
lucene中的高亮
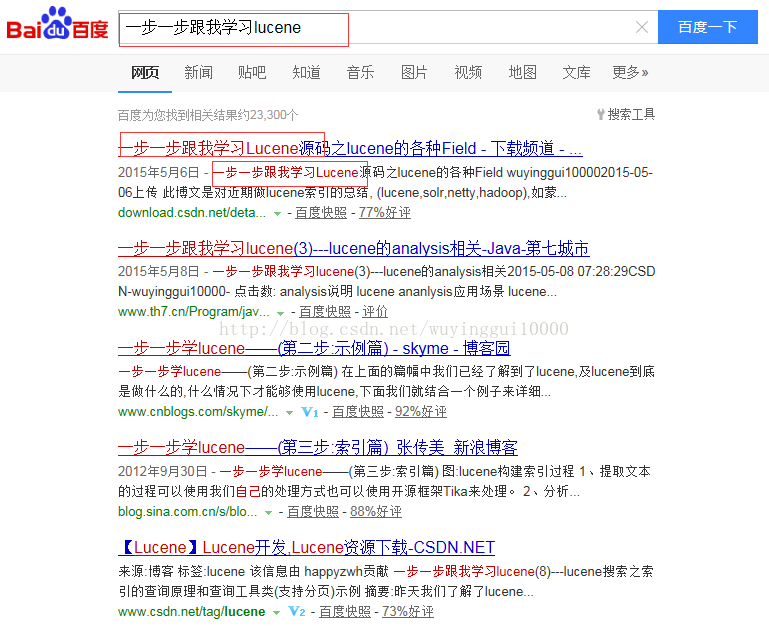
這裡我們搜尋的內容是“一步一步跟我學習lucene”,搜尋引擎展示的結果中對使用者的輸入資訊進行了配色方面的處理,這種區分正常文字和輸入內容的效果即是高亮顯示;
這樣做的好處:
- 視覺上讓人便於查詢有搜尋對應的文字塊;
- 介面展示更友好;
lucene提供了highlighter外掛來體現類似的效果;
highlighter對查詢關鍵字高亮處理;
highlighter包包含了用於處理結果頁查詢內容高亮顯示的功能,其中Highlighter類highlighter包的核心元件,藉助Fragmenter, fragment Scorer, 和Formatter等類來支援使用者自定義高亮展示的功能;
示例程式
這裡邊我利用了之前的做的目錄檔案索引
- package com.lucene.search.util;
- import java.io.IOException;
- import java.io.StringReader;
- import java.util.concurrent.ExecutorService;
- import java.util.concurrent.Executors;
- import org.apache.lucene.analysis.Analyzer;
- import org.apache.lucene.analysis.TokenStream;
- import org.apache.lucene.analysis.standard.StandardAnalyzer;
- import org.apache.lucene.document.Document;
- import org.apache.lucene.index.Term;
- import org.apache.lucene.search.IndexSearcher;
- import org.apache.lucene.search.ScoreDoc;
- import org.apache.lucene.search.TermQuery;
- import org.apache.lucene.search.TopDocs;
- import org.apache.lucene.search.highlight.Highlighter;
- import org.apache.lucene.search.highlight.InvalidTokenOffsetsException;
- import org.apache.lucene.search.highlight.QueryScorer;
- import org.apache.lucene.search.highlight.SimpleFragmenter;
- import org.apache.lucene.search.highlight.SimpleHTMLFormatter;
- import org.apache.lucene.util.BytesRef;
- publicclass HighlighterTest {
- publicstaticvoid main(String[] args) {
- IndexSearcher searcher;
- TopDocs docs;
- ExecutorService service = Executors.newCachedThreadPool();
- try {
- searcher = SearchUtil.getMultiSearcher("index", service);
- Term term = new Term("content",new BytesRef("lucene"));
- TermQuery termQuery = new TermQuery(term);
- docs = SearchUtil.getScoreDocsByPerPage(1, 30, searcher, termQuery);
- ScoreDoc[] hits = docs.scoreDocs;
- QueryScorer scorer = new QueryScorer(termQuery);
- SimpleHTMLFormatter simpleHtmlFormatter = new SimpleHTMLFormatter("<B>","</B>");//設定高亮顯示的格式<B>keyword</B>,此為預設的格式
- Highlighter highlighter = new Highlighter(simpleHtmlFormatter,scorer);
- highlighter.setTextFragmenter(new SimpleFragmenter(20));//設定每次返回的字元數
- Analyzer analyzer = new StandardAnalyzer();
- for(int i=0;i<hits.length;i++){
- Document doc = searcher.doc(hits[i].doc);
- String str = highlighter.getBestFragment(analyzer, "content", doc.get("content")) ;
- System.out.println(str);
- }
- } catch (IOException e1) {
- // TODO Auto-generated catch block
- e1.printStackTrace();
- } catch (InvalidTokenOffsetsException e) {
- // TODO Auto-generated catch block
- e.printStackTrace();
- }finally{
- service.shutdown();
- }
- }
- }
lucene的highlighter高亮展示的原理:
- 根據Formatter和Scorer建立highlighter物件,formatter定義了高亮的顯示方式,而scorer定義了高亮的評分;
評分的演算法是先根據term的評分值獲取對應的document的權重,在此基礎上對文字的內容進行輪詢,獲取對應的文字出現的次數,和它在term對應的文字中出現的位置(便於高亮處理),評分並分詞的演算法為:
- publicfloat getTokenScore() {
- position += posIncAtt.getPositionIncrement();//記錄出現的位置
- String termText = termAtt.toString();
- WeightedSpanTerm weightedSpanTerm;
- if ((weightedSpanTerm = fieldWeightedSpanTerms.get(
- termText)) == null) {
- return0;
- }
- if (weightedSpanTerm.positionSensitive &&
- !weightedSpanTerm.checkPosition(position)) {
- return0;
- }
- float score = weightedSpanTerm.getWeight();//獲取權重
- // found a query term - is it unique in this doc?
- if (!foundTerms.contains(termText)) {//結果排重處理
- totalScore += score;
- foundTerms.add(termText);
- }
- return score;
- }
formatter的原理為:對搜尋的文字進行判斷,如果scorer獲取的totalScore不小於0,即查詢內容在對應的term中存在,則按照格式拼接成preTag+查詢內容+postTag的格式
詳細演算法如下:
- public String highlightTerm(String originalText, TokenGroup tokenGroup) {
- if (tokenGroup.getTotalScore() <= 0) {
- return originalText;
- }
- // Allocate StringBuilder with the right number of characters from the
- // beginning, to avoid char[] allocations in the middle of appends.
- StringBuilder returnBuffer = new StringBuilder(preTag.length() + originalText.length() + postTag.length());
- returnBuffer.append(preTag);
- returnBuffer.append(originalText);
- returnBuffer.append(postTag);
- return returnBuffer.toString();
- }
其預設格式為“<B></B>”的形式;
- Highlighter根據scorer和formatter,對document進行分析,查詢結果呼叫getBestTextFragments,TokenStream tokenStream,String text,boolean mergeContiguousFragments,int maxNumFragments),其過程為
- scorer首先初始化查詢內容對應的出現位置的下標,然後對tokenstream新增PositionIncrementAttribute,此類記錄單詞出現的位置;
- 對文字內容進行輪詢,判斷查詢的文字長度是否超出限制,如果超出文字長度提示過長內容;
- 如果獲取到指定的文字,先對單次查詢的內容進行內容的擷取(擷取值根據setTextFragmenter指定的值決定),再呼叫formatter的highlightTerm方法對文字進行重新構建
- 在本次輪詢和下次單詞出現之前對文字內容進行處理
查詢工具類
- package com.lucene.search.util;
- import java.io.File;
- import java.io.IOException;
- import java.nio.file.Paths;
- import java.util.Set;
- import java.util.concurrent.ExecutorService;
- import org.apache.lucene.analysis.Analyzer;
- import org.apache.lucene.analysis.standard.StandardAnalyzer;
- import org.apache.lucene.document.Document;
- import org.apache.lucene.index.DirectoryReader;
- import org.apache.lucene.index.IndexReader;
- import org.apache.lucene.index.MultiReader;
- import org.apache.lucene.index.Term;
- import org.apache.lucene.queryparser.classic.ParseException;
- import org.apache.lucene.queryparser.classic.QueryParser;
- import org.apache.lucene.search.BooleanQuery;
- import org.apache.lucene.search.IndexSearcher;
- import org.apache.lucene.search.MatchAllDocsQuery;
-
相關推薦
如何讓vue文件中的代碼在Sublime Text 3中高亮和智能提示
sta sublime light 彩色 沒有 智能提示 tex syn package 大家寫在Sublime Text 3中編寫vue文件時,會發現沒有代碼智能提示,清一色的黑底白字,不會像html、js一樣變成彩色,給我們帶來了很大的不便。所以需要安裝一款叫作Vue
vue文件在編輯器Sublime Text3中高亮
pack nta 方法 In tro 提高 ext3 ins text 編寫代碼時,代碼在編輯器中顯示高亮,一方面,在感官方面使人覺得很舒服;另一方面,還可以提高開發效率。下面簡單介紹vue文件在Sublime Text3 中高亮的vue插件的安裝方法:
VS程式設計,編輯WPF過程中,點選設計器中介面某一控制元件,在XAML中高亮突出顯示相應的控制元件程式碼的設定方法。
在編輯製件WPF過程中,當介面中控制元件較多時,可通過點選設計器中具體的控制元件,從而中在xaml程式碼視窗中快速跳轉到對應的部分。為了突出顯示該部分控制元件程式碼的名稱,方便視覺上直觀的觀察到被選中的控制元件對應的XAML程式碼,可以在VS中設定:選中控制元件後,高亮顯示對應的XAML
vue檔案在編輯器Sublime Text3中高亮
編寫程式碼時,程式碼在編輯器中顯示高亮,一方面,在感官方面使人覺得很舒服;另一方面,還可以提高開發效率。下面簡單介紹vue檔案在Sublime Text3 中高亮的vue外掛的安裝方法: 第一步:安裝Package Control 第二步:執
如何在搜尋頁面中高亮顯示關鍵字
上個周的 高亮顯示關鍵字問題困擾了我一段時間,還好在週五解決了,而且顯示效果也還不錯. 通過呼叫BEAN的字串替換功能,可以實現關鍵字的高亮顯示. 以下是JAVABEAN Replace.java package util; public class Replace {
基於vue的實時搜尋,在結果中高亮顯示關鍵詞
1)利用oninput屬性來觸發搜素功能 2)利用RegExp來對字串來全域性匹配關鍵字,利用replace方法來對匹配的關鍵字進行嵌入高亮的<span class="gaoliang">標籤,最後利用v-html來嵌入html標籤來達到關鍵字高亮顯示程式碼
如何讓vue檔案中的程式碼在Sublime Text 3中高亮?
大家寫在Sublime Text 3中編寫vue檔案時,會發現沒有程式碼智慧提示,清一色的黑底白字,不會像html、js一樣變成彩色,給我們帶來了很大的不便。所以需要安裝一款叫作Vue Syntax Highlight的外掛,它不僅可以使程式碼高亮起來,還能進行
Lucene高亮顯示及中文分詞
直接demo,不廢話 建立一個Maven 在pom.xml貼上依賴 <dependencies> <dependency> <groupId>org.apache.lucene</groupId> <art
richTextBox中高亮顯示選中字串或文字
最近開發程式需要對一段文字中的某個字串進行高亮顯示,網上找了下資料,例項驗證如下: private void 突出顯示(string 要查詢字串) { //首先找到要查詢字串的起始位置 int 開始位置=richTextBox短語顯示.Find(要查詢字串
3.6 Lucene基本檢索+關鍵詞高亮+分頁
trac 16px b- 標註 enter author amp 影響 重要 3.2節我們已經運行了一個Lucene實現檢索的小程序,這一節我們將以這個小程序為例,講一下Lucene檢索的基本步驟,同時介紹關鍵詞高亮顯示和分頁返回結果這兩個有用的技巧。 一、Lucene檢索
Lucene筆記35-Lucene的擴充套件-高亮索引檔案
一、對索引檔案新增高亮 現在我們有一些索引檔案,怎麼對這些索引檔案新增高亮呢?首先需要根據搜尋域和值找到這篇文件,然後通過文件獲取域值,再將域值交給highlighter進行加工並返回,這個時候,返回的值就是新增過高亮的了。 二、程式碼展示 package com.wsy; imp
Lucene筆記34-Lucene的擴充套件-高亮基礎
一、高亮顯示用到的類 Fragmenter:拿到一個字串之後,對字串進行分段 QueryScorer:查詢評分,將評分最高的展示給使用者 Encoder:顯示出來的文字有兩種,一種是SimpleEncode(忽略掉HTML標籤),一種是DefaultEncode(展示HTM
lucene 中文分詞和結果高亮顯示
要使用中文分詞要加入新的依賴 smartcn <!-- https://mvnrepository.com/artifact/org.apache.lucene/lucene-analyzers-smartcn --> <dependency> &
lucene中文分詞以及高亮顯示
這篇部落格介紹一下如何在Lucene中使用中文分詞以及高亮顯示查詢結果中與搜尋匹配的部分 1.在pom.xml中加入相關依賴 <!-- 高亮顯示 --> <dependency> <groupId&g
Lucene學習篇之高亮搜尋結果
前言: import org.apache.lucene.document.Document; import org.apache.lucene.index.DirectoryReader; import org.apache.lucene.index.IndexRe
如何使用 Lucene 做網站高亮搜尋功能?
作者 | 倪升武 責編 | 胡巍巍 現在基本上所有網站都支援搜尋功能,現在搜尋的工具有很多,比如Solr、Elasticsearch,它們都是基於 Lucene 實現的,各有各的使用場景。Lucene 比較靈活,中小型專案中使用的比較多,我個人也比較喜歡用。
Lucene學習之高亮顯示
在搜尋引擎中我們經常會看到這樣的情景: 紅色部分我們稱之為高亮顯示,lucene提供了HighLighter模組來實現這一功能。 高亮顯示模組通常包含兩個獨立的功能,首先是動態拆分,就是從匹配搜尋的大量文字中選取一小部分句子。第二個內容就是高亮顯示。 我們先來看下高亮顯示的原理:
Lucene多欄位查詢&高亮顯示
在百度搜索的時候,查詢的關鍵詞會高亮顯示 在搜尋一個關鍵詞的時候,有可能這個關鍵詞在title和content中,搜尋的時候要把結果全部顯示出來 例項說明 package com.bart.lucene.mutilseacher; import
全文檢索Lucene(三)--中文分詞與高亮顯示
一、中文分詞smartcn 二、檢索結果高亮顯示實現 首先,建立maven專案,新增相關依賴。<dependencies> <dependency> <groupId>org.apache.lucene</g
一步一步跟我學習lucene(11)---lucene搜尋之高亮顯示highlighter
highlighter介紹 這幾天一直加班,部落格有三天沒有更新了,望見諒;我們在做查詢的時候,希望對我們自己的搜尋結果與搜尋內容相近的地方進行著重顯示,就如下面的效果 這裡我們搜尋的內容是“一步一步跟我學習lucene”,搜尋引擎展示的結果中對使用者的輸入資訊進行了配色方