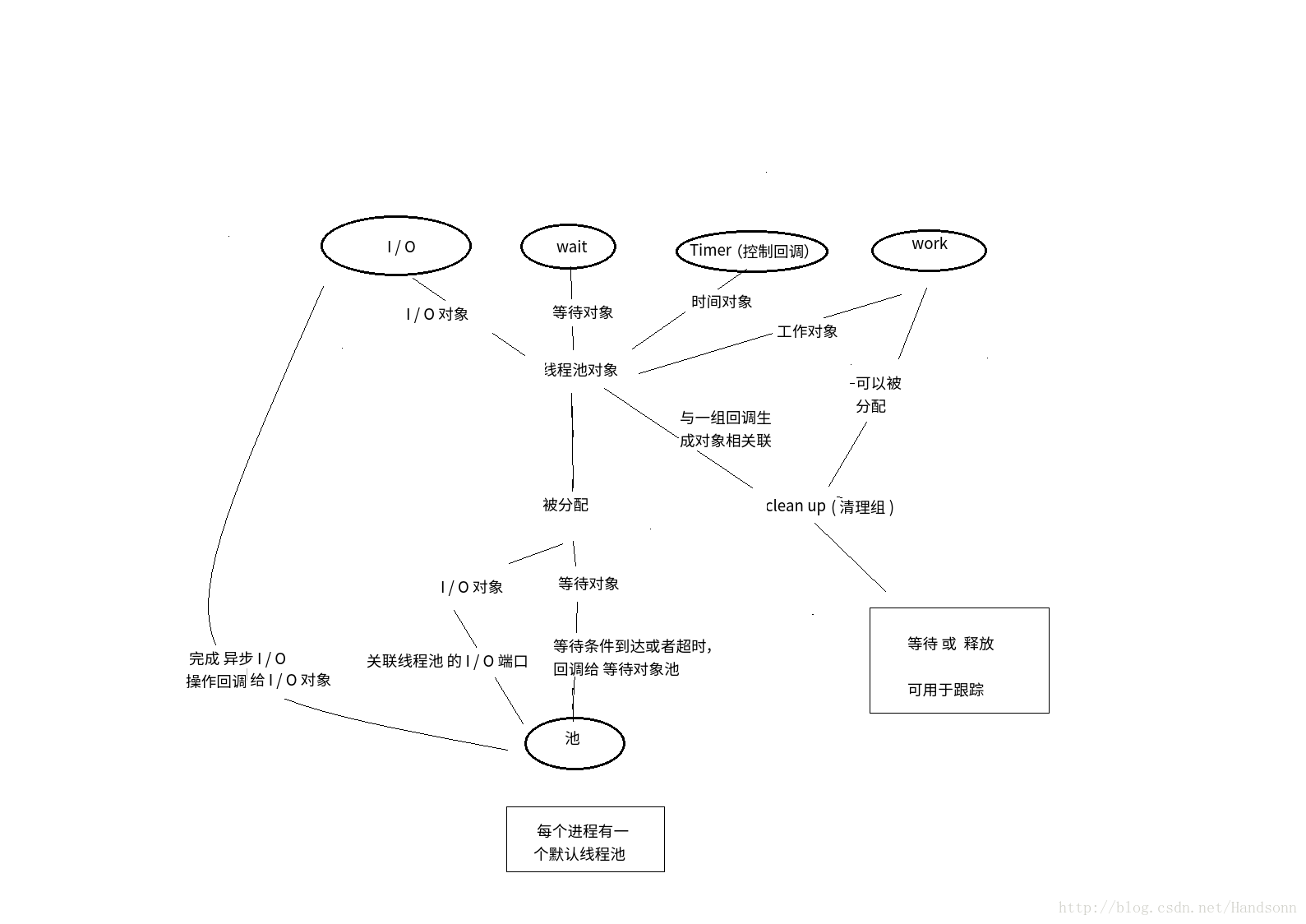
windows 每個程序都可以根據需要建立具有不同特徵的多個獨立池,並且每個程序還有一個預設的執行緒池,執行緒池的預設大小為每個可用處理器有 25 個執行緒,比如 我的電腦 4核心8硬體執行緒,預設有 25 × 8 個執行緒。
當我們提交一個請求後,執行緒池就會建立一個預設的執行緒池並讓執行緒池的一個執行緒來呼叫回撥函式。並不需要我們手動呼叫建立執行緒。當執行緒從入口函式返回時,並不會銷燬而是返回到執行緒池。執行緒池會不斷重複使用各個執行緒,而不會頻繁銷燬和新建執行緒。
4、區別
那麼上面這兩者有什麼區別嗎?
可以看到,windows 提供了一系列的 api 組合使用,也就是一套機制來實現一個執行緒池,結果通過回撥來進行跟蹤,並且 clean up 的 api 可以由我們來使用,所以在一些情況下可以進行回收,而 java 的提供了多個執行緒池,當然也可以進行執行緒的配置,包括核心和非核心,而清理工作由執行緒池進行,所以一些 shutdown 無效的情況下外部並無法手動清除。
5、寫一個
我們需要做的操作有
a、入隊操作,並且獲取返回值
這是一個 lambda 表示式 ( ps:c++ 11 的新特性):
() -> return type {body}
typename result_of
template<typename F, typename... Args>
auto enqueue(F &&f, Args&&... args)
-> future<typename result_of<F(Args...)>::type>;b、中斷操作,需要一個標誌來中斷執行緒,可以在解構函式中進行處理
ThreadPool::~ThreadPool()
{
...
stop = true;
}c、加鎖(阻塞)、喚醒
mutex queue_mutex;
condition_variable condition;總的來說:
在建構函式中做一些初始化處理操作並且不斷呼叫入隊,在此期間需要進行加鎖,然後便可入隊,我們定義自己想要的返回值在入隊之後獲取並進行列印,最後在解構函式中標誌中斷為 true。
程式碼尚未完善,待定。。。

6、使用
如果 c++ IDE 直接使用,咱們可以寫到 hpp 檔案,然後 include 即可,在 Android 中,可以打包成 so 庫
a、打包成 so 庫
打包流程,圖片較多,記錄在下面這篇裡面
b、使用:視訊彈幕、斷點下載
視訊彈幕就是不斷同步視訊播放和執行緒池的字串輸出,具體可以參考 :DanmakuFlameMaster
斷點下載:正在完善,待續…
7、其它

1)為什麼執行緒池要這麼設計
執行緒池設計中採用了 system design 的多級跳思路,核心執行緒是固定建立的,非核心執行緒是當核心執行緒都滿了,臨時建立的,類似於記憶體滿了,動態建立 swap(這裡的前提是swap和記憶體讀寫速度一致)
system design 中 很多多級跳的思路都是借鑑 L1 Cache、L2 Cache、 L3 Cache來設計的
更多一級快取、二級快取、三級快取的可以參考其他文章
2)什麼時候使用執行緒池
執行緒池的出現:著眼於減少執行緒池本身帶來的開銷
我們將執行緒執行過程分為三個過程:T1、T2、T3:
T1:執行緒建立時間
T2:執行緒執行時間,包括執行緒的同步等時間
T3:執行緒銷燬時間
那麼我們可以看出,執行緒本身的開銷所佔的比例為
。化簡之後 即 1 -可以看到,設 T2 保持不變,當執行緒自身開銷時間越來越多,即 建立越來越多執行緒,T1 + T3 會越來越大,分母隨之變大,整個開銷也會越來越大,也就是說,如果執行緒建立銷燬很頻繁的話,cpu 的這筆開銷將是不可忽略的。
因此,可以考慮以下情況使用執行緒池:
1 、多個任務並且執行時間短,不需要立即建立新執行緒。執行緒池建立執行緒是滯後的,不會發現執行緒不夠立即去建立新執行緒。
2 、任務單一時間長,如下載檔案。
還有一些明顯的好處:
a、方便管理,例如執行緒順序控制(如優先順序自定義、延時傳送、自定義運作流程演算法 等等);
b、一些結果反饋
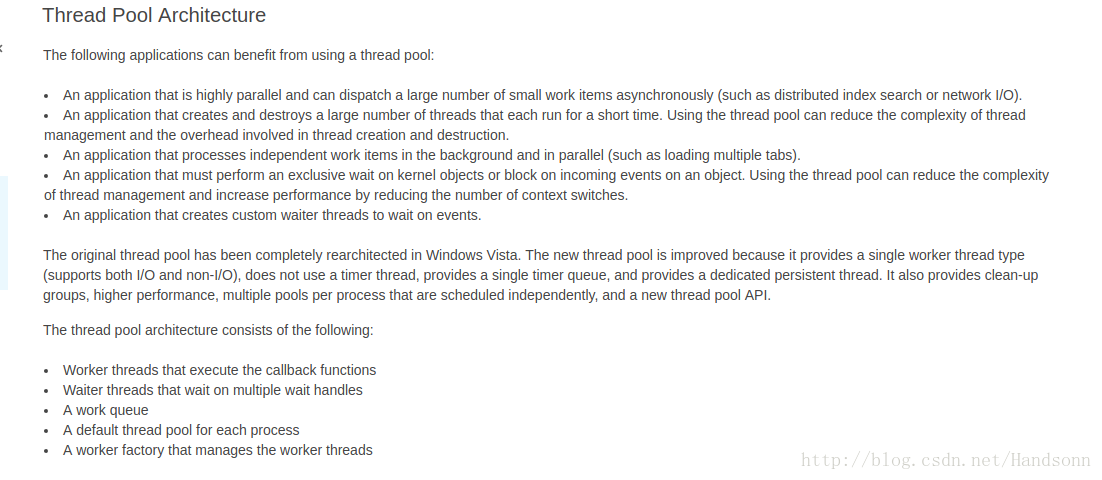
PS:執行緒池的優點可以參考 msdn 的敘述 ( 或者說什麼情況下使用執行緒池比較有利 ):
3)文章推薦
github:
關於執行緒池,還有很多地方並沒有很好了解,如ForkJoinPool具體怎麼分配任務,等等,可想而知,要寫出一個這麼優秀的執行緒池要多666,以上便是個人對執行緒池比較粗淺的一點理解,如有不對,歡迎指正,Thanks !