
深度學習中的訓練集與測試集
摘自https://testerhome.com/topics/10811
測試集與訓練集
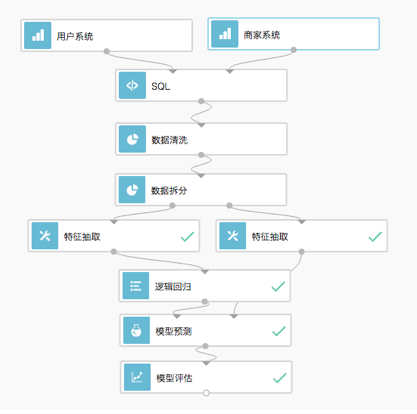
看上面的圖,這是一個邏輯迴歸演算法的DAG(有向無環圖),它是這個二分類演算法的簡單應用流程的展示。
可以看到我們在採集完資料並做過處理後,會把資料進行拆分。 訓練集作用訓練模型,而測試集會被輸入到模型中來評估模型的效能。這是我們測試人工智慧服務的最常用方式, 通過這個流程會產生一個模型的評估報告,如下:
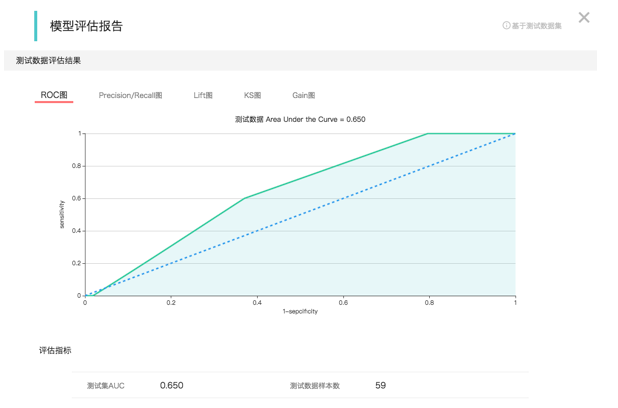
當然這種拆分是有一定的規則的,如果資料集比較小,那麼一般遵循7:3的經驗拆分,7分用來訓練模型,3分用來評估模型效能。 測試集不能太少,少了結果不準確,不能太多,太多了會導致訓練集資料不足。 但這個規則不是死的。 如果資料集本身比較大,例如有100W行資料。那麼我們抽取其中1W行做為測試集也就可以了。
相關推薦
深度學習中的訓練集與測試集
摘自https://testerhome.com/topics/10811測試集與訓練集看上面的圖,這是一個邏輯迴歸演算法的DAG(有向無環圖),它是這個二分類演算法的簡單應用流程的展示。 可以看到我們在採集完資料並做過處理後,會把資料進行拆分。 訓練集作用訓練模型,而測試集
關於在深度學習中訓練資料集的batch的經驗總結
由於深度學習的網格很大,用來訓練的資料集也很大。因此不可能一下子將所有資料集都輸入到網路中,便引入了batch_size的概念,下面總結自己兩種常用的呼叫batch的方法 1、使用TensorFlow, tf.train.batch()。 2、 offset = (offset
機器學習:訓練集,驗證集與測試集
來源:http://mooc.study.163.com/learn/2001281003?tid=2001391036#/learn/content?type=detail&id=2001702114&cid=2001693028 作用 訓練集:用於訓練模型的
python中如何實現將資料分成訓練集與測試集
接下來,直接給出大家響應的程式碼,並對每一行進行標註,希望能夠幫到大家。 需要用到的是庫是。numpy 、sklearn。 #匯入相應的庫(對資料庫進行切分需要用到的庫是sklearn.model
機器學習:訓練集與測試集的劃分
機器學習中有一個問題是不可避免的,那就是劃分測試集和訓練集。為什麼要這麼做呢,當然是提高模型的泛化能力,防止出現過擬合,並且可以尋找最優調節引數。訓練集用於訓練模型,測試集則是對訓練好的模型進行評估的資料集。通常來說,訓練集和測試集是不會有交集的,常用的資料集劃分方法有以下兩種:
Machine Learning筆記整理 ------ (二)訓練集與測試集的劃分
1. 留出法 (Hold-out) 將資料集D劃分為2個互斥子集,其中一個作為訓練集S,另一個作為測試集T,即有: D = S ∪ T, S ∩ T = ∅ 用訓練集S訓練模型,再用測試集T評估誤差,作為泛化誤差估計。 特點:單次使用留出法得到的估計結果往往不夠穩定可靠,故如果要使用留出法,一般採用若
訓練集與測試集切分
前言 為了 更好的訓練資料並且更好測試模型,一般做機器學習之前都會進行訓練集和測試集的切分。 train_test_split實現 其實我們可以先把資料的輸入X和輸出向量y進行一個水平拼接,然後隨機之後拆開,但是過程比較麻煩。在sklearn中shuf
在深度學習中處理不均衡資料集
在深度學習中處理不均衡資料集 不是所有的資料都是完美的。實際上,如果你拿到一個真實的完全均衡的資料集的話,那你真的是走運了。大部分的時候,你的資料都會有某種程度上的不均衡,也就是說你的資料集中每個類別的數量會不一樣。 我們為什麼想要資料是均衡的? 在我們開始花時間做深度學習專案之前,
驗證集與測試集
驗證集沒有演算法自動學習的過程,但存在人工調參過擬合的成份。在有監督的機器學習中,經常會說到訓練集(train)、驗證集(validation)和測試集(test),這三個集合的區分可能會讓人糊塗,特別是,有些讀者搞不清楚驗證集和測試集有什麼區別。I. 劃分如果我們自己已經有
驗證集與測試集的區別
在對機器學習演算法進行學習和實踐的時候,我們經常會遇到“驗證集”和“測試集”,通常的機器學習書籍都會告訴我們,驗證集和測試集不相交,驗證集和訓練集不相交,測試集和訓練集不相交。也就是驗證集與測試集似乎是同一級的東西,那麼我們自然而然會有一個困惑為什麼還要分測試集
深度學習中訓練引數的調節
1、學習率 步長的選擇:你走的距離長短,越短當然不會錯過,但是耗時間。步長的選擇比較麻煩。步長越小,越容易得到區域性最優化(到了比較大的山谷,就出不去了),而大了會全域性最優 一般來說,前1000步,很大,0.1;到了後面,迭代次數增高,下降0.01,再多,然後再小一些。 2、權重 梯度消失的情
深度學習中的數學與技巧(7):特徵值和特徵向量的幾何意義、計算及其性質
一、特徵值和特徵向量的幾何意義 特徵值和特徵向量確實有很明確的幾何意義,矩陣(既然討論特徵向量的問題,當然是方陣,這裡不討論廣義特徵向量的概念,就是一般的特徵向量)乘以一個向量的結果仍是同維數的一個向量。因此,矩陣乘法對應了一個變換,把一個向量變成同維數的另一個向量。
機器學習中資料訓練集,測試集劃分與交叉驗證的聯絡與區別(含程式)
因為一個模型僅僅重複了剛剛訓練過的樣本的標籤,這種情況下得分會很高,但是遇到沒有訓練過的樣本就無法預測了。這種情況叫做過擬合。為了避免過擬合,一個常見的做法就是在進行一個(有監督的)機器學習實驗時,保留
機器學習中,從樣本集合分得訓練集、測試集的三種方法
一、為什麼要分開訓練集與測試集 在機器學習中,我們是依靠對學習器的泛化誤差進行評估的方法來選擇學習器。具體方法如下:我們需要從訓練集資料中產出學習器,再用測試集來測試所得學習器對新樣本的判別能力,以測試集上的測試誤差作為泛化誤差的近似,來選取學習器。 通常我
機器學習中訓練資料集,交叉驗證資料集,測試資料集的作用
#1. 簡介 在Andrew Ng的機器學習教程裡,會將給定的資料集分為三部分:訓練資料集(training set)、交叉驗證資料集(cross validation set)、測試資料集(test set)。三者分別佔總資料集的60%、20%、20%。 那麼
機器學習中訓練集和測試集歸一化-matlab
本文不是介紹如何使用matlab對資料集進行歸一化,而是通過matlab來介紹一下資料歸一化的概念。 以下內容是自己的血淚史,因為歸一化的錯誤,自己的實驗過程至少走了兩個星期的彎路。由此可見機器學習中一些基礎知識和概念還是應該紮實掌握。 背景介紹:
【心得】深度學習入門——訓練並測試自己資料集
經過幾天的努力,成功訓練自己的資料集,並進行了單張圖片的測試。 訓練過程中val準確率約為0.91。看起來效果還比較理想,是否已經過擬合還沒有進行確定。 在訓練過程中,最討厭的就是處理檔案路徑和檔案存放位置。 一、ImageNet分類部分: caffe模型下有一個ex
深度學習tips-訓練集、開發集和測試集
training set、development set and test set 這三者是在進行一個機器學習專案中非常重要的內容。它們的確定往往決定了這個專案的走向。錯誤的訓練集、開發集和測試集的劃分很可能會讓一個團隊浪費數月時間。 trainin
機器學習系列(五)——訓練集、測試集、驗證集與模型選擇
在機器學習過程中,為了找到泛化效能最好的那個函式,我們需要確定兩方面的引數:1、假設函式引數,也就是我們通常所說的ww和bb,這類引數可以通過各種最優化演算法自動求得。2、模型引數,比如多項式迴歸中的多項式次數,規則化引數λλ等,這些引數被稱為超引數,一般在模型
深度學習之TensorFlow使用CNN測試Cifar-10資料集(Python實現)
題目描述: 1. 對Cifar-10影象資料集,用卷積神經網路進行分類,統計正確率。 2.選用Caffe, Tensorflow, Pytorch等開 源深度學習框架之一,學會安裝這些框架並呼叫它們的介面。 3.直接採用這些深度學習框架針對Cifar-10資料集已訓練好的網路模型,只