
ES建立索引、投放文件過程
阿新 • • 發佈:2019-02-08
因為之前對ES並不是太熟悉,實際工作時,在ElasticSearch和Kibanan的使用過程中,出現了好多棘手的狀況,修修補補,對於在ES上建立索引到插入文件,搜尋、查詢文件的整個流程,大概有了規範化的執行模式,以下是在本人總結的大致從建立到插入的流程,以及其中注意的一些細節。 以ES整合Kibanan為例:第一步:建立索引 在Kibanan的Dev Tools網路介面中輸入命令建立索引(其他建立索引方式,如Java API、CURL均可)Kibanan中命令為 :PUT 索引名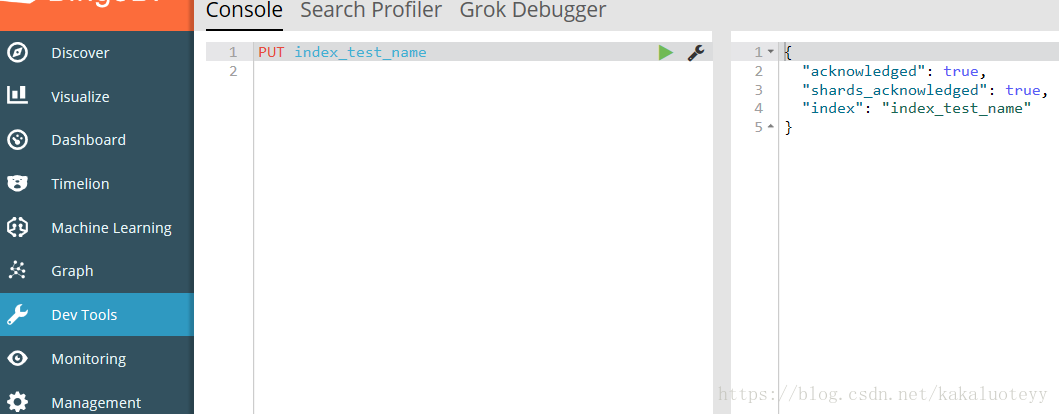 第二步:建立mapping對映,設定分詞 這一步還是很關鍵的,之前使用的時候沒有建立對映、設定分詞,導致後面使用term精確匹配的時候,“2018-05”這樣的欄位始終無法命中,因為如果沒有任何的相關設定,ES是預設分詞的,會把“2018-05”拆分成“2018”和“05”,而無法匹配”2018-05“了。建立各個欄位的對映的時候注意型別,否則後面JSON傳入文件的時候可能型別不匹配而無法插入文件。 同樣,在Kibanan的Dev Tools中,輸入如下格式命令為欄位對映type和設定分詞
第二步:建立mapping對映,設定分詞 這一步還是很關鍵的,之前使用的時候沒有建立對映、設定分詞,導致後面使用term精確匹配的時候,“2018-05”這樣的欄位始終無法命中,因為如果沒有任何的相關設定,ES是預設分詞的,會把“2018-05”拆分成“2018”和“05”,而無法匹配”2018-05“了。建立各個欄位的對映的時候注意型別,否則後面JSON傳入文件的時候可能型別不匹配而無法插入文件。 同樣,在Kibanan的Dev Tools中,輸入如下格式命令為欄位對映type和設定分詞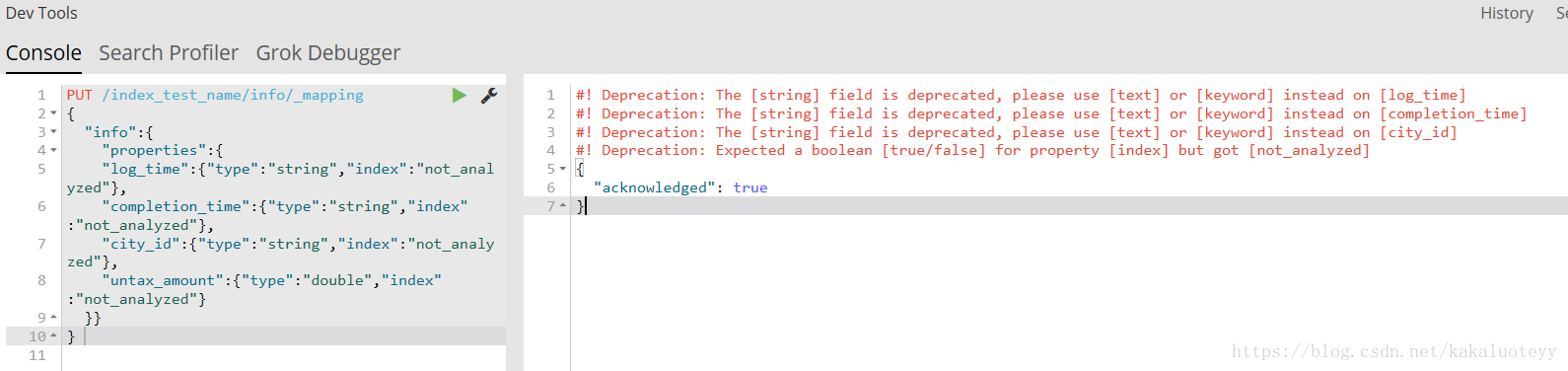 設定成功Kibanan會返回acknowledge:true,提示設定成功。後面,我們就可以新增文件了。
設定成功Kibanan會返回acknowledge:true,提示設定成功。後面,我們就可以新增文件了。
另外,在實際的使用過程中生成報表、視覺化或者聚合資料的時候可能會遇到Fielddata is disabled on text fields by default. Set fielddata=true on [state] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory
第二步:建立mapping對映,設定分詞 這一步還是很關鍵的,之前使用的時候沒有建立對映、設定分詞,導致後面使用term精確匹配的時候,“2018-05”這樣的欄位始終無法命中,因為如果沒有任何的相關設定,ES是預設分詞的,會把“2018-05”拆分成“2018”和“05”,而無法匹配”2018-05“了。建立各個欄位的對映的時候注意型別,否則後面JSON傳入文件的時候可能型別不匹配而無法插入文件。 同樣,在Kibanan的Dev Tools中,輸入如下格式命令為欄位對映type和設定分詞如上,info為該索引的type型別,log_time、completion_time、city_id、untax_amount為該索引包含的欄位,上面的對映中,我們為每一個欄位設定了資料型別type,"index":"not_analyzed"為設定該欄位不分詞,匯入文件前一定要設定好。PUT /index_test_name/info/_mapping { "info":{ "properties":{ "log_time":{"type":"string","index":"not_analyzed"}, "completion_time":{"type":"string","index":"not_analyzed"}, "city_id":{"type":"string","index":"not_analyzed"}, "untax_amount":{"type":"double","index":"not_analyzed"} }} }
設定成功Kibanan會返回acknowledge:true,提示設定成功。後面,我們就可以新增文件了。另外,在實際的使用過程中生成報表、視覺化或者聚合資料的時候可能會遇到Fielddata is disabled on text fields by default. Set fielddata=true on [state] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory
PUT index_test_name/_mapping/info
{
"properties":{
"log_time":{
"type":"text",
"fielddata":true
}
}
}