雜湊表基本操作及其擴充套件
雜湊表
- 雜湊表的概念:
- 雜湊表本身是一個數組,其元素在陣列中存放位置為:通過雜湊函式使元素關鍵碼和元素儲存位置有一定的對映關係
- 雜湊表的特點:
- 搜尋陣列中某一元素時,可以通過該元素的關鍵碼和儲存位置的對映關係直接找到對應位置檢視是否存在
- 在陣列中插入元素時,根據雜湊函式計算出插入元素的位置並且在此位置存放
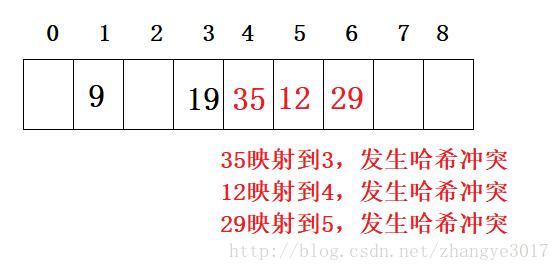
- 存在雜湊衝突:兩個不同的元素通過雜湊函式所對映的儲存位置相同即為雜湊衝突。例如:兩個元素的關鍵字X != y,但有HashFunc(x) == HashFunc(y)
雜湊衝突的解決方法
根據雜湊表的特點可知,雜湊衝突在所難免,雖然可以通過調整雜湊函式來降低雜湊函式的可能性,但還是不能完全避免雜湊衝突,因此提出兩種解決方案:
閉雜湊:開放地址法,即當雜湊表未裝滿時,將待插入元素Key放在下一“空位”處,
- “空位尋找”:線性探測和二次探測
線性探測:從發生雜湊衝突的位置挨著挨著向後找空位置,直到找到空位置,例如:
二次探測:從雜湊衝突的位置加上,i=1,2,3,….例如:
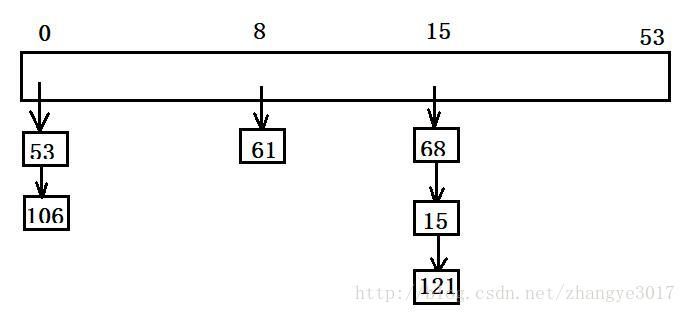
開雜湊:拉鍊法,首先對關鍵碼集合用雜湊函式計算雜湊地址,具有相同地址的關鍵碼歸於同一子集合,每一個子集合稱為一個桶,各個桶中的元素通過一個單鏈錶鏈接起來,各連結串列的頭結點儲存在雜湊表中(如圖)

基本操作
插入
- 注意問題:
(1)使用閉雜湊方法時擴容須滿足的負載因子 (大於0.7)
(2)使用開雜湊方法時擴容須滿足的負載因子 (等於1)
(3)擴容時將原雜湊表中的內容存放至新表時,對映到新表的位置須重新計算
(4)為了儘可能的避免雜湊衝突,使用素數表對齊做雜湊表的容量
- 注意問題:
刪除
- 注意問題:
(1) 閉雜湊刪除時只需要將其元素的狀態改為刪除即可
(2)開雜湊在刪除時需要將其所在節點進行刪除,刪除節點須注意是否為頭節點
- 注意問題:
查詢
- 注意問題:
(1)閉雜湊查詢某一元素時,只須在存在狀態的元素中尋找,如果狀態該元素的關鍵碼所對映的位置為空(EMPTY)或者刪除(DELET),表示該元素不存在
(2)閉雜湊查詢某一元素時,不僅需要在所對映的當前位置去找,還須在其所掛連結串列中尋找
- 注意問題:
程式碼實現
- 閉雜湊(開放地址)
#include<stdio.h>
#include<stdlib.h>
#include<assert.h> - 開雜湊(拉鍊法)
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
#include<string.h>
typedef int KeyType;
typedef int ValueType;
typedef struct HashNode
{
KeyType _key;
ValueType _value;
struct HashNode* _next;
}HashNode;
typedef struct HashTable
{
HashNode** _tables;
size_t _N;
size_t _size;
}HashTable;
size_t GetNextPrimeNum(size_t N);//空間
void HashTableInit(HashTable* ht);//初始化
size_t HashFunc(size_t n, KeyType key);//計算座標
HashNode* BuyHashNode(KeyType key, ValueType value);//建立節點
HashNode* HashTableFind(HashTable* ht, KeyType key);//查詢
int HashTableRemove(HashTable* ht, KeyType key);//刪除
void HashTablePrint(HashTable* ht);//列印
void HashTableDestory(HashTable* ht);//銷燬
void TestHashTable();
size_t GetNextPrimeNum(size_t N)
{
const int _PrimeSize = 28;
static const unsigned long _PrimeList[_PrimeSize] =
{
53ul, 97ul, 193ul, 389ul, 769ul,
1543ul, 3079ul, 6151ul, 12289ul, 24593ul,
49157ul, 98317ul, 196613ul, 393241ul, 786433ul,
1572869ul, 3145739ul, 6291469ul, 12582917ul, 25165843ul,
50331653ul, 100663319ul, 201326611ul, 402653189ul, 805306457ul,
1610612741ul, 3221225473ul, 4294967291ul
};
size_t i = 0;
for (; i < _PrimeSize; ++i)
{
if (_PrimeList[i]>N)
{
return _PrimeList[i];
}
}
return _PrimeList[_PrimeSize - 1];
}
void HashTableInit(HashTable* ht)
{
ht->_N = GetNextPrimeNum(0);
ht->_size = 0;
ht->_tables = (HashNode**)malloc(sizeof(HashNode*)*ht->_N);
assert(ht->_tables);
memset(ht->_tables, NULL, sizeof(HashNode*)*ht->_N);
}
size_t HashFunc(size_t n, KeyType key)
{
return key%n;
}
//建立節點
HashNode* BuyHashNode(KeyType key, ValueType value)
{
HashNode* node = (HashNode*)malloc(sizeof(HashNode));
assert(node);
node->_key = key;
node->_value = value;
node->_next = NULL;
return node;
}
//插入
int HashTableInsert(HashTable* ht, KeyType key, ValueType value)
{
assert(ht);
if (ht->_N == ht->_size)
{
//獲取下一個質數
size_t newN= GetNextPrimeNum(ht->_N);
//拷貝
HashNode** NewTable = (HashNode**)malloc(sizeof(HashNode*)*newN);
assert(NewTable);
memset(NewTable, NULL, sizeof(HashNode*)*newN);
for (size_t i = 0; i < ht->_N; ++i)
{
//新的位置
HashNode* cur =ht->_tables[i];
while (cur)
{
//進行頭插
size_t newindex = HashFunc(newN, cur->_key);
HashNode* next = cur->_next;
cur->_next = NewTable[newindex];
NewTable[newindex]=cur;
cur = next;
}
}
ht->_N = newN;
free(ht->_tables);
ht->_tables = NewTable;
}
//獲取位置
size_t index = HashFunc(ht->_N, key);
HashNode* cur = ht->_tables[index];
while (cur)
{
if (cur->_key == key)//已經插入過不在插入
{
return -1;
}
cur = cur->_next;
}
HashNode* node = BuyHashNode(key, value);
node->_next = ht->_tables[index];
ht->_tables[index] = node;
++ht->_size;
return 0;
}
//查詢
HashNode* HashTableFind(HashTable* ht, KeyType key)
{
assert(ht);
size_t index = HashFunc(ht->_N,key);
HashNode* cur = ht->_tables[index];
while (cur)
{
if (cur->_key == key)
{
return cur;
}
cur = cur->_next;
}
return NULL;
}
//刪除
int HashTableRemove(HashTable* ht, KeyType key)
{
assert(ht);
size_t index = HashFunc(ht->_N, key);
//1.頭節點
//2.非頭節點
HashNode* cur = ht->_tables[index];
HashNode* prev = cur;
while (cur)
{
if (cur->_key == key)
{
if (prev == cur)
{
//頭節點
ht->_tables[index] = cur->_next;
}
else
{
//不是頭節點
prev->_next = cur->_next;
}
free(cur);
return 0;
}
prev = cur;
cur = cur->_next;
}
return -1;
}
//銷燬
void HashTableDestory(HashTable* ht)
{
assert(ht);
free(ht->_tables);
ht->_tables = NULL;
ht->_N = 0;
ht->_size = 0;
}
//列印
void HashTablePrint(HashTable* ht)
{
assert(ht);
for (size_t i = 0; i < ht->_N; ++i)
{
HashNode* cur = ht->_tables[i];
while (cur)
{
printf("[%d]->%d ", i, cur->_key);
cur = cur->_next;
}
}
printf("\n\n");
}雜湊擴充套件
擴充套件一(點陣圖)
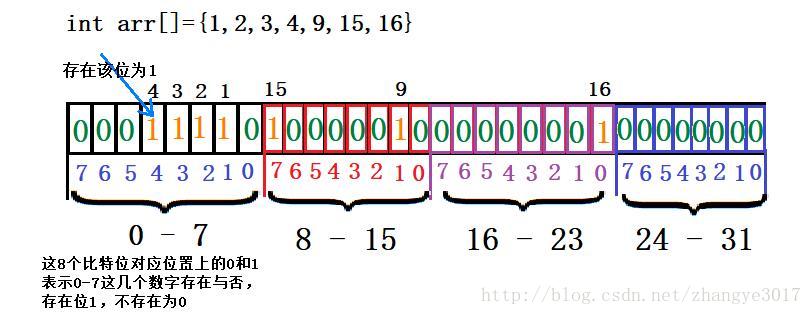
- 點陣圖理解:,點陣圖是利用每一位來表示一個整數是否存在來節省空間,1表示存在,0表示不存在。
點陣圖優缺點
(1)優點:點陣圖所開空間只與範圍有關,節省空間,在處理海量資料問題時,可使用點陣圖;例如:在40億個數中判斷一個數是否存在
(2)缺點:通過點陣圖所得到的結果不精確點陣圖操作
(1)插入:注意位置的計算,先計算待插入元素在陣列當中的位置,在計算在哪一個位元位
(2)重置:和插入一樣,找到位置,進行去反即可
(3)查詢:因為是1代表存在,故利用按位與(&)操作符檢視是否為1
擴充套件二(布隆過濾器)
概念
Bloom Filter是一種空間效率很高的隨機資料結構,它利用位陣列很簡潔地表示一個集合,並能判斷一個元素是否屬於這個集合。特點
(1)它適用於判斷元素是否存在集合當中,速率非常高。Bloom Filter有可能會出現錯誤判斷,但不會漏掉判斷。
(2)Bloom Filter可以準確的判斷出某個元素不在集合之中。但如果判斷某個元素存在集合中,有一定的概率判斷錯誤。因此,Bloom Filter不適合那些“零錯誤”的應用場合。
(3)在能容忍低錯誤率的應用場合下,Bloom Filter比其他查詢演算法(如hash,折半查詢)極大節省了空間。- 結構
(1)陣列:既然是雜湊的擴充套件,結構中必然包含陣列,但此陣列是有位元位(bite)組成的陣列
(2)含有多個雜湊函式,為了表達S={x1, x2,…,xn}這樣一個n個元素的集合,Bloom Filter使用k個相互獨立的雜湊函式(Hash Function),它們分別將集合中的每個元素對映到{1,…,n}的範圍中。 操作
(1)插入:布隆的結構裡有多個雜湊函式,必然某一資料的關鍵碼對映到陣列的位置不止一個
(2)刪除:一個數據對應多個位置,故刪除一個必然會影響其他資料,布隆過濾器的操作裡不支援刪除
(3)查詢:前面布隆的特點已經說過查詢會出現誤差,故布隆不適合出現在“零錯誤”的場合應用
(1)對y使用k個雜湊函式得到k個雜湊值
(2)判斷是否所有hash(y)的位置都是1(1≤i≤k),即k個位置都被設定為1了,
(3)如果所有位置都已置成了‘1’,y就可能集合中的元素;只有一個位置上是‘0’,那y一定不是集合中的元素。
注意1:布隆過濾器無法準確判斷某個元素存在於集合中,因為一個不存在元素通過k個雜湊函式映射出來的位置上的值可能都是‘1’。
注意2:布隆過濾器不能刪除元素。刪除一個元素就要把k個位置置為‘0’,這樣就會影響其他元素。(可以改進)改進
前面我們提到布隆過濾器不能刪除元素這一缺點是可以改進的,解決方案是用多個bit來儲存一個元素。這裡為了計算方便,採用32bit來儲存。全‘0’代表不存在,出現一個便加一,刪除元素時把對應位置減一就可以了。