基於深度學習的目標檢測及場景文字檢測研究進展
根據本人組會PPT總結整理,複習備用。
一.目標檢測與場景文字檢測定義

目標檢測:給定一張圖片或者視訊幀,找出其中所有目標的位置,並給出每個目標的具體類別。
場景文字檢測:
文字檢測(Text Detection):對照片中存在文字的區域進行定位,即找到單詞或者文字行(word/linelevel)的邊界框(bounding box);
文字識別(Text Recognition):對定位後的文字進行識別。
將這兩個步驟合在一起就能得到文字的端到端檢測(End-to-end Recognition)。
二.影象分類模型
卷積神經網路(Convolutional Netural Network,CNN)是一種前饋神經網路,它的人工神經元可以響應一部分覆蓋範圍內的周圍單元。CNN的經典結構始於1998年的LeNet,成於2012年曆史性的AlexNet,從此大盛於影象相關領域。主要包括:
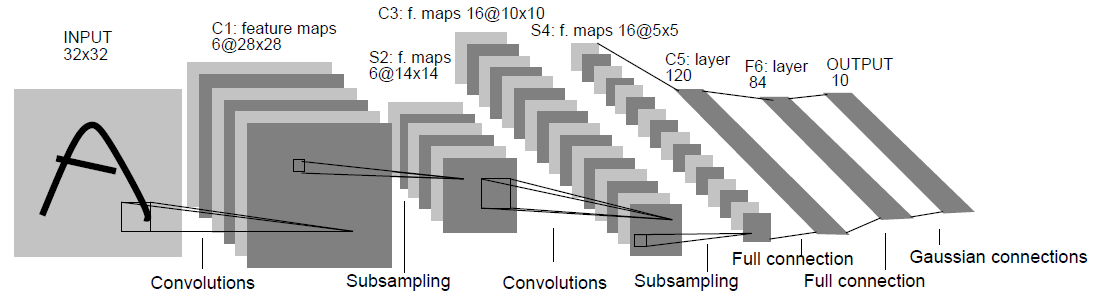
1.LeNet,1998年
2.AlexNet,2012年
3.ZF-Net,2013年
4.GoogleNet,2014年
5.VGG,2014年
6.ResNet,2015年
7.ResNeXt,2017年
8.DenseNet,2017年
1.LeNet
1998年的LeNet標誌著CNN的真正面試,但是這個模型在後來的一段時間並未能真正火起來。主要原因包括:
1)當時沒有GPU,計算能力低;
2)SVM等傳統機器學習演算法也能達到類似的效果甚至超過。
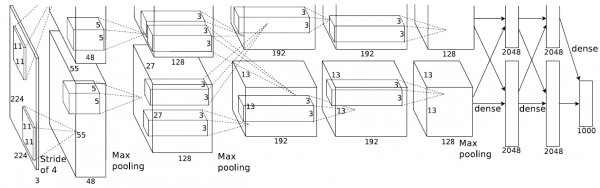
2.AlexNet
AlexNet的top-5錯誤率為15.3%,是2012年的ILSVRC大賽的冠軍。
AlexNet相比傳統的CNN有哪些重要改動呢?
1)數徐增強。如水平翻轉,隨機剪裁,平移變換,顏色,光照變換。
2)dropout。防止過擬合。
3)Relu啟用函式。代替傳統的Tanh或者Sigmoid。
4)Local Response Normalization。利用臨近的資料做歸一化。
5)Overlapping Pooling。
6)多GPU並行。
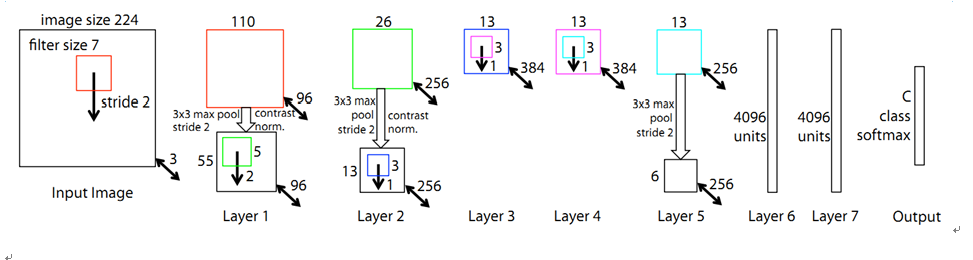
3.ZF-Net
ZF-Net的top-5錯誤率為11.2%,是2013年ILSVRC大賽的冠軍。ZF-Net基於AlexNet進行了微調。
1)使用Relu啟用函式和交叉熵代價函式;
2)使用較小的filter,以保留更多的原始畫素資訊。
4.GoogleNet
GoogleNet的top-5錯誤率為6.7%,是2014年ILSVRC大賽的冠軍。其特點是:
1)共有9個inception模組,將CNN原來的序列結構改為並行,共有22層。
2)不使用FC層,而使用平均池化代替,量級從7*7*1024變為1*1*1024,從而減少大量引數計算。
3)將同一輸入的多個修建版本輸入網路,故softmax為平均概率。
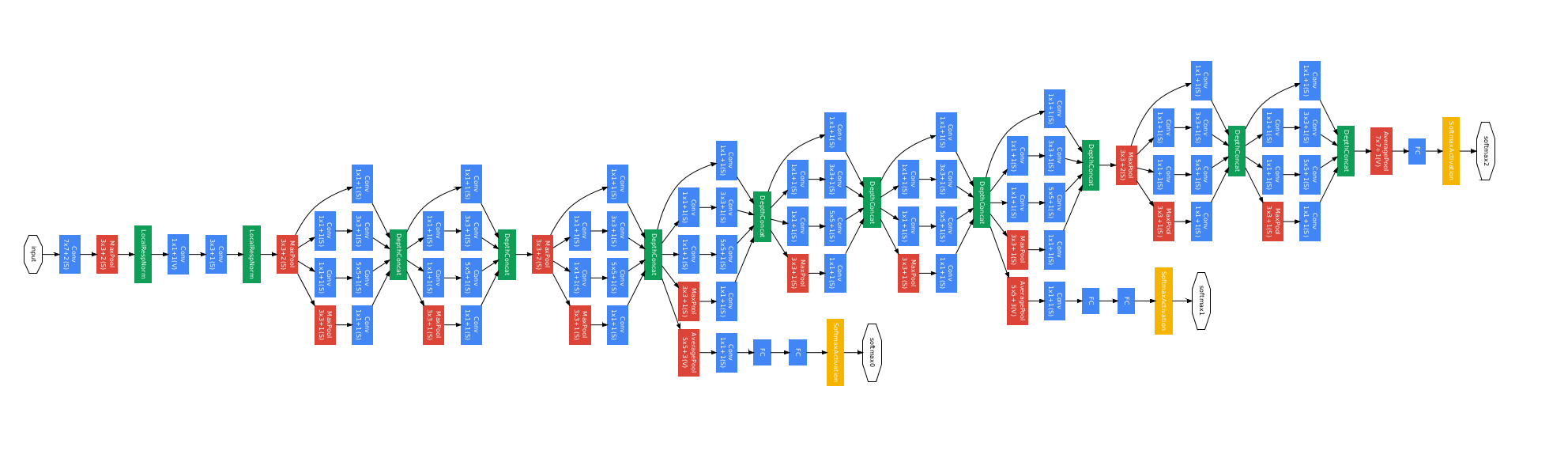
5.VGG-Net
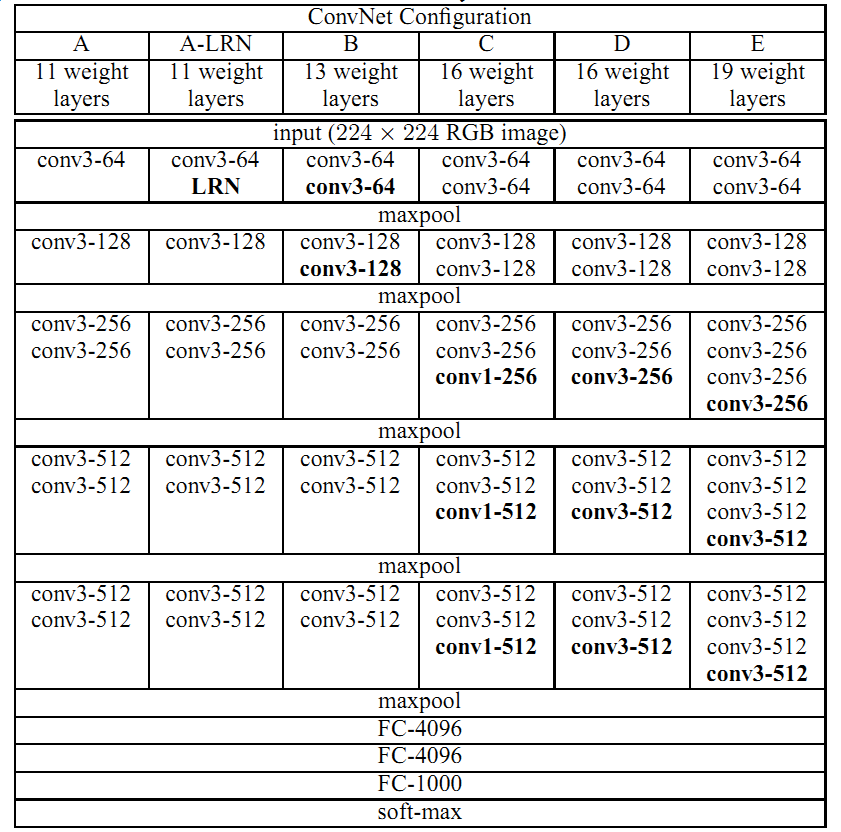
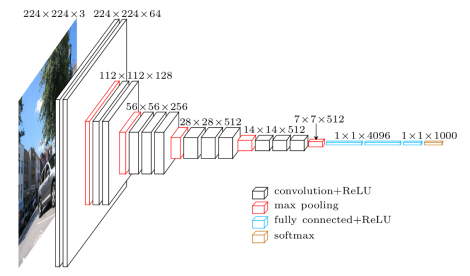
其中,最具有代表性的包括VGG16(D)和VGG19(E)。VGG與AlexNet相比,估值更精確,更省空間。改動如下:
1)增加每層中卷積層的個數(1-> 2~4)
2)降低卷積核的大小(7*7->3*3)
3)增加通道數量
下圖為VGG16的示意圖:
6.ResNet
ResNet(residual network)的top-5錯誤率為3.6%,是2015年ILSVRC大賽的冠軍。
在“平整”網路中,隨著網路層數的增加,訓練誤差也隨之增加。
如何避免訓練誤差?
假設:原始層由一個已經學會的較淺模型複製而來,附加層設定為恆等對映。
那麼,原始層與附加層疊加,至少具有與原始層相同的訓練誤差。
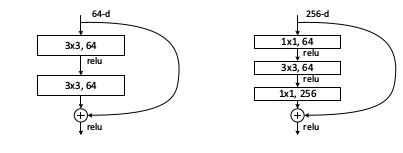
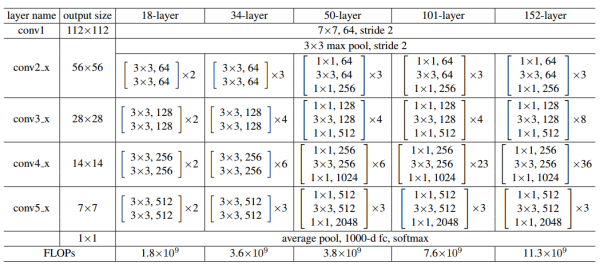
上圖左邊為resnet-34的殘差單元,右邊為resnet-50/101/152的殘差單元。
下表為典型的殘差網路結構。
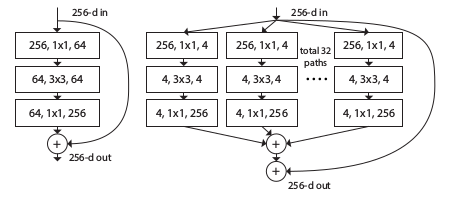
7.ResNeXt
1)同時採用VGG堆疊的思想和 GoogleNet inception的split-transform-merge的思想;
2)提出了aggregrated transformations,用一種平行堆疊相同拓撲結構的blocks代替原來的ResNet的三層卷積的block;
3)證明了增加cardinality比增加深度和寬度更有效果(cardinality:size of the set of transformations);
4)在增準確率的同時基本不改變或降低模型的複雜度。
下圖左邊是resnet的block,右邊是resnext的block,cardinality = 32
8. DenseNet
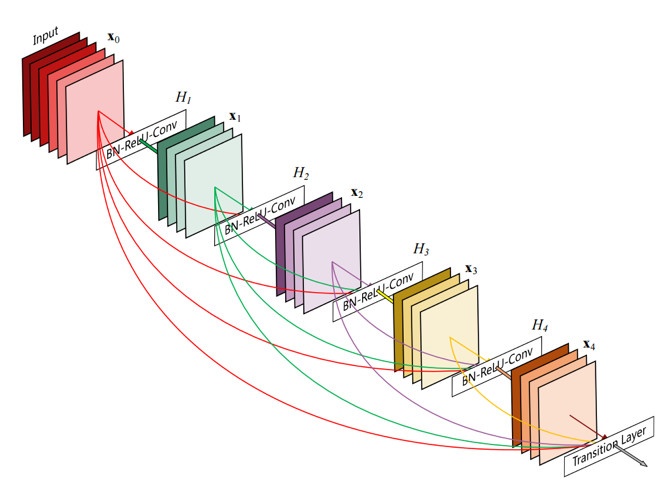
DenseNet每一層的變換:
,其中
指的是第0個到第l-1個層的連線。
類別ResNet的變換:
特點:
1)讓網路中的每一層都直接與前面層相連,實現特徵的重複利用;
2)同時把網路中的每一層都設計得比較“窄”,即只學習非常少的特徵圖(最極端情況就是每一層只學習一個特徵圖),達到降低冗餘性的目的。
優點:省引數,省計算,抗過擬合
二.目標檢測方法
1.傳統目標檢測方法
傳統目標檢測的三個階段:
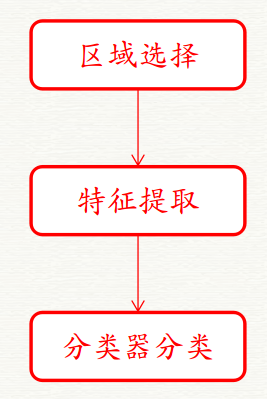
1)區域選擇:利用滑動視窗遍歷整幅影象,設定不同尺度和不同長寬比。
2)特徵提取:利用目標的形態多樣性,光照變化多樣性,背景多樣性等,進行特徵提取。常用特徵提取方法有:SIFT, HOG。
3)分類器分類:主要有SVM,Adaboost等。
缺點:
1)基於滑動視窗的區域選擇策略沒有針對性,時間複雜度高,視窗冗餘;
2)手工設計的特徵對於多樣性的變化沒有很好的魯棒性。
2.基於Region Proposal的深度學習目標檢測演算法
對於傳統目標檢測任務存在的兩個主要問題,我們該如何解決呢?
-區域選擇:Region Proposal
region proposal是預先找出圖中目標可能出現的位置。由於region proposal利用了影象中的紋理,邊緣,顏色等資訊,可以保證在選取較少視窗(幾千個甚至幾百個)的情況下保持較高的召回率。
-特徵提取+分類:CNN分類模型
獲得候選區域後可以使用CNN分類模型對其進行影象分類。
1)R-CNN(CVPR 2014, TPAMI 2015)
Rich Feature Hierarchies for Accurate Object Detection and Segmentation
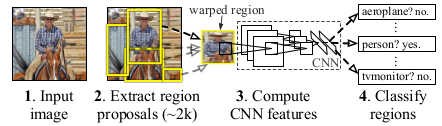
RCNN演算法分成四個步驟:
(1)一張影象生成1k~2k個候選區域;
(2)對每個候選區域,使用深度網路提取特徵;
(3)將特徵送入每一類的SVM,判斷是否屬於該類;
(4)使用迴歸器精細修正候選框位置。
效果:R-CNN在pascal voc2007上的檢測結果從DPM HSC的34.3%直接提升到了66%(mAP)。
R-CNN速度慢的原因:對影象提取region proposal(2000個左右)之後將每個proposal當成一張影象進行後續處理(利用CNN提取特徵+SVM分類),實際上對一張影象進行了2000次提取特徵和分類的過程。
2)Fast R-CNN(ICCV 2015)
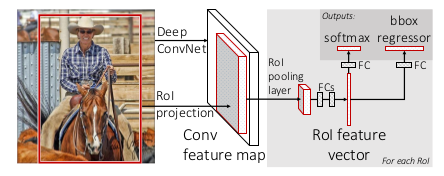
與R-CNN框架圖對比,有兩處不同:
(1)最後一個卷積層後加了一個RoI(Regions of Interest) pooling layer;
(2)損失函式使用了多工損失函式(multi-task loss),將邊框迴歸直接加入到CNN網路中進行訓練。
Fast R-CNN改進:
(1)RoI pooling layer:SPP-NET對每個proposal使用了不同大小的金字塔對映,將RoI pooling layer只需要下采樣到一個7*7的特徵圖;
(2)使用softmax代替SVM分類,將多工損失函式邊框迴歸加入到網路中:除了region proposal提取階段以外,其他的訓練過程是端到端的;
(3)微調部分卷積層。
存在問題:要先提取region proposal,沒有實現真正意義上的端到端訓練。
3)Faster R-CNN(ICCV 2015)
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
整個網路可以分為四個部分:
(1)Conv layers。首先使用一組基礎的conv+relu+pooling層提取image的feature maps。該feature maps被共享用於後續的RPN層和全連線層。
(2)Region Proposal Networks。RPN網路用於生成region proposals。該層通過softmax判斷anchors屬於foreground或者background,再利用bounding box regression來修正anchors來獲得精確的proposals。
(3)RoI Pooling。該層收集輸入的feature maps和proposals,送入後續全連線層判定目標類別。
(4)Classification。利用proposal feature maps計算proposals的類別,同時再次利用bounding box regression獲得檢測框最終的精確位置。
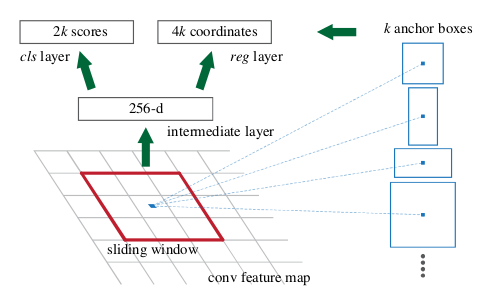
主要貢獻:提出了區域推薦網路(RPN,Region Proposal Networks),實現了真正意義上的端到端訓練。
RPN網路:在提取特徵的最後的卷積層上滑動一遍,利用anchor機制和邊框迴歸,得到多尺度多長寬比的region proposals。
Anchor機制:
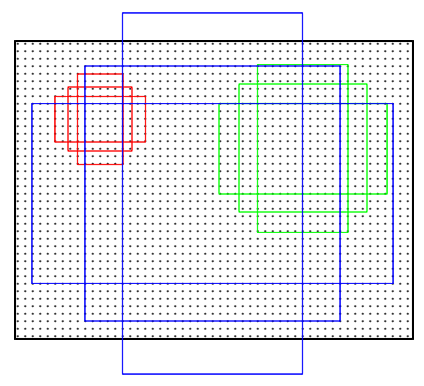
對於提取特徵的最後的卷積層的每一個位置,考慮9個可能的候選視窗:
三種面積(128*128,256*256,512*512) * 三種比例(1:1,1:2,2:1)。這些候選視窗稱為anchors。
4)Mask R-CNN(ICCV 2017)
Mask R-CNN是一個小巧靈活的通用物件例項分割框架。它不僅可以對影象中的目標進行檢測,還可以對每一個目標給出一個高質量的分割結果。它在Faster R-CNN基礎之上進行擴充套件,並行地在bounding box recognition分支上新增一個用於預測目標掩模(object mask)的新分支。
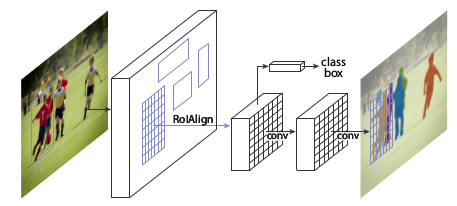
Mask R-CNN改進:
(1)基礎網路的增強:ResNeXt-101 + FPN(Feature Pyramid Network);
(2)RoI Align層的加入:即對feature map的插值,直接對RoI pooling的量化操作會使得得到的mask與實際物體位置有一個微小偏移;
(3)掩模表示:一個掩模編碼了一個輸入物件的空間佈局。使用一個FCN來對每個RoI預測一個m*m的掩模,保留了空間結構資訊;
(4)分割loss的改進:對每個類別獨立地預測一個二值掩模,沒有引入類間競爭,每個二值掩模的類別依靠網路RoI分類分支給出的分類預測結果。
Mask-RCNN比一般的state-of-the-art方法(用Faster-RCNN+ResNet-101+FPN實現)的mAP高3.6%:
1.1%來自RoI Align;0.9%來自多工訓練;1.6%來自更好的基礎網路(ResNeXt-101 + FPN).
3.基於迴歸學習的深度學習目標檢測演算法
目前的深度學習目標檢測演算法可以分為兩類:兩步檢測和一步檢測
兩步檢測:Region Proposal + CNN
Faster R-CNN的方法目前是主流的目標檢測演算法,但是速度上並不能滿足實時的要求。
一步檢測:
直接利用CNN的全域性特徵預測每個位置可能的目標。代表方法:YOLO,SSD
1)YOLO(CVPR 2016)
You Only Look Once: Unified, Real-Time Object Detection
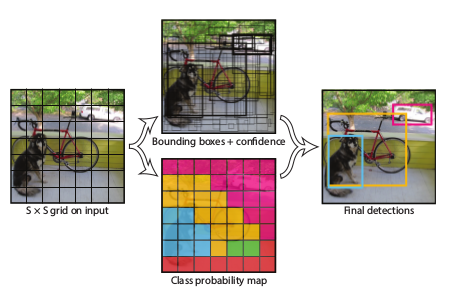
YOLO目標檢測流程:
(1)給定一個輸入影象,將影象劃分為7*7的網格;
(2)對於每個網格,都預測2個邊框;
(3)根據上一步可以預測出7*7*2個目標視窗,然後根據閾值去除可能性比較低的目標視窗,最後NMS去除冗餘視窗即可。
如何迴歸:
最後一層為7*7*30維(7*7:劃分的網格數;30維:4維座標資訊(中心點座標+長寬)+1維目標置信度+20維類別)
利用前面的4096維的全圖特徵直接在每個網格上回歸出目標檢測所需要的資訊(邊框資訊+類別)。
2)SSD(ECCV 2016)
SSD:Single Shot MultiBox Detector
SSD和YOLO的異同:
相同:SSD獲取目標位置和類別的方法和YOLO一樣,都是使用迴歸;
不同:YOLO預測某個位置使用的是全域性的特徵,SSD預測某個位置使用的是該位置周圍的特徵。
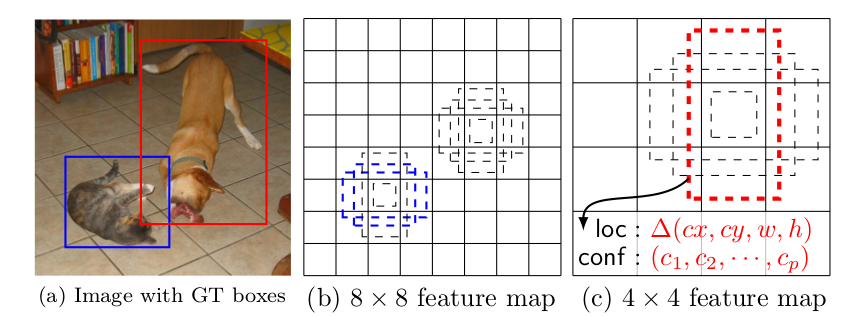
假如某一層特徵圖(圖b)大小為8×8,那麼就使用3×3的滑動視窗提取每個位置的特徵,然後進行特徵迴歸得到目標的座標資訊和類別資訊(圖c)。
如何建立某個位置和其特徵的對應關係呢?
-在多個feature map上,使用Faster RCNN的anchor機制,利用多層的特徵並且自然地達到多尺度提取。
Prior box與Faster rcnn中anchor的區別?
-相同:都是目標的預設框,沒有本質的區別;
-不同:每個位置的prior box一般是4~6個,少於Faster RCNN預設的9個;同時,prior box是設定在不同尺度的feature maps上的,而且大小不同。
4.提高目標檢測效能的方法
(1)難分樣本挖掘(hard negative mining)
R-CNN在訓練SVM分類器時使用了難分樣本挖掘的思想,但Fast R-CNN和Faster R-CNN由於使用端到端的訓練策略並沒有使用難分樣本挖掘,只是設定了正負樣本的比例並隨機抽取。CVPR2016的Training Region-based Object Detectors with Online Hard Example Mining將難分樣本挖掘(hard example mining)機制嵌入到SGD演算法中,使得Fast R-CNN在訓練的過程中根據region proposal的損失自動選取合適的region proposal作為正負例訓練。實驗結果表明使用OHEM(Online Hard Example Mining)機制可以使得Fast R-CNN演算法在VOC2007和VOC2012上mAP提高4%左右。
(2)多層特徵融合
Fast R-CNN和Faster R-CNN都是利用了最後卷積層的特徵進行目標檢測,而由於高層的卷積層特徵已經損失了很多細節資訊(pooling操作),所以在定位時不是很精確。HyperNet等一些方法則利用了CNN的多層特徵融合進行目標檢測,這不僅利用了高層特徵的語義資訊,還考慮了低層特徵的細節紋理資訊,使得目標檢測定位更精準。
(3)使用上下文資訊
在提取region proposal特徵進行目標檢測時,結合region proposal的上下文資訊,檢測效果往往會更好一些。
三.場景文字檢測方法
1.基於目標檢測
1)Symmetry-based text line detection in natural scenes(CVPR 2015)
(1)利用文字行自身上下結構的相似性:設計一個具有對稱性的模板,即在不同尺度下掃描影象,通過其相應得到對稱的中心點;
(2)在得到對稱中心點之後通過文字的高度和連通性得到邊界框(bounding box);
(3)使用CNN進行後續的處理。
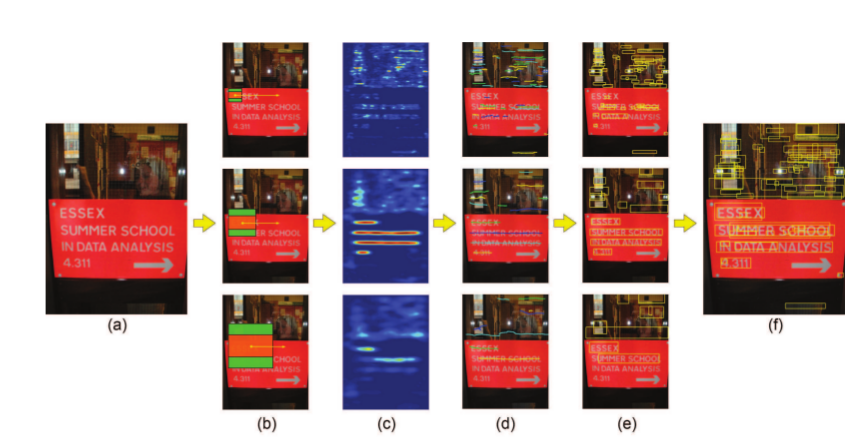
文字行proposal生成過程:
(1)輸入影象;
(2)在多維度進行特徵抽取;
(3)生成對稱概率對映圖;
(4)在對稱概率對映圖中尋找對稱軸;
(5)估計邊框;
(6)多維度提取proposal。
2)Reading Text in the Wild with Convolutional Neural Networks(IJCV 2016)
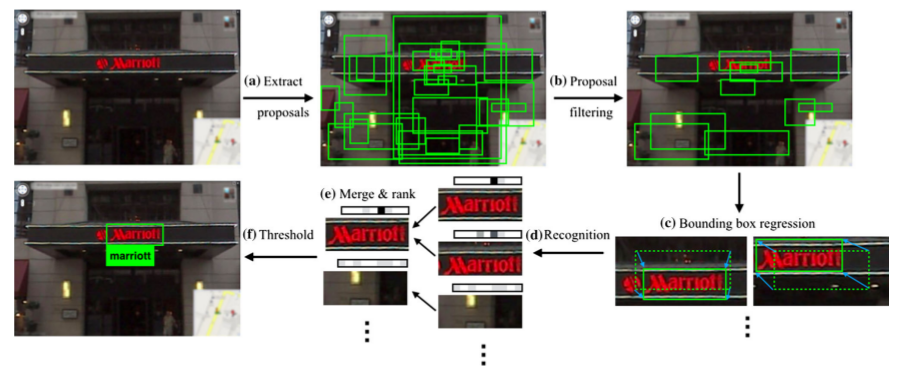
針對文字檢測問題對R-CNN進行了改造:
(1)通過edge box或者其他的handcraft feature來計算proposal;
(2)使用分類器對文字框進行分類,去掉非文字區域;
(3)使用CNN對文字框進行迴歸來得到更為精確的邊界框(bounding box regression);
(4)使用文字識別演算法進一步過濾出非文字區域。
3)Detecting Text in Natural Image with Connectionist Text Proposal Network(ECCV 2016)
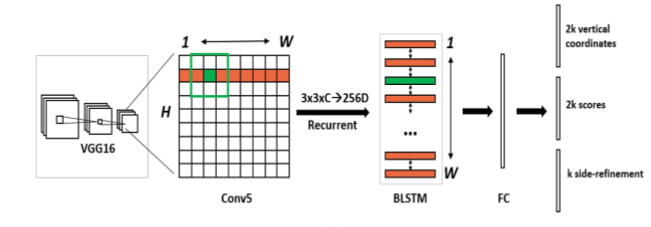
對Faster RCNN進行了改造:
(1)改進了RPN,將anchor產生的window的寬度固定為3;
(2)RPN後面不是直接連線全連線層+迴歸,而是先通過一個BLSTM,再連線一個全連線層;
(3)座標僅僅迴歸一個y,而不是x1,y1,x2,y2;
(4)新增k個anchors的side-refinement offsets。
4)Arbitrary-Oriented Scene Text Detection via Rotation Proposals(2017)
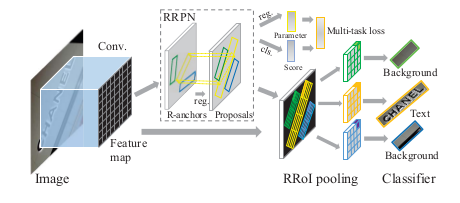
對Faster R-CNN進行了改造,將RoI pooling替換為可以快速計算任意方向的操作來對文字進行自動處理。
(1)帶角度資訊的anchor:考慮到文字的aspect ratio與一般物體的不同,因此增加了更多型別的aspect ratios;
(2)旋轉的RoI:對於RPN網路結構的輸出是帶有角度的proposal,因此在Faster-RCNN中的RoI階段需要將proposal進行旋轉後再pooling。
5)Deep matching prior network Toward tighter multi-oriented text detection(CVPR 2017)
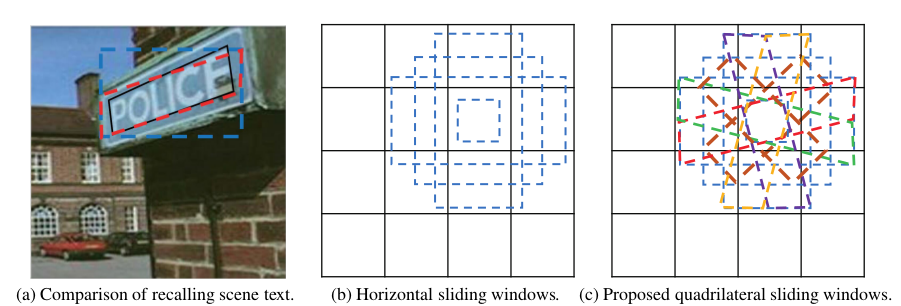
對SSD框架進行了改造:在生成proposal時迴歸矩形框不如迴歸一個任意多邊形。
6)TextBoxes: A Fast Text Detector with a Single Deep Neural Network(AAAI 2017)
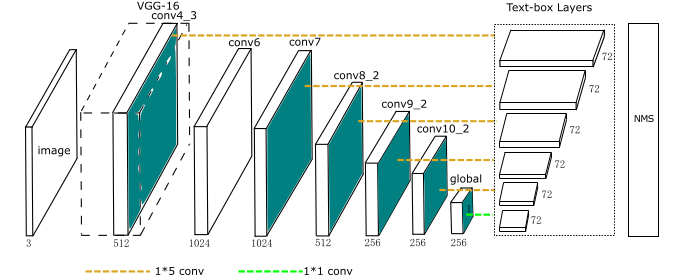
對SSD框架進行改進:
(1)設計預設框(default box)時包含較長的形狀;
(2)長方形的卷積核比常用的1*1或者3*3卷積核更適合文字檢測;
(3)使用識別模型對文字進行過濾和判斷。
7)Detecting Oriented Text in Natural Images by Linking Segments(CVPR 2017)
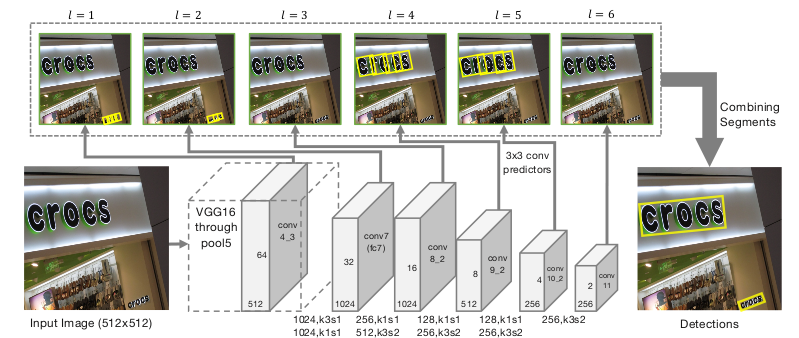
對SSD框架進行改進:
(1)將文字視為小塊單元,對文字小塊同時進行旋轉和迴歸;
(2)通過對文字小塊之間的方向性進行計算來學習文字之間的聯絡;
(3)通過簡單的後處理得到任意形狀甚至具有形變的文字檢測結果。
2.基於目標分割
1)Multi-oriented Text Detection with Fully Convolutional Networks(CVPR 2016)

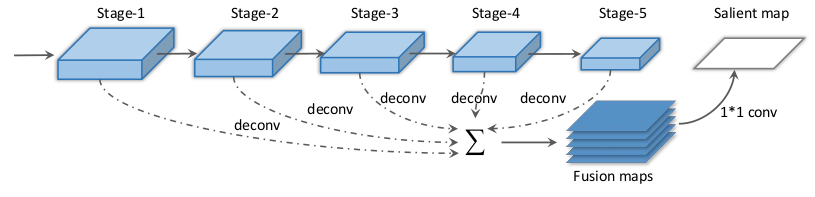
(1)將文字行視為一個需要分割的目標;
(2)通過分割得到文字的顯著性影象,得到文字的大概位置,整體方向及排列方式;
(3)結合其他的特徵進行高效的文字檢測。
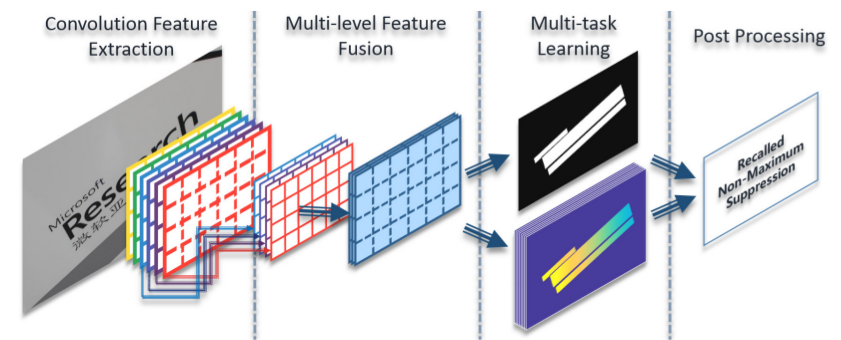
2)East: An Efficient and Accurate Scene Text Detector(CVPR 2017)
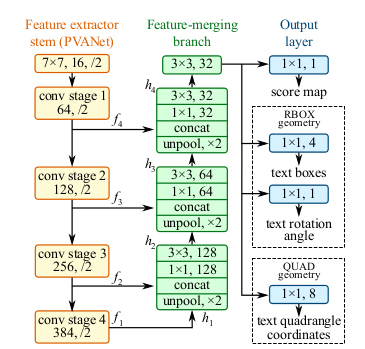
同時使用分割(segmentation)和邊界框迴歸(bounding box regression)的方式對場景文字進行檢測。
使用PVANet對網路進行優化,加速,並輸出三種不同的結果:
(1)邊緣部分分割的得分(score)結果;
(2)可旋轉的邊界框(rotated bounding boxes)的迴歸結果;
(3)多邊形bounding boxes(quadrangle bounding boxes)的結果。
同時對NMS進行改進,得到了很好的效果。
3)Deep Direct Regression for Multi-Oriented Scene Text Detection(2017)
直接對邊框進行迴歸,不產生目標邊框。