
HDU2665 主席樹原理解決靜態區間第K大值問題總結 有詳細圖解和程式碼解釋
鄙人不才,剛學習了一點主席樹,想自己來寫一篇關於主席樹的詳解,主要針對主席樹解決靜態(無修改)區間內第K大值的問題,可以參考HDU 2665。解決其他的問題的主席樹演算法等自己搞懂後再補上。下文如果有什麼錯誤還請指出,感激不盡!
感謝以下博文對主席樹的講解:
1.主席樹1
2.主席樹2
3.主席樹3
前置技能:
1.線段樹。
2.字首和。
3.sort函式、unique函式以及lower_bound函式的使用方法。
主席樹又叫函式式線段樹,其實就是多顆線段樹的相互連線形成的一種資料結構。主席樹這個名字和它的功能毛關係都沒有,如果你樂意,叫它狗蛋樹都可以。其時間複雜度和空間複雜度都為為 O(nlogn).
言歸正傳,首先來看一下求靜態區間第K大值的問題。平常的做法是先將該區間排序,然後求出第K大值,一旦求多組區間第K大值的話,時間複雜度就很高了。這時候就得用到主席樹。
我們先來簡化一下問題:求整個區間的第K大值問題。我們可以用線段樹解決,讓線段樹的第 i 個葉子節點表示原陣列中排第 i 的有多少個,而其他節點表示排第L~R 的有多少個,其中L、R 就是它控制的範圍[L,R] 。例如,給你一組數:1,2,2,2,4,4,8. 讓你求第5 小的數,你發現排第 1~4 小的數分別有 1,3,2,1 個,很明顯排第5小的數在前面紅色的數字 2 表示的數中,也就是數字4。
現在再來考慮求任意區間的第K大值。這裡利用到了字首和的知識,比如給你一組數讓你求區間[L,R] 內的和,一個簡單的方法就是求出字首和 sum[i]=a[1]+a[2]+…+a[i] ,然後讓sum[R]-sum[L-1] 就是結果。這裡也是一樣,假設有 n 個數,我們需要建立n 顆結構完全相同(即節點個數和位置等都相同,只是節點表示的值不同)的線段樹
為什麼這樣是可行的呢?前面說過了因為所有的線段樹都是同構的,每個節點代表的意思相同,都是前 i 個數中排在第 L~R 的數的個數。第 i 和第 j-1 顆線段樹一相減就表示在第 j-1 ~ i 個數中排在第 L~R 的數的個數。這樣說起來可能有點繞,下面讓我們看下圖。
一、建樹
下面的圖針對的是資料:1,4,2,3所建的樹。
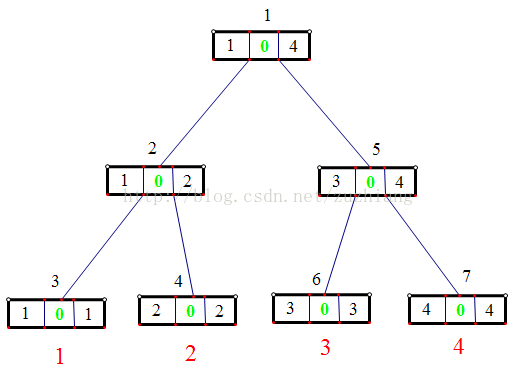
上圖是初始化時的狀況,這時候還沒往樹中插入任何元素。圖中每個矩形塊表示一個節點,其中間綠色的數字表示當前數形成的線段樹中排第L~R 的數的個數,其中L、R是這個節點所能表示的範圍 [L,R]。矩形的左右兩端的數就是這個節點表示的範圍L和R了。至於節點外的數字可以看作是節點的編號,從1開始,按照中根遍歷的順序編號。對於每個葉子節點下面的紅色數字表示的是在原陣列中排第幾。第 i 個葉子節點自然是表示排第 i 了。


上圖分別為插入第1個數和插入第2個數所形成的線段樹。我們將上面兩圖的對應節點相減一下,是不是就得到了只插入第 2 個數時候形成的線段樹呢?這裡我想再強調一點,線段樹的第 i 個葉子節點儲存的不是數的值,而是在原陣列中排第 i 的數有多少個,而其他節點表示的是排第 L~R 的數有多少個,其中L、R 就是這個節點所能表示的範圍 [L,R]。
二、更新
上面說到了,如果原陣列有n 個節點的話需要建立n 個線段樹,用腳指頭想都會覺得十分耗費空間。我們發現,第 i 個線段樹是在第i-1 個線段樹的基礎上改變了一些值而來的。所以,我們可不可以共用那些沒有改動的值呢?當然是可以的了。

如上圖所示,插入第 1 個數形成的線段樹和初始化時的線段樹的改動的部分就是圖中紅線圈起來的部分。所以我們只需要在原線段樹的基礎上加上這些點即可,其他點共用即可。

如上圖所示,紅色的部分就是插入第 1 個數形成的線段樹,它共用了前一個線段樹的一部分。注意,這時候新節點的編號不是從1開始重新編號的。

又如上圖所示,藍色的部分就是插入第 2 個數形成的線段樹,它又共用了前一個線段樹的一部分。
正是通過考慮到插入一個數的時候只會更改log(n) 個節點,也就是樹高個節點,所以這需要新增這些節點即可,這樣一來就實現了壓縮空間的目的。
三、查詢
就如上面提到過的,如果要查詢區間 [L,R] 先要讓第R 顆線段樹減去第L 顆線段樹,然後在得到的新樹中查詢,其實這個過程可以一邊相減一邊查詢,因為你要查詢一個第K 大數,它所查詢經過的節點路徑是一定的。例如你要查詢第K 大數,已經得到了相減後的新樹,如果新樹根節點的左子樹中有num 個數,如果num>=k ,則說明要查詢的數在左子樹中,否則在右子樹中,利用遞迴查詢即可,當區間長度為 1 時就查詢到了。
具體實現:
我們用L、R陣列儲存節點所能表示的範圍 [L,R],sum陣列表示排第第L~R 的數的個數。tol表示節點的編號,如果編號相同,則L、R、sum表示同一個節點。當然這裡也可以用一個結構體儲存一下。
a陣列儲存原陣列,hash陣列儲存排序後的陣列,T陣列儲存插入每個元素後形成的線段樹的根節點的編號。
如果原陣列中有n 個不同的數,則我們建一個葉子節點有n 個的線段樹就可以了。它們分別排第 1~n 。獲取不同的數的個數可以用unique函式。查詢當前數排第幾可以用lower_bound函式。
總結一下:主席樹就是對原陣列的前 i 個數建一顆線段樹儲存前 i 個數的第 1~n 大值資訊,其中 n 為原陣列中不同數的個數。由於插入當前數時只改變了logn個節點的值,所以前一棵樹可以重複利用,大大節省了空間。在查詢時,利用字首和的性質,區間 [L,R] 對應的第 R顆數減去第 L-1 棵樹,得到這段區間內的第 1~n 大值資訊,然後查詢。如果左子樹中的數的個數大於要查詢的
K ,則結果在左子樹中,否則在右子樹中查詢。
下面是HDU 2665的AC程式碼,如果註釋有什麼不正確的地方還請大家多多指正~
#include<stdio.h>
#include<string.h>
#include<iostream>
#include<algorithm>
#define MAXN 100010
using namespace std;
int tol;
//若tol值相同,則L、R、sum就表示同一個節點
//L為左端點的編號,R為右端點的編號,sum表示區間[L,R]內數的個數
int L[MAXN<<5],R[MAXN<<5],sum[MAXN<<5];
int a[MAXN],T[MAXN],Hash[MAXN]; //T記錄每個元素對應的根節點
//建樹函式,建立一顆空樹
int build(int l,int r)
{ //引數表示左右端點
int mid,root=++tol;
sum[root]=0; //區間內數的個數為0
if(l<r)
{
mid=(l+r)>>1;
L[root]=build(l,mid); //構造左子樹並將左端點編號存入L
R[root]=build(mid+1,r); //構造右子樹並將右端點編號存入R
}
return root;
}
//更新函式
int update(int pre,int l,int r,int pos)
{//引數分別為:上一線段樹的根節點編號,左右端點,插入數在原陣列中排第pos
//從根節點往下更新到葉子,新建立出一路更新的節點,這樣就是一顆新樹了。
int mid,root=++tol;
L[root]=L[pre]; //先讓其等於前面一顆樹
R[root]=R[pre]; //先讓其等於前面一顆樹
sum[root]=sum[pre]+1; //當前節點一定被修改,數的個數+1
if(l<r)
{
mid=(l+r)>>1;
if(pos<=mid) L[root]=update(L[pre],l,mid,pos); //插入到左子樹
else R[root]=update(R[pre],mid+1,r,pos); //插入到右子樹
}
return root;
}
//查詢函式,返回的是第k大的數在原陣列中排第幾
int query(int u,int v,int l,int r,int k)
{ //引數分別為:兩顆線段樹根節點的編號,左右端點,第k大
//只會查詢到相關的節點
int mid,num;
if(l>=r) return l;
mid=(l+r)>>1;
num=sum[L[v]]-sum[L[u]]; //當前詢問的區間中左子樹中的元素個數
//如果左兒子中的個數大於k,則要查詢的值在左子樹中
if(num>=k) return query(L[u],L[v],l,mid,k);
//否則在右子樹中
else return query(R[u],R[v],mid+1,r,k-num);
}
int main()
{
int i,n,m,t,d,pos;
scanf("%d",&t);
while(t--)
{
scanf("%d%d",&n,&m);
for(i=1;i<=n;i++)
{
scanf("%d",&a[i]);
Hash[i]=a[i];
}
sort(Hash+1,Hash+n+1);
d=unique(Hash+1,Hash+n+1)-Hash-1; //d為不同數的個數
tol=0; //編號初始化
T[0]=build(1,d); //1~d即區間
for(i=1;i<=n;i++)
{ //實際上是對每個元素建立了一顆線段樹,儲存其根節點
pos=lower_bound(Hash+1,Hash+d+1,a[i])-Hash;
//pos就是當前數在原陣列中排第pos
T[i]=update(T[i-1],1,d,pos);
}
int l,r,k;
while(m--)
{
scanf("%d%d%d",&l,&r,&k);
pos=query(T[l-1],T[r],1,d,k);
printf("%d\n",Hash[pos]);
}
}
return 0;
}