
深度學習線上教育平臺實踐---推薦演算法TensorFlow實現
在前面幾節中,我們向大家介紹了基於深度學習的推薦系統的數學原理,在這一節中,我們討論怎樣使用TensorFlow來實現這些數學原理。我們知道,TensorFlow對於深度學習演算法的實現有很多資料參考,但是我們前面介紹的推薦系統,與一般的深度學習網路有很大的不同,屬於Matrix Factorization的一種,所以在具體實現中,需要對TensorFlow有一個較為深入的瞭解,才能寫出一個較好的解決方案。
我們首先設計個性化題庫類,並進行必要的初始化,如下所示:
import numpy as np
import matplotlib.pyplot as plt
import tensorflow as 我大家能更好的理解數學原理的程式碼實現,我們這裡的資料,就是前面章節數學理論中的資料,共有五道題,兩個知識點,共有5個學生,其中4個學生有做題記錄,第5個學生沒有做題記錄,就是上一節中冷啟動時的情況。
程式的入口是run方法,該方法中,首先讀入我們的試驗資料,然後呼叫train方法訓練模型,然後呼叫predict方法,預測第4個學生對第2道題目的需要程度。
下面我們首先來看試驗資料準備工作,這裡我們為了與前面理論部分一致,我們選擇了在程式中寫死的資料,在實際應用中,這部分資料應該是從資料庫學生做題記錄中讀取出來的。這部分程式碼如下所示:
def load_dataset(self):
ph = np.zeros(shape=(self.nm, self.nu), dtype=np.float32)
r = np.ones(shape=(self.nm, self.nu), dtype=np.int32)
# first row
ph[0][0] = 5.0
r[0][0] = 1
ph[0][1] = 5.0
r[0][1] = 1
ph[0][2] = 0.0
r[0][2] = 1
ph[0][3] = 0.0
r[0][3] = 1
ph[0][4] = -1.0
r[0][4] = 0
# second row
ph[1][0] = 5.0
r[1][0] = 1
ph[1][1] = -1.0
r[1][1] = 0
ph[1][2] = -1.0
r[1][2] = 0
ph[1][3] = 0.0
r[1][3] = 1
ph[1][4] = -1.0
r[1][4] = 0
# third row
ph[2][0] = -1.0
r[2][0] = 0
ph[2][1] = 4.0
r[2][1] = 1
ph[2][2] = 0.0
r[2][2] = 1
ph[2][3] = -1.0
r[2][3] = 0
ph[2][4] = -1.0
r[2][4] = 0
# forth row
ph[3][0] = 0.0
r[3][0] = 1
ph[3][1] = 0.0
r[3][1] = 1
ph[3][2] = 5.0
r[3][2] = 1
ph[3][3] = 4.0
r[3][3] = 1
ph[3][4] = -1.0
r[3][4] = 0
# fifth row
ph[4][0] = 0.0
r[4][0] = 1
ph[4][1] = 0.0
r[4][1] = 1
ph[4][2] = 5.0
r[4][2] = 1
ph[4][3] = 0.0
r[4][3] = 1
ph[4][4] = -1.0
r[4][4] = 0
# 求出mu(因為僅統計大於等於零項,所以不能用tf.reduce_mean函式)
mu = np.zeros(shape=(self.nm, 1))
for row in range(self.nm):
sum = 0.0
num = 0
for col in range(self.nu):
if 1 == r[row][col]:
sum += ph[row][col]
num += 1
mu[row][0] = sum / num
print('mu={0}!'.format(mu))
print('ph={0}!'.format(ph))
self.refine_ph(ph, mu)
ph = ph - mu
print('ph={0}!'.format(ph))
return ph, r, mu
def refine_ph(self, ph, mu):
for row in range(self.nm):
for col in range(self.nu):
if ph[row][col] < 0.0:
ph[row][col] = mu[row][0]在這段程式中有幾點需要注意的地方,我們用ph表儲存前面章節中表格中的資料,r用來儲存學生是否做過某道題目,mu表示均值向量。這裡需要特別注意的是,我們在求均值向量mu時,我們不能直接用TensorFlow的內建函式tf.reduce_mean,因為我們只統計學生已經做過的題目,而不統計沒有做過的題目。最後就是refine_ph函式,我們將所有學生未做過的題目,全部設定為相應的均值。
下面我們來看訓練方法:
def calDeltaY(self, Y, Y_):
sum = 0.0
for row in range(self.nm):
for col in range(self.nu):
if 1 == self.r[row][col]:
sum += (Y[row][col] - Y_[row][col])*(Y[row][col] - Y_[row][col])
return sum
def build_model(self):
print('build model')
self.Y_ = tf.placeholder(shape=[self.nm, self.nu], dtype=tf.float32, name='Y_')
self.X = tf.Variable(tf.truncated_normal(shape=[self.nm, self.n], mean=0.0, stddev=0.01, seed=1.0), dtype=tf.float32, name='X')
self.UT = tf.Variable(tf.truncated_normal(shape=[self.n, self.nu], mean=0.0, stddev=0.01, seed=1.0), dtype=tf.float32, name='X')
self.Y = tf.matmul(self.X, self.UT)
self.L = self.calDeltaY(self.Y, self.Y_) #tf.reduce_sum((self.Y - self.Y_)*(self.Y - self.Y_))
self.J = self.L + self.lanmeda*tf.reduce_sum(self.X**2) + self.lanmeda*tf.reduce_sum(self.UT**2)
self.train_step = tf.train.AdamOptimizer(learning_rate=0.001, beta1=0.9,
beta2=0.999, epsilon=1e-08, use_locking=False,
name='Adam').minimize(self.J)
def train(self):
self.build_model()
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for epoch in range(self.epochs):
X, UT, Y, J, train_step = sess.run([self.X, self.UT, self.Y, self.J, self.train_step], feed_dict={self.Y_: self.Y_ph})
#print(Y)
print('{0}:{1}'.format(epoch, J))
self.Xv = X
self.UTv = UT在訓練方法中,我們首先呼叫build_model來建立模型。所以我們先來看這個方法。我們先把當前我們通過學生做題情況得到的學習對題目的需要資訊,儲存到self.Y_中。接下來的處理就與普通深度學習網路不同了,因為我們這裡題目和學生向量都是變數,都需要通過梯度下降演算法進行優化,所以我們將題目向量self.X和學生向量self.UT都設定為變數,並用均值為0,標準差為0.01的高斯分佈隨機數進行初始化。我們計算在當前引數情況下,學生對每道題目需求程度的計算值self.Y,我們定義學生對每道題目需求程度的計算值與學生對每道題目需求程度的真實需求值之差為損失函式self.L,我們在損失函式的基礎上,新增調整項後,作為最終的代價函式,最後我們選用AdamOptimizer對代價函式進行優化,求出其最小值。
在上面需要注意的是在求self.L時,因為我們只對學生做過的題目進行計算,不處理未做過的題目,所以不能直接使用tf.reduce_sum((self.Y - self.Y_)*(self.Y - self.Y_))來計算,而是需要呼叫calDeltaY方法來計算。
接下來我們啟動TensorFlow的Session,開始進行訓練,在每一步中,首先根據現有學生向量self.UT和題目向量self.X,計算出對每道題目的需要程度計算值,求出與實際的差距,根據Adam優化隨機梯度下降演算法,調整學生向量self.UT和題目向量self.X,最後使對每道題目的需要程度計算值與實際值的差最小,將最終的題目向量儲存到self.Xv,最終的學生向量儲存到self.UTv中。
當模型訓練完成後,就可以來預測學生對題目的需要程度了,程式碼如下所示:
def predict(self, ui, xi):
print(self.Xv[xi])
Uv = np.transpose(self.UTv)
print(Uv[ui])
print(np.dot(self.Xv[xi], Uv[ui]) + self.mu[xi][0])
for row in range(self.nm):
for col in range(self.nu):
print(' {0} '.format(np.dot(self.Xv[row], Uv[col]) + self.mu[row][0]))
print('\r\n')執行上面的程式,可以得到如下結果:
均值計算結果
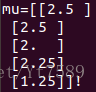
學生對每道題目需要程度的實際值:
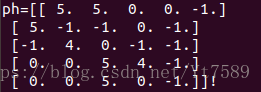
圖中-1代表前面章節表格中的問號,代表學生沒有做過這些題。
為了解決冷啟動問題,對上述資料進行均值化後的結果:
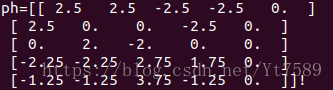
最後學完的題目向量和學生向量,以及學生4對題目2需要程度的預測值:
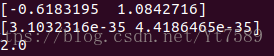
我們求出學生對題目的需要程度:
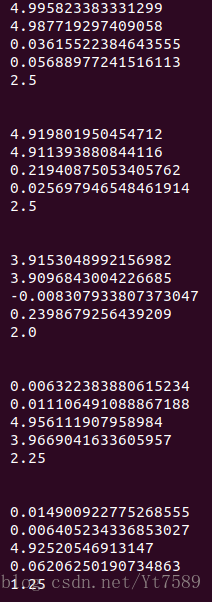
圖中的每一塊代表之前表格中的一行,由上圖可以看出,我們計算出來的需要程度,與實際需要程度還是非常接近的,這從一個側面證明了我們演算法實現是正確的。
通過這5篇文章,讀者對基於深度學習的推薦系統,相信已經有了一個清晰的瞭解,可以根據自己專案的實際情況,來定製化不同的系統了。
最後還要說的一點就是,我們在這裡採用的是Matrix Factorization方法,實際上我們可以把上面的演算法轉換成標準的神經網路形式,變成一個基於神經網路的迴歸問題,在實際應用中,採用神經網路形式,在很多情況下,結果還是會優於Matrix Factorization的。讀者可以想想怎麼來實現。我在這裡給大家一個提示,就是輸入層為學生數量的one-hot矩陣,隱藏層為學生向量的維數,輸出層為題目總數。在這裡我就不詳細展開了,請大家自己動手來實現。