
豆瓣電影Top250爬取的資料的一些簡單視覺化筆記
阿新 • • 發佈:2019-02-04
豆瓣Top250網址
將之前爬取到的豆瓣電影進行簡單的視覺化:
資料列表儲存為CSV格式,如圖
#!-*- coding:utf-8 -*-
import pandas as pd
import numpy as np
import matplotlib.pylab as plt
import re
from numpy import rank
from builtins import map
from datashape.coretypes import Map
#http://www.jianshu.com/p/0a76c94e9db7 參考了簡書上的餅狀圖教程
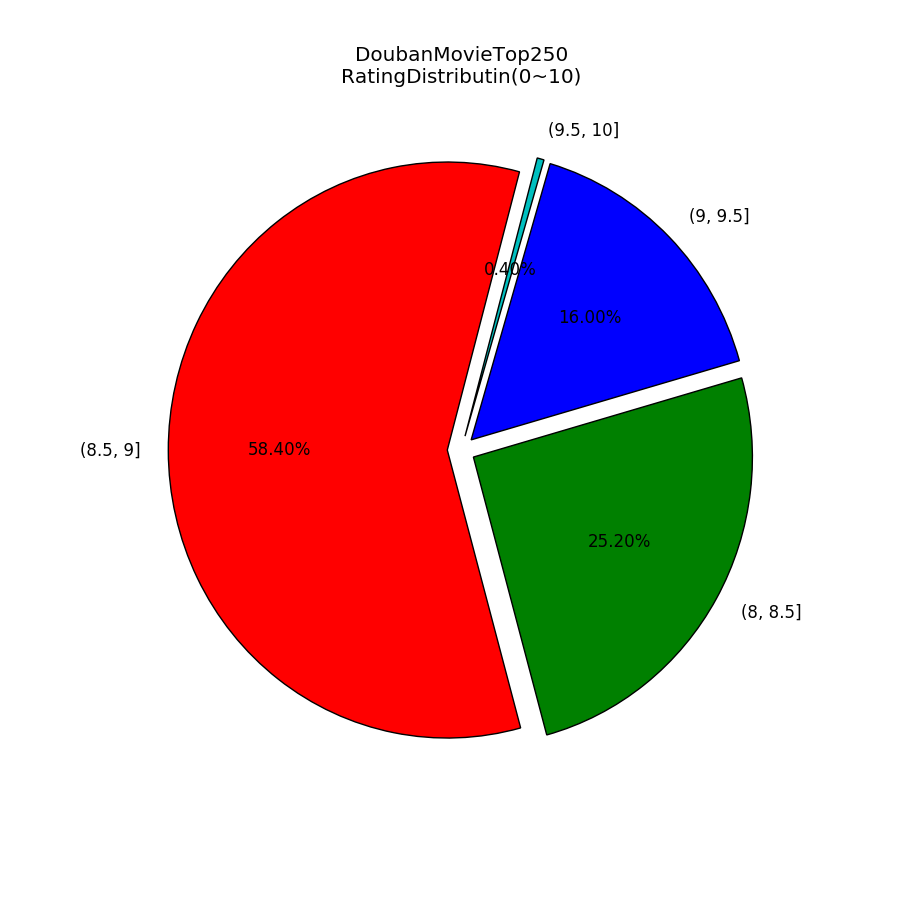
#切換工作目錄,IPython執行%pylab 豆瓣電影Top250評分的分佈餅圖:
#year pie
year=Movie['Year']
for i in year.index:
if len(year[i])>4:
year.drop(i,inplace=True) # year.drop(i,inplace=True) 去除多個年代的特例,inplace重要,修改改變原值
year=year.astype(int)
bins=np.linspace(min(year)-1,max(year)+1,10).astype(int) #產生區間,bins一般為(,]的,所以+1
year_cut=pd.cut(year,bins=bins)
year_class=year_cut.value_counts()
year_pct=year_class/year_class.sum()*100
year_arr_pct=np.array(year_pct)
color=['b', 'g', 'r', 'c', 'm', 'y', (0.2,0.5,0.7), (0.6,0.5,0.7),(0.2,0.7,0.1)] #RGB 0-1之間的tuple
f2=plt.figure(figsize=(9,9))
patches,out_text,in_text=plt.pie(year_arr_pct,labels=year_pct.index,colors=color,autopct='%.2f%%',explode=[0.05]*9,startangle=30)
plt.title('MovieTop250\nYears Distribution')
f2.show()
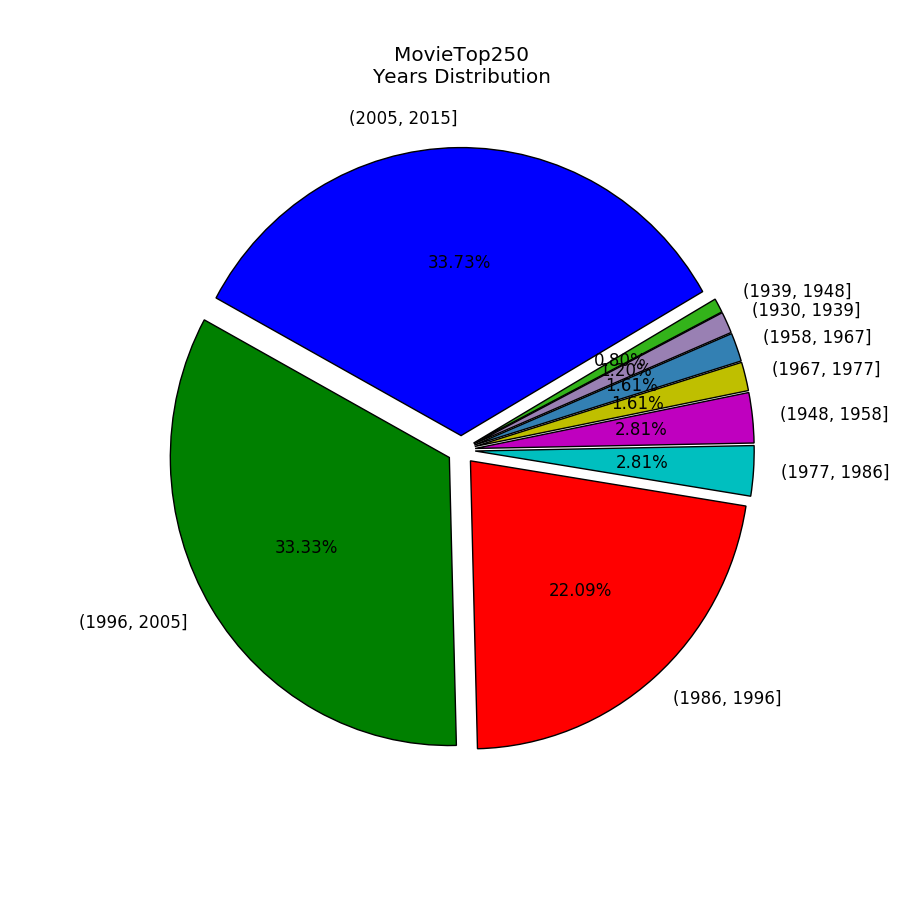
plt.savefig('MovieTop250_YearsDistribution.png')電影出品年的分佈餅圖:
#評價人數
rank=np.array(Movie.index,dtype=int)+1 #index start from 0
Movie['rank']=rank
f3=plt.figure(3,figsize=(12,10))
plt.scatter(x=Movie['rank'],y=Movie['RatingNum'],c=Movie['Rating10'],s=80)
plt.title('Douban Movie\nRank and Rating People by Rating',fontsize=20)
plt.xlabel('Rank',fontsize=15)
plt.ylabel('Rating People',fontsize=15)
plt.axis([-5,255,0,750000]) #x軸座標範圍
plt.colorbar() #顯示colorbar
plt.savefig('DoubanMovie_Rank_and_RatingPeople_by_Rating.png')
plt.show()豆瓣電影Top250,電影排名&評價人數&電影評分的散點圖:
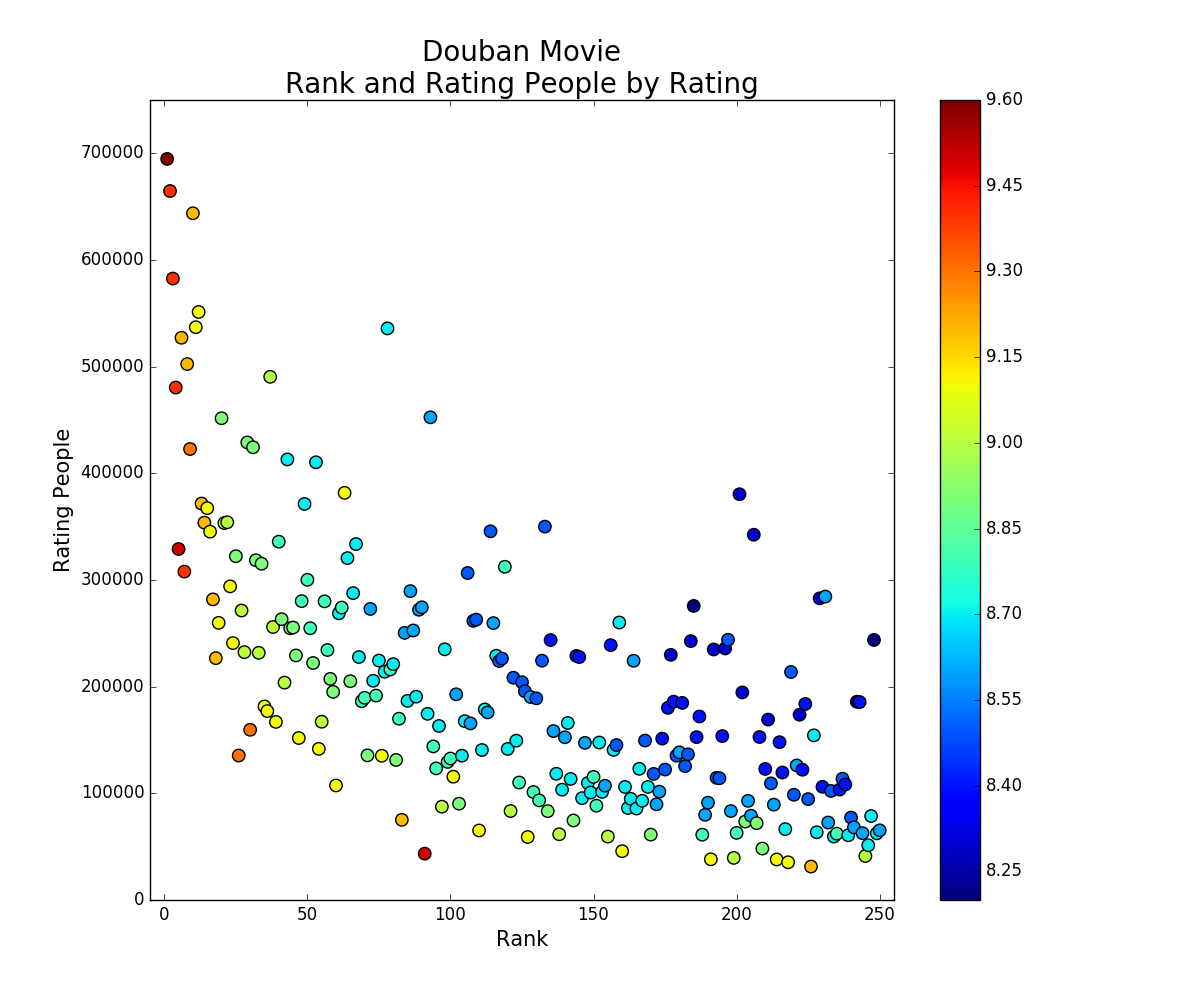
這張圖比較有意思:
1)評價人數比較少的電影,評分往往要高點(排除前面口碑爆棚的幾部),可能因為評價的樣本不夠,分數會偏高。所以評價人數多的更客觀。
2)豆瓣的排名看來是按評價人數和評分加權排名的.找到了豆瓣排序演算法的一些介紹,然而並沒有介紹具體公式,連結豆瓣演算法
3)前面幾部看來真的經典到不行。
前10名:肖申克的救贖
這個殺手不太冷
阿甘正傳
霸王別姬
美麗人生
千與千尋
辛德勒的名單
海上鋼琴師
機器人總動員
盜夢空間
泰坦尼克號
(千與千尋還沒看過。。。)
按電影國家分類:
#!-*- coding:utf-8 -*-
import pandas as pd
import numpy as np
import matplotlib.pylab as plt
from matplotlib.font_manager import FontProperties #fontproperties的模組,pyde自動新增的,好評
Movie=pd.read_csv('MovieTop250.csv',encoding='utf-8')
country_iter=(set(x.split(' ')) for x in Movie['Country']) #generator生成器,分解字串
countries=sorted(set.union(*country_iter)) #Return the union of sets as a new set.
#*country_iter:This works for any iterable of iterables.
df=pd.DataFrame(np.zeros((len(Movie),len(countries))),columns=countries)#建立一個0DataFrame,np.zeros()內為要tuple
for i,gen in enumerate(Movie['Country']):
df.ix[i,gen.split(' ')]=1 #第i條資料的country置為1
num_of_country=df.sum()
num_of_country[1]=num_of_country[0]+num_of_country[1] #中國和中國大陸合併
num_of_country.pop('中國')
num_of_country.sort_values(inplace=True,ascending=False)
f1=plt.figure()
for i,gen in enumerate(num_of_country[:10]):
plt.bar(i,gen) #i為bar的起始橫座標,gen為縱座標,寬度預設
names=list(num_of_country.index)
plt.xticks(np.arange(10)+0.4,names,fontproperties='SimHei') #在圖中顯示中文字元要加上fontproperties='SimHei'
plt.ylabel('Movie Number')
plt.title('Douban Movie\nMovie Distribution by Countries')
plt.savefig('Movie_Distribution_by_Countries.png')
f1.show()
國家分佈的柱狀圖: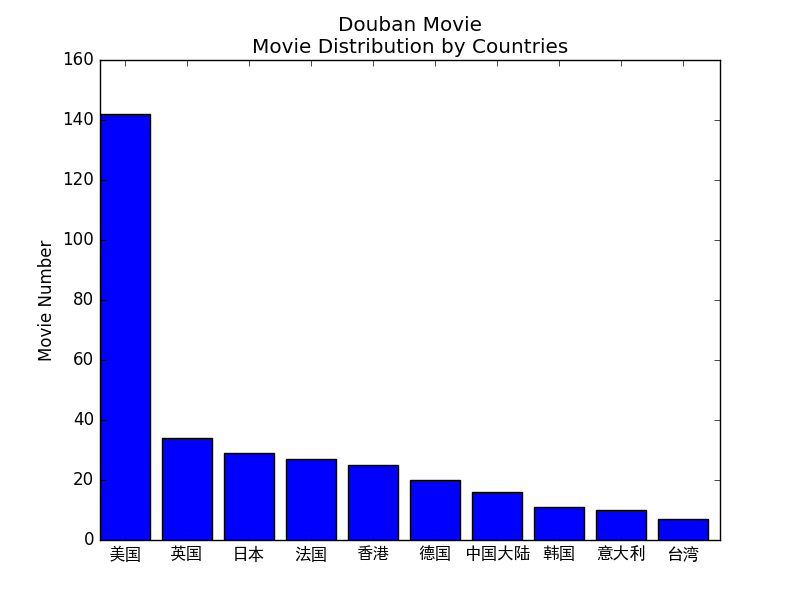
因為有些影片為多國合作的,也算各自國家的吧。
過濾了很多隻有一兩部的國家,果然還是美帝有金坷垃,畝產一萬八
genre_iter=(set(x.split(' ')) for x in Movie['Grenre'])
genre=sorted(set.union(*genre_iter))
frame=pd.DataFrame(np.zeros((len(Movie),len(genre))),columns=genre)
for i,gen in enumerate(Movie['Grenre']):
frame.ix[i,gen.split(' ')]=1
genre_sum=frame.sum()
genre_sum.sort_values(inplace=True,ascending=False)
f2=plt.figure(2)
'''for i,gen in enumerate(genre_sum[:8]):
plt.bar(i,gen)
names=list(genre_sum.index)
plt.xticks(np.arange(8)+0.4,names,fontproperties='SimHei')
plt.show()'''
#改進的方法
p2=plt.bar(np.arange(8),genre_sum.values[:8],align='center') #p2包含8個元素,每個對應一個bar
names=list(genre_sum.index)
plt.xticks(np.arange(8),names,fontproperties='SimHei')
plt.legend((p2[0],),('MovieNumber',)) #只有一個元素的tuple應寫成(ele,)
plt.ylabel('Movie Number')
plt.title('Douban Movie\nDistribution by Genre')
plt.savefig('Movie_Distribution_by_Genre.png')
plt.show()
影片型別分佈柱狀圖:
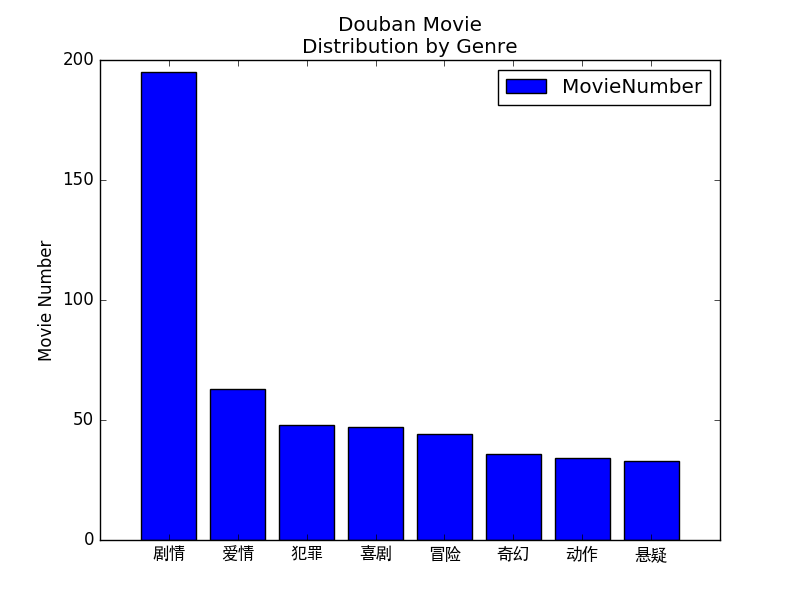
這裡的劇情類基本大多數影片都算,定義很不清晰。
看來還是愛情屬性最能引起觀眾的共鳴,聽得最多的也是情歌
還發現簡書上一個教程點選Jupyter畫圖互動,在命令列直接輸入%pylab inline直接顯示在notebook中,不會產生新的Ipyhon視窗,對中文的支援很好。不過好像沒法儲存,當草稿打。