
基於機器學習的高價值使用者簡歷自動分類
一、業務介紹
對於任何網際網路招聘企業來說,求職者的簡歷庫都是核心資產。因為這是他們變現的基礎。只有擁有足夠多的簡歷,讓企業可以在該網站上獲取需要的人才,才能持續從企業客戶獲得訂單。
以獵聘網為例。獵聘網的市場定位為滿足企業中高階人才的需求。這使得獵聘向企業客戶提供的簡歷是具有一定質量的中高層企業管理者、專業技術人才等。出售這樣的簡歷資源,也是獵聘變現的主要來源。那麼在此類簡歷資源定價方面,企業需要付較高的費用來購買此類簡歷;而對於其餘的簡歷,企業僅需要付出非常低廉的成本即可獲得。因此,獵聘內部根據簡歷的資訊,將簡歷進行等級分類。
目標清晰後,那麼問題隨之而來。獵聘網獲取簡歷的最主要方式是線上註冊。網站為吸引使用者註冊,在註冊時一般只是填寫一些簡單的名片資訊。待註冊完成後選擇進行簡歷完善,填寫複雜麻煩一些個人資訊,如教育經歷和工作經歷等。最終形成一份完善的簡歷。但獵聘每天有數萬新使用者註冊。有些使用者如果找工作的意願並不強烈等原因,只是填寫了少量的職業資訊,即名片資訊,而並未完成整個簡歷的填寫。而一般情況下的手工分類在分級的過程中,使用了簡歷中多方面的資訊,如果簡歷不完整,將無法準確對簡歷進行評價。
為獲得完整的簡歷,獵聘職業顧問團隊(GCDC)需要電話聯絡該部分使用者引導完善簡歷。當然這種方式也是成本最為昂貴的。歷史資料表明,未填寫簡歷的使用者中有相當數量的高價值的使用者,而獵聘職業顧問需要能夠優先撥打這批高階使用者並提升其轉化率。這就要求將評分較高、更有可能是高階的使用者推薦給GCDC進行優先電話撥打,提高了高階使用者簡歷轉化率。
二、資料處理與模型部分
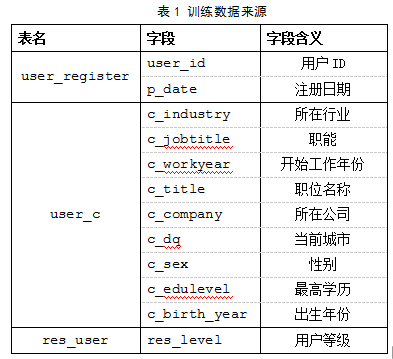
1.資料採集:訓練資料主要來自三張表——user_c、user_register和res_user。表user_c主要儲存使用者的名片資訊;user_register儲存使用者的註冊資訊;res_user儲存使用者的簡歷資訊。從這三個表中我們抽取使用者的名片資訊及評級資訊。(欄位及對應含義見表-1)
2、資料預處理。如資料去重;剔除無效資料:年齡未滿18歲或超過退休年齡、工齡小但職位高等明顯不合常識的資料。
3.選取特徵屬性:確定瞭如下8個特徵:性別(男、女)、出生年份、開始工作年份、最高學歷、職能、當前公司、當前工作的城市。為使用者等級的評判依據。
4.特徵屬性的預處理:
1)非度量屬性的二值化處理:如性別屬性。男女設定為二值屬性(男→1;女→0);
2)可度量離散特徵的有序化處理。如城市分一、二、三線城市。學歷分博士、碩士、本科、專科及以下等。
5.資料建模
k近鄰(k-Nearest Neighbors,簡稱kNN)是一種常用的監督式學習方法。其基本思想是 :相似的物件具有相同或者相近的類別(物以類聚、人以群分)。如果一個物件在特徵空間中的k個距離最近、最相似的訓練樣本大多數屬於某個類別,則該物件可以被判定屬於該類別。
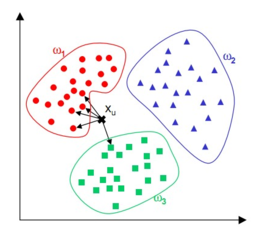
在建立模型時,對已分類資料為訓練例項。對於每一個新的例項,計算其與每個訓練例項的歐式距離,選取距離最近的k個例項(k值的選取依賴於交叉驗證),採用“多數表決”的策略,計算新樣例屬於高階使用者的可能性(打分在1~100分),並根據分數高低對使用者進行排序,推薦給使用者獲取部門作為召回策略的重要參考。
由以上計算過程可知,對於每一待分類的樣例,均需計算其與所有已分類資料的距離,然後選擇前最小的前K個值,根據這K個值多數原則來判定此樣例的所屬類別。但如果簡歷庫中已有數以千萬計的分類建立,待分類樣本也十分龐大。這給計算會帶來沉重的負擔。為提高分類效率,可以
先對分類進行粗篩選。比如將明顯為低端職位的直接劃為一類,(如”司機”、”水電工”、”家政”等)。這樣粗篩選後,在進入kNN計算環節。以此提高效率和準確率。