網路爬蟲的原理和案例
網路爬蟲基本原理
網路爬蟲是捜索引擎抓取系統的重要組成部分。爬蟲的主要目的是將網際網路上的網頁下載到本地形成一個或聯網內容的映象備份。這篇部落格主要對爬蟲以及抓取系統進行一個簡單的概述。
一、網路爬蟲的基本結構及工作流程
一個通用的網路爬蟲的框架如圖所示:
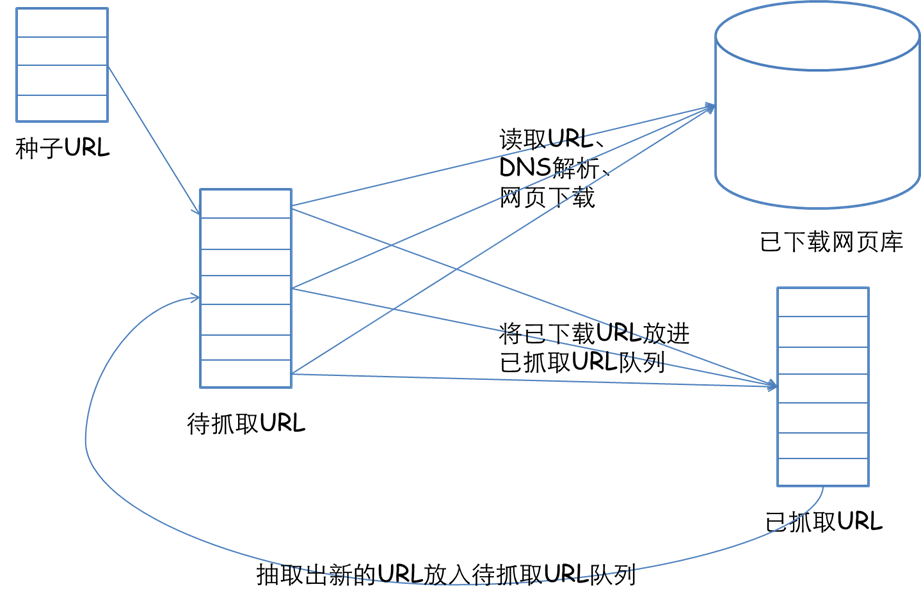
網路爬蟲的基本工作流程如下:
首先選取一部分精心挑選的種子URL;
將這些URL放入待抓取URL佇列;
從待抓取URL佇列中取出待抓取在URL,解析DNS,並且得到主機的ip,並將URL對應的網頁下載下來,儲存進已下載網頁庫中。此外,將這些URL放進已抓取URL佇列。
分析已抓取URL佇列中的URL,分析其中的其他URL,並且將URL放入待抓取URL佇列,從而進入下一個迴圈。
二、從爬蟲的角度對網際網路進行劃分
對應的,可以將網際網路的所有頁面分為五個部分:
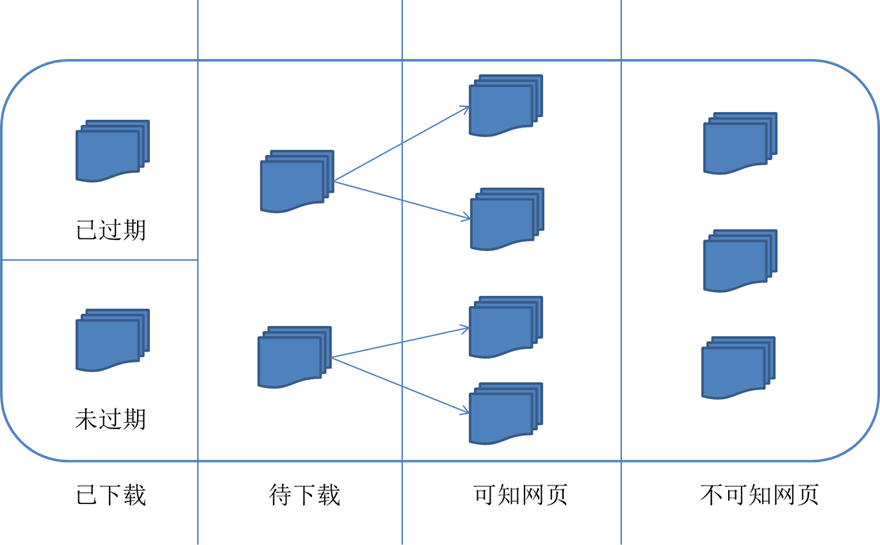
已下載未過期網頁
已下載已過期網頁:抓取到的網頁實際上是網際網路內容的一個映象與備份,網際網路是動態變化的,一部分網際網路上的內容已經發生了變化,這時,這部分抓取到的網頁就已經過期了。
待下載網頁:也就是待抓取URL佇列中的那些頁面
可知網頁:還沒有抓取下來,也沒有在待抓取URL佇列中,但是可以通過對已抓取頁面或者待抓取URL對應頁面進行分析獲取到的URL,認為是可知網頁。
還有一部分網頁,爬蟲是無法直接抓取下載的。稱為不可知網頁。
三、抓取策略
在爬蟲系統中,待抓取URL佇列是很重要的一部分。待抓取URL佇列中的URL以什麼樣的順序排列也是一個很重要的問題,因為這涉及到先抓取那個頁面,後抓取哪個頁面。而決定這些URL排列順序的方法,叫做抓取策略。下面重點介紹幾種常見的抓取策略:
1.深度優先遍歷策略
深度優先遍歷策略是指網路爬蟲會從起始頁開始,一個連結一個連結跟蹤下去,處理完這條線路之後再轉入下一個起始頁,繼續跟蹤連結。我們以下面的圖為例:
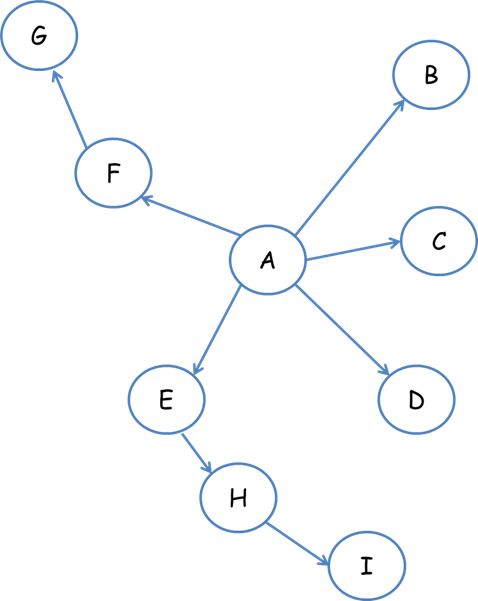
遍歷的路徑:A-F-G E-H-I B C D
2.寬度優先遍歷策略
寬度優先遍歷策略的基本思路是,將新下載網頁中發現的連結直接插入待抓取URL佇列的末尾。也就是指網路爬蟲會先抓取起始網頁中連結的所有網頁,然後再選擇其中的一個連結網頁,繼續抓取在此網頁中連結的所有網頁。還是以上面的圖為例:
遍歷路徑:A-B-C-D-E-F G H I
3.反向連結數策略
反向連結數是指一個網頁被其他網頁連結指向的數量。反向連結數表示的是一個網頁的內容受到其他人的推薦的程度。因此,很多時候搜尋引擎的抓取系統會使用這個指標來評價網頁的重要程度,從而決定不同網頁的抓取先後順序。
在真實的網路環境中,由於廣告連結、作弊連結的存在,反向連結數不能完全等他我那個也的重要程度。因此,搜尋引擎往往考慮一些可靠的反向連結數。
簡單的爬蟲例項
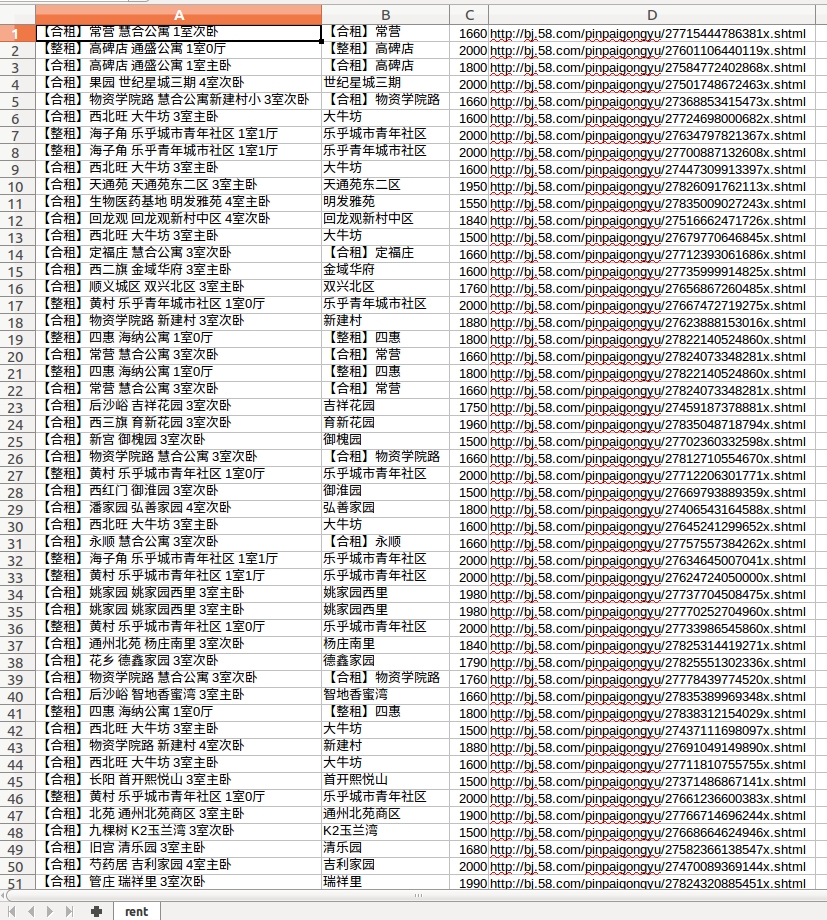
爬取58同城上的房子簡介,房子型別,房子價格等資訊,然後寫入到rent.csv檔案中,形成表格.
#!/usr/bin/python
#coding=utf-8
from bs4 import BeautifulSoup
from urlparse import urljoin
import requests
import csv
# 選取價格在1500-2000之間的房子資訊
url = 'http://bj.58.com/pinpaigongyu/pn/{page}/?minprice=1500_2000'
page = 0
csv_file = open('rent.csv','wb')
csv_writer = csv.writer(csv_file,delimiter = ',')
while True:
page += 1
print "fetch: ",url.format(page = page)
response = requests.get(url.format(page = page))
html = BeautifulSoup(response.text)
house_list = html.select('.list > li')
if not house_list:
break
for house in house_list:
house_title = house.select("h2")[0].string.encode("utf-8")
house_url = urljoin(url,house.select("a")[0]["href"])
house_info_list = house_title.split()
if "公寓" in house_info_list[1] or "青年公寓" in house_info_list[1]:
house_location = house_info_list[0]
else:
house_location = house_info_list[1]
house_money = house.select(".money")[0].select("b")[0].string.encode("utf-8")
csv_writer.writerow([house_title,house_location,house_money,house_url])
csv_file.close()