Python實現k-means演算法
阿新 • • 發佈:2019-02-02
這也是周志華《機器學習》的習題9.4。
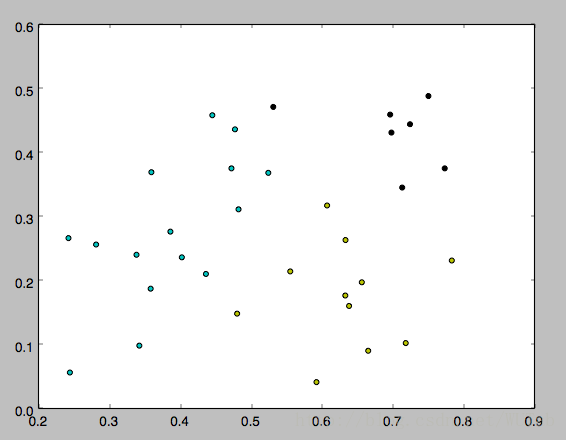
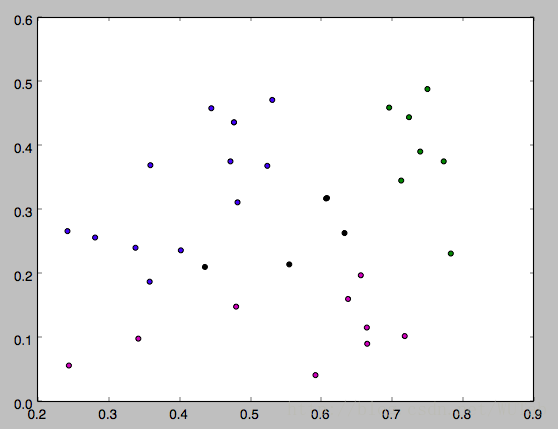
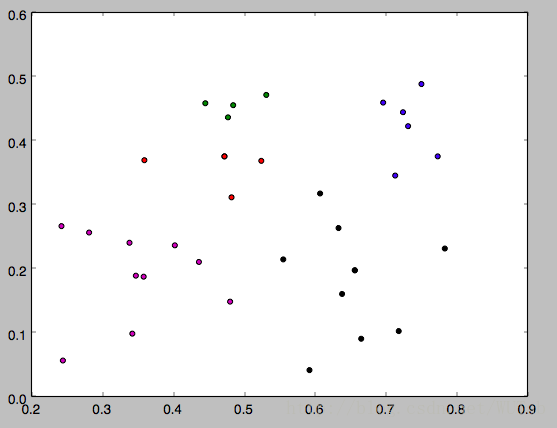
資料集是西瓜資料集4.0,如下
編號,密度,含糖率 1,0.697,0.46 2,0.774,0.376 3,0.634,0.264 4,0.608,0.318 5,0.556,0.215 6,0.403,0.237 7,0.481,0.149 8,0.437,0.211 9,0.666,0.091 10,0.243,0.267 11,0.245,0.057 12,0.343,0.099 13,0.639,0.161 14,0.657,0.198 15,0.36,0.37 16,0.593,0.042 17,0.719,0.103 18,0.359,0.188 19,0.339,0.241 20,0.282,0.257 21,0.784,0.232 22,0.714,0.346 23,0.483,0.312 24,0.478,0.437 25,0.525,0.369 26,0.751,0.489 27,0.532,0.472 28,0.473,0.376 29,0.725,0.445 30,0.446,0.459
演算法很簡單,就不解釋了,程式碼也不復雜,直接放上來:
# -*- coding: utf-8 -*-
"""Excercise 9.4"""
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import sys
import random
data = pd.read_csv(filepath_or_buffer = '../dataset/watermelon4.0.csv', sep = ',')[["密度","含糖率"]].values
########################################## K-means ####################################### 執行方式:在命令列輸入 python k_means.py 4。其中4就是
下面是k分別等於3,4,5的執行結果,因為一開始的均值向量是隨機的,所以每次執行結果會有不同。