
關於spark的yarn模式的測試
額。。。本人菜雞一隻,強行記錄點東西,分享一下,也怕自己腦子不好使,忘記了~如果有說錯的,還請大家指出批評!!
前言:spark的執行模式有很多,通過--master這樣的引數來設定的,現在spark已經有2.3.0的版本了,執行模式有mesos,yarn,local,更好的是他可以和多種框架做整合,2.3的版本也新增了Kubernetes。。。
言歸正傳,講下我所做的測試:
測試的程式碼如下(用的是spark1.6的版本):
import org.apache.spark.sql.hive.HiveContext import org.apache.spark.{SparkConf, SparkContext} /** * Created by 略略略 on 2018. */ object Hive_Row_Number { def main(args: Array[String]) { //1、建立spark上下文 val conf = new SparkConf() .setAppName("Hive_Row_Number") //設定這個值,避免sql的shuffle分割槽數為預設的200,就會很慢 .set("spark.sql.shuffle.partitions", "5"); //這裡如果是local執行就把註釋解開, //如果打成jar包,伺服器執行,一定要註釋掉, //否則client模式會變成local(就是任務不會提交到yarn上去計算) //cluster模式執行會有結果,但是會報錯 //.setMaster("local[*]") val sc = SparkContext.getOrCreate(conf) //這裡要考慮是否要讀取hive的資料,或者使用HQL //如果需要:就使用HiveContext,如果不需要,就使用SQLContext //如果使用HiveContext並且在本地做的測試,很可能需要新增-XX:PermSize=128M -XX:MaxPermSize=256M 來避免記憶體溢位 //因為構建HiveContext的時候,會載入不少hive預設的jar包,類,物件, //在1.6版本這兩個物件還是分開的,但是2.0以上的版本就是統一到SparkSession這個物件上了 val sqlContext = new HiveContext(sc) val df = sqlContext.sql("select deptno,sal,ename,row_number() over (partition by deptno order by sal desc) as rnk from test.emp") //取rnk為前三的 df.show() df.registerTempTable("tmp") println("=============註冊成臨時表的方法=================") sqlContext.sql("select deptno,sal,ename,rnk from tmp where rnk <= 3").show() println("=============子查詢巢狀的方法=================") sqlContext.sql( """ |SELECT |deptno,sal,ename,rnk |FROM |(SELECT |deptno,sal,ename, |ROW_NUMBER() OVER (PARTITION BY deptno ORDER BY sal DESC) as rnk |FROM class19.emp) a |WHERE rnk <= 3 """.stripMargin).show() } }
這個程式碼呢,你要告訴你的spark應用程式,從哪裡去讀取元資料資訊,也就是hive-site.xml這個檔案
一、連線元資料資訊有兩種方式:
-1.可以使用hive提供的metastore服務
-2.可以直接通過hive-site.xml中給定的mysql資料庫連線資訊,連線上mysql上的hive的元資料資訊庫
這裡附上我的,不用配置很多東西,我使用的是hive提供的metastore服務
記得要開啟 bin/hive --service metastore
<?xml version="1.0" encoding="UTF-8" standalone="no"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed to the Apache Software Foundation (ASF) under one or more contributor license agreements. See the NOTICE file distributed with this work for additional information regarding copyright ownership. The ASF licenses this file to You under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. --> <configuration> <property> <name>hive.metastore.uris</name> <value>thrift://bigdata-01:9083</value> <description>Thrift URI for the remote metastore. Used by metastore client to connect to remote metastore.</description> </property> <property> <name>hive.metastore.warehouse.dir</name> <value>hdfs://bigdata-01:8020/user/hive/warehouse</value> </property> </configuration>
具體怎麼操作,就不說了吧,這不是這篇文章的重點。
二、執行什麼模式,配置引數可以有三個地方給定:
1、程式碼中給定,例如 val conf = new SparkConf().setMaster(XXX)
2、提交job的時候,就是在寫那個spark-submit指令碼的時候可以給定 --master XXX
3、在spark-env,或者spark-defaults.conf等這類的配置檔案中提前寫好
優先順序:3<2<1,也就是說,如果你在三個地方都寫了相同的引數,給定了不同的值,那麼最後那個值為程式碼中給定的值
三、local模式
這也不是想要說的重點,執行的時候,要記得新增一下hive-site.xml(和hive/conf目錄下的hive-site.xml配置保持一致)到專案的resource中,例如:
然後,直接執行main方法,搞定!
四、伺服器或者虛擬機器執行模式:
1、就需要將專案打包,打包方式有很多,簡單描述下,這也不是我要說的重點:
-1、打成胖包,就是打包的時候把相關依賴全部打進jar,會導致jar檔案比較大,也有可能遇到jar包衝突的問題
-2、打成瘦包,就是隻把resource目錄下的配置和程式碼打進jar中,相反,有可能會遇到jar缺失,找不到的問題
-3.開發工具直接打包
myeclipse的叫export,idea的叫build,myeclipse預設的export不能新增外部依賴(就是不能打成胖包),但是idea可以
-4.maven打包
maven打包如果要打胖包,可以使用assembly外掛,如果不打胖包就無所謂了
-5.以上的打包方式一定要注意一點,就是要把resource裡面的配置檔案打入,不然執行程式碼的時候,建立HiveContext,不知道去哪裡連線metastore服務!
-6.然後,我做了兩個測試:
打了兩個包,一個有hive-site.xml,一個沒有,然後我會進行如下兩種模式的測試!
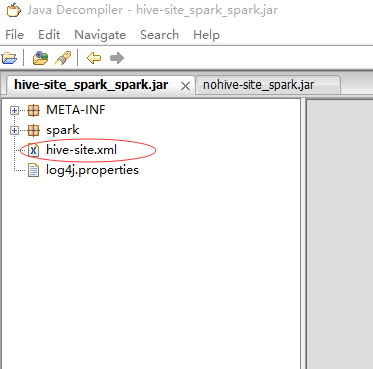
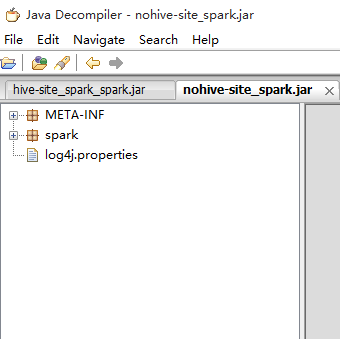
2、yarn-client模式
概念:使用這種方式提交的話,spark的driver就會在提交的機器上開啟,driver就是用來構建spark上下文,和DAG的流程圖,等到有action的操作的時候,才把一個個task任務甩到executor上去執行,所有的executor的task資訊等亂七八糟有的沒的的log資訊,都會返回到driver端,因此client模式,可以看到這個spark的application執行期間是否出現問題,有問題能夠對症下藥。但是這種模式有個問題,就是當前機器的driver要接收非常多的訊息,非常多的連線,導致當前機器效能下降(而且我們並不知道當前機器有沒有能力承受這麼大的壓力)
執行命令:
bin/spark-submit \
--master yarn \
--deploy-mode client \
--class spark.sql.Hive_Row_Number \
--queue QUEUE_NAME \
/usr/datas/nohive-site_spark.jar但是我想要把回顯的所有資訊存在一個文本當中,讓我今後檢視,因此(使用nohup命令):
nohup bin/spark-submit \
--master yarn \
--deploy-mode client \
--class spark.sql.Hive_Row_Number \
--queue QUEUE_NAME \
/usr/datas/nohive-site_spark.jar >> nohive-site.log 2>&1 &這樣就會自動在當前目錄下生成一個nohive-site.log檔案,就可以查看了
這裡就擷取部分資訊來說明
1)classpath
首先,我在spark-env.sh中添加了SPARK_CLASSPATH,把我需要的一些基礎的依賴放到了external_jars這個目錄中,因此我發現yarn-client模式也會自動載入這個目錄下面的所有jar包
但是這種方式,在我的1.6的版本是過時的,不過還是生效的
提示你,應該使用如下的方式:
-1-、先將spark-env.sh中的SPARK_CLASSPATH註釋掉(不註釋會報錯,在下面的測試三的第四種有截圖)
-2-、再將executor所有需要的jar包考到一個檔案裡(XXXX/XXX裡)
-3-、然後在spark-default中設定引數:spark.executor.extraClassPath=XXXX/XXX/* (設定executor端jar)
-4-、最後在執行:
nohup bin/spark-submit \
--master yarn \
--deploy-mode client \
--class spark.sql.Hive_Row_Number \
--queue QUEUE_NAME \
--driver-class-path /usr/jars/mysql-connector-java-5.1.34-bin.jar(設定driver端需要的jar) \
/opt/datas/nohive-site_spark.jar >> nohive-site.log 2>&1 &本文後面,會歸納一些jar包讀取不到(新增jar包的方式)的解決方法
2)hive-site到底讀沒讀到
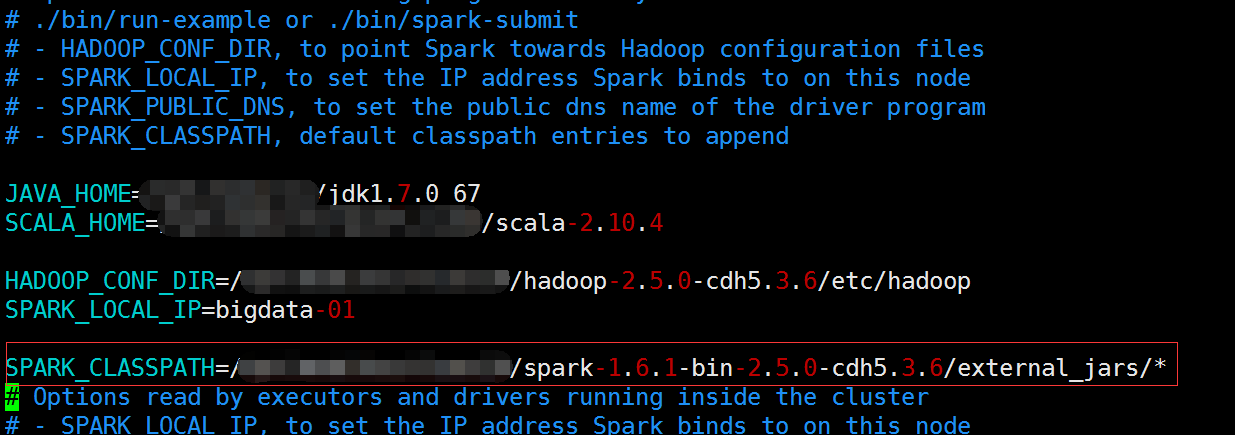

jar中沒有hive-site.xml
測試一:在spark/conf下放置了hive-site.xml,程式能正常執行
雖然能看到中間有一段在連線預設自帶的derby,並且還有個warn,不過後面又有:INFO hive.metastore: Trying to connect to metastore with URI thrift://bigdata-01:9083這麼一段資訊,最後結果也出來,證明spark on yarn 也會自動載入spark的conf目錄下的配置檔案,那麼我就放心了
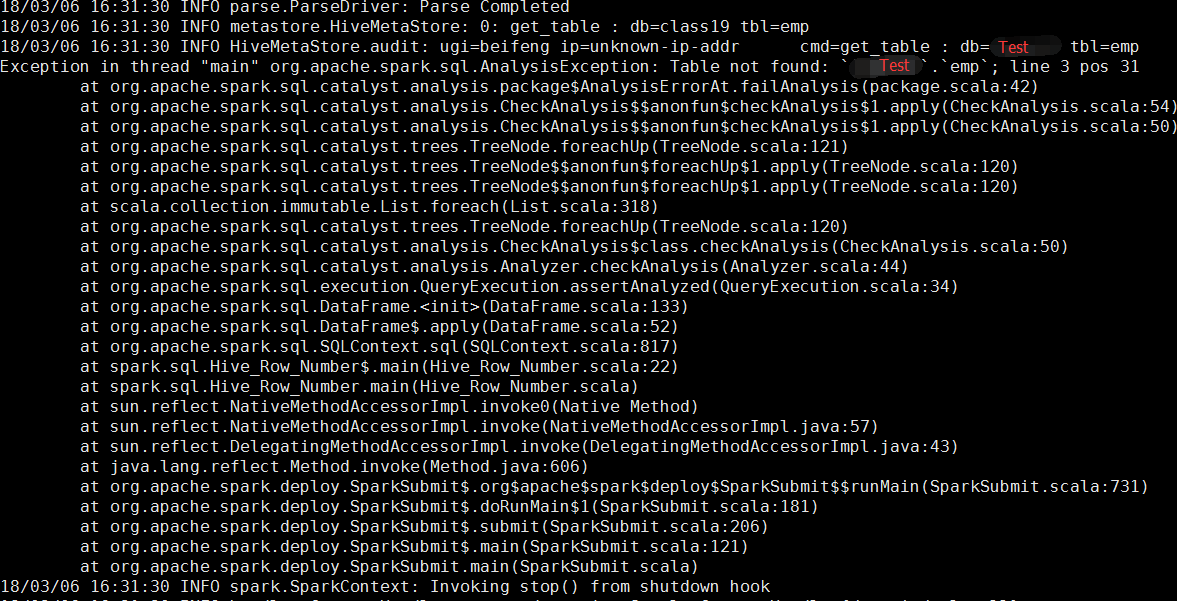
測試二:然後我將spark/conf下面的hive-site.xml刪除,結果再次執行果然報錯了,報的錯是:
這報錯一看就知道,這個sparksql載入的derby,所以找不到我在hive裡面放的那個emp表
測試三:
我嘗試了
第一種:--conf hive.metastore.uris=thrift://bigdata-01:9083
--conf hive.metastore.warehouse.dir=hdfs://bigdata-01:8020/user/class19/warehouse
第二種:--files /spark-1.6.1-bin-2.5.0-cdh5.3.6/conf/a/hive-site.xml
第三種:--properties-file /spark-1.6.1-bin-2.5.0-cdh5.3.6/conf/a/hive-site.xml
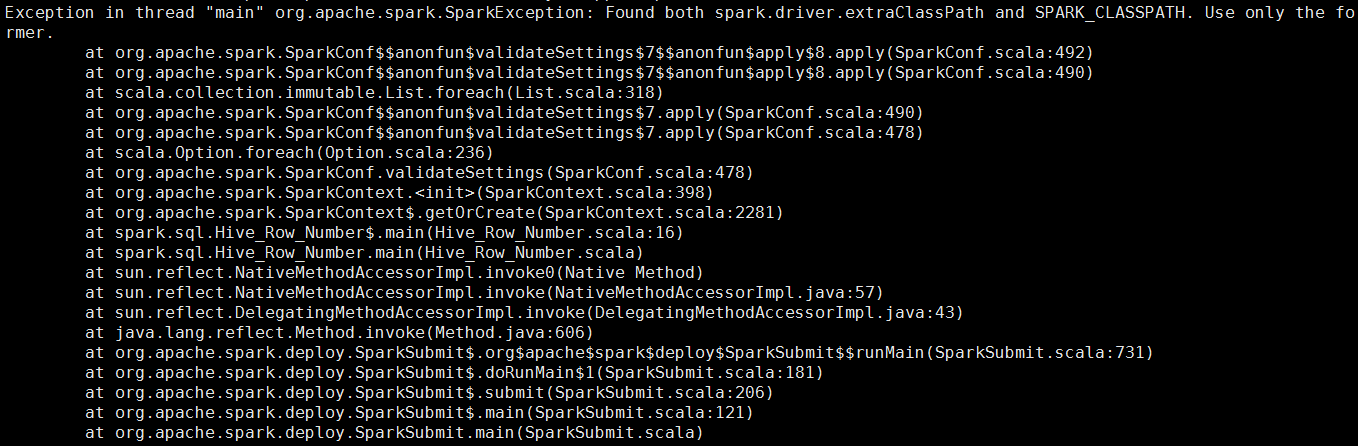
第四種:--driver-class-path /opt/modules/class19/spark-1.6.1-bin-2.5.0-cdh5.3.6/conf/a/hive-site.xml
均不可行,並且第四種,因為--driver-class-path,spark.executor.extraClassPath會和SPARK_CLASSPATH衝突,而報如下的錯:
測試四:使用自帶hive-site.xml的jar包
bin/spark-submit
--master yarn \
--deploy-mode client \
--class spark.sql.Hive_Row_Number \/opt/datas/hive-site_spark.jar
完美執行!
3、yarn-cluster模式
概念:實際專案執行的時候,請使用這種模式,因為這種模式會有資源管理者(resourcemanager)來分配driver開啟在哪一臺機器上,人為是不可控的,因此你也看不到程式執行的時候是否報錯,有什麼回顯資訊。好處就是你不用管當前(提交任務的)機器是否有能力承受大資料量的回顯資訊。standalone叢集也是一樣的。
測試一:使用自帶hive-site.xml的jar包執行
第一種:要麼執行成功(我是成功的)!
第二種:要麼執行會有報錯(這裡就提供報錯解決方案)
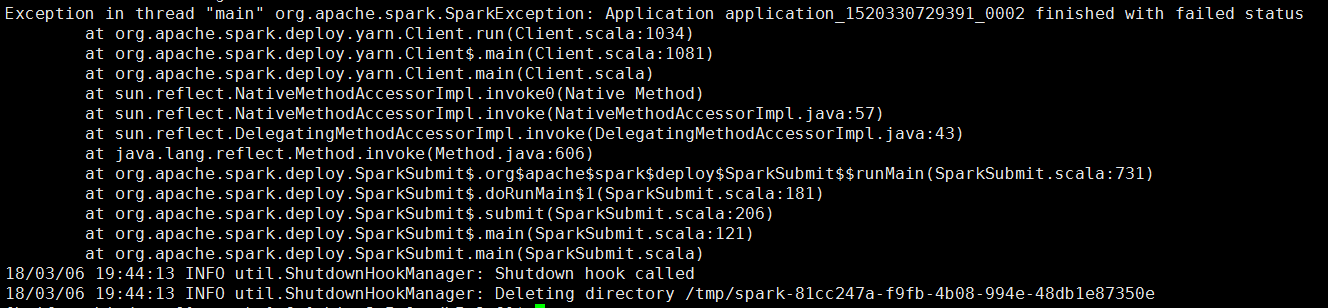
例如:報錯如下
這樣的報錯,估計神仙都看不懂吧。。。
首先,嘗試在yarn的8088頁面上檢視應用的history(前提是historyserver服務已經正常開啟),發現看不了:
報錯如下
Configuration Local logs Server stacks Server metrics java.lang.Exception: Unknown container. Container either has not started or has already completed or doesn't belong to this node at all.
但是其實無所謂,因為如果你的yarn有開啟日誌聚合,那麼肯定有記錄日誌資訊
日誌聚合開啟:在yarn-site.xml裡面配置
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>所以可以嘗試在hadoop中使用:bin/yarn logs -applicationId application_1520330729391_0002
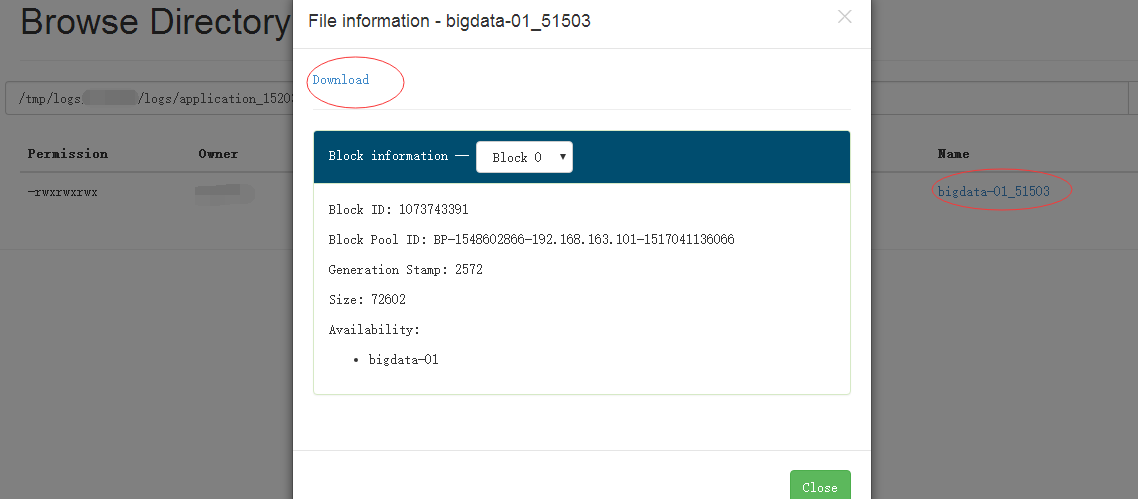
就可以回顯日誌出來,但是有時候日誌太長,有可能就會看不全,因此也可以下載下來,預設是在HDFS的:/tmp/logs/${使用者名稱}/logs下可以找到對應的appid,然後下載下來(別問我怎麼下載的。。。)開啟!就可以看到裡面相關的報錯資訊,一般來說是解決的了。
如何下載看下圖:
好了,到這裡已經把我要說的東西和測試的東西將完了,再提一點:就是實際執行的時候,有幾個引數要考慮清楚!
| --queue QUEUE_NAME | 你所在的小組提交spark任務提交到yarn的哪個佇列中 |
| --driver-cores NUM | driver的核心數,預設為1,不用給多,因為他不處理資料 |
| --driver-memory MEM | driver的記憶體數,預設是1024M就是1G,這個值不用給太大,可以先使用預設的試試,報錯了再增加 |
| --num-executors NUM | executor的總數,executor是實際處理資料的 |
| --executor-cores NUM | 每個executor的核心數,核心數決定了並行數,核心越多,就有越多的task(分割槽)可以一起執行,一般為分割槽數的一半,或者三分之一,如果資源夠,想要加快執行速度,就增加這個值,增加分割槽數 |
| --executor-memory MEM | 每個executor的記憶體數,和上面描述的一樣,記憶體越多,處理越快,越不會報記憶體溢位,理論上是有多少資源給多少 |
| --conf spark.yarn.executor.memoryOverHead=2048 | 特別提下這個引數,是堆外記憶體,堆外記憶體的使用總量 = jvmOverhead(off heap) + directMemoryOverhead(direct memory) + otherMemoryOverhead,部分記憶體溢位的情況,可以嘗試在submit指令碼中增加這個值,轉載一個大神的文章:http://blog.csdn.net/bitcarmanlee/article/details/78793823 |
然後再說說,測試時候遇到的一些報錯和解決方法:
報錯一:java.lang.ClassNotFoundException: org.datanucleus.api.jdo.JDOPersistenceManagerFactory
解決:就是類找不到嘛!有很多方式新增jar包,百度之後,發現這個類是datanucleus-api中的,並且這裡是連線資料庫出的問題,因此我想,hive中應該有這個jar包!
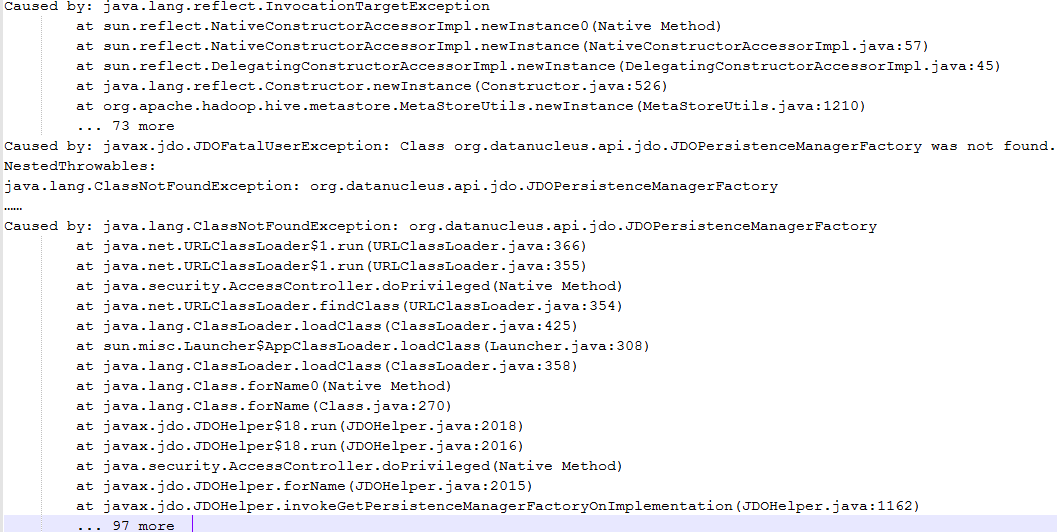
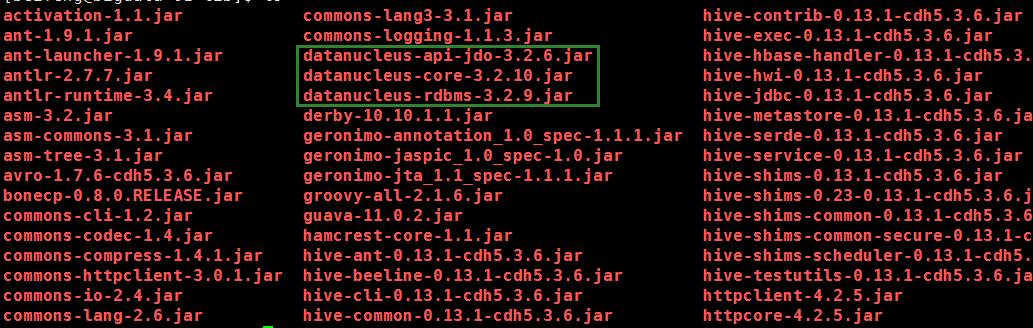
因此我將這幾個jar包直接放入${HADOOP_HOME}/share/hadoop/yarn/lib下,然後問題解決
原因:其實是我執行nohive-site_spark.jar(就是讀取不到hive-site.xml這個配置的jar包),使用yarn-cluster模式的時候,程式碼中建立HiveContext不知道要連線metastore服務,所以他就自己連線derby,但是連線的時候需要datanucleus的這幾個jar中的方法,但是yarn的環境上又沒有,所以報錯了,因此我們可以從解決方法中推斷,yarn-cluster新增jar包可以通過往${HADOOP_HOME}/share/hadoop/yarn/lib目錄下放jar包來解決,並且yarn不用重啟
題外話:我在提交的時候使用--jars和--archives新增jar包,發現都不生效,所以,才使用如上的方法,有可能各自環境不同,理論上應該是有效果的,但是。。。。我這裡就是不行!
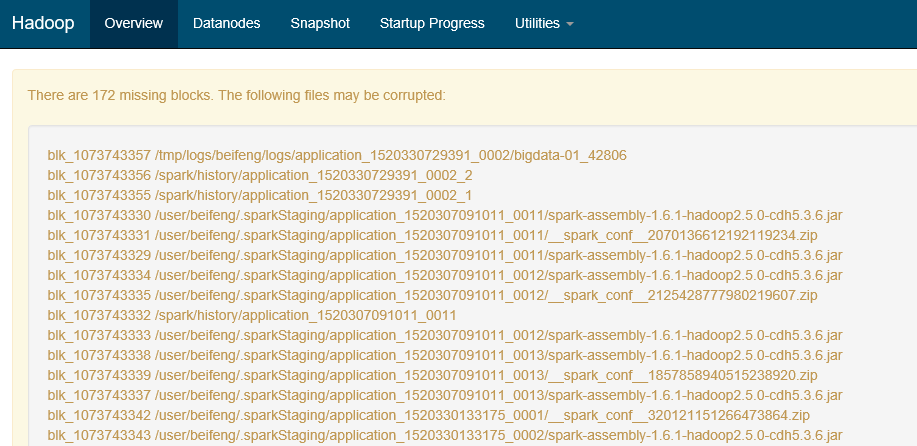
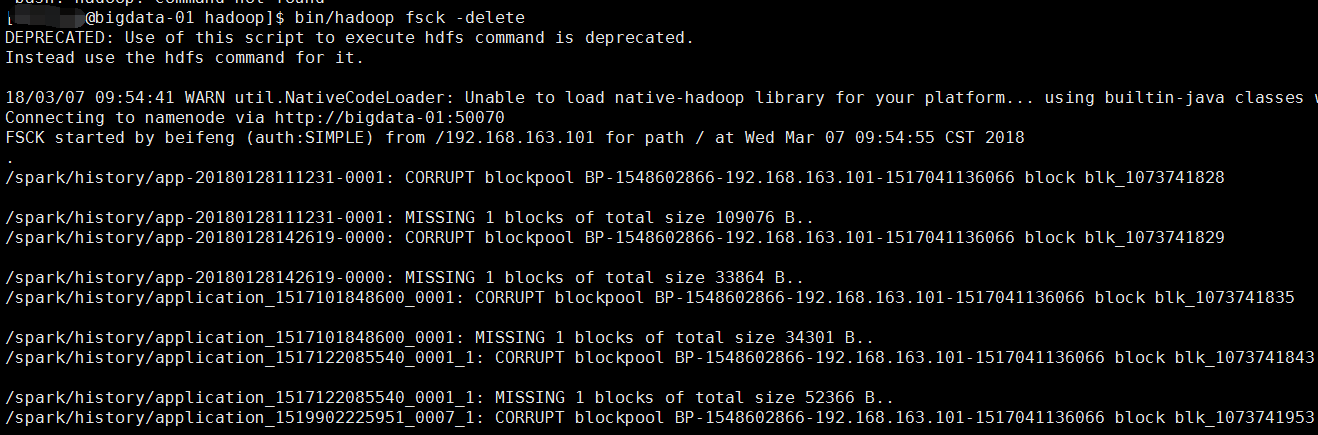
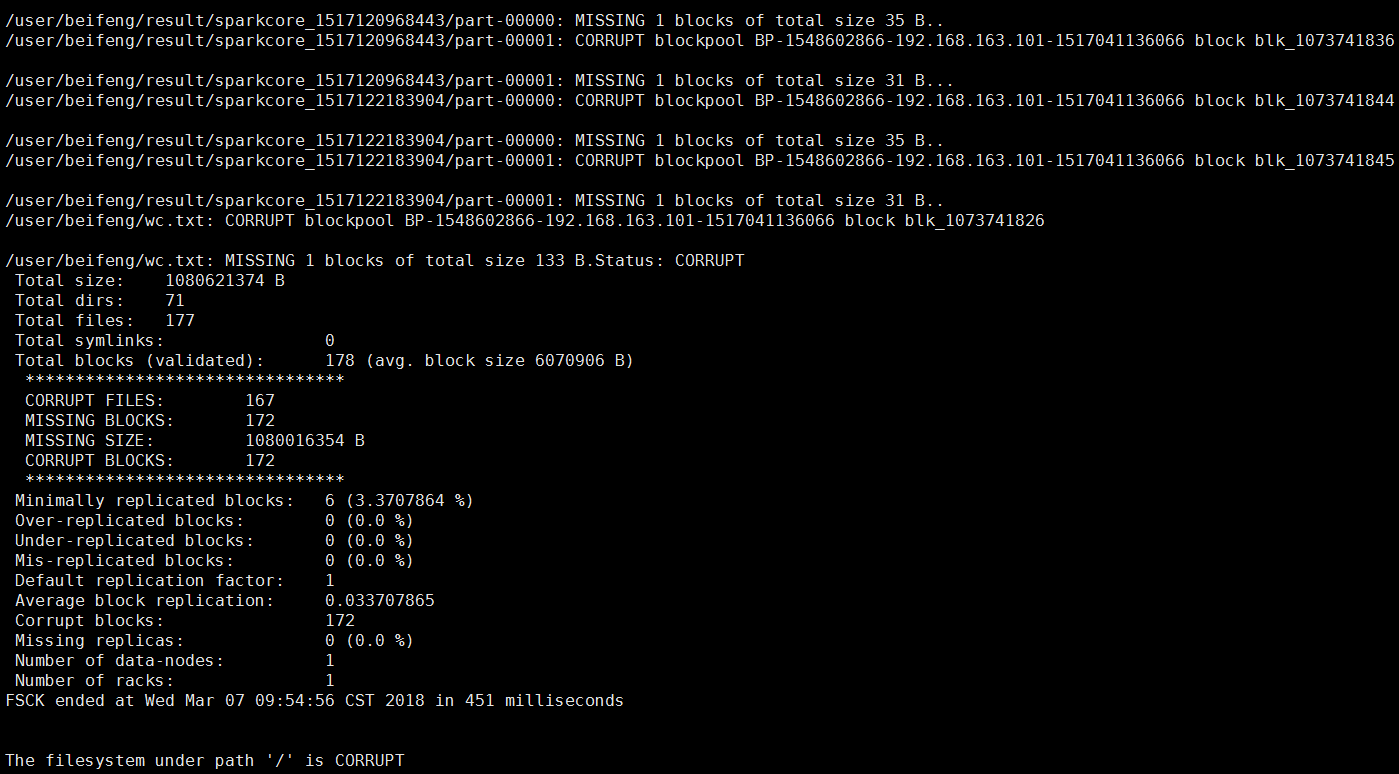
報錯二:Please check the logs or run fsck in order to identify the missing blocks. See the Hadoop FAQ for common causes and potential solutions.
hadoop的50070頁面直接顯示檔案塊丟失
解決:執行 bin/hadoop fsck -delete
原因:因為手賤,刪除了linux上hadoop的檔案快,就是blk_XXXXX
就是hdfs上的資料其實是以這種方式存在linux磁碟上的,因此我刪除了一部分儲存日誌的blk,導致了元資料資訊在,但是資料塊不在了,才報的那個錯,但是這部分資料其實我不需要了,所有就直接把出異常的檔案塊的元資料資訊也刪除就可以了
報錯三:提交spark任務,但是任務執行不了,一直在ACCEPTED狀態
18/03/07 10:46:48 INFO yarn.Client: Application report for application_1520390683689_0001 (state: ACCEPTED)
解決:這種錯誤去看yarn的狀態!就是8088頁面
注意看下你是否有ActiveNodes(正常的nodemanger)來執行job,如果出問題,這個nodemanager就會變成UnhealthyNodes(不健康的節點),程式執行不了,就是沒有一個正常節點了!
然後檢視${HADOOP_HOME}/logs目錄下nodemanager的報錯資訊,我發現了這個:
used space above thresholdof 90.0% (其實挺不好找到的,要仔細找才能看到)
磁碟空間的使用率超過90% ,nodemanager變成不健康的節點;
我的hadoop環境是在根目錄下的,所以就看第一個值,現在是83%,是已經解決了的狀態!
解決:
第一種:增大90%這個閾值,增加到95%
<property>
<name>yarn.nodemanager.disk-health-checker.max-disk-utilization-per-disk-percentage</name>
<value>95.0</value></property>
不過治標不治本
第二種:刪除本地一些沒用的東西,日誌或者什麼安裝包(tar.gz)等等的檔案(這種解決方式比較常見)



第三種:掏錢,加磁碟。。。
最後的最後總結下我曾經使用過,測試過,看到過的新增jar和配置檔案的方法:
注意:下面的幾種選項是否會生效,還要看不同的叢集實際測試結果,執行之後去檢視hadoop的執行日誌(hadoop叢集上要開啟日誌聚合),可以通過bin/yarn logs ${appname},或者可以直接去hdfs上看tmp/yarn/....找你對應applicationname,如果不生效,一般來說就是報某個類找不到,把找不到的類,去百度,看看是在哪個jar中的
1、--jars XXXXX / --package XXXX
2、可以在程式碼當中
conf.setJars("spark應用的jar檔案在當前機器上的路徑"),在要每一臺機器上的相同路徑上放入jars
3、spark on yarn
-1.記得讓spark可以讀取到yarn-site.xml,classpath中新增上hadoop的etc目錄,或者讓spark讀取到yarn-site(讓spark知道resourcemanager在哪裡)
-2.可以把jar包cp到${HADOOP_HOME}/share/hadoop/yarn/lib/
-3.新增完之後,在yarn上執行spark任務的時候會自動去讀取相關的jar包
4、在sparkjar打包的時候,把所有的依賴全部打進去(胖包相對來說就會比較大,可能幾百M)
可以使用assembly,或者使用idea直接build
但是這種模式也有可能遇到問題,jar包衝突,照樣檢視yarn上的執行日誌去確定異常
5、一般來說資原始檔
log4j,hive-site,yarn-site....
這種檔案,佔用磁碟空間很小,所以可以在打成jar包的時候直接新增到jar中,然後就可以讀取到資原始檔
6、在spark-env上新增相關配置(我記得不太一定能夠新增上)SPARK_CLASSPATH=${SPARK_HOME}/external_jars/*