
遷移學習基本知識
本文用於瞭解遷移學習的基本知識!!!
1. 什麼是遷移學習?
遷移學習也稱為歸納遷移、領域適配,其目標是將某個領域或任務上學習到的知識或模式應用到不同的但相關的領域或問題中。例如學習走路的技能可以用來學習跑步、學習識別轎車的經驗可以用來識別卡車等。
2. 遷移學習的主要思想?
從相關的輔助領域中遷移標註資料或知識結構、完成或改進目標領域或任務的學習效果。
3. 遷移學習研究的意義?
在很多工程實踐中,為每個應用領域收集標註資料代價十分昂貴、甚至是不可能的,因此從輔助領域或任務中遷移現有的知識結構從而完成或改進目標領域任務是十分必要的、是源於實踐需求的重要研究問題。
4. 遷移學習與傳統機器學習相比的特點?
遷移學習放寬了傳統機器學習訓練資料和測試資料服從獨立同分布這一假設,從而使得參與學習的領域或任務可以服從不同的邊緣概率分佈或條件概率分佈。
5. 遷移學習與半監督學習的比較?
雖然傳統半監督學習可以解決資料稀疏性,但其要求目標領域存在相當程度的標註資料;當標註資料十分稀缺且獲取代價太大時,仍然需要從輔助領域遷移知識來提高目標領域的學習效果。
6. 遷移學習問題的描述?
遷移學習設計領域和任務兩個重要概念。
領域D定義為由d維特徵空間X和邊緣概率分佈P(x)組成;
任務T定義為有類別空間Y和預測模型f(x)(條件概率分佈)組成
7. 檢視領域間概率分佈的差異性?
使用PCA方法將兩個領域的資料降為二維後進行視覺化。
8. 輸入空間與特徵空間的關係?
所有特徵向量存在的空間稱為特徵空間。特徵空間的每一維對應於一個特徵,有時假設輸入空間與特徵空間為相同的空間;有時假設輸入空間與特徵空間為不同的空間,將例項從輸入空間對映到特徵空間。
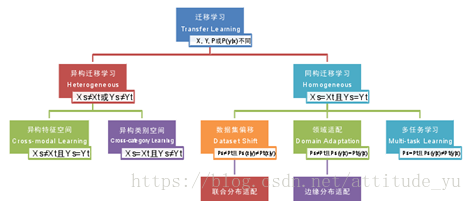
9. 遷移學習的分類?
按照特徵空間、類別空間、邊緣概率分佈、條件概率分佈進行分類
分為兩大類:異構遷移學習(源領域和目標領域特徵空間不同或類別空間不同)、同構遷移學習(源領域和目標領域特徵空間相同且類別空間相同)
10. 無監督遷移學習的特徵表示法?
無監督遷移學習即目標領域沒有標註資料的遷移學習任務。
通過學習新的特徵表示Φ(x),使得領域間共享特性增強而獨享特性減弱。
其是基於假設:特徵空間中的部分特徵是領域獨享的,而另一部分特徵是領域共享的且可泛化的;或者存在一個領域間共享的且可泛化的隱含特徵空間,該空間可以由特徵學習演算法在減小領域間概率分佈差異的準則下抽取得到。
特徵表示法可分為兩個子類:隱含表徵學習法和概率分佈適配法。
a.隱含特徵表示法:通過分析輔助領域和目標領域的大量無標註樣例來構建抽象特徵表示,從而隱式地縮小領域間的分佈差異;
b.概率分佈適配法:通過懲罰或移除在領域間統計可變的特徵、或通過學習子空間嵌入表示來最小化特定距離函式,從而顯式地提升輔助領域和目標領域的樣本分佈相似度。
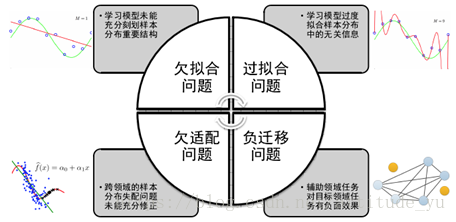
11. 遷移學習問題的主要問題挑戰?
包括經典機器學習的過擬合、欠擬合問題,以及遷移學習特有的欠適配、負遷移問題;
a.負遷移:輔助領域任務對目標領域任務有負面效果,目前從演算法設計角度對負遷移問題研究的主要思想是減少在領域間遷移的知識結構,例如僅在領域間共享模型的先驗概率、而不共享模型引數或似然函式。
b.欠適配:跨領域的概率分佈適配問題未能充分修正。
c.欠擬合:學習模型未能充分刻劃概率分佈的重要結構。
d.過擬合:學習模型過度擬合樣本分佈的無關資訊。
總而言之:過擬合和欠擬合針對的是某個領域的學習模型效能好壞,欠適配和負遷移針對的是輔助領域知識結構或模式對目標領域學習模型效能的影響。
12. 現有的概率分佈相似性度量函式有哪些?
最大均值差異、佈雷格曼散度等。
13. 遷移學習與機器學習的關係?
遷移學習強調的是在不同但是相似的領域、任務和分佈之間進行知識的遷移。從本質上講,遷移學習就是將已有領域的資訊和知識運用於不同但相關領域中去的一種新的機器學習方法。遷移學習不要求相似領域服從相同的概率分佈,其目標是將源領域裡面已有的知識和資訊,通過一定的技術手段將這部分知識遷移到新領域中,進而解決目標領域標籤樣本資料較少甚至沒有標籤的學習問題。
14. 根據遷移場景將遷移學習分類?
歸納遷移學習:源和目標學習任務不同。
直推式遷移學習:源和目標學習任務相同。
無監督遷移學習:目標領域和源領域資料都沒有標籤。
15. 根據遷移方法將遷移學習分類?
基於模型的遷移學習:通過共享源領域和目標領引數實現遷移。
基於例項的遷移學習:假設源領域的部分資料可通過更新權重,在目標領域得到再利用。
基於特徵表示的遷移學習:試圖找到原始資料的新特徵表示,減小領域間分佈差異。
基於相關性知識的遷移學習:把資料間關係從源領域遷移到目標領域。
16. 域適應(域適配)?
屬於遷移學習中的同構遷移,即源域和目標域的特徵空間和類別空間相同,但資料分佈不同。
域適應根據目標領域是否有標籤,分為無監督(目標域無標籤)和半監督(目標域有少量標籤)。
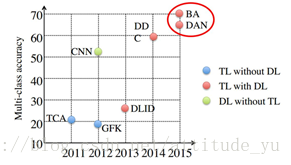
17. 深度遷移學習方法(BA, DDC, DAN)比傳統遷移學習方法(TCK, GFK)精度高:
18. 深度學習的可遷移性?
前面幾層學習到的是通用的特徵(general feature);隨著網路層次的加深,後面的網路更偏重於學習任務特定的特徵(specifc feature),所以可將通用特徵遷移到其它領域。
19. 最簡單的深度網路遷移:Finetune(Finetuning,微調)
finetune 就是利用別人已經訓練好的網路,固定前面若干層的引數,只針對我們的任務,微調後面若干層。因為在實際的應用中,我們通常不會針對一個新任務,就去從頭開始訓練一個神經網路。這樣的操作顯然是非常耗時的。尤其是,我們的訓練資料不可能像 ImageNet 那麼大,可以訓練出泛化能力足夠強的深度神經網路。即使有如此之多的訓練資料,我們從頭開始訓練,其代價也是不可承受的。
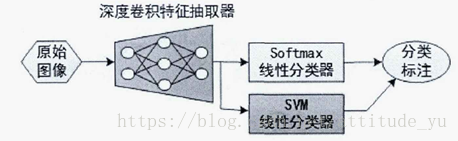
20. 基於CNN的遷移學習?
在當前計算機視覺領域的任務中,所提出的的方法已普遍使用深度遷移的策略進行預訓練。使用大規模影象資料集對深度CNN模型進行訓練,比如ImageNet,由於樣本和引數的數量都十分龐大,即使使用GPU加速也會花費較長的訓練時間。但深度CNN體系結構的另一個優勢便是經過預訓練的網路模型可以實現網路結構與引數資訊的分離,所以只要網路結構一致,便可以利用已經訓練好的權重引數構建並初始化網路,極大的節省了網路的訓練時間。
步驟:首先在大規模資料集上訓練深度CNN模型學習資料集的通用特徵,之後通過在新任務的小樣本資料集上的網路微調,即保留訓練好模型中所有卷積層的引數,只是替換最後一層全連線層。從而可以使網路模型進一步學習到新任務資料集中新的深度卷積特徵,最後增加 softmax層可實現分類。
20.Finetune的優點:
a.不需要針對新任務從頭開始訓練網路,節省了時間成本
b.預訓練好的模型通常都是在大資料集上進行的,無形中擴充了我們的訓練資料,使得模型更魯棒、泛化能力更好,提升了訓練精度
Finetune的缺點:
a.無法處理訓練資料和測試資料分佈不同的情況,因為Finetune的基本假設是訓練資料和測試資料服從相同的資料分佈
21.深度網路自適應遷移:
增加自適應層,然後在這些層加入自適應度量,最後對網路進行Finetune。
參考資料:
1. 龍明盛 博士論文《遷移學習問題與方法研究》
2. 張景祥 博士論文《遷移學習技術及其應用研究》
3. 王晉東 《遷移學習簡明手冊》