
【九】hadoop程式設計之基於內容的推薦演算法
基於內容的協同過濾推薦演算法:給使用者推薦和他們之前喜歡的物品在內容上相似的其他物品
物品特徵建模(item profile)
以電影為例
1表示電影具有某特徵,0表示電影不具有某特徵
科幻 言情 喜劇 動作 紀實 國產 歐美 日韓 斯嘉麗的約翰 成龍 范冰冰
復仇者聯盟: 1 0 0 1 0 0 1 0 1 0 0
綠巨人: 1 0 0 1 0 0 1 0 0 0 0
寶貝計劃: 0 0 1 1 0 1 0 0 0 1 1
十二生肖: 0 0 0 1 0 1 0 0 0 1 0
演算法步驟
1.構建item profile矩陣
物品ID——標籤
tag: (1) (2) (3) (4) (5) (6) (7) (8) (9)
I1: 1 0 0 1 1 0 1 0 0
I2: 0 1 0 1 0 0 1 0 1
I3: 0 1 1 0 0 1 0 1 1
I4: 1 0 1 1 1 0 0 0 0
I5: 0 1 0 1 0 0 1 1 0
2.構建item user評分矩陣
使用者ID——物品ID
I1 I2 I3 I4 I5
U1 1 0 0 0 5
U2 0 4 0 1 0
U3 0 5 3 0 1
3.item user X item profile = user profile
使用者ID——標籤
tag: (1) (2) (3) (4) (5) (6) (7) (8) (9)
U1 1 5 0 6 1 0 6 5 0
U2 1 4 1 5 1 0 4 0 4
U3 0 9 3 6 0 3 6 4 8
值的含義:使用者對所有標籤感興趣的程度
比如: U1-(1)表示使用者U1對特徵(1)的偏好權重為1,可以看出使用者U1對特徵(4)(7)最感興趣,其權重為6
4.對user profile 和 item profile求餘弦相似度
左側矩陣的每一行與右側矩陣的每一行計算餘弦相似度
cos<U1,I1>表示使用者U1對物品I1的喜好程度,最後需要將已有評分的物品置零,不推薦該物品
專案目錄:
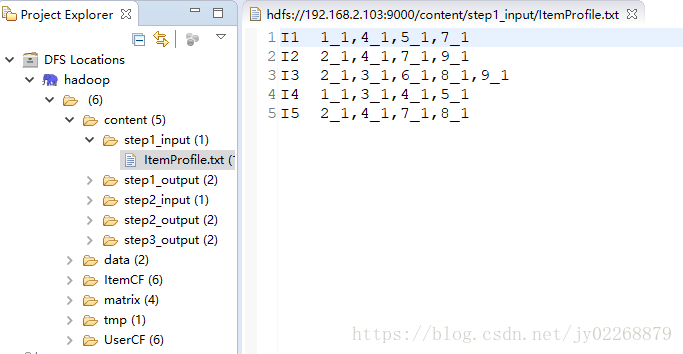
輸入檔案如下
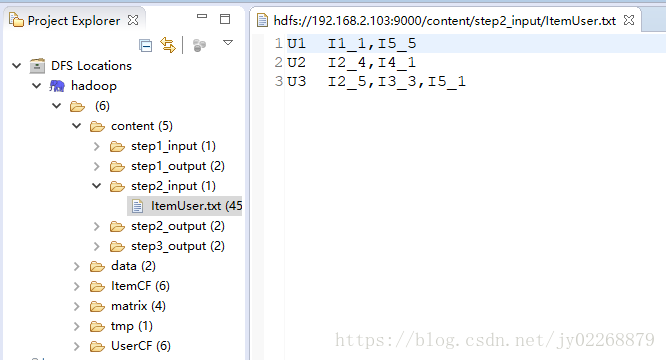
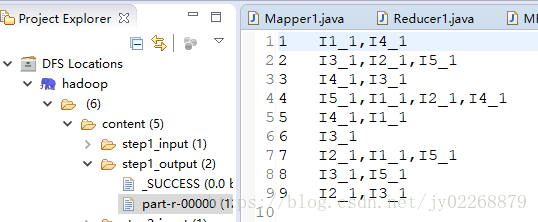
MapReduce步驟
1.將item profile轉置
輸入:物品ID(行)——標籤ID(列)——0或1 物品特徵建模
輸出:標籤ID(行)——物品ID(列)——0或1
程式碼:
mapper1
package step1;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
/**
* @author liyijie
* @date 2018年5月13日下午10:36:18
* @email [email protected]
* @remark
* @version
*
* 將item profile轉置
*/
public class Mapper1 extends Mapper<LongWritable, Text, Text, Text> {
private Text outKey = new Text();
private Text outValue = new Text();
/**
* key:1
* value:1 1_0,2_3,3_-1,4_2,5_-3
* */
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] rowAndLine = value.toString().split("\t");
//矩陣行號 物品ID
String itemID = rowAndLine[0];
//列值 使用者ID_分值
String[] lines = rowAndLine[1].split(",");
for(int i = 0 ; i<lines.length; i++){
String userID = lines[i].split("_")[0];
String score = lines[i].split("_")[1];
//key:列號 使用者ID value:行號_值 物品ID_分值
outKey.set(userID);
outValue.set(itemID+"_"+score);
context.write(outKey, outValue);
}
}
}reducer1
package step1;
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
/**
* @author liyijie
* @date 2018年5月13日下午10:56:28
* @email [email protected]
* @remark
* @version
*
*
*
* 將item profile轉置
*/
public class Reducer1 extends Reducer<Text, Text, Text, Text> {
private Text outKey = new Text();
private Text outValue = new Text();
//key:列號 使用者ID value:行號_值,行號_值,行號_值,行號_值... 物品ID_分值
@Override
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
StringBuilder sb = new StringBuilder();
//text:行號_值 物品ID_分值
for(Text text:values){
sb.append(text).append(",");
}
String line = null;
if(sb.toString().endsWith(",")){
line = sb.substring(0, sb.length()-1);
}
outKey.set(key);
outValue.set(line);
context.write(outKey,outValue);
}
}mr1
package step1;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* @author liyijie
* @date 2018年5月13日下午11:07:13
* @email [email protected]
* @remark
* @version
*
* 將item profile轉置
*/
public class MR1 {
private static String inputPath = "/content/step1_input";
private static String outputPath = "/content/step1_output";
private static String hdfs = "hdfs://node1:9000";
public int run(){
try {
Configuration conf=new Configuration();
conf.set("fs.defaultFS", hdfs);
Job job = Job.getInstance(conf,"step1");
//配置任務map和reduce類
job.setJarByClass(MR1.class);
job.setJar("F:\\eclipseworkspace\\content\\content.jar");
job.setMapperClass(Mapper1.class);
job.setReducerClass(Reducer1.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileSystem fs = FileSystem.get(conf);
Path inpath = new Path(inputPath);
if(fs.exists(inpath)){
FileInputFormat.addInputPath(job,inpath);
}else{
System.out.println(inpath);
System.out.println("不存在");
}
Path outpath = new Path(outputPath);
fs.delete(outpath,true);
FileOutputFormat.setOutputPath(job, outpath);
return job.waitForCompletion(true)?1:-1;
} catch (ClassNotFoundException | InterruptedException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return -1;
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
int result = -1;
result = new MR1().run();
if(result==1){
System.out.println("step1執行成功");
}else if(result==-1){
System.out.println("step1執行失敗");
}
}
}結果
2.item user (評分矩陣) X item profile(已轉置)
輸入:根據使用者的行為列表計算的評分矩陣
快取:步驟1輸出
輸出:使用者ID(行)——標籤ID(列)——分值(使用者對所有標籤感興趣的程度)
程式碼:
mapper2
package step2;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.text.DecimalFormat;
import java.util.ArrayList;
import java.util.List;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
/**
* @author liyijie
* @date 2018年5月13日下午11:43:51
* @email [email protected]
* @remark
* @version
*
*
* item user (評分矩陣) X item profile(已轉置)
*/
public class Mapper2 extends Mapper<LongWritable, Text, Text, Text> {
private Text outKey = new Text();
private Text outValue = new Text();
private List<String> cacheList = new ArrayList<String>();
private DecimalFormat df = new DecimalFormat("0.00");
/**在map執行之前會執行這個方法,只會執行一次
*
* 通過輸入流將全域性快取中的矩陣讀入一個java容器中
*/
@Override
protected void setup(Context context)throws IOException, InterruptedException {
super.setup(context);
FileReader fr = new FileReader("itemUserScore1");
BufferedReader br = new BufferedReader(fr);
//右矩陣
//key:行號 物品ID value:列號_值,列號_值,列號_值,列號_值,列號_值... 使用者ID_分值
String line = null;
while((line=br.readLine())!=null){
cacheList.add(line);
}
fr.close();
br.close();
}
/**
* key: 行號 物品ID
* value:行 列_值,列_值,列_值,列_值 使用者ID_分值
* */
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] rowAndLine_matrix1 = value.toString().split("\t");
//矩陣行號
String row_matrix1 = rowAndLine_matrix1[0];
//列_值
String[] cloumn_value_array_matrix1 = rowAndLine_matrix1[1].split(",");
for(String line:cacheList){
String[] rowAndLine_matrix2 = line.toString().split("\t");
//右側矩陣line
//格式: 列 tab 行_值,行_值,行_值,行_值
String cloumn_matrix2 = rowAndLine_matrix2[0];
String[] row_value_array_matrix2 = rowAndLine_matrix2[1].split(",");
//矩陣兩位相乘得到的結果
double result = 0;
//遍歷左側矩陣一行的每一列
for(String cloumn_value_matrix1:cloumn_value_array_matrix1){
String cloumn_matrix1 = cloumn_value_matrix1.split("_")[0];
String value_matrix1 = cloumn_value_matrix1.split("_")[1];
//遍歷右側矩陣一行的每一列
for(String cloumn_value_matrix2:row_value_array_matrix2){
if(cloumn_value_matrix2.startsWith(cloumn_matrix1+"_")){
String value_matrix2 = cloumn_value_matrix2.split("_")[1];
//將兩列的值相乘並累加
result+= Double.valueOf(value_matrix1)*Double.valueOf(value_matrix2);
}
}
}
if(result==0){
continue;
}
//result就是結果矩陣中的某個元素,座標 行:row_matrix1 列:row_matrix2(右側矩陣已經被轉置)
outKey.set(row_matrix1);
outValue.set(cloumn_matrix2+"_"+df.format(result));
//輸出格式為 key:行 value:列_值
context.write(outKey, outValue);
}
}
}reducer2
package step2;
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
/**
* @author liyijie
* @date 2018年5月13日下午11:43:59
* @email [email protected]
* @remark
* @version
*
* item user (評分矩陣) X item profile(已轉置)
*/
public class Reducer2 extends Reducer<Text, Text, Text, Text>{
private Text outKey = new Text();
private Text outValue = new Text();
// key:行 物品ID value:列_值 使用者ID_分值
@Override
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
StringBuilder sb = new StringBuilder();
for(Text text:values){
sb.append(text+",");
}
String line = null;
if(sb.toString().endsWith(",")){
line = sb.substring(0, sb.length()-1);
}
outKey.set(key);
outValue.set(line);
context.write(outKey,outValue);
}
}mr2
package step2;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* @author liyijie
* @date 2018年5月13日下午11:44:07
* @email [email protected]
* @remark
* @version
*
* item user (評分矩陣) X item profile(已轉置)
*/
public class MR2 {
private static String inputPath = "/content/step2_input";
private static String outputPath = "/content/step2_output";
//將step1中輸出的轉置矩陣作為全域性快取
private static String cache="/content/step1_output/part-r-00000";
private static String hdfs = "hdfs://node1:9000";
public int run(){
try {
Configuration conf=new Configuration();
conf.set("fs.defaultFS", hdfs);
Job job = Job.getInstance(conf,"step2");
//如果未開啟,使用 FileSystem.enableSymlinks()方法來開啟符號連線。
FileSystem.enableSymlinks();
//要使用符號連線,需要檢查是否啟用了符號連線
boolean areSymlinksEnabled = FileSystem.areSymlinksEnabled();
System.out.println(areSymlinksEnabled);
//新增分散式快取檔案
job.addCacheArchive(new URI(cache+"#itemUserScore1"));
//配置任務map和reduce類
job.setJarByClass(MR2.class);
job.setJar("F:\\eclipseworkspace\\content\\content.jar");
job.setMapperClass(Mapper2.class);
job.setReducerClass(Reducer2.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileSystem fs = FileSystem.get(conf);
Path inpath = new Path(inputPath);
if(fs.exists(inpath)){
FileInputFormat.addInputPath(job,inpath);
}else{
System.out.println(inpath);
System.out.println("不存在");
}
Path outpath = new Path(outputPath);
fs.delete(outpath,true);
FileOutputFormat.setOutputPath(job, outpath);
return job.waitForCompletion(true)?1:-1;
} catch (ClassNotFoundException | InterruptedException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} catch (URISyntaxException e) {
e.printStackTrace();
}
return -1;
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
int result = -1;
result = new MR2().run();
if(result==1){
System.out.println("step2執行成功");
}else if(result==-1){
System.out.println("step2執行失敗");
}
}
}結果
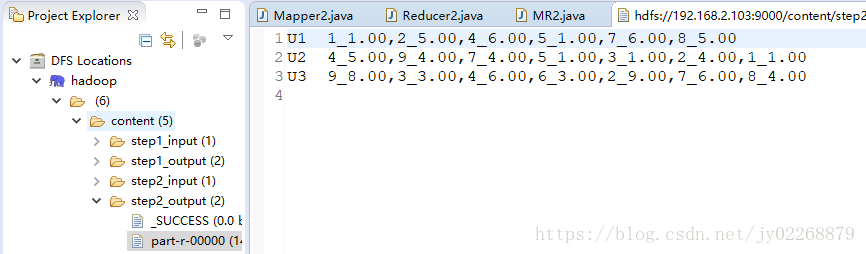
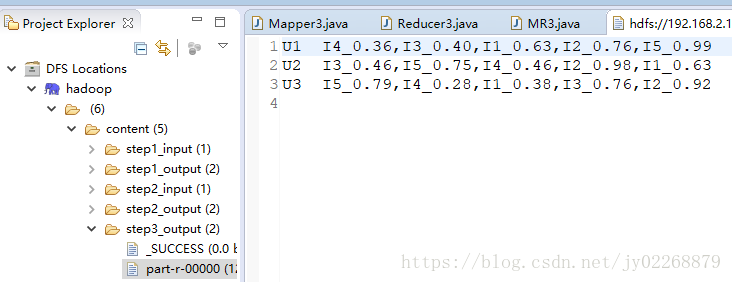
3.cos<步驟1輸入,步驟2輸出>
輸入:步驟1輸入 物品特徵建模
快取:步驟2輸出
輸出:使用者ID(行)——物品ID(列)——相似度
程式碼:
mapper3
package step3;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
import java.text.DecimalFormat;
import java.util.ArrayList;
import java.util.List;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
/**
* @author liyijie
* @date 2018年5月13日下午11:43:51
* @email [email protected]
* @remark
* @version
*
*
* cos<步驟1輸入,步驟2輸出>
*/
public class Mapper3 extends Mapper<LongWritable, Text, Text, Text> {
private Text outKey = new Text();
private Text outValue = new Text();
private List<String> cacheList = new ArrayList<String>();
// 右矩陣列值 下標右行 右值
//private Map<String,String[]> cacheMap = new HashMap<>();
private DecimalFormat df = new DecimalFormat("0.00");
/**在map執行之前會執行這個方法,只會執行一次
*
* 通過輸入流將全域性快取中的矩陣讀入一個java容器中
*/
@Override
protected void setup(Context context)throws IOException, InterruptedException {
super.setup(context);
FileReader fr = new FileReader("itemUserScore2");
BufferedReader br = new BufferedReader(fr);
//右矩陣
//key:行號 物品ID value:列號_值,列號_值,列號_值,列號_值,列號_值... 使用者ID_分值
String line = null;
while((line=br.readLine())!=null){
cacheList.add(line);
}
fr.close();
br.close();
}
/**
* key: 行號 物品ID
* value:行 列_值,列_值,列_值,列_值 使用者ID_分值
* */
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String[] rowAndLine_matrix1 = value.toString().split("\t");
//矩陣行號
String row_matrix1 = rowAndLine_matrix1[0];
//列_值
String[] cloumn_value_array_matrix1 = rowAndLine_matrix1[1].split(",");
//計算左側矩陣行的空間距離
double denominator1 = 0;
for(String column_value:cloumn_value_array_matrix1){
String score = column_value.split("_")[1];
denominator1 += Double.valueOf(score)*Double.valueOf(score);
}
denominator1 = Math.sqrt(denominator1);
for(String line:cacheList){
String[] rowAndLine_matrix2 = line.toString().split("\t");
//右側矩陣line
//格式: 列 tab 行_值,行_值,行_值,行_值
String cloumn_matrix2 = rowAndLine_matrix2[0];
String[] row_value_array_matrix2 = rowAndLine_matrix2[1].split(",");
//計算右側矩陣行的空間距離
double denominator2 = 0;
for(String column_value:row_value_array_matrix2){
String score = column_value.split("_")[1];
denominator2 += Double.valueOf(score)*Double.valueOf(score);
}
denominator2 = Math.sqrt(denominator2);
//矩陣兩位相乘得到的結果 分子
double numerator = 0;
//遍歷左側矩陣一行的每一列
for(String cloumn_value_matrix1:cloumn_value_array_matrix1){
String cloumn_matrix1 = cloumn_value_matrix1.split("_")[0];
String value_matrix1 = cloumn_value_matrix1.split("_")[1];
//遍歷右側矩陣一行的每一列
for(String cloumn_value_matrix2:row_value_array_matrix2){
if(cloumn_value_matrix2.startsWith(cloumn_matrix1+"_")){
String value_matrix2 = cloumn_value_matrix2.split("_")[1];
//將兩列的值相乘並累加
numerator+= Double.valueOf(value_matrix1)*Double.valueOf(value_matrix2);
}
}
}
double cos = numerator/(denominator1*denominator2);
if(cos == 0){
continue;
}
//cos就是結果矩陣中的某個元素,座標 行:row_matrix1 列:row_matrix2(右側矩陣已經被轉置)
outKey.set(cloumn_matrix2);
outValue.set(row_matrix1+"_"+df.format(cos));
//輸出格式為 key:行 value:列_值
context.write(outKey, outValue);
}
}
}reducer3
package step3;
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
/**
* @author liyijie
* @date 2018年5月13日下午11:43:59
* @email [email protected]
* @remark
* @version
*
* cos<步驟1輸入,步驟2輸出>
*/
public class Reducer3 extends Reducer<Text, Text, Text, Text>{
private Text outKey = new Text();
private Text outValue = new Text();
// key:行 物品ID value:列_值 使用者ID_分值
@Override
protected void reduce(Text key, Iterable<Text> values, Context context)
throws IOException, InterruptedException {
StringBuilder sb = new StringBuilder();
for(Text text:values){
sb.append(text+",");
}
String line = null;
if(sb.toString().endsWith(",")){
line = sb.substring(0, sb.length()-1);
}
outKey.set(key);
outValue.set(line);
context.write(outKey,outValue);
}
}mr3
package step3;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
/**
* @author liyijie
* @date 2018年5月13日下午11:44:07
* @email [email protected]
* @remark
* @version
*
* cos<步驟1輸入,步驟2輸出>
*/
public class MR3 {
private static String inputPath = "/content/step1_input";
private static String outputPath = "/content/step3_output";
//將step1中輸出的轉置矩陣作為全域性快取
private static String cache="/content/step2_output/part-r-00000";
private static String hdfs = "hdfs://node1:9000";
public int run(){
try {
Configuration conf=new Configuration();
conf.set("fs.defaultFS", hdfs);
Job job = Job.getInstance(conf,"step3");
//如果未開啟,使用 FileSystem.enableSymlinks()方法來開啟符號連線。
FileSystem.enableSymlinks();
//要使用符號連線,需要檢查是否啟用了符號連線
boolean areSymlinksEnabled = FileSystem.areSymlinksEnabled();
System.out.println(areSymlinksEnabled);
//新增分散式快取檔案
job.addCacheArchive(new URI(cache+"#itemUserScore2"));
//配置任務map和reduce類
job.setJarByClass(MR3.class);
job.setJar("F:\\eclipseworkspace\\content\\content.jar");
job.setMapperClass(Mapper3.class);
job.setReducerClass(Reducer3.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileSystem fs = FileSystem.get(conf);
Path inpath = new Path(inputPath);
if(fs.exists(inpath)){
FileInputFormat.addInputPath(job,inpath);
}else{
System.out.println(inpath);
System.out.println("不存在");
}
Path outpath = new Path(outputPath);
fs.delete(outpath,true);
FileOutputFormat.setOutputPath(job, outpath);
return job.waitForCompletion(true)?1:-1;
} catch (ClassNotFoundException | InterruptedException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} catch (URISyntaxException e) {
e.printStackTrace();
}
return -1;
}
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
int result = -1;
result = new MR3().run();
if(result==1){
System.out.println("step3執行成功");
}else if(result==-1){
System.out.println("step3執行失敗");
}
}
}結果
相關推薦
【九】hadoop程式設計之基於內容的推薦演算法
基於內容的協同過濾推薦演算法:給使用者推薦和他們之前喜歡的物品在內容上相似的其他物品物品特徵建模(item profile)以電影為例1表示電影具有某特徵,0表示電影不具有某特徵 科幻 言情 喜劇 動作
【九】MongoDB管理之安全性
方法 開啟 oot backup 由於 alt 集群管理 失敗 exec 要保證一個安全的MongoDB運行環境,DBA需要實施一些控制保證用戶或應用程序僅僅訪問它們需要的數據。這些措施包括但不限於: 認證機制 基於角色的訪問控制 加密 審計 一、認證機制 認證是驗證客
【181122】OpenGL程式設計之攝像漫遊VC程式碼演示原始碼
原始碼下載簡介 OpenGL程式設計之攝像漫遊VC原始碼演示,這是學程式編遊戲系列叢書中的一個例項,原始碼無錯,編譯順利。視窗中運動的雷達和飛機是可以用鍵盤控制的,↑進 ↓退 →右 ←左 UP仰 DOWM俯,程式執行後會自動搜尋視訊渲染模式,如果找不到,會給出提示,程式也就不能執行,好好研究
【Shell】Shell程式設計之for迴圈命令
bash shell提供了for命令,用於建立通過一系列值重複的迴圈,for命令的格式為: for var in list do commands done 在引數list中提供了一系列用於迭代
【原創】IOCP程式設計之聚集散播
做為IOCP應用中重要的一個方法就是被稱為“聚集-散播”的方法。非常遺憾的是在很多介紹IOCP使用的資料中,我幾乎沒有見過有專門介紹此方法的文章,因此本文就重點講述此方法。 在使用IOCP操作大量的TCP連線並處理IO請求的時候,一個很讓我們頭疼的事情就是所謂的“粘包”問題
推薦系統之基於內容推薦CB
(個性化)推薦系統構建三大方法:基於內容的推薦content-based,協同過濾collaborative filtering,隱語義模型(LFM, latent factor model)推薦。這篇部落格主要講基於內容的推薦content-based。 基於內容的推薦
基於內容推薦演算法詳解(比較全面的文章)
Collaborative Filtering Recommendations (協同過濾,簡稱CF) 是目前最流行的推薦方法,在研究界和工業界得到大量使用。但是,工業界真正使用的系統一般都不會只有CF推薦演算法,Content-based Recommendations
Machine Learning第九講【推薦系統】--(一)基於內容的推薦系統
符號介紹: 對於每一個使用者j,假設我們已經通過學習找到引數,則使用者j對電影i的評分預測值為:。 對於上面的例子:
caffe深度學習【九】目標檢測 yolo v1的caffe實現 基於VOC2007資料集
YOLO v1演算法原文的作者是在darknet框架下實現的, 原文作者的實現 ,這裡主要講的是caffe版本的YOLO實現,主要採用yeahkun寫的:點選開啟連結 其實只是步驟相對來說有點繁瑣,但是要跑通並不困難: 大致步驟包括: 1、編譯ca
【spark你媽喊你回家吃飯-05】RDD程式設計之旅基礎篇-01
1.RDD工作流程 1.1 RDD理解 RDD是spark特有的資料模型,談到RDD就會提到什麼彈性分散式資料集,什麼有向無環圖,本文暫時不去展開這些高深概念,在閱讀本文時候,大家可以就把RDD當作一個數組,這樣的理解對我們學習RDD的API是非常有幫助的。本文所有示例程式
【十九】機器學習之路——樸素貝葉斯分類
最近在看周志華《機器學習》的貝葉斯分類器這一章時覺得書上講的很難理解,很多專業術語和符號搞的我頭大,大學時候概率論我還是學的還是不錯的,無奈網上搜了搜前輩的部落格,看到一篇把樸素貝葉斯講的很簡單的文章,頓時豁然開朗。關於貝葉斯分類且聽我慢慢道來: 貝葉
Java併發程式設計隨筆【九】中被丟棄的執行緒組ThreadGroup
執行緒組的初衷是作為一種隔離的機制,當然是出於安全的考慮。但是它們從來沒有真正的履行這個承諾,它們的安全價值已經差到根本不在Java安全模型的標準工作中被提及的地步。 既然執行緒組並沒有提供所提及的任何安全功能,那麼它們到底提供了什麼功能呢?不多,它們允許你同
【十九】Spring Boot 之多資料來源和分散式事務(JTA、Atomikos、Druid、Mybatis)
1.事務開始 2.A資料來源insert 3.B資料來源insert 4.報錯 5.事務回滾(A、B資料來源都回滾) 專案目錄 pom.xml <?xml version="1.0" encoding="UTF-8"?> <projec
【異常】Hadoop分散式叢集搭建之zookeeper故障
各節點中均已安裝配置好zookeeper。 在主節點中用遠端命令啟動個節點中的zookeeper。執行成功。 然而在檢視各節點的zookeeper狀態時,主節點報錯 Error contacting service. It is probably no
【轉載】Hadoop 2.7.3 和Hbase 1.2.4安裝教程
啟動 運行 property new rop net 文本文 .tar.gz cor 轉載地址:http://blog.csdn.net/napoay/article/details/54136398 目錄(?)[+] 一、機器環境
【BZOJ3689】異或之 堆+可持久化Trie樹
ace iostream 持久化 sof stream tro urn org cst 【BZOJ3689】異或之 Description 給定n個非負整數A[1], A[2], ……, A[n]。對於每對(i, j)滿足1 <=
【16】vuex2.0 之 getter
this map 多個參數 name not 同時 方便 比較 compute 有的組件中獲取到 store 中的state, 需要對進行加工才能使用,computed 屬性中就需要寫操作函數,如果有多個組件中都需要進行這個操作,那麽在各個組件中都寫相同的函數,那就非常
【15】vuex2.0 之 modules
his 來看 暴露 方式 ets 我們 spa web space vue 使用的是單一狀態樹對整個應用的狀態進行管理,也就是說,應用中的所有狀態都放到store中,如果是一個大型應用,狀態非常多, store 就會非常龐大,不太好管理。這時vuex 提供了另外一種方式
【0002】設計模式之原則
範圍 class 變化 chan reason 一件事 ever 模式 單一職責原則 【1】單一職責原則: 要求一個接口或者類只有一個原因引起變化; 也就是一個接口或者類只有一個職責,它負責一件事情; There should never be more
【比賽】百度之星2017 初賽Round A
初賽 題意 bsp 多少 5% 答案 數字 nbsp 計算 第一題 題意:給定多組數據P,每次詢問P進制下,有多少數字B滿足條件:只要數位之和是B的倍數,該數字就是B的倍數。 題解:此題是參考10進制下3和9倍數的特殊性質。 對於10進制,ab=10*a+b=9*a+(a+