
mysql的full join的實現
資料庫多表查詢主要有以下幾種
inner join內連線查詢,只有兩個表都匹配才會顯示記錄
left /right [outer] join 左/右外連線 左表匹配右表,左表全部顯示,結果中缺少的右表字段的值 則返回null,右外連線相反
full join 全連線,只要其中某個表存在匹配,就會返回行,不存在的欄位返回null
自連線 就是虛擬出同一張表,在一張表上實現多表查詢
【注意】:
在mysql裡是不支援full join的
但仍然可以同過 左外連線+ union+右外連線 實現
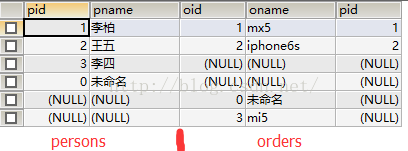
例:
</pre><pre name="code" class="sql"> SELECT * FROM Persons p LEFT OUTER JOIN Orders o ON p.pid=o.pid UNION SELECT * FROM Persons p RIGHT OUTER JOIN Orders o ON p.pid=o.pid;
相關推薦
Spark SQL 之 Join 實現
結構 很多 找到 過濾 sql查詢優化 ade read 轉換成 分析 原文地址:Spark SQL 之 Join 實現 Spark SQL 之 Join 實現 塗小剛 2017-07-19 217標簽: spark , 數據庫 Join作為SQL中
SparkSQL的3種Join實現
檢查 .cn es2017 一行 _id b2c manage 設計 png 引言 Join是SQL語句中的常用操作,良好的表結構能夠將數據分散在不同的表中,使其符合某種範式,減少表冗余、更新容錯等。而建立表和表之間關系的最佳方式就是Join操作。 對於Spark來說有
大資料教程(9.6)map端join實現
上一篇文章講了mapreduce配合實現join,本節博主將講述在map端的join實現; 一、需求 &n
java利用Fork/Join實現1+...+100
import java.util.concurrent.*; /** * Created by Mr.Jo on 2018/9/10. */ public class Main{ static class CountTask extends Recursive
Java中用Thread.join實現單任務分成多個任務最後合併結果集
執行任務的具體執行緒類: package com.utils; import java.util.ArrayList; import java.util.List; public class MyThread extends Thread { private Lis
Entity Framework(EF)之Linq查詢的left join實現
EF中多表聯結查詢只實現了inner join並沒有實現left join,但是在實際的業務中需要用到left join的情況是很常見的。那麼我們可以通過設定左表之外的表查詢無記錄時返回預設值即可。具體參見以下程式碼。 EF程式碼: var order = (from a
59_elasticSearch 通過應用層join實現使用者與部落格的關聯
59_通過應用層join實現使用者與部落格的關聯一、概述1、構造使用者與部落格資料在構造資料模型的時候,還是將有關聯關係的資料,然後分割為不同的實體,類似於關係型資料庫中的模型案例背景:部落格網站, 我們會模擬各種使用者發表各種部落格,然後針對使用者和部落格之間的關係進行資料
使用Queryable.Join實現多表連線查詢
背景 今天處理一個問題時,遇到EF Model中多表連線查詢的情況,於是學習了一下Queryable.Join()的用法。由於本人是Linq新手,很多地方都看不懂,只能依葫蘆畫瓢。 業務說明 1) 一個EF Model名為Daks,對應的DbContext名為Dak
如何使用LEFT JOIN實現多表查詢
什麼是LEFT JOIN請各位自行了解,廢話不多說,先直接上三張表 組織表(t_organization) 部門表(t_department) 使用者表(t_user) 邏輯是組織下面有部門,部門下面有使用者,組織和部門通過organization_id欄
Hadoop中MapReduce多種join實現例項分析
感謝分享:http://database.51cto.com/art/201410/454277.htm 1、在Reudce端進行連線。 在Reudce端進行連線是MapReduce框架進行表之間join操作最為常見的模式,其具體的實現原理如下: Map端的主要工作:為來自
MySQL中使用INNER JOIN來實現Intersect並集操作
int isam har 業務 charset tin ner get 一句話 MySQL中使用INNER JOIN來實現Intersect並集操作 一、業務背景 我們有張表設計例如以下: CREATE TABLE `user_defined_value` (
hive------ Group by、join、distinct等實現原理
map etc 條件 val log in use ins none 操作 1. Hive 的 distribute by Order by 能夠預期產生完全排序的結果,但是它是通過只用一個reduce來做到這點的。所以對於大規模的數據集它的效率非常低。在很多
join命令實現文件內容拼接
join awk join使用介紹 功能說明:將兩個文件中,指定欄位內容相同的行連接起來。 語 法:join [-i][-a<1或2>][-e<字符串>][-o<格式>] [-t<字符>][-v<1或2>][-1
Hadoop_21_編寫MapReduce程序實現Join功能
持久化 tle 格式 AD style tro 消息 clas HA 1.序列化與Writable接口 1.1.hadoop的序列化格式 序列化和反序列化就是結構化對象和字節流之間的轉換,主要用在內部進程的通訊和持久化存儲方面 hadoop在節點間的內部通訊使用的是
Spark SQL join的三種實現方式
引言 join是SQL中的常用操作,良好的表結構能夠將資料分散到不同的表中,使其符合某種規範(mysql三大正規化),可以最大程度的減少資料冗餘,更新容錯等,而建立表和表之間關係的最佳方式就是join操作。 對於Spark來說有3種Join的實現,每種Join對應的不同的應用場景(SparkSQL自動決策
Reduce端join演算法實現 - (訂單跟商品)
程式碼地址: https://gitee.com/tanghongping/hadoopMapReduce/tree/master/src/com/thp/bigdata/rjon 現在有兩張表 1.訂單表 2.商品表 訂單資料表t_order: id
MapReduce快取方式實現LEFT JOIN
1.通過快取實現map端的left join 快取檔案pdts.txt內容: orders.txt檔案內容 1.1)在驅動程式中增加指定檔案快取: import org.apache.hadoop.conf.Configuration; import org.apach
MapReduce在Reduce中實現LEFT JOIN
本文以訂單和商品演示如何實現left join。 一:準備資料 訂單資料表t_order: id date pid amount 1001 20150710 P0
實現為fork/join框架生成自定義執行緒的ThreadFactory介面
Java 9併發程式設計指南 目錄 實現為fork/join框架生成自定義執行緒的ThreadFactory介面 準備工作 實現過程 工作原理 擴充套件學習 更多關注 fork/join框架是Java9中最有趣的特性之一,它是E
Java實現主執行緒等待子執行緒join,CountDownLatch
本文介紹兩種主執行緒等待子執行緒的實現方式,以5個子執行緒來說明: 1、使用Thread的join()方法,join()方法會阻塞主執行緒繼續向下執行。 2、使用Java.util.concurrent中的CountDownLatch,是一個倒數計數器。初始化時先設定