
實驗三 無損資料壓縮編解碼實驗(Huffman編解碼)
~每一步中很多程式碼的註釋都是跟著上一句寫的,可以把註釋連起來看~
一、實驗原理
1. Huffman編碼步驟
(1)統計各個符號(把檔案的一個位元組看成一個符號)在檔案中出現的概率,按照出現概率從小到大排序。
(2)每一次選出概率最小的兩個符號作為二叉樹的葉節點,合併兩個葉節點的概率,合併後的節點作為它們的父節點,直至合併到根節點。
(3)二叉樹的左節點為0,右節點為1,從上到下由根節點到葉節點得到每個葉節點的編碼。
因此,將節點和碼字的資料型別定義如下
typedef struct huffman_node_tag //節點資料型別
{
unsigned 2. 靜態連結庫的使用
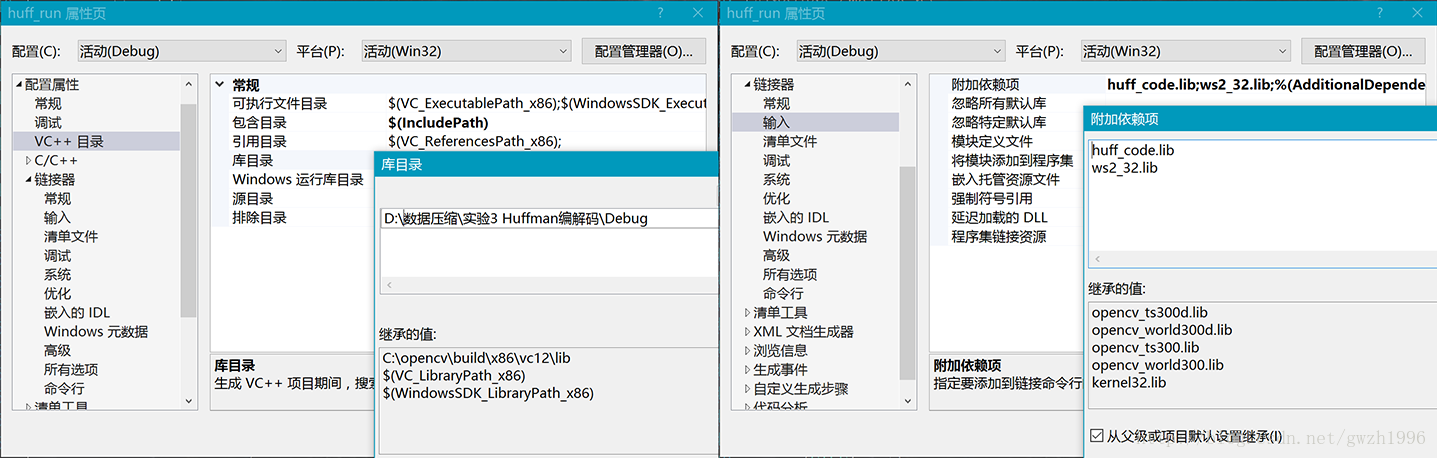
本實驗由兩個專案組成,第一個專案為 Huffman 編碼的具體實現,名為 huff_code,建立專案時選擇的是靜態庫,生成一個 .lib 檔案。第二個專案 huff_run 只需要包含這個庫即可呼叫其中的編碼函式,後面的其它實驗也要用到這個庫。專案屬性需要配置庫目錄屬性,也就是第一個專案生成檔案的路徑,和附加依賴性屬性,也就是庫的名稱,如圖 1 所示。由於程式碼中用到了位元組序轉換的函式 htonl、ntohl,附加依賴項還需包含 ws2_32.lib。
二、實驗流程及程式碼分析
1. Huffman編碼流程
(1)讀取檔案
//--------huffcode.c--------
...
static void usage(FILE* out){ //命令列引數格式
fputs("Usage: huffcode [-i<input file>] [-o<output file>] [-d|-c]\n" "..." , out);
}
//————————————————————————————————————————————————————————
int main(int argc, char** argv)
{
char memory = 0; //memory表示是否對記憶體資料進行操作
char compress = 1; //compress為1表示編碼,0表示解碼
const char *file_in = NULL, *file_out = NULL;
FILE *in = stdin, *out = stdout;
while((opt = getopt(argc, argv, "i:o:cdhvm")) != -1){ //讀取命令列引數的選項
switch(opt){
case 'i': file_in = optarg; break; // i 為輸入檔案
case 'o': file_out = optarg; break; // o 為輸出檔案
case 'c': compress = 1; break; // c 為壓縮操作
case 'd': compress = 0; break; // d 為解壓縮操作
case 'h': usage(stdout); system("pause"); return 0; // h 為輸出引數用法說明
case 'v': version(stdout); system("pause"); return 0; // v 為輸出版本號資訊
case 'm': memory = 1; break; // m 為對記憶體資料進行編碼
default: usage(stderr); system("pause"); return 1;
}
}
if(file_in){ //讀取輸入輸出檔案等
in = fopen(file_in, "rb"); if(!in)...
}
...
if(memory) //對記憶體資料進行編碼或解碼操作
return compress ?memory_encode_file(in, out) : memory_decode_file(in, out);
//還是對檔案資料進行編碼或解碼操作
return compress ?huffman_encode_file(in, out) : huffman_decode_file(in, out);
} 使用庫函式中的getopt解析命令列引數,這個函式的前兩個引數為main中的argc和argv,第三個引數為單個字元組成的字串,每個字元表示不同的選項,單個字元後接一個冒號,表示該選項後必須跟一個引數。
下面先分析對檔案的編碼流程,之後是其中具體實現各種操作的函式。
//--------huffman.c--------
...
//最大符號數目,由於一個位元組一個位元組進行編碼,因此為256
#define MAX_SYMBOLS 256
typedef huffman_node* SymbolFrequencies[MAX_SYMBOLS]; //信源符號陣列,資料型別為之前定義過的樹節點型別
typedef huffman_code* SymbolEncoder[MAX_SYMBOLS]; //編碼後的碼字陣列,資料型別為之前定義過的碼字型別
//————————————————————————————————————————————————————————
int huffman_encode_file(FILE *in, FILE *out) //對檔案進行Huffman編碼的函式
{
SymbolFrequencies sf;
SymbolEncoder *se;
huffman_node *root = NULL;
unsigned int symbol_count = get_symbol_frequencies(&sf, in); //第一遍掃描檔案,得到檔案中各位元組的出現頻率
se = calculate_huffman_codes(&sf); //再根據得到的符號頻率建立一棵Huffman樹,還有Huffman碼錶
root = sf[0]; //編完碼錶後,Huffman樹的根節點為 sf[0],具體原因在後面的分析
rewind(in); //回到檔案開頭,準備第二遍掃描檔案
int rc = write_code_table(out, se, symbol_count); //先在輸出檔案中寫入碼錶
if(rc == 0) rc = do_file_encode(in, out, se); //寫完碼錶後對檔案位元組按照碼錶進行編碼
free_huffman_tree(root); free_encoder(se);
return rc;
}(2)統計各位元組出現的頻率
static unsigned int get_symbol_frequencies(SymbolFrequencies *pSF, FILE *in) //統計中各位元組出現頻率的函式
{
int c; unsigned int total_count = 0;
memset(*pSF, 0, sizeof(SymbolFrequencies)); //首先把所有符號的頻率設為0
while((c = fgetc(in)) != EOF) //然後讀每一個位元組,把一個位元組看成一個信源符號,直到檔案結束
{
unsigned char uc = c;
if(!(*pSF)[uc]) //如果還沒有在數組裡建立當前符號的資訊
(*pSF)[uc] = new_leaf_node(uc); //那麼把這個符號設為一個葉節點
++(*pSF)[uc]->count; //如果已經是一個葉節點了或者葉節點剛剛建立,符號數目都+1
++total_count; //總位元組數+1
}
return total_count;
}
//————————————————————————————————————————————————————————
static huffman_node* new_leaf_node(unsigned char symbol) //建立一個葉節點的函式
{
huffman_node *p = (huffman_node*)malloc(sizeof(huffman_node)); //分配一個葉節點的儲存空間
p->isLeaf = 1; //表明當前節點為葉節點
p->symbol = symbol; //節點儲存的信源符號
p->count = 0; //信源符號數目設為0
p->parent = 0; //父節點為空
return p;
}(3)建立碼樹
static SymbolEncoder* calculate_huffman_codes(SymbolFrequencies * pSF) //建立一棵Huffman樹的函式
{
unsigned int i = 0, n = 0;
huffman_node *m1 = NULL, *m2 = NULL;
SymbolEncoder *pSE = NULL;
qsort((*pSF), MAX_SYMBOLS, sizeof((*pSF)[0]), SFComp); //先使用自定義的順序對出現次數進行排序,使得下標為0的元素的count最小
for(n = 0; n < MAX_SYMBOLS && (*pSF)[n]; ++n); //統計下信源符號的真實種類數,因為一個檔案中不一定256種位元組都會出現
for(i = 0; i < n - 1; ++i)
{
//把出現次數最少的兩個信源符號節點設為 m1,m2
m1 = (*pSF)[0];
m2 = (*pSF)[1];
//然後合併這兩個符號,把合併後的新節點設為這兩個節點的父節點
(*pSF)[0] = m1->parent = m2->parent = new_nonleaf_node(m1->count + m2->count, m1, m2);
(*pSF)[1] = NULL; //合併之後,第二個節點為空
qsort((*pSF), n, sizeof((*pSF)[0]), SFComp); //然後再排一遍序
}
//樹構造完成後,為碼字陣列分配記憶體空間並初始化
pSE = (SymbolEncoder*)malloc(sizeof(SymbolEncoder));
memset(pSE, 0, sizeof(SymbolEncoder));
build_symbol_encoder((*pSF)[0], pSE); //從樹根開始,為每個符號構建碼字
return pSE;
}
//————————————————————————————————————————————————————————
static int SFComp(const void *p1, const void *p2) //自定義的排序順序函式,把節點陣列由小到大排序
{
//把兩個排序元素設為自定義的樹節點型別
const huffman_node *hn1 = *(const huffman_node**)p1;
const huffman_node *hn2 = *(const huffman_node**)p2;
if(hn1 == NULL && hn2 == NULL) return 0; //如果兩個節點都空,返回相等
if(hn1 == NULL) return 1; //如果第一個節點為空,則第二個節點大
if(hn2 == NULL) return -1; //反之第二個節點小
//如果都不空,則比較兩個節點中的計數屬性值,然後同上返回比較結果
if(hn1->count > hn2->count) return 1;
else if(hn1->count < hn2->count) return -1;
return 0;
}
//————————————————————————————————————————————————————————
static huffman_node* new_nonleaf_node(unsigned long count, huffman_node *zero, huffman_node *one) //建立一個內部節點的函式
{
huffman_node *p = (huffman_node*)malloc(sizeof(huffman_node)); //分配一個節點的儲存空間
p->isLeaf = 0; //內部節點,不是葉節點
//根據引數,設定這個節點的符號數和左右子節點
p->count = count; p->zero = zero; p->one = one;
p->parent = 0; //父節點設為空
return p;
} qsort為標準庫中自帶的快速排序函式,引數為 <待排序陣列> <陣列元素個數> <元素的大小> <自定義比較陣列元素的函式>。
臨時變數 m1,m2 不斷地設為信源符號陣列中出現次數最少的兩個元素,陣列第一個元素一直是出現次數最小的兩個符號的合併,這樣迴圈結束後,pSF 陣列中所有元素除第一個 pSF[0] 以外都空,而這些新建立的節點分佈在記憶體中各個角落,通過節點屬性中的左右兩個子節點指標指向各自的子節點,構建出一棵二叉樹結構,把這些節點連在一起,pSF[0] 就是這棵樹的根節點。因此如果要遍歷這棵樹,只要 pSF[0] 就夠了。
(4)生成碼字
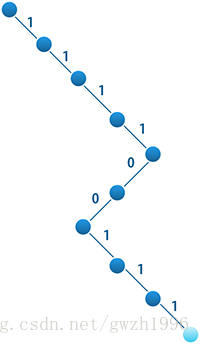
這個實驗裡碼字的編制比較麻煩,原因在於碼字陣列中的一個元素為 unsigned char 型別,一個元素儲存了 8 位的碼字,一個碼字中的一位(0或1)在儲存時確實只佔用了 1 bit。 假如有一個葉節點在樹中的位置如圖 2 所示(淺藍色節點),那麼按照編碼規則碼字應該從根到葉編碼,為 111100111。


static void build_symbol_encoder(huffman_node *subtree, SymbolEncoder *pSE) //遍歷碼樹的函式
{
if(subtree == NULL) return; //如果是空樹,返回
if(subtree->isLeaf) //如果是葉節點,則對葉節點進行編碼
(*pSE)[subtree->symbol] = new_code(subtree);
else //如果都不是,那麼先訪問左節點,到了葉節點之後再訪問右節點
{
build_symbol_encoder(subtree->zero, pSE);
build_symbol_encoder(subtree->one, pSE);
}
}
//————————————————————————————————————————————————————————
static huffman_code* new_code(const huffman_node* leaf) //生成碼字的函式
{
//碼字的位數 numbits,也就是樹從下到上的第幾層,還有儲存碼字的陣列 bits
unsigned long numbits = 0;
unsigned char* bits = NULL;
while(leaf && leaf->parent) //如果還沒到根節點
{
//那麼得到當前節點的父節點,由碼字位數得到碼字在位元組中的位置和碼字的位元組數
huffman_node *parent = leaf->parent;
unsigned char cur_bit = (unsigned char)(numbits % 8);
unsigned long cur_byte = numbits / 8;
if(cur_bit == 0) //如果位元位數為0,說明到了下一個位元組,新建一個位元組儲存後面的碼字
{
size_t newSize = cur_byte + 1; //新的位元組數為當前位元組數+1,size_t 即為 unsigned int 型別
bits = (char*)realloc(bits, newSize); //陣列按照新的位元組數重新分配空間
bits[newSize - 1] = 0; //並把新增加的位元組設為0
}
if(leaf == parent->one) //如果是右子節點,按照Huffman樹左0右1的原則,應當把當前位元組中當前位置1
//先把1右移到當前位(cur_bit)位置,再把當前位元組(bits[cur_byte])與移位後的1做或操作
bits[cur_byte] |= 1 << cur_bit;
++numbits; //然後碼字的位數加1
leaf = parent; //下一位碼字在父節點所在的那一層
}
//回到根之後編碼完畢,對碼字進行倒序
if(bits)
reverse_bits(bits, numbits);
//倒序後,輸出碼字陣列
huffman_code *p = (huffman_code*)malloc(sizeof(huffman_code));
p->numbits = numbits; p->bits = bits;
return p;
}
//————————————————————————————————————————————————————————
static void reverse_bits(unsigned char* bits, unsigned long numbits) //對碼字進行倒序的函式
{
//先判斷碼字最多需要多少個位元組儲存
unsigned long numbytes = numbytes_from_numbits(numbits);
//分配位元組數所需的儲存空間,還有當前位元組數和位元位數
unsigned char *tmp = (unsigned char*)alloca(numbytes);
unsigned long curbit;
long curbyte = 0;
memset(tmp, 0, numbytes);
for(curbit = 0; curbit < numbits; ++curbit)
{
//判斷當前位是位元組裡的哪一位,到了下一個位元組,位元組數+1
unsigned int bitpos = curbit % 8;
if(curbit > 0 && curbit % 8 == 0) ++curbyte;
//從後往前取碼字中的每一位,再移位到所在位元組的正確位置
tmp[curbyte] |= (get_bit(bits, numbits - curbit - 1) << bitpos);
}
memcpy(bits, tmp, numbytes);
}
//由位元位長度得到位元組數。除以8取整,如果還有餘數說明要再加一個位元組
static unsigned long numbytes_from_numbits(unsigned long numbits)
{ return numbits / 8 + (numbits % 8 ? 1 : 0); }
/* 取出碼字 bits 中的第 i 位
第 i 位在第 i/8 位元組的第 i%8 位,把這一位移到位元組最低位處,和 0000 0001 做與操作,從而只留下這一位,返回*/
static unsigned char get_bit(unsigned char* bits, unsigned long i)
{ return (bits[i / 8] >> i % 8) & 1; } 遍歷碼樹時,先一直向下訪問到葉節點中的左子節點,再回到根,再訪問葉節點中的右子節點,pSE 的下標就是待編碼的信源符號。
碼字由陣列 bits 儲存,陣列的一個元素有 8 位(一個位元組),因此定義了 cur_bit 和 cur_byte 兩個變數,用於標識當前的一位碼字在 bits 中的位元組位置和位元組裡的位位置。預設情況下碼字陣列 bits 全為 0,需要置 1 的情況就和 1 進行或操作把某些位元位置 1。
(5)寫入碼錶,對檔案進行編碼
static int write_code_table(FILE* out, SymbolEncoder *se, unsigned int symbol_count) //寫入碼錶的函式
{
unsigned long i, count = 0;
//還是要先統計下真實的碼字種類,不一定256種都有
for(i = 0; i < MAX_SYMBOLS; ++i)
if((*se)[i]) ++count;
//把位元組種類數和位元組總數變成大端儲存的形式,寫入檔案中
i = htonl(count);
if(fwrite(&i, sizeof(i), 1, out) != 1) return 1;
symbol_count = htonl(symbol_count);
if(fwrite(&symbol_count, sizeof(symbol_count), 1, out) != 1) return 1;
//然後開始寫入碼錶
for(i = 0; i < MAX_SYMBOLS; ++i)
{
huffman_code *p = (*se)[i];
if(p)
{
fputc((unsigned char)i, out); //碼錶中有三種資料,先寫入位元組符號
fputc(p->numbits, out); //再寫入碼長
//最後得到位元組數,寫入碼字
unsigned int numbytes = numbytes_from_numbits(p->numbits);
if(fwrite(p->bits, 1, numbytes, out) != numbytes) return 1;
}
}
return 0;
} 在檔案中寫入位元組種類數和位元組數時,系統按照小端方式寫入,比如 256(100H) 寫入後變為 00 01 00 00。為了在檔案中能從左到右直接讀出真實資料(圖 3),這裡先把它們變成了大端方式儲存再寫入檔案,在解碼時還要做一次轉換。經過上述處理後,編碼後的檔案結構如圖 3 所示
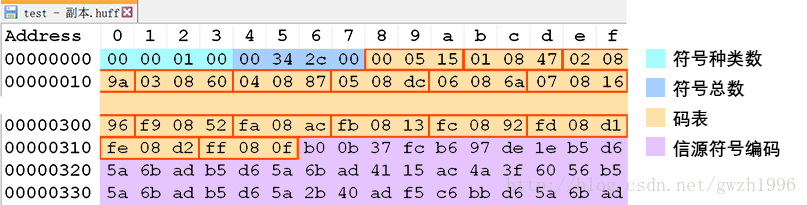
static int do_file_encode(FILE* in, FILE* out, SymbolEncoder *se) //對檔案符號進行編碼的函式
{
unsigned char curbyte = 0;
unsigned char curbit = 0;
int c;
while((c = fgetc(in)) != EOF)
{
//逐位元組讀取待編碼的檔案,要找到當前符號(位元組)uc對應的碼字code,只需要把uc作為碼字陣列se的下標即可
unsigned char uc = (unsigned char)c;
huffman_code *code = (*se)[uc];
unsigned long i;
for(i = 0; i < code->numbits; ++i)
{
//把碼字中的一個位元位放到編碼位元組的相應位置
curbyte |= get_bit(code->bits, i) << curbit;
//每次寫入一個位元組
if(++curbit == 8){
fputc(curbyte, out);
curbyte = 0; curbit = 0;
}
}
}
//處理一下最後一個位元組的編碼不足一位元組的情況
if(curbit > 0) fputc(curbyte, out);
return 0;
}對檔案進行編碼時,一個位元組一個位元組地讀檔案,把位元組作為信源符號,查詢碼字陣列得到碼字。寫檔案也是一個位元組一個位元組寫,有時候一些碼字可能不足一個位元組或超過一個位元組(8位碼字),那麼就等到下一個符號的編碼,直到湊足一個位元組的長度再寫入檔案。因此編碼後的資料中一個位元組可能包含有原來檔案的多個符號(位元組),從而達到了資料壓縮的目的。
2. Huffman解碼流程
(1)讀取碼錶
static huffman_node* read_code_table(FILE* in, unsigned int *pDataBytes)
{
huffman_node *root = new_nonleaf_node(0, NULL, NULL);
unsigned int count;
//讀檔案和寫檔案一樣,按照小端方式讀
if(fread(&count, sizeof(count), 1, in) != 1{
free_huffman_tree(root); return NULL;
}
//所以按照大端方式存放的資料count,再轉換一次就得到了正確結果
count = ntohl(count);
//原檔案的總位元組數pDataBytes同理
if(fread(pDataBytes, sizeof(*pDataBytes), 1, in) != 1){
free_huffman_tree(root); return NULL;
}
*pDataBytes = ntohl(*pDataBytes);
//————————————————————————————————————————————————————————
while(count-- > 0) //讀完這些後,檔案指標指向了碼錶開頭,依次讀取碼錶中的每一項,每一項由符號,碼長,碼字三種資料組成
{
int c;
unsigned int curbit;
unsigned char symbol, numbits, numbytes;
unsigned char *bytes;
huffman_node *p = root;
if((c = fgetc(in)) == EOF) //一次讀一個位元組,第一個位元組是信源符號symbol
{
free_huffman_tree(root); return NULL;
}
symbol = (unsigned char)c;
if((c = fgetc(in)) == EOF) //第二個位元組是碼長資料numbits
{
free_huffman_tree(root); return NULL;
}
numbits = (unsigned char)c;
//計算出這樣一個碼長需要多少個位元組(numbytes個)儲存,開闢與位元組數對應的空間
numbytes = (unsigned char)numbytes_from_numbits(numbits);
bytes = (unsigned char*)malloc(numbytes);
if(fread(bytes, 1, numbytes, in) != numbytes) //然後讀取numbytes個位元組得到碼字bytes
{
free(bytes); free_huffman_tree(root); return NULL;
}
//————————————————————————————————————————————————————————
for(curbit = 0; curbit < numbits; ++curbit) //讀完碼錶一項三種資料後,開始由碼字建立Huffman樹
{
if(get_bit(bytes, curbit)) //如果碼字中的當前位為1
{
if(p->one == NULL) //那麼應該建立一個右子節點(如果沒有的話)
{
//如果讀到了最後一位,那麼新建一個葉節點,否則建立一個內部節點
p->one = curbit == (unsigned char)(numbits - 1)
? new_leaf_node(symbol)
: new_nonleaf_node(0, NULL, NULL);
p->one->parent = p; //設定好新建節點的父節點
}
p = p->one; //不管右子節點是不是新建的,都要把這個節點當成父節點,以便建立它後續的子節點
}
else //如果碼字中的當前位為0
{
if(p->zero == NULL) //那麼應該建立一個左子節點(如果沒有的話)
{
//同理,選擇節點型別並確定節點之間的關係
p->zero = curbit == (unsigned char)(numbits - 1)
? new_leaf_node(symbol)
: new_nonleaf_node(0, NULL, NULL);
p->zero->parent = p;
}
p = p->zero;
}
}
free(bytes);
}
return root; //和編碼一樣,只要有最上面的根節點就能遍歷整棵樹
}
(2)根據碼樹進行解碼
int huffman_decode_file(FILE *in, FILE *out) //Huffman解碼函式
{
huffman_node *root, *p; int c;
unsigned int data_count;
root = read_code_table(in, &data_count); //開啟檔案後首先讀入碼錶,建立Huffman樹,並且獲取原檔案的位元組數
if(!root) return 1;
p = root;
while(data_count > 0 && (c = fgetc(in)) != EOF) //準備好碼樹之後,一次讀一個位元組進行解碼
{
unsigned char byte = (unsigned char)c;
unsigned char mask = 1;
//mask負責提取位元組中的每一位,提取完之後向左移動一位來提取下一位。因此移動8位之後變成0,迴圈退出,讀下一個位元組
while(data_count > 0 && mask)
{
//如果當前位元組為0,就轉到左子樹,否則轉到右子樹
p = byte & mask ? p->one : p->zero;
mask <<= 1; //準備讀下一個位元組
if(p->isLeaf) //如果走到了葉節點
{
fputc(p->symbol, out); //就輸出葉節點中儲存的符號
p = root; //然後轉到根節點,再從頭讀下一個碼字
--data_count; //而且剩下沒解碼的符號數-1
}
}
}
free_huffman_tree(root);
return 0;
}3. 對記憶體資料的Huffman編解碼
(建設中。。。)
三、實驗結果與總結
實驗中需要新增程式碼將編碼結果列表輸出,輸出列表主要包含四項:信源符號,符號頻率(或出現次數),符號的碼字長度,碼字。信源符號可以通過陣列下標得到,信源符號出現的次數在節點資料型別中,碼字和字長在碼字資料型別中。為了方便,重新定義瞭如下的結構,一起儲存這三項資料:
typedef struct huffman_stat_tag //信源符號的統計資料型別
{
unsigned long numbits; //碼字長度
unsigned char *bits; //碼字
double freq; //信源符號出現的頻率
}huffman_stat;
typedef huffman_stat* SymbolStatices[MAX_SYMBOLS];在命令列引數中需要再多加一個引數來指定輸出的文字檔案,新增命令列引數方法在讀入編碼檔案部分分析過。
void getStatFreq(SymbolStatices* stat, SymbolFrequencies* sf, unsigned int symbol_count) //由信源符號陣列得到出現頻率的函式
{
unsigned int i;
for (i = 0; i < MAX_SYMBOLS; i++)
(*stat)[i] = (huffman_stat*)malloc(sizeof(huffman_stat)); //把統計陣列信源符號的每個位置分配一塊空間
for (i = 0; i < MAX_SYMBOLS; i++)
{
if ((*sf)[i]) //如果符號陣列當前元素不為空
{
unsigned int j = (*sf)[i]->symbol; //那麼得到當前元素儲存的信源符號
(*stat)[j]->freq = (double)(*sf)[i]->count / symbol_count; //把符號作為下標,對 freq 賦值
}
}
for (i = 0; i < MAX_SYMBOLS; i++)
{
if (!(*sf)[i]) //找到那些信源符號為空的陣列
(*stat)[i]->freq = 0; //信源符號頻率為0
}
}
//————————————————————————————————————————————————————————
void getStatCode(SymbolStatices* stat, SymbolEncoder *se) //由碼字陣列得到統計陣列中其它兩項資訊的函式
{
unsigned int i;
for (i = 0; i < MAX_SYMBOLS; i++)
{
//之前已經分配過儲存空間了,如果當前符號存在,得到符號的碼長和碼字
if ((*se)[i])
{
(*stat)[i]->numbits = (*se)[i]->numbits;
(*stat)[i]->bits = (*se)[i]->bits;
}
}
}
//————————————————————————————————————————————————————————
void output_statistics(FILE* table, SymbolStatices stat) //將碼字列表寫入檔案的函式
{
unsigned long i,j, count = 0;
for (i = 0; i < MAX_SYMBOLS; ++i)
if (stat[i]) ++count;
fprintf(table, "Symbol\t Frequency\t Length\t Code\n"); //表頭每一項的說明
for (i = 0; i < count; i++)
{
fprintf(table, "%d\t", i); //第一列為信源符號
fprintf(table, "%f\t", stat[i]->freq); //第二列為符號的出現頻率
//如果信源符號頻率為零,碼字為空指標,因此輸出一個 0 作為碼字長度然後輸出下一個符號
if (stat[i]->freq == 0)
{
fprintf(table,"0\n");
continue;
}
fprintf(table, "%d\t", stat[i]->numbits); //第三列為碼字長度
for (j = 0; j < numbytes_from_numbits(stat[i]->numbits); j++)
{
fprintf(table, "%x", stat[i]->bits[j]); //第四列為用十六進位制表示的碼字,可以與編碼後文件中的碼錶對應
}
fprintf(table, "\t");
for (j = 0; j < stat[i]->numbits; j++)
{
//還有用二進位制方式表示的碼字,每次取出碼字的一位,輸出到檔案中
unsigned char c = get_bit(stat[i]->bits, j);
fprintf(table, "%d", c);
}
fprintf(table, "\n");
}
} 統計陣列中符號頻率的賦值 getStatFreq 放在編碼函式 huffman_encode_file 中 get_symbol_frequencies 後面,碼長和碼字的賦值 getStatCode 放在 calculate_huffman_codes 後面,最後使用 output_statistics 輸出要求的編碼結果檔案即可。
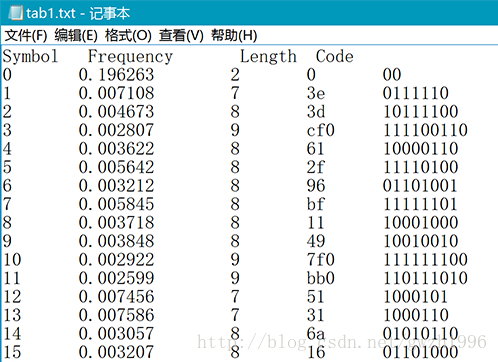
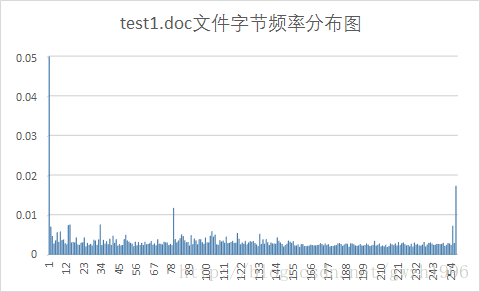
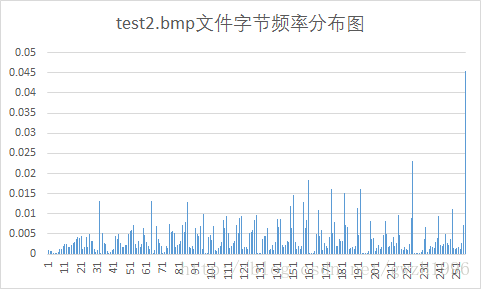
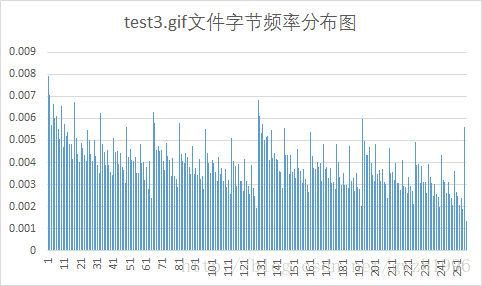
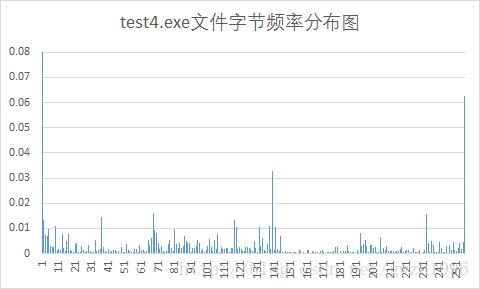
另外,第二列頻率值可以計算檔案的信源熵,第二列和第三列可以計算平均碼長。總共選擇了九種不同格式的檔案對它們進行壓縮,實驗用檔案如圖 5 所示,實驗結果如表 1 所示。其中壓縮比為原檔案大小除以壓縮後的檔案大小。

| 檔案型別 | 平均碼長 | 信源熵(bit/sym) | 原檔案大小(KB) | 壓縮後文件大小(KB) | 壓縮比 |
|---|---|---|---|---|---|
| doc | 7.09 | 7.05 | 203 | 181 | 1.122 |
| bmp | 7.39 | 7.36 | 704 | 651 | 1.081 |
| gif | 7.97 | 7.94 | 3443 | 3433 | 1.003 |
| exe | 6.10 | 6.08 | 308 | 206 | 1.495 |
| psd | 7.71 | 7.68 | 1170 | 1129 | 1.036 |
| png | 8.00 | 7.99 | 3644 | 3645 | 0.999 |
| mp3 | 7.99 | 7.98 | 5252 | 5248 | 1.001 |
| 7.99 | 7.97 | 2861 | 2858 | 1.001 | |
| xls | 4.67 | 4.64 | 274 | 161 | 1.702 |
 |
 |
 |
|---|---|---|
 |
相關推薦實驗三 無損資料壓縮編解碼實驗(Huffman編解碼)~每一步中很多程式碼的註釋都是跟著上一句寫的,可以把註釋連起來看~ 一、實驗原理 1. Huffman編碼步驟 (1)統計各個符號(把檔案的一個位元組看成一個符號)在檔案中出現的概率,按照出現概率從小到大排序。 (2)每一次選出概率最小的 實驗三 表資料的插入、修改和刪除1、 開啟資料庫YGGL; Use yggl; 2、 向Employees表中插入一條記錄:000001 王林 大專 1966-01-23 1 8 中山路32-1-508 83355668 2; In 實驗三:二叉樹的操作(結構轉換,遞迴和非遞迴的先序、中序和後序遍歷,以及層次遍歷,葉子結點和總結點的計數)(1)將一棵二叉樹的所有結點儲存在一維陣列中,虛結點用#表示,利用二叉樹性質5,建立二叉樹的二叉連結串列。 (2) 寫出對用二叉連結串列儲存的二叉樹進行先序、中序和後序遍歷的遞迴和非遞迴演算法。 (3)寫出對用二叉連結串列儲存的二叉樹進行層次遍歷演算法。 (4)求二叉樹 資料結構實驗之圖論四:迷宮探索(超詳細解釋)Problem Description 有一個地下迷宮,它的通道都是直的,而通道所有交叉點(包括通道的端點)上都有一盞燈和一個開關;請問如何從某個起點開始在迷宮中點亮所有的燈並回到起點? Input 連續T組資料輸入,每組資料第一行給出三個正整數,分別表示地下迷宮的 實驗三 二叉樹的物理實現(左子右兄弟-順序表)說明 基於順序表的左子/右兄弟結點表示法 參考資料 一、說明 1、樹的儲存結構一般有父結點表示法(雙親表示法,一般是順序表),子結點表示法(連結串列+順序表),左子/右兄弟結點表示法(連結串列+順序表); 2、在電腦科學中,二叉樹是每個結點最多有兩個子樹的樹結構。通常 實驗三:TCP/IP協議分析實驗一、實驗目的 瞭解TCP/IP協議的工作過程,掌握分析協議的方法,對捕獲的資料包逐欄位分析,以加深對協議、協議封裝及協議資料單元的理解。 二、實驗拓撲 三、實驗內容 安裝WinPcap和Wireshark應用軟體; 執行Wireshark應用程式,抓取網路上資料包; 2018-2019-2 20175224 實驗三《敏捷開發與XP實驗》實驗報告inf 封面 alibaba 目的 設計 add 程序 截圖 練習 一、實驗報告封面 課程:Java程序設計 班級:1752班 姓名:艾星言 學號:20175224 指導教師:婁嘉鵬 實驗日期:2019年4月29日 實驗時間:13:45 - 15:25 實驗序號:24 邱長勇的專欄 [計算機視覺 計算機圖形學 三維重建 影象理解 語音識別 音視訊編解碼 機器學習]HTML 5的Audio/Video元素是基於Flash外掛的音視訊替代方案。 HTML5 視訊和音訊的 DOM 參考手冊 HTML5 DOM 為 <audio> 和 <video> 元素提供了方法、屬性和事件。 這些方法、屬性和事件允許您使 echarts 三種資料雙y軸顯示 (文末附帶完整程式碼)1、展示效果: 2、程式碼說明: 3、完整程式碼 <div id="trmmEcharts" class="echartsDiv"></div> <script type="text/javascript"> 視訊主觀實驗中一個簡易的視訊測試介面(C# Winfrom實現)在做針對視訊的主觀質量測試時,需要讓受試者通過測試介面進行觀看與打分。因此做了一個簡易的測試介面,採集使用者的資訊和打分情況,並匯入SQL資料庫,方便進一步的處理。測試流程分為7步,即圖中對應的7個序號,本篇部落格將對各部分的邏輯和程式碼進行梳理,整體難度不大,由於時間緊迫很 【按鍵】短按,長按,按鍵釋放,三種模式的按鍵掃描程式(軟體消抖動)--- 矩陣鍵盤請先閱讀上篇: 短按,長按,按鍵釋放,三種模式的按鍵掃描程式(軟體消抖動) 上面的程式適用於單個按鍵,那是不是也可以適用於矩陣鍵盤呢? 答案是肯定的。 接下來在這裡做一個簡單的擴充套件,具體框架不用改變,所以具體的框架內容和思路在這裡不詳述了,自行參考上篇文章,這裡就說說擴充套件 【按鍵】短按,長按,按鍵釋放,三種模式的按鍵掃描程式(軟體消抖動)先來說一下這三種模式的意思: 1. 短按模式:單擊按鍵時,返回一次有效按鍵值;長按時也只返回一次有效按鍵值。這樣可以有效地排除因不小心長按帶來的返回多次有效按鍵,進而執行多次按鍵處理程式。 2. 長按模式: 單擊按鍵時,返回一次有效按鍵;長按時,返回多次有效按鍵值。這樣可以很快的調節 資料結構練習——多項式相加(鏈式表)做個記錄,註釋都有 語言c++ 環境codeblock17 已通過測試 code #include <iostream> #include <stdio.h> #include <stdlib.h> #include <algorithm> 三款比較有名的終端瀏覽器(w3m links2 lynx)分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow 也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興! MATLAB三維散點圖的繪製(scatter3、plot3),同時標明序號(1)函式scatter3 用法:scatter3(x,y,z,'.',c) % c 為顏色,需和x,y,z長度相同 例子: x=[4229042.63 4230585.02&nbs H264的解碼總結(概念性的總結)概念簡介: 1:nal的作用:簡稱網路抽象層,負責H264的格式化資料並且提供頭資訊,以保證資料適合各種信和儲存介質上的傳輸。 nal的結構是: NAL頭+RBSP(所謂的RBSP是原始編碼資料後面加了結尾位元) RBSP為資料塊:資料塊分為 A:SODB最原始的編碼資料, B:RBSP C語言 資料型別輸入輸出函式(2018.11.17)基本資料型別 5個方式瞭解基本型別 1、符號 2、位元組數 3、資料範圍 4、表示方法 5、運算方法 記憶體空間分配給變數,不是型別 指標型別:指標變臉中只能存放地址 空型別:主要用於資料型別的轉換和定義函式型別 void指標是萬用指標,萬用=無用,多數用於型別轉換後使用 限定性流程 My SQL Case_3: 根據旅遊局資料練習My SQL語句(前6題)練習1. 從dw_complain_total這個表中列出201509的投訴總量及男女分別投訴多少? # 練習1. 從dw_complain_total這個表中列出201509的投訴總量及男女分別投訴多少? # 注意:as用法,時間函式用法, 還有求的是總量 select sum( vue中用computed簡單實現資料的雙向繫結(getter 和 setter)vue是號稱實現了資料雙向繫結的框架,但事實上在日常開發中我們用的最多的就是 v-model 將data(vue例項中)裡面的是資料和view 相關聯,實現 data 更新,view自動重新整理的效果。但是,在移動成都上來說,這種資料雙向繫結的效果並不是特別的明顯。 今天,我用輸入框和 co 資料結構C語言版(第二章迷宮)轉自未空blog //我剛開始對STACK的記憶體分配那有點問題,後來用這個程式碼除錯了下,感覺有點明白了, 地址由高到低分配,然後程式碼中的base和top剛開始指向地址最低的地方,記憶體不夠時重新在原有基礎上新增記憶體,top指向原有的棧頂,然後繼續 |