linux核心netfilter模組分析之:HOOKs點的註冊及呼叫
-1: 為什麼要寫這個東西?
最近在找工作,之前netfilter 這一塊的程式碼也認真地研究過,應該每個人都是這樣的你懂 不一定你能很準確的表達出來。 故一定要化些時間把這相關的東西總結一下。
0:相關文件
1:iptable中三個tables所掛接的HOOKs
其實這個問題很簡單的執行iptables開啟看看就知道,此處的hook與核心的hook是對應起來的。
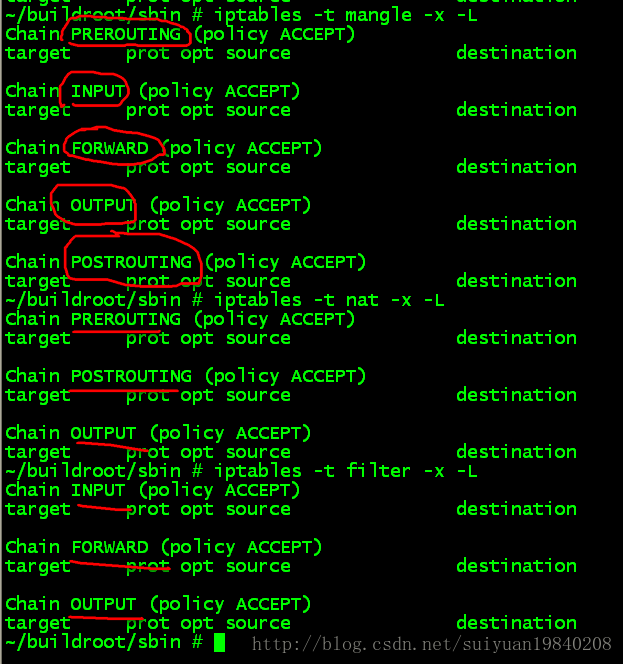
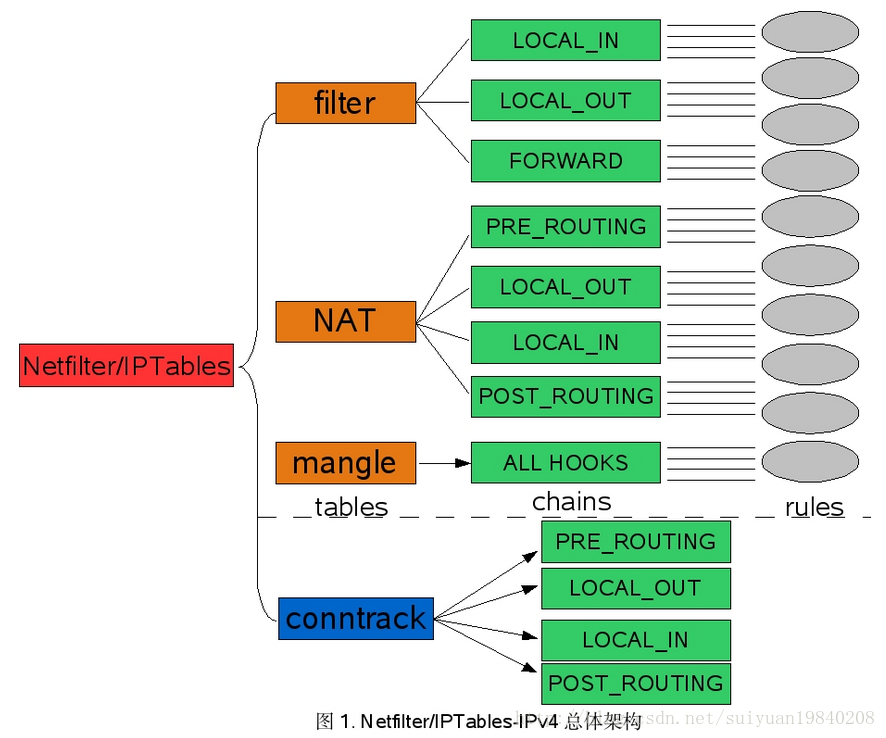
因此在核心中註冊的5個HOOK點如下:
enum nf_inet_hooks {
NF_INET_PRE_ROUTING,
NF_INET_LOCAL_IN,
NF_INET_FORWARD,
NF_INET_LOCAL_OUT,
NF_INET_POST_ROUTING,
NF_INET_NUMHOOKS
};
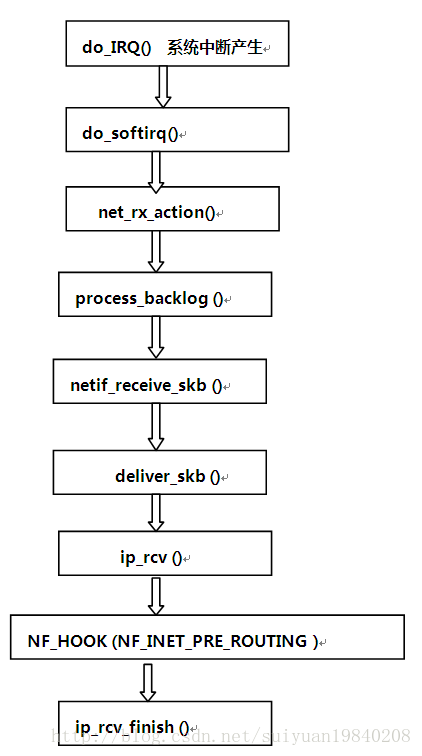
在向下看linux核心中的實現之前在看看一個數據包在進過linux核心中neitfilter的處理過程。
其中這5個HOOK點的執行點說明如下:
資料報從進入系統,進行IP校驗以後,首先經過第一個HOOK函式NF_IP_PRE_ROUTING進行處理;
然後就進入路由程式碼,其決定該資料報是需要轉發還是發給本機的;
若該資料報是發被本機的,則該資料經過HOOK函式NF_IP_LOCAL_IN處理以後然後傳遞給上層協議;
若該資料報應該被轉發則它被NF_IP_FORWARD處理;
經過轉發的資料報經過最後一個HOOK函式NF_IP_POST_ROUTING處理以後,再傳輸到網路上。
本地產生的資料經過HOOK函式NF_IP_LOCAL_OUT 處理後,進行路由選擇處理,然後經過NF_IP_POST_ROUTING處理後傳送出去。
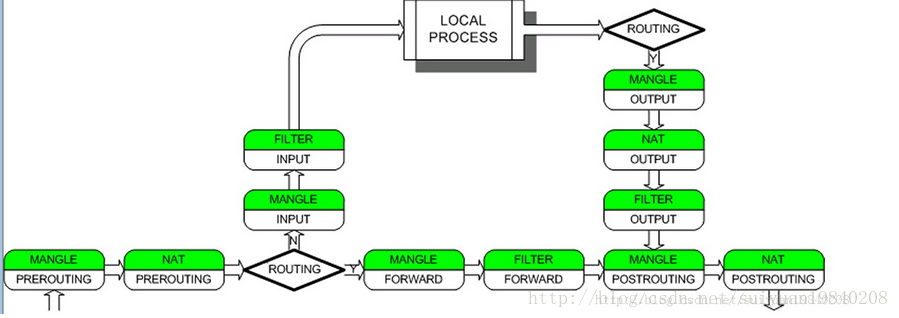
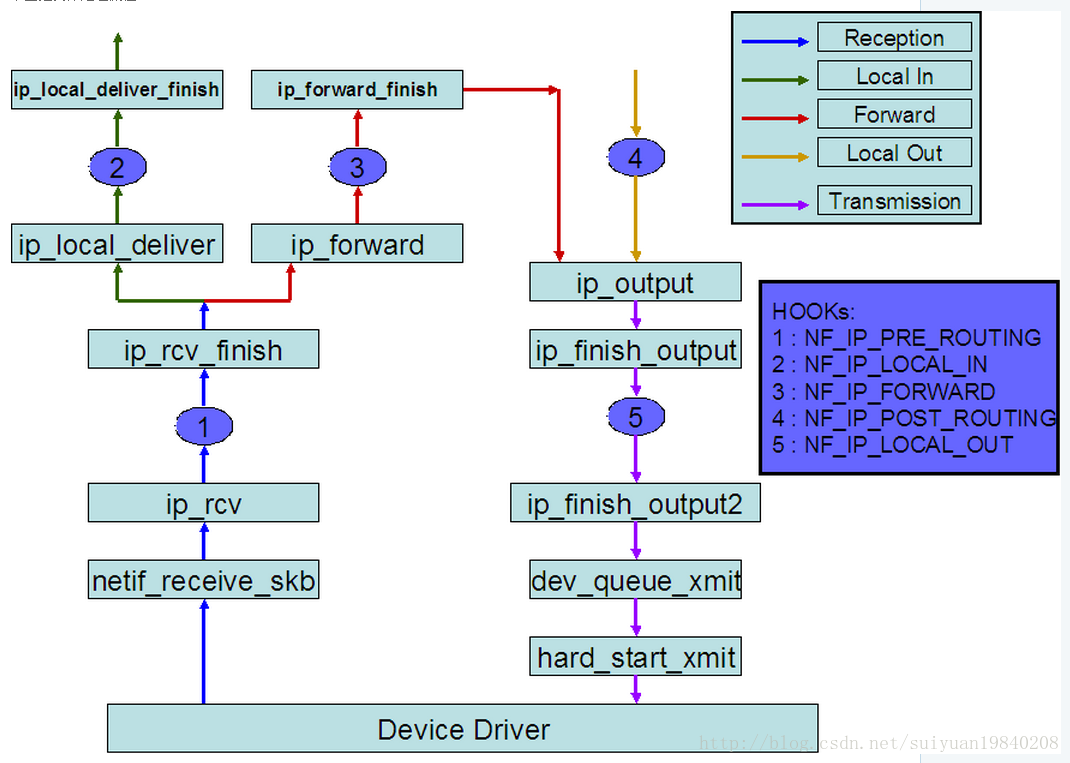
上面的圖可以知道,一個數據包在核心中進行的hook的處理點。
2 :proc檔案下的跟蹤記錄
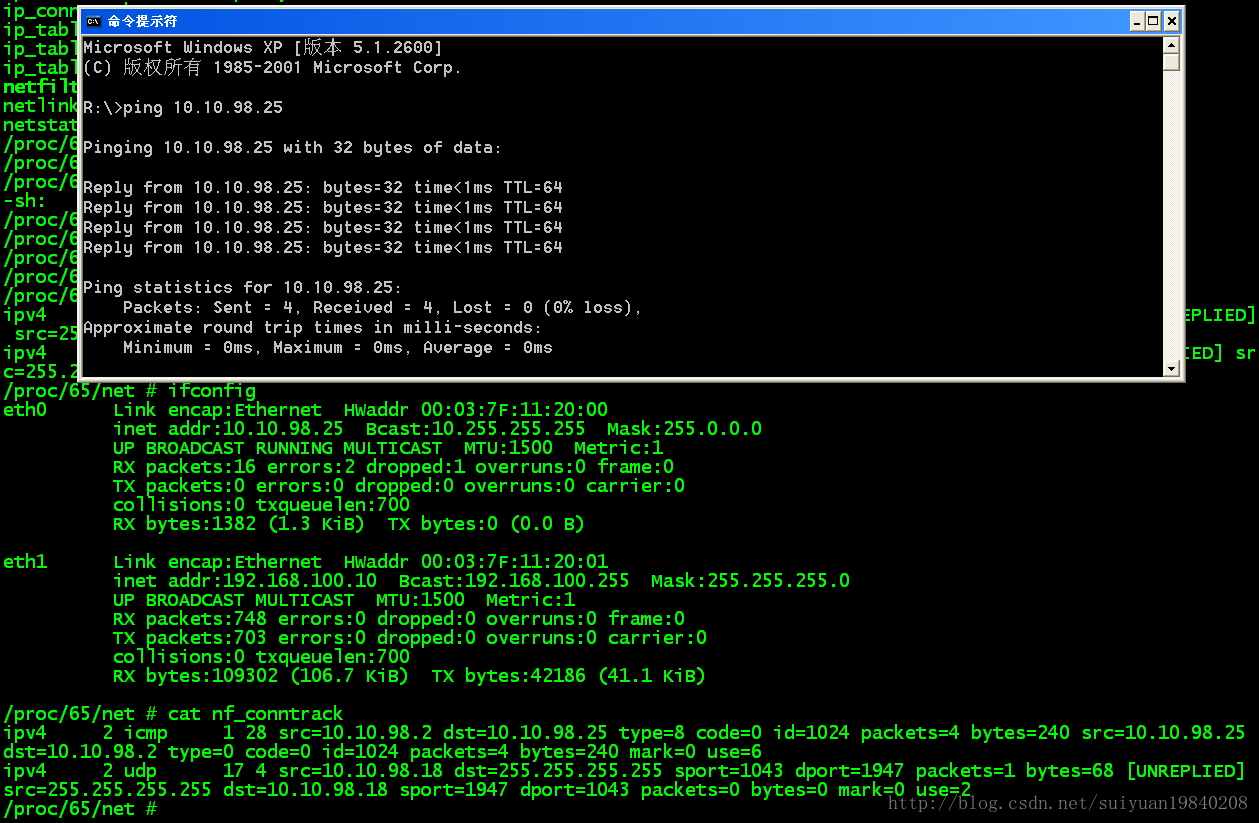
上面的就是連線跟蹤記錄,其中記錄linux系統建立的每一條連線,其中包括源IP,目的IP,源port,目的port,協議ID,其這些可以稱為5元組。有關這個在linux內含中的定義是的結構體struct nf_conn 中的變數
/* Connection tracking(連結跟蹤)用來跟蹤、記錄每個連結的資訊(目前僅支援IP協議的連線跟蹤)。
每個連結由“tuple”來唯一標識,這裡的“tuple”對不同的協議會有不同的含義,例如對tcp,udp
來說就是五元組: (源IP,源埠,目的IP, 目的埠,協議號),對ICMP協議來說是: (源IP, 目
的IP, id, type, code), 其中id,type與code都是icmp協議的資訊。連結跟蹤是防火牆實現狀態檢
測的基礎,很多功能都需要藉助連結跟蹤才能實現,例如NAT、快速轉發、等等。*/
/* XXX should I move this to the tail ? - Y.K */
/* These are my tuples; original and reply */
struct nf_conntrack_tuple_hash tuplehash[IP_CT_DIR_MAX]; 此變數就儲存著上面的跟蹤記錄,
3:hooks點的定義及註冊
其中每個不同協議的不同HOOK點最終都會註冊到全域性的nf_hooks連結串列變數之中:同時註冊到同一個HOOK的處理函式會根據優先順序的不同的進行先後處理。
extern struct list_head nf_hooks[NFPROTO_NUMPROTO][NF_MAX_HOOKS];
其中定義的協議如下:
enum {
NFPROTO_UNSPEC = 0,
NFPROTO_IPV4 = 2, //ipV4
NFPROTO_ARP = 3, //ARP
NFPROTO_BRIDGE = 7, //brigde
NFPROTO_IPV6 = 10,
NFPROTO_DECNET = 12,
NFPROTO_NUMPROTO,
};
NF_MAX_HOOKS 巨集的定義已經在前面說明。HOOK點的定義。

與下面的HOOK的struct nf_hook_ops對比一下就可以看到差異:變數pf的值不同,優先順序不同,即核心中根據不同的協議型別可以註冊不同的掛載點進行不同的優先順序資料包的處理。

其註冊使用函式為:nf_register_hooks()函式在核心中多個地方出現,因為使用者可以根據自己的需要對特定的協議在特定的位置新增HOOK出現函式。

nf_register_hook()函式的實現就是:
int nf_register_hook(struct nf_hook_ops *reg)
{
struct nf_hook_ops *elem;
int err;
err = mutex_lock_interruptible(&nf_hook_mutex);
if (err < 0)
return err;////遍歷已經註冊的的HOOK,OPS,將新加入的根據優先順序新增到連結串列最後
list_for_each_entry(elem, &nf_hooks[reg->pf][reg->hooknum], list) {
if (reg->priority < elem->priority)
break;
}
list_add_rcu(®->list, elem->list.prev);
mutex_unlock(&nf_hook_mutex);
return 0;
}上面就是HOOK點的註冊函式,即根據協議型別和HOOK點註冊到全域性陣列中nf_hooks[][]中。
4:註冊的HOOK點何時被使用?
在linux核心中當需要使用註冊的HOOK點時,使用函式:
#define
NF_HOOK(pf, hook, skb, indev, outdev, okfn) \
NF_HOOK_THRESH(pf, hook, skb, indev, outdev, okfn, INT_MIN)
NF_HOOK->NF_HOOK_THRESH->nf_hook_thresh->nf_hook_slow——這個是最終的執行函式。
先看看下面函式都返回值:
/* Responses from hook functions. */
#define NF_DROP 0
#define NF_ACCEPT 1
#define NF_STOLEN 2
#define NF_QUEUE 3
#define NF_REPEAT 4
#define NF_STOP 5
#define NF_MAX_VERDICT NF_STOP
int nf_hook_slow(u_int8_t pf, unsigned int hook, struct sk_buff *skb,
struct net_device *indev,
struct net_device *outdev,
int (*okfn)(struct sk_buff *),
int hook_thresh)
{
struct list_head *elem;
unsigned int verdict;
int ret = 0;
/* We may already have this, but read-locks nest anyway */
rcu_read_lock();
elem = &nf_hooks[pf][hook];//是不是很熟悉就是上面的全域性變數專門用來註冊全域性HOOK點的變數。
next_hook:/* 開始遍歷對應的netfilter的規則,即對應的proto和hook掛載點 */
verdict = nf_iterate(&nf_hooks[pf][hook], skb, hook, indev,outdev, &elem, okfn, hook_thresh);
if (verdict == NF_ACCEPT || verdict == NF_STOP) {
ret = 1;
} else if (verdict == NF_DROP) {
kfree_skb(skb);
ret = -EPERM;
} else if ((verdict & NF_VERDICT_MASK) == NF_QUEUE) {
if (!nf_queue(skb, elem, pf, hook, indev, outdev, okfn,
verdict >> NF_VERDICT_BITS))
goto next_hook;
}
rcu_read_unlock();
return ret;
}現在來看看nf_iterate()函式:
unsigned int nf_iterate(struct list_head *head,
struct sk_buff *skb,
unsigned int hook,
const struct net_device *indev,
const struct net_device *outdev,
struct list_head **i,
int (*okfn)(struct sk_buff *),
int hook_thresh)
{
unsigned int verdict;
//其中head就是全域性的2維陣列nf_hooks,
/*
* The caller must not block between calls to this
* function because of risk of continuing from deleted element.
*/
list_for_each_continue_rcu(*i, head) {
struct nf_hook_ops *elem = (struct nf_hook_ops *)*i;
if (hook_thresh > elem->priority)
continue;
/* Optimization: we don't need to hold module
reference here, since function can't sleep. --RR */
verdict = elem->hook(hook, skb, indev, outdev, okfn);//根據協議和HOOK點執行掛在的處理函式
if (verdict != NF_ACCEPT) {//返回結果進行判斷。
#ifdef CONFIG_NETFILTER_DEBUG
if (unlikely((verdict & NF_VERDICT_MASK)
> NF_MAX_VERDICT)) {
NFDEBUG("Evil return from %p(%u).\n",
elem->hook, hook);
continue;
}
#endif
if (verdict != NF_REPEAT)
return verdict;
*i = (*i)->prev;
}
}
return NF_ACCEPT;
}對各個返回值的解釋如下:
NF_DROP:直接drop掉這個資料包; NF_ACCEPT:資料包通過了掛載點的所有規則; NF_STOLEN:這個還未出現,留在以後解釋; NF_QUEUE:將資料包enque到使用者空間的enque handler; NF_REPEAT:為netfilter的一個內部判定結果,需要重複該條規則的判定,直至不為NF_REPEAT; NF_STOP:資料包通過了掛載點的所有規則。但與NF_ACCEPT不同的一點時,當某條規則的判定結果為NF_STOP,那麼可以直接返回結果NF_STOP,無需進行後面的判定了。而NF_ACCEPT需要所以的規則都為ACCEPT,才能返回NF_ACCEPT。在資料包流經核心協議棧的整個過程中,在內中定義的HOOK中的如:PRE_ROUTING、LOCAL_IN、FORWARD、LOCAL_OUT和POST_ROUTING會根據資料包的協議簇PF_INET到這些關鍵點去查詢是否註冊有鉤子函式。如果沒有,則直接返回okfn函式指標所指向的函式繼續走協議棧;如果有,則呼叫nf_hook_slow函式,從而進入到Netfilter框架中去進一步呼叫已註冊在該過濾點下的鉤子函式,再根據其返回值來確定是否繼續執行由函式指標okfn所指向的函式
一個IP資料包的接受過程如下: