
程式的記憶體佈局——函式呼叫棧的那點事
[注]此文是《程式設計師的自我修養》的讀書總結,其中摻雜著一些個人的理解,若有不對,歡迎拍磚。
程式的記憶體佈局
現代的應用程式都執行在一個虛擬記憶體空間裡,在32位的系統裡,這個記憶體空間擁有4GB的定址能力。現代的應用程式可以直接使用32位的地址進行定址,整個記憶體是一個統一的地址空間,使用者可以使用一個32位的指標訪問任意記憶體位置。
【關於虛擬地址空間的介紹,看這裡http://blog.csdn.net/yang_yulei/article/details/24385573】
在程序的不同地址區間上有著不同的地位,Windows在預設情況下會將高地址的2GB空間分配給核心,而Linux預設將高地址的1GB空間分配給核心

(1)程式碼區:這個區域儲存著被裝入執行的二進位制機器程式碼,處理器會到這個區域取指並執行。
(2)資料區:用於儲存全域性變數、常量。
(3)堆區:程序可以在堆區動態地請求一定大小的記憶體,並在用完之後歸還給堆區。動態分配和回收是堆區的特點。
(4)棧區:用於動態地儲存函式之間的關係,以保證被呼叫函式在返回時恢復到母函式中繼續執行。
高階語言寫出的程式經過編譯連結,最終會變成可執行檔案。當可執行檔案被裝載執行後,就成了所謂的程序。
可執行檔案程式碼段中包含的二進位制級別的機器程式碼會被裝入記憶體的程式碼區(.text);
處理器將到記憶體的這個區域一條一條地取出指令和運算元,並送入運算邏輯單元進行運算;
如果程式碼中請求開闢動態記憶體,則會在記憶體的堆區分配一塊大小合適的區域返回給程式碼區的程式碼使用;
當函式呼叫發生時,函式的呼叫關係等資訊會動態地儲存在記憶體的棧區,以供處理器在執行完被呼叫函式的程式碼時,返回母函式。
如果把計算機看成一個有條不紊的工廠,我們可以得到如下類比:
* CPU是幹活的工人。
* 資料區、堆區、棧區等則是用來存放原料、半成品、成品等各種東西的場所。
* 存放在程式碼區的指令則告訴CPU要做什麼,怎麼做,到哪裡去領原材料,用什麼工具來做,做完以後把成品放到哪個貨倉去。
棧
在經典的作業系統裡,棧總是向下增長的。棧頂由esp暫存器定位。壓棧操作使棧頂的地址減小,彈出操作使棧頂地址增大。
當函式呼叫的時候發生了什麼?
例如:
int main(void)
{
foo(1,2,3) ;
return 0 ;
}1、在main方法的呼叫棧中,將
foo的引數從右向左 依次push到棧中。
2、把main方法當前指令的 下一條指令地址 (即return address)push到棧中。(隱藏在call指令中)
3、使用call指令呼叫目標函式體foo。
請注意,以上3步都處於main的呼叫棧,其中ebp儲存其棧底,而esp儲存其棧頂
接下來,在foo函式中:
1、push ebp: 將ebp的當前值push到棧中,即儲存ebp。
2、mov ebp,esp: 將esp的值賦給ebp,則意味著進入了foo方法的呼叫棧。
3、[可選]sub esp, XXX: 在棧上分配XXX位元組的臨時空間。(擡高棧頂)(編譯器根據函式中的區域性變數的總大小確定臨時空間的大小)
4、[可選]push XXX: 儲存(push)一些暫存器的值。
【注意:push暫存器的值,這一操作,可以在分配臨時空間之前,也可在其之後,《程式設計師的自我修養》寫的是在開闢臨時變數之後】
(編譯器中儲存的有相應的變數名對應的臨時空間中的位置)
而在foo方法呼叫完畢後,便執行前面階段的逆操作:
1、儲存返回值: 通常將函式的返回值儲存在暫存器eax中。
2、[可選]恢復(pop)一些暫存器的值。
3、mov esp,ebp: 恢復esp同時回收區域性變數空間。(恢復原棧頂)
4、pop ebp: 將棧頂的值賦給ebp,即恢復main呼叫棧的棧底。(恢復原棧底)
5、ret: 從棧頂獲得之前保留的return address,並跳轉到此位置繼續執行。
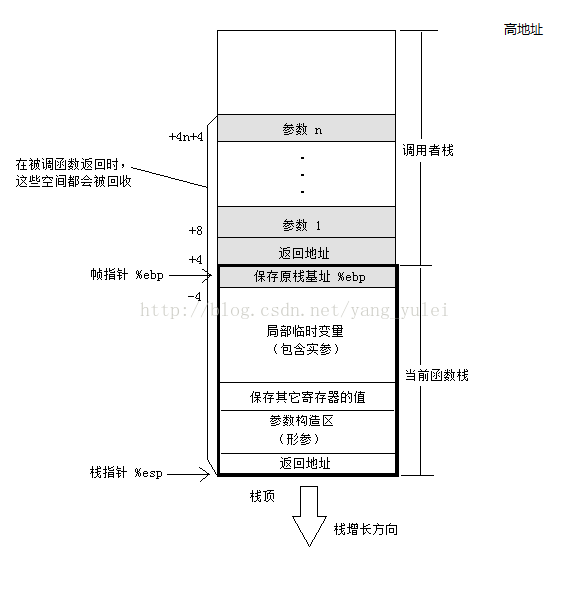
main方法先將foo方法所需的引數壓入棧中,然後再改變ebp,進入foo方法的呼叫棧。
因此,如果在foo方法中需要訪問那些引數,則需要根據當前ebp中的值,再向高地址偏移後進行訪問——因為高地址才是main方法的呼叫棧。
也就是說,地址ebp + 8存放了foo方法的第1個引數,地址ebp + 12存放了foo方法的第2個引數,以此類推。那麼地址ebp + 4存放了什麼呢?它存放的是return address,即foo方法返回後,需要繼續執行下去的main方法指令的地址。
【注意】
若需在函式中儲存被調函式儲存暫存器(如ESI、EDI),則編譯器在儲存EBP值時進行儲存,或延遲儲存直到區域性變數空間被分配。在棧幀中並未為被調函式儲存暫存器的空間指定標準的儲存位置。
【注:幾個相關的暫存器(關於詳細的介紹,見王爽彙編)】
(1)esp:棧指標暫存器(extended stack pointer),其記憶體放著一個指標,該指標永遠指向系統棧最上面一個棧幀的棧頂。
(2)ebp:基址指標暫存器(extended base pointer),其記憶體放著一個指標,該指標永遠指向系統棧最上面一個棧幀的底部。(ebp在當前棧幀內位置固定,故函式中對大部分資料的訪問都基於ebp進行)
(3)eip:指令暫存器(extended instruction pointer),其記憶體放著一個指標,該指標永遠指向下一條等待執行的指令地址。 可以說如果控制了EIP暫存器的內容,就控制了程序——我們讓eip指向哪裡,CPU就會去執行哪裡的指令。eip可被jmp、call和ret等指令隱含地改變(事實上它一直都在改變)(ret指令就是把當前棧頂儲存的返回值地址 彈到eip中)
函式棧幀的大小並不固定,一般與其對應函式的區域性變數多少有關。函式執行過程中,其棧幀大小也是在不停變化的。
呼叫慣例
函式的呼叫方和被呼叫方對於函式如何呼叫需要遵守同樣的約定,函式才能被正確地呼叫,這樣的約定稱為**呼叫慣例**。
* 函式引數的傳遞順序和方式呼叫慣例要規定引數壓棧的順序:是從左至右,還是從右至左。有些呼叫慣例還允許使用暫存器傳遞引數,以提高效能。
* 棧的維護方式
(誰負責彈出形參?)
在被調函式返回時,需要將被壓入棧中的引數全部彈出,以使得棧在函式呼叫前後保持一致。這個彈出的工作可以由函式的呼叫方完成,也也可以由被函式完成。
* 名字修飾規則
為了連結的時候對呼叫慣例進行區分,呼叫慣例要對函式本身的名字進行修飾,不同的呼叫慣例有不同的名字修飾策略。
| 呼叫慣例 | 誰彈形參 | 引數壓棧方向 | 名字修飾 |
|---|---|---|---|
| cdecl | 呼叫方 | 從右至左 | 下劃線+函式名 |
| stdcall | 被調方 | 從右至左 | 下劃線+函式名@引數位元組數 |
| pascal | 被調方 | 從左至右 | 較複雜 |
| fastcall | 被調方 | 頭兩個引數放入暫存器,其它從右至左 | @函式名字名@引數位元組數 |
_cdecl
是CDeclaration的縮寫,表示C語言預設的函式呼叫方法:所有引數從右到左依次入棧,這些引數由呼叫者清除,稱為手動清棧。被呼叫函式無需要求呼叫者傳遞多少引數,呼叫者傳遞過多或者過少的引數,甚至完全不同的引數都不會產生編譯階段的錯誤。(典型的如printf函式)
_stdcall
是Standard Call的縮寫,是C++的標準呼叫方式:所有引數從右到左依次入棧。這些堆疊中的引數由被呼叫的函式在返回後清除,使用的指令是 retn X,X表示引數佔用的位元組數,CPU在ret之後自動彈出X個位元組的堆疊空間。稱為自動清棧。函式在編譯的時候就必須確定引數個數,並且呼叫者必須嚴格的控制引數的生成,不能多,不能少,否則返回後會出錯。
幾乎我們寫的每一個WINDOWS API函式都是_stdcall型別的,因為不同的編譯器產生棧的方式不盡相同,呼叫者不一定能正常的完成清除工作。如果使用_stdcall,上面的問題就解決了,函式自己解決清除工作。所以,在跨平臺的呼叫中,我們都使用_stdcall(雖然有時是以WINAPI的樣子出現)。
但當我們遇到這樣的函式如printf()它的引數是可變的,不定長的,被呼叫者事先無法知道引數的長度,事後的清除工作也無法正常的進行,因此,這種情況我們只能使用\_cdecl。到這裡我們有一個結論,如果你的程式中沒有涉及可變引數,最好使用_stdcall關鍵字。
函式返回值傳遞
一般情況下,暫存器eax是傳遞返回值的通道,函式將返回值儲存在eax中,返回後函式的呼叫方再讀取eax。
但是eax本身只有4位元組,那麼大於4位元組的返回值是如何傳遞的呢?
對於返回5~8位元組資料的情況,一般採用eax和edx聯合返回的方式進行的。其中eax儲存返回值的低4位元組,edx儲存返回值的高4位元組。對於超過8位元組的返回型別:
typedef struct big_thing
{
char buf[128] ;
} big_thing ;
big_thing return_test();
//---------------------------
int main(void)
{
big_thing n = return_test() ;
}
big_thing return_test()
{
big_thing b ;
b.buf[0] = 0 ;
return b ;
}首先,在主調函式main中,肯定有一個128位元組的變數n,在被調函式return_test中,肯定有一個128位元組的變數b。
那被調函式如何返回128位元組的變數?直接從b拷貝到n麼?你這樣直接改變主調函式中變數的值,似乎不符合返回值傳值的規則。
那麼實際上,編譯器是怎麼設計大尺寸返回值傳遞的呢?
* main函式在其棧中的區域性變數區域中額外開闢一片空間,將其一部分作為傳遞返回值的臨時物件temp。
* 將temp物件的地址作為隱藏引數傳遞給return_test函式。
* return_test函式將資料拷貝給temp物件,並將temp物件的地址用eax傳出。
* return_test返回後,main函式將eax指向的temp物件的內容拷貝給n。
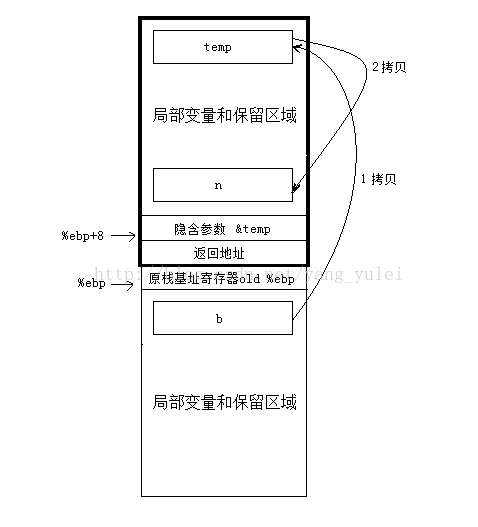
(return_test是沒有真正的引數的,只有一個“偽引數”由函式的呼叫方悄悄傳入)
【總結】
函式返回值的傳遞:小於8位元組的返回值,以暫存器為中轉。大於8位元組的,以主調函式中新開闢的同樣大小的中間變數temp為中轉。
C語言對於尺寸太大的返回值型別,會使用一個臨時的棧上記憶體區域作為中轉,結果返回值物件會被拷貝兩次。故不到萬不得已,不要輕易返回大尺寸物件。
C++函式的返回值傳遞C++處理大返回值略有不同,其可能是像C那樣,1次拷貝到棧上的臨時物件裡,然後把臨時物件拷貝到儲存返回值的物件裡。
但,有些編譯器會進行返回值優化RVO(Return Value Optimization),這樣,物件拷貝會減少一次,即沒有臨時物件temp了,直接拷貝到主調函式的相應物件中。
例如:
#include <iostream>
using namespace std ;
struct cpp_obj
{
cpp_obj()
{
cout<< "ctor\n" ;
}
cpp_obj(const cpp_obj& c)
{
cout<< "copy ctor\n" ;
}
cpp_obj& operator=(const cpp_obj& rhs)
{
cout<< "operator=\n" ;
return *this ;
}
~cpp_obj()
{
cout<< "dtor\n" ;
}
} ;
cpp_obj foo()
{
cpp_obj b ;
cout << "before foo return\n" ;
return b ;
}
int main()
{
cpp_obj n ;
n = foo() ;
cout << "before main return\n" ;
return 0 ;
}
//---------執行結果---------
ctor
ctor
before foo return
operator=
dtor
before main return
dtorNRV
C++對於返回值還有一種更“激進”的優化策略——NRV(Named Return Value)具名返回值優化
這種優化是甚至連被調函式中的區域性變數都不要了!直接在主調函式中操作物件(根據隱藏引數傳入的物件的引用)。
NRV優化簡單的說:
主調函式中有一條語句,Cobj a = f();其中f()是一個函式,函式裡邊申請了一個Cobj的物件b,然後把它返回。在物件返回的時候,一般情況下要呼叫拷貝函式,把函式f()裡邊的區域性物件b拷貝到函式外部的物件a。
但是如果用了NRV優化,那就不必要呼叫拷貝建構函式,編譯器可以這樣做,把a的地址傳遞進函式f(),然後不讓f()申請要返回的物件b的空間,用a的地址來代替b的地址,這樣當要返回物件b的時候,就不必要拷貝了,因為b就是a,省去了區域性變數b,省去了拷貝的過程。
關於NRV要注意兩點:(自己總結的,若有不對,請拍磚)
1、在被調函式foo中,其區域性變數宣告處即是呼叫主調函式main中物件的預設建構函式處。main中的物件定義處,只是開闢一個空間,當時並不呼叫建構函式。
2、為何在主調函式中 CObj obj = foo() 會觸發NRV優化
而分開寫: CObj obj ; obj = foo() ; 沒有NRV優化呢?
因為:
程式設計師必須給class X定義拷貝建構函式才能觸發NRV優化,不然還是按照最初的較慢的方式執行。(我們的第二種方式沒有涉及到拷貝建構函式,故不會觸發NRV優化)
但現在的編譯器即使去掉類中的拷貝建構函式,也一樣會有NRV優化,但必須是向在物件初始化時呼叫子函式才會有NRV。
(若沒有NRV優化,則被調函式中會生成區域性物件,但這個區域性物件直接拷貝到主函式相應的物件中,也不會像C那樣還要生成一個臨時變數)
若把上面的例子的呼叫方式改為: cpp_obj n = foo() ;
則會觸發NRV優化,執行結果就是:
//cpp_obj n = foo() ;改為:
foo(n) ;
//foo實際就被改為:
void foo(cpp_obj& __result)
{
// 呼叫__result的預設建構函式
__result.cpp_obj::cpp_obj();
// 處理__result
return;
}
//---------NRV後的執行結果---------
ctor
before foo return
before main return
dtor關於NRV優化詳細見《深入理解C++物件模型》
堆
堆是一塊巨大的記憶體空間,常常佔據整個虛擬地址空間的絕大部分。在這片空間裡,程式可以請求一塊連續記憶體,並自由地使用,這塊記憶體在程式主動放棄之前都會一直保持有效。在C語言中我們可以用malloc函式在堆上申請空間。
malloc的實現:
作業系統核心管理著程序的地址空間,它通過的有系統呼叫,若讓malloc呼叫這個系統呼叫實現申請記憶體,可完成這個工作。
但是,這樣做效能較差,因為每次進行申請釋放空間都需要進行系統呼叫,系統呼叫的開銷比較大,會進行核心態和使用者態的切換。
比較好的做法是程式向作業系統申請一塊適當大小的堆空間,然後由程式自己管理這塊空間,管理著堆空間分配的往往是程式的執行庫(一般是作業系統提供的共享庫)。
malloc實際上就是對這共享庫中函式的包裝。
"批發-零售"類比:
執行庫相當於是向作業系統批發了一塊較大的堆空間,然後零售給程式用。執行庫在向程式零售空間時,必須管理此空間,不能把一塊空間出售兩次。
當空間不夠用時,執行庫再向作業系統批發(呼叫OS相應的系統呼叫)。
注意:這個執行庫一般也是作業系統或語言提供給我們的,其包含了管理堆空間的演算法,其執行在使用者態下。
(我們自己也可以實現這個分配演算法,但常用的分配演算法已經被各種系統、庫實現了無數遍,沒有必要重複發明輪子)
每個程序在建立時都會有一個預設堆,這個堆在程序啟動時建立,並且直到程序結束都一直存在。在Windows中預設堆大小為1MB。
(注意:在Windows中堆不一定是向上增長的)
問:malloc申請的空間是不是連續的?
答:若“空間”指的是虛擬空間的話,那麼答案是連續的,即每一次malloc分配後返回的空間都可以看做是一塊連續的地址。(程序中可能存在多個堆,但一次能夠分配的最大堆空間取決於最大的那個堆)
如果空間值的是物理空間,則不一定連續,因為一塊連續的虛擬地址空間有可能是若干個不連續的物理頁拼湊成的。
堆空間管理演算法
* 1、空閒連結串列法
把堆中各個空閒塊按連結串列的方式連線起來,當用戶請求時遍歷連結串列找到合適的塊。
* 2、點陣圖(這個思想好)
將整個堆劃分為大量的大小相同的塊。當用戶請求時分配整數個空間給使用者。我們可以用一個整數陣列的位來記錄分配狀況。
(每個塊只有頭/使用/空閒三種狀態,即用兩個位就可表示一個塊,因此稱為點陣圖。頭是用來標記定界的作用)