
【CUDA並行程式設計系列(4)】CUDA記憶體
前言
CUDA並行程式設計系列是本人在學習CUDA時整理的資料,內容大都來源於對《CUDA並行程式設計:GPU程式設計指南》、《GPU高效能程式設計CUDA實戰》和CUDA Toolkit Documentation的整理。通過本系列整體介紹CUDA並行程式設計。內容包括GPU簡介、CUDA簡介、環境搭建、執行緒模型、記憶體、原子操作、同步、流和多GPU架構等。
本系列目錄:
本章將介紹CUDA的記憶體結構,通過例項展示暫存器和共享記憶體的使用。
CUDA記憶體結構
GPU的記憶體結構和CPU類似,但也存在一些區別,GPU的記憶體中可讀寫的有:暫存器(registers)、Local memory、共享記憶體(shared memory)和全域性記憶體(global memory),只讀的有:常量記憶體(constant memory)和紋理記憶體(texture memory)。
CUDA Toolkit Document給出的的記憶體結構如下圖所示:
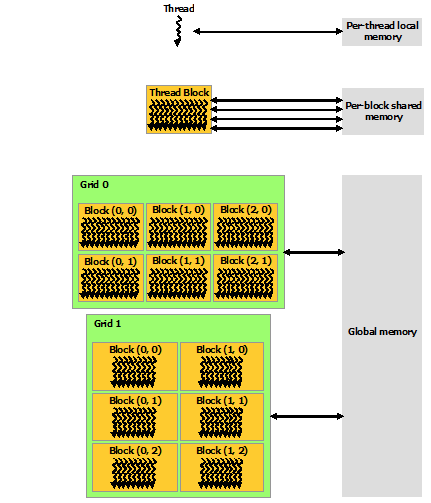
每個執行緒都有獨立的暫存器和Local memory,同一個block的所有執行緒共享一個共享記憶體,全域性記憶體、常量記憶體和紋理記憶體是所有執行緒都可訪問的。全域性記憶體、常量記憶體和紋理記憶體對程式的優化有特殊作用。
暫存器
與CPU不同,GPU的每個SM(流多處理器)有成千上萬個暫存器,在GPU技術簡介中已經提到,SM類似於CPU的核,每個SM擁有多個SP(流處理器),所有的工作都是在SP上處理的,GPU的每個SM可能有8~192個SP,這就意味著,SM可同時執行這些數目的執行緒。
暫存器是每個執行緒私有的,並且GPU沒有使用暫存器重新命名機制,而是致力於為每一個執行緒都分配真實的暫存器,CUDA上下文切換機制非常高效,幾乎是零開銷。當然,這些細節對程式設計師是完全透明的。
和CPU一樣,訪問暫存器的速度是非常快的,所以應儘量優先使用暫存器。無論是CPU還是GPU,通過暫存器的優化方式都會使程式的執行速度得到很大提高。
舉一個例子:
for (int i = 0; i < size; ++i)
{
sum += array[i];
}sum如果存於記憶體中,則需要做size次讀/寫記憶體的操作,而如果把sum設定為區域性變數,把最終結果寫回記憶體,編譯器會將其放入暫存器中,這樣只需1次記憶體寫操作,將大大節約執行時間。
Local memory
Local memory和暫存器類似,也是執行緒私有的,訪問速度比暫存器稍微慢一點。事實上,是由編譯器在暫存器全部使用完的時候自動分配的。在優化程式的時候可以考慮減少block的執行緒數量以使每個執行緒有更多的暫存器可使用,這樣可減少Local memory的使用,從而加快執行速度。
共享記憶體
共享記憶體允許同一個block中的執行緒讀寫這一段記憶體,但執行緒無法看到也無法修改其它block的共享記憶體。共享記憶體緩衝區駐留在物理GPU上,所以訪問速度也是很快的。事實上,共享記憶體的速度幾乎在所有的GPU中都一致(而全域性記憶體在低端顯示卡的速度只有高階顯示卡的1/10),因此,在任何顯示卡中,除了使用暫存器,還要更有效地使用共享記憶體。
共享記憶體的存在就可使執行執行緒塊中的多個執行緒之間相互通訊。共享記憶體的一個應用場景是執行緒塊中多個執行緒需要共同操作某一資料。考慮一個向量點積運算的例子:
(x1, x2, x3, x4 ) * (y1, y2, y3, y4) = x1y1 + x2y2 + x3y3 + x4y4
和向量加法一樣,向量點積也可以在GPU上平行計算,每個執行緒將兩個相應的元素相乘,然後移到下兩個元素,執行緒每次增加的索引為匯流排程的數量,下面是實現這一步的程式碼:
const int N = 33 * 1024;
const int threadsPerBlock = 256;
__global__ void dot( float *a, float *b, float *c )
{
__shared__ float cache[threadsPerBlock];
int tid = threadIdx.x + blockIdx.x * blockDim.x;
int cacheIndex = threadIdx.x;
float temp = 0;
while (tid < N)
{
temp += a[tid] * b[tid];
tid += blockDim.x * gridDim.x;
}
cache[cacheIndex] = temp;
}CUDA C使用__shared__修飾符申明共享記憶體的變數。在每個執行緒中分別計算相應元素的乘積之和,並儲存在共享記憶體變數cache對應的索引中,可以看出,如果只有一個block,那麼所有執行緒結束後,對cache求和就是最終結果。當然,實際會有很多個block,所以需要對所有block中的cache求和,由於共享記憶體在block之間是不能訪問的,所以需要在各個block中分部求和,並把部分和儲存在陣列中,最後在CPU上求和。block中分部求和程式碼如下:
__global__ void dot( float *a, float *b, float *c ) {
__shared__ float cache[threadsPerBlock];
int tid = threadIdx.x + blockIdx.x * blockDim.x;
int cacheIndex = threadIdx.x;
float temp = 0;
while (tid < N) {
temp += a[tid] * b[tid];
tid += blockDim.x * gridDim.x;
}
cache[cacheIndex] = temp;
//同步
__syncthreads();
//分部求和
int i = blockDim.x/2;
while (i != 0) {
if (cacheIndex < i)
cache[cacheIndex] += cache[cacheIndex + i];
__syncthreads();
i /= 2;
}
if (cacheIndex == 0)
c[blockIdx.x] = cache[0];
}__syncthreads()是執行緒同步函式,呼叫這個函式確保線上程塊中所有的執行緒都執行完__syncthreads()之前的程式碼,在執行後面的程式碼,當然,這會損失一定效能。
當執行__syncthreads()之後的程式碼,我們就能確定cache已經計算好了,下面只需要對cache求和就可以了,最簡單的就是用一個for迴圈計算。但是,這相當只有一個執行緒在起作用,執行緒塊其它執行緒都在做無用功,
使用規約執行是一個更好地選擇,即每個執行緒將cache中的兩個值相加起來,然後結果儲存會cache中,規約的思想如下圖所示。
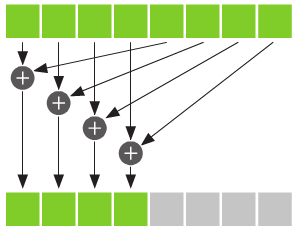
按這種方法,每次將會使資料減少一半,只需執行log2(threadsPerBlock)個步驟後,就能得到cache中所有值的總和。
最後使用如下程式碼將結果儲存在c中:
if (cacheIndex == 0)
c[blockIdx.x] = cache[0];這是因為只有一個值需要寫入,用一個執行緒來操作就行了,如果不加if,那麼每個執行緒都將執行一次寫記憶體操作,浪費大量的執行時間。
最後,只需要在CPU上把c中的值求和就得到了最終結果。下面給出完整程式碼:
#include <stdio.h>
const int N = 33 * 1024;
const int threadsPerBlock = 256;
const int blocksPerGrid = (N + threadsPerBlock -1) / threadsPerBlock;
__global__ void dot( float *a, float *b, float *c )
{
__shared__ float cache[threadsPerBlock];
int tid = threadIdx.x + blockIdx.x * blockDim.x;
int cacheIndex = threadIdx.x;
float temp = 0;
while (tid < N)
{
temp += a[tid] * b[tid];
tid += blockDim.x * gridDim.x;
}
cache[cacheIndex] = temp;
//同步
__syncthreads();
//規約求和
int i = blockDim.x/2;
while (i != 0)
{
if (cacheIndex < i)
{
cache[cacheIndex] += cache[cacheIndex + i];
}
__syncthreads();
i /= 2;
}
if (cacheIndex == 0)
{
c[blockIdx.x] = cache[0];
}
}
int main(int argc, char const *argv[])
{
float *a, *b, *partial_c;
float *dev_a, *dev_b, *dev_partial_c;
a = (float*)malloc( N*sizeof(float) );
b = (float*)malloc( N*sizeof(float) );
partial_c = (float*)malloc( blocksPerGrid*sizeof(float));
cudaMalloc(&dev_a, N*sizeof(float));
cudaMalloc(&dev_b, N*sizeof(float));
cudaMalloc(&dev_partial_c, blocksPerGrid*sizeof(float));
for (int i=0; i < N; ++i)
{
a[i] = i;
b[i] = i * 2;
}
cudaMemcpy(dev_a, a, N*sizeof(float), cudaMemcpyHostToDevice);
cudaMemcpy(dev_b, b, N*sizeof(float), cudaMemcpyHostToDevice);
dot<<<blocksPerGrid,threadsPerBlock>>>( dev_a, dev_b, dev_partial_c );
cudaMemcpy(partial_c, dev_partial_c, blocksPerGrid*sizeof(float), cudaMemcpyDeviceToHost);
int c = 0;
for (int i=0; i < blocksPerGrid; ++i)
{
c += partial_c[i];
}
cudaFree(dev_a);
cudaFree(dev_b);
cudaFree(dev_partial_c);
free(a);
free(b);
free(partial_c);
return 0;
}常量記憶體
常量記憶體,通過它的名字就可以猜到它是隻讀記憶體。常量記憶體其實只是全域性記憶體的一種虛擬地址形式,並沒有特殊保留的常量記憶體塊。記憶體的大小為64KB。常量記憶體可以在編譯時申明為常量記憶體,使用修飾符__constant__申明,也可以在執行時通過主機端定義為只讀記憶體。常量只是從GPU記憶體的角度而言的,CPU在執行時可以通過呼叫cudaCopyToSymbol來改變常量記憶體中的內容。
全域性記憶體
GPU的全域性記憶體之所以是全域性記憶體,主要是因為GPU與CPU都可以對它進行寫操作,任何裝置都可以通過PCI-E匯流排對其進行訪問。在多GPU系統同,GPU之間可以不通過CPU直接將資料從一塊GPU卡傳輸到另一塊GPU卡上。在呼叫核函式之前,使用cudaMemcpy函式就是把CPU上的資料傳輸到GPU的全域性記憶體上。
紋理記憶體
和常量記憶體一樣,紋理記憶體也是一種只讀記憶體,在特定的訪問模式中,紋理記憶體能夠提升程式的效能並減少記憶體流量。紋理記憶體最初是為圖形處理程式而設計,不過同樣也可以用於通用計算。由於紋理記憶體的使用非常特殊,有時使用紋理記憶體是費力不討好的事情。因此,對於紋理記憶體,只有在應用程式真正需要的時候才對其進行了解。主要應該掌握全域性記憶體、共享記憶體和暫存器的使用。
參考文獻
- 庫克. CUDA並行程式設計. 機械工業出版社, 2014.
- 桑德斯. GPU高效能程式設計CUDA實戰. 機械工業出版社, 2011.
- R. Couturier, Ed., Designing Scientific Applications on GPUs, CRC Press, 2013.