
Python3網路爬蟲——爬蟲基本原理
2、爬蟲基本流程



相關推薦
網絡爬蟲的基本原理
一段時間 圖片 大眾點評網 cap 客戶 都是 特點 sdn 不能 1、網絡爬蟲原理 網絡爬蟲指按照一定的規則(模擬人工登錄網頁的方式),自動抓取網絡上的程序。簡單的說,就是講你上網所看到頁面上的內容獲取下來,並進行存儲。網絡爬蟲的爬行策略分為深度優先和廣度優先。如下圖是深
what's the 爬蟲之基本原理
加載過程 遇到 都是 處理 三位數 拒絕 view 模塊 head what‘s the 爬蟲? 了解爬蟲之前,我們首先要知道什麽是互聯網 1、什麽是互聯網? 互聯網是由網絡設備(網線,路由器,交換機,防火墻等等)和一臺臺計算機連接而成,總體上像一張網一樣。 2、互聯網建
爬蟲的基本原理
大量 css選擇器 god json 方法 網站服務 ODB mysq sof 爬蟲就是獲取網頁並提取和保存信息的自動化程序 1.獲取網頁 爬蟲首先要做的就是獲取網頁,這裏就是獲取網頁的源代碼。源代碼裏包含了網頁的部分有用信息。只要把源代碼獲取到,就可以從提取信息了
爬蟲基礎---HTTP協議理解、網頁的基礎知識、爬蟲的基本原理
以及 res form 一次 發的 urn 網絡協議 位置 nsf 一、HTTP協議的理解 URL和URI 在學習HTTP之前我們需要了解一下URL、URI(精確的說明某資源的位置以及如果去訪問它) URL:Universal Resource Locator 統一資源定位
Python爬蟲知識點——爬蟲的基本原理
知識點 一個 想要 代碼 請求 原理 表達 網絡爬蟲 服務 爬蟲的基本原理 爬蟲就是獲取網頁並提取和保存信息的自動化程序 獲取網頁: 獲取網頁就是獲取網頁的源碼,只要把源碼獲取下來,就可以從中提取想要的消息 爬蟲的流程:想網站的服務器發送一個請求,返回的響應體就是網頁
爬蟲從入門到放棄——爬蟲的基本原理
顯示 sta aof 學習python visual http協議 簡單 超過 bubuko 爬蟲的基本原理:https://www.cnblogs.com/zhaof/p/6898138.html 這個文章寫的非常好,把爬蟲 的基本思路解釋的很清楚的。 一、介紹工具
909422229_資料爬蟲:爬蟲的基本原理介紹
一、什麼是爬蟲 爬蟲:請求網站並提取資料的自動化程式 百科:網路爬蟲(又被稱為網頁蜘蛛,網路機器人,在FOAF社群中間,更經常的稱為網頁追逐者),是一種按照一定的規則,自動地抓取全球資訊網資訊的程式或者指令碼。另外一些不常使用的名字還有螞蟻、自動索引、模擬程式或者蠕蟲。 如果我們把網
Linux 網路裝置驅動開發(三) —— 網路裝置驅動基本原理和框架
一、協議棧層次對比 二、Linux網路子系統 Linux網路子系統的頂部是系統呼叫介面層。它為使用者空間提供的應用程式提供了一種訪問核心網路子系統的方法(socket)。位於其下面是一個協議無關層,它提供一種通用的方法來使用傳輸層協議。然後是具體協議的實現,在Lin
Python3網路爬蟲——爬蟲基本原理
1、網路爬蟲概述爬蟲就是請求網站並提取資料的自動化程式 網路爬蟲(Web Spider),又被稱為網頁蜘蛛,是一種按照一定的規則,自動地抓取網站資訊的程式或者指令碼。 網路蜘蛛是通過網頁
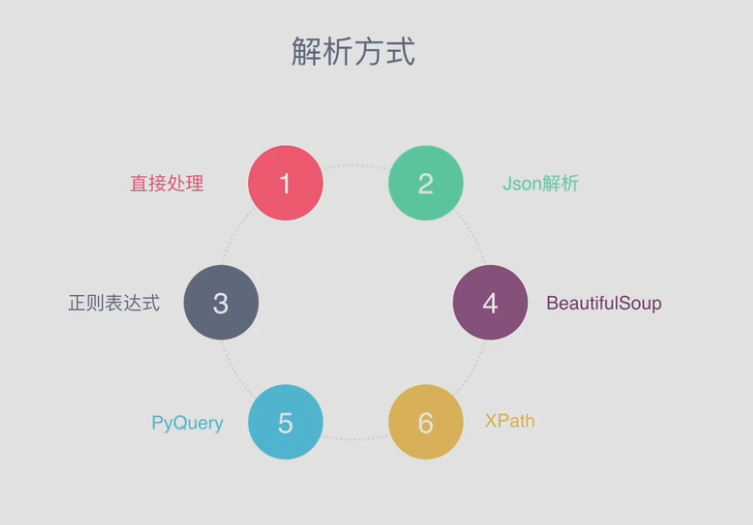
【筆記】5、初學python3網路爬蟲——正則表示式的基本使用
python3網路爬蟲——正則表示式的基本使用 學習指引:視訊教程《python3網路爬蟲實戰》 為了避免學習後短時間內遺忘,讓自己隨時可以查閱前方自己學過的知識,特意註冊csdn部落格,方便自己學習時做筆記,也方便隨時回顧。也希望自己的學習過程能給同樣初學
Python3網路爬蟲開發實戰】3-基本庫的使用 2-使用requests 1-基本用法
1. 準備工作在開始之前,請確保已經正確安裝好了requests庫。如果沒有安裝,可以參考1.2.1節安裝。2. 例項引入urllib庫中的urlopen()方法實際上是以GET方式請求網頁,而requests中相應的方法就是get()方法,是不是感覺表達更明確一些?下面通過例項來看一下:import req
Python3網絡爬蟲——三、Requests庫的基本使用
成功 ges cookies pan doc 需求 post請求 成了 bsp 一、什麽是Requests Requests是用Python語言編寫,基於urllib,采用Apache2 Licensed開元協議的HTTP庫。它比urllib更加的方便,可以節約我們大量
爬蟲基本原理
獲取 get 模式 like family asc shell ros text 推薦:(http://cuiqingcai.com/1052.html),本文是我在看了靜覓的視屏教程後的筆記. 1、一個HTML頁面裏可以有多個URL地址; 2、一個URL只能指向一個HT
【網絡爬蟲入門02】HTTP客戶端庫Requests的基本原理與基礎應用
多應用 多服務器 技術學 用戶 iis unicode licensed content sed 【網絡爬蟲入門02】HTTP客戶端庫Requests的基本原理與基礎應用 廣東職業技術學院 歐浩源 1、引言 實現網絡爬蟲的第一步就是要建立網絡連接並向服務器或網頁等
python爬蟲基本原理及入門
http safari pre col 分享圖片 ade 如果 渲染 登陸百度 爬蟲:請求目標網站並獲得數據的程序 爬蟲的基本步驟: 使用python自帶的urllib庫請求百度: import urllib.request response = urllib.req
爬蟲基本原理2
alt option mongo 種類型 瀏覽器 get 部分 json 頭部 什麽是爬? 請求?網站並提取數據的?自動化程序 爬蟲的基本流程 發起請求 通過HTTP庫向?目標站點發起請求,即發送?個Request,請求可以包含額外的headers等信息,等待服務器
python應用之爬蟲實戰1 爬蟲基本原理
協議 針對 應用領域 原理 error data target 資訊 搜索 知識內容: 1.爬蟲是什麽 2.爬蟲的基本流程 3.request和response 4.python爬蟲工具 參考:http://www.cnblogs.com/linhaifeng/arti
Django爬蟲基本原理及Request和Response分析
detail 密碼 href Go 模塊 ica 正則表達式 ons CI 一、爬蟲互聯網是由網絡設備(網線,路由器,交換機,防火墻等等)和一臺臺計算機連接而成,像一張網一樣。互聯網的核心價值在於數據的共享/傳遞:數據是存放於一臺臺計算機上的,而將計算機互聯到一起的目的就是
python3網絡爬蟲學習——基本庫的使用(1)
read 基本 類名 transport same 數字 cep 這一 服務器 最近入手學習Python3的網絡爬蟲開發方向,入手的教材是崔慶才的《python3網絡爬蟲開發實戰》,作為溫故所學的內容同時也是分享自己操作時的一些經驗與困惑,所以開了這個日記,也算是監督自己去
python3網絡爬蟲學習——基本庫的使用(3)
進行 程序 如果 www int control content cti expires 這一節我們主要講解處理異常 在我們發送請求的時候,有的時候可能網絡不好,出現了異常,程序因為報錯而終止運行,為此我們需要對其進行處理 urllib裏的error模塊定義了request