
快取雪崩、快取穿透、快取預熱、快取更新、快取降級等問題
前面一節說到了《為什麼說Redis是單執行緒的以及Redis為什麼這麼快!》,今天給大家整理一篇關於Redis經常被問到的問題:快取雪崩、快取穿透、快取預熱、快取更新、快取降級等概念的入門及簡單解決方案。
一、快取雪崩
快取雪崩我們可以簡單的理解為:由於原有快取失效,新快取未到期間(例如:我們設定快取時採用了相同的過期時間,在同一時刻出現大面積的快取過期),所有原本應該訪問快取的請求都去查詢資料庫了,而對資料庫CPU和記憶體造成巨大壓力,嚴重的會造成資料庫宕機。從而形成一系列連鎖反應,造成整個系統崩潰。
快取正常從Redis中獲取,示意圖如下:
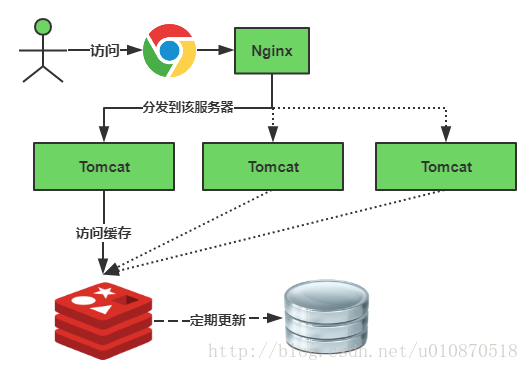
快取失效瞬間示意圖如下:
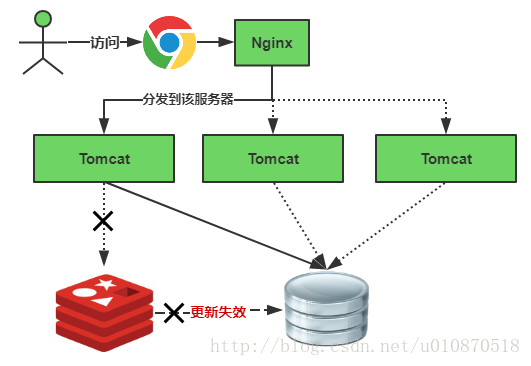
快取失效時的雪崩效應對底層系統的衝擊非常可怕!大多數系統設計者考慮用加鎖
以下簡單介紹兩種實現方式的虛擬碼:
(1)碰到這種情況,一般併發量不是特別多的時候,使用最多的解決方案是加鎖排隊,虛擬碼如下:
//虛擬碼
public object GetProductListNew() {
int cacheTime = 30;
String cacheKey = "product_list" 加鎖排隊只是為了減輕資料庫的壓力,並沒有提高系統吞吐量。假設在高併發下,快取重建期間key是鎖著的,這是過來1000個請求999個都在阻塞的。同樣會導致使用者等待超時,這是個治標不治本的方法!
注意:加鎖排隊的解決方式分散式環境的併發問題,有可能還要解決分散式鎖的問題;執行緒還會被阻塞,使用者體驗很差!因此,在真正的高併發場景下很少使用!
(2)還有一個解決辦法解決方案是:給每一個快取資料增加相應的快取標記,記錄快取的是否失效,如果快取標記失效,則更新資料快取,例項虛擬碼如下:
//虛擬碼
public object GetProductListNew() {
int cacheTime = 30;
String cacheKey = "product_list";
//快取標記
String cacheSign = cacheKey + "_sign";
String sign = CacheHelper.Get(cacheSign);
//獲取快取值
String cacheValue = CacheHelper.Get(cacheKey);
if (sign != null) {
return cacheValue; //未過期,直接返回
} else {
CacheHelper.Add(cacheSign, "1", cacheTime);
ThreadPool.QueueUserWorkItem((arg) -> {
//這裡一般是 sql查詢資料
cacheValue = GetProductListFromDB();
//日期設快取時間的2倍,用於髒讀
CacheHelper.Add(cacheKey, cacheValue, cacheTime * 2);
});
return cacheValue;
}
} 解釋說明:
1、快取標記:記錄快取資料是否過期,如果過期會觸發通知另外的執行緒在後臺去更新實際key的快取;
2、快取資料:它的過期時間比快取標記的時間延長1倍,例:標記快取時間30分鐘,資料快取設定為60分鐘。 這樣,當快取標記key過期後,實際快取還能把舊資料返回給呼叫端,直到另外的執行緒在後臺更新完成後,才會返回新快取。
關於快取崩潰的解決方法,這裡提出了三種方案:使用鎖或佇列、設定過期標誌更新快取、為key設定不同的快取失效時間,還有一各被稱為“二級快取”的解決方法,有興趣的讀者可以自行研究。
二、快取穿透
快取穿透是指使用者查詢資料,在資料庫沒有,自然在快取中也不會有。這樣就導致使用者查詢的時候,在快取中找不到,每次都要去資料庫再查詢一遍,然後返回空(相當於進行了兩次無用的查詢)。這樣請求就繞過快取直接查資料庫,這也是經常提的快取命中率問題。
有很多種方法可以有效地解決快取穿透問題,最常見的則是採用布隆過濾器,將所有可能存在的資料雜湊到一個足夠大的bitmap中,一個一定不存在的資料會被這個bitmap攔截掉,從而避免了對底層儲存系統的查詢壓力。
另外也有一個更為簡單粗暴的方法,如果一個查詢返回的資料為空(不管是資料不存在,還是系統故障),我們仍然把這個空結果進行快取,但它的過期時間會很短,最長不超過五分鐘。通過這個直接設定的預設值存放到快取,這樣第二次到緩衝中獲取就有值了,而不會繼續訪問資料庫,這種辦法最簡單粗暴!
//虛擬碼
public object GetProductListNew() {
int cacheTime = 30;
String cacheKey = "product_list";
String cacheValue = CacheHelper.Get(cacheKey);
if (cacheValue != null) {
return cacheValue;
}
cacheValue = CacheHelper.Get(cacheKey);
if (cacheValue != null) {
return cacheValue;
} else {
//資料庫查詢不到,為空
cacheValue = GetProductListFromDB();
if (cacheValue == null) {
//如果發現為空,設定個預設值,也快取起來
cacheValue = string.Empty;
}
CacheHelper.Add(cacheKey, cacheValue, cacheTime);
return cacheValue;
}
}把空結果,也給快取起來,這樣下次同樣的請求就可以直接返回空了,即可以避免當查詢的值為空時引起的快取穿透。同時也可以單獨設定個快取區域儲存空值,對要查詢的key進行預先校驗,然後再放行給後面的正常快取處理邏輯。
三、快取預熱
快取預熱這個應該是一個比較常見的概念,相信很多小夥伴都應該可以很容易的理解,快取預熱就是系統上線後,將相關的快取資料直接載入到快取系統。這樣就可以避免在使用者請求的時候,先查詢資料庫,然後再將資料快取的問題!使用者直接查詢事先被預熱的快取資料!
解決思路:
1、直接寫個快取重新整理頁面,上線時手工操作下;
2、資料量不大,可以在專案啟動的時候自動進行載入;
3、定時重新整理快取;
四、快取更新
除了快取伺服器自帶的快取失效策略之外(Redis預設的有6中策略可供選擇),我們還可以根據具體的業務需求進行自定義的快取淘汰,常見的策略有兩種:
(1)定時去清理過期的快取;
(2)當有使用者請求過來時,再判斷這個請求所用到的快取是否過期,過期的話就去底層系統得到新資料並更新快取。
兩者各有優劣,第一種的缺點是維護大量快取的key是比較麻煩的,第二種的缺點就是每次使用者請求過來都要判斷快取失效,邏輯相對比較複雜!具體用哪種方案,大家可以根據自己的應用場景來權衡。
五、快取降級
當訪問量劇增、服務出現問題(如響應時間慢或不響應)或非核心服務影響到核心流程的效能時,仍然需要保證服務還是可用的,即使是有損服務。系統可以根據一些關鍵資料進行自動降級,也可以配置開關實現人工降級。
降級的最終目的是保證核心服務可用,即使是有損的。而且有些服務是無法降級的(如加入購物車、結算)。
在進行降級之前要對系統進行梳理,看看系統是不是可以丟卒保帥;從而梳理出哪些必須誓死保護,哪些可降級;比如可以參考日誌級別設定預案:
(1)一般:比如有些服務偶爾因為網路抖動或者服務正在上線而超時,可以自動降級;
(2)警告:有些服務在一段時間內成功率有波動(如在95~100%之間),可以自動降級或人工降級,併發送告警;
(3)錯誤:比如可用率低於90%,或者資料庫連線池被打爆了,或者訪問量突然猛增到系統能承受的最大閥值,此時可以根據情況自動降級或者人工降級;
(4)嚴重錯誤:比如因為特殊原因資料錯誤了,此時需要緊急人工降級。
六、總結
這些都是實際專案中,可能碰到的一些問題,也是面試的時候經常會被問到的知識點,實際上還有很多很多各種各樣的問題,文中的解決方案,也不可能滿足所有的場景,相對來說只是對該問題的入門解決方法。一般正式的業務場景往往要複雜的多,應用場景不同,方法和解決方案也不同,由於上述方案,考慮的問題並不是很全面,因此並不適用於正式的專案開發,但是可以作為概念理解入門,具體解決方案要根據實際情況來確定!
參考文章: