
[Spark SQL01]Spark SQL入門
1、SQL結合spark有兩條線:
Spark SQL和Hive on Spark(還在開發狀態,不穩定,暫時不建議使用)。
#Hive on Spark是在Hive中的,使用Spark作為hive的執行引擎,只需要在hive中修改一個引數即可:
# set hive.execution.engine=spark
2、Spark SQL
a.概述:
Spark SQL是Spark處理資料的一個模組,跟基本的Spark RDD的API不同,Spark SQL中提供的介面將會提供給Spark更多關於結構化資料和計算的資訊。其本質是,Spark SQL使用這些額外的資訊去執行額外的優化,這兒有幾種和Spark SQL進行互動的方法,包括SQL和Dataset API
b.SQL:
Spark SQL的一大用處就是執行SQL查詢語句,Spark SQL也可以用來從Hive中讀取資料,當我們使用其它程式語言來執行一個SQL語句,結果返回的是一個Dataset或者DataFrame.你可以使用命令列,JDBC或者ODBC的方式來與SQL進行互動。
c.Dataset和DataFrame
Dataset是一個分散式資料集合。Dataset是一個在Spark 1.6版本之後才引入的新介面,它既擁有了RDD的優點(強型別、能夠使用強大的lambda函式),又擁有Spark SQL的優點(用來一個經過優化的執行引擎)。你可以將一個JVM物件構造成一個Dataset
DataFrame是Dataset中一個有名字的列。從概念上,它等價於關係型資料庫中的一張表,或者等價於R/Python中的Data Frame,但它在底層做了更好的優化。構造DataFrame的資料來源很多:結構化的資料檔案、hive表、外部資料庫、已經存在的RDD。DataFrame 的API支援java,scal.python,R。
3、面試題
RDD VS DataFrame
esgd
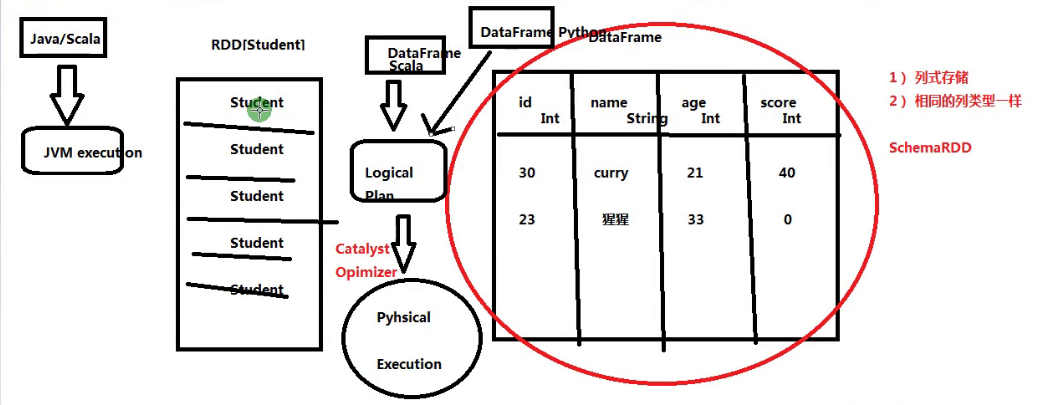
a.基於RDD的程式設計,不同語言效能是不一樣的,而DataFrame是一樣的,因為底層會有一個優化器先將程式碼進行優化。
b.對於RDD,暴露給執行引擎的資訊只有資料的型別,如RDD[Student]裝的是Student,而對於DataFrame,對於外部可見的資訊有欄位型別,欄位key,欄位value等。
c.RDD是一個數組,DataFrame是一個列式表。
4、Spark SQL願景
a.寫更少的程式碼
b.讀更少的資料(壓縮,儲存格式,列裁剪)
c.對於不同語言的應用程式讓優化器自動進行優化
5、Spark SQL架構
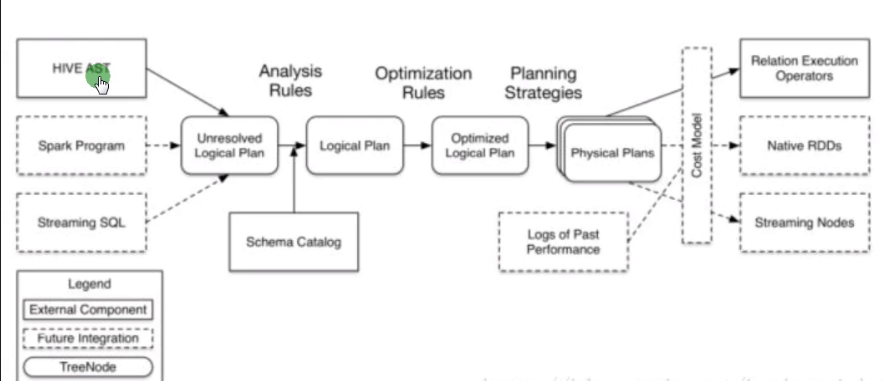
客戶端->未解析的邏輯執行計劃(Schema Catalog 將schema作用在資料上)->邏輯執行計劃->優化過後的邏輯執行計劃->物理執行計劃->Spark引擎。
#Spark SQL 要使用hive中的表,需要將hive-site.xml加入spark的配置檔案目錄。
6、執行計劃(Hive 或Spark SQL)
explain extended +查詢語句
7、SparkSession
新增依賴:
<dependency>
<groupId>org.spark.apache</groupId>
<artifactId>spark-sql_2.11</artifactId> ##2.11位scala版本
<version>${spark.version}</version>
</dependency>
Spark中所有功能的入口點是SparkSession類,我們可以使用SparkSession.builder()來建立一個SparkSession,具體如下(scala):
import org.apache.spark.sql.SparkSession val spark = SparkSession .builder() .appName("Spark SQL basic example") .config("spark.some.config.option", "some-value") .getOrCreate() // For implicit conversions like converting RDDs to DataFrames import spark.implicits._
可以在spark repo下的"examples/src/main/scala/org/apache/spark/examples/sql/SparkSQLExample.scala" 路徑下找到所有例子的程式碼。
在Spark 2.0之後,SparkSession內建了對於hive特性的支援,允許使用HiveQL來書寫查詢語句訪問UDF,以及從Hive表中讀取資料。使用這些特性,你不需要進行任何Hive的設定。
8、建立DataFrame
通過SparkSession,應用程式可以從一個現有的RDD、Hive表、Spark資料來源來建立一個DataFrame。
以下建立DataFrame是基於JSON格式的檔案:
val df = spark.read.json("examples/src/main/resources/people.json") // Displays the content of the DataFrame to stdout df.show() // +----+-------+ // | age| name| // +----+-------+ // |null|Michael| // | 30| Andy| // | 19| Justin| // +----+-------+可以在spark repo下的"examples/src/main/scala/org/apache/spark/examples/sql/SparkSQLExample.scala" 路徑下找到所有例子的程式碼。
9、無型別的Dataset操作(又稱DataFrame 操作)
上面提到的,在Spark 2.0時,在java或者scala API中,DataFrame是Dataset的行,這些操作也被稱為“非型別轉換”,與“型別化轉換”相比,具有強型別的Scala/Java Dataset。
這兒包括一些使用Dataset處理結構化資料的例子:
// This import is needed to use the $-notation import spark.implicits._ // Print the schema in a tree format df.printSchema() // root // |-- age: long (nullable = true) // |-- name: string (nullable = true) // Select only the "name" column df.select("name").show() // +-------+ // | name| // +-------+ // |Michael| // | Andy| // | Justin| // +-------+ // Select everybody, but increment the age by 1 df.select($"name", $"age" + 1).show() // +-------+---------+ // | name|(age + 1)| // +-------+---------+ // |Michael| null| // | Andy| 31| // | Justin| 20| // +-------+---------+ // Select people older than 21 df.filter($"age" > 21).show() // +---+----+ // |age|name| // +---+----+ // | 30|Andy| // +---+----+ // Count people by age df.groupBy("age").count().show() //groupBy返回一個Dataset,count返回一個DataFrame. // +----+-----+ // | age|count| // +----+-----+ // | 19| 1| // |null| 1| // | 30| 1| // +----+-----+
可以在spark repo下的"examples/src/main/scala/org/apache/spark/examples/sql/SparkSQLExample.scala" 路徑下找到所有例子的程式碼。
對於可以在資料集上執行的操作型別的完整列表,請參閱API Documentation。
除了簡單的列引用和表示式之外,資料集還擁有豐富的函式庫,包括字串操作、日期算術、常見的數學運算等等。完整列表檢視DataFrame Function Reference.
10、以程式設計方式執行SQL查詢語句
SparkSession中的SQL函式可以讓應用程式以程式設計的方式執行SQL查詢語句,讓結果返回一個DataFrame。
// Register the DataFrame as a SQL temporary view df.createOrReplaceTempView("people") val sqlDF = spark.sql("SELECT * FROM people") sqlDF.show() // +----+-------+ // | age| name| // +----+-------+ // |null|Michael| // | 30| Andy| // | 19| Justin| // +----+-------+
可以在spark repo下的"examples/src/main/scala/org/apache/spark/examples/sql/SparkSQLExample.scala" 路徑下找到所有例子的程式碼。
11、全域性臨時檢視
Spark SQL中的臨時檢視作用域僅僅在於建立該檢視的會話視窗,如果視窗關閉,該檢視也終止。如果你想要一個在所有會話中都生效的臨時檢視,並且即使應用程式終止該檢視仍然存活,你可以建立一個全域性臨時檢視。 全域性臨時檢視與系統儲存資料庫global_temp相關聯,我們必須使用規範的名字來定義它,比如:SELECT * FROM global_temp.view1.
// Register the DataFrame as a global temporary view df.createGlobalTempView("people") // Global temporary view is tied to a system preserved database `global_temp` spark.sql("SELECT * FROM global_temp.people").show() // +----+-------+ // | age| name| // +----+-------+ // |null|Michael| // | 30| Andy| // | 19| Justin| // +----+-------+ // Global temporary view is cross-session spark.newSession().sql("SELECT * FROM global_temp.people").show() // +----+-------+ // | age| name| // +----+-------+ // |null|Michael| // | 30| Andy| // | 19| Justin| // +----+-------+可以在spark repo下的"examples/src/main/scala/org/apache/spark/examples/sql/SparkSQLExample.scala" 路徑下找到所有例子的程式碼。
12、建立Dataset
Dataset有點像RDD,但它並不是使用java或Kryo這樣的序列化方式,而是使用專用的編碼器將物件進行序列化,以便於在網路上進行處理和傳輸。雖然編碼器和標準的序列化都可以將物件轉成位元組,但編碼器產生動態的程式碼,它使用的格式允許Spark在不執行反序列化的情況下去執行像過濾、排序、雜湊等許許多多的操作。
case class Person(name: String, age: Long) // Encoders are created for case classes val caseClassDS = Seq(Person("Andy", 32)).toDS() caseClassDS.show() // +----+---+ // |name|age| // +----+---+ // |Andy| 32| // +----+---+ // Encoders for most common types are automatically provided by importing spark.implicits._ val primitiveDS = Seq(1, 2, 3).toDS() primitiveDS.map(_ + 1).collect() // Returns: Array(2, 3, 4) // DataFrames can be converted to a Dataset by providing a class. Mapping will be done by name val path = "examples/src/main/resources/people.json" val peopleDS = spark.read.json(path).as[Person] peopleDS.show() // +----+-------+ // | age| name| // +----+-------+ // |null|Michael| // | 30| Andy| // | 19| Justin| // +----+-------+