
模式識別(Pattern Recognition)學習筆記(十二)--SVM(廣義):大間隔
在學習之前,先說一些題外話,由於博主學習模式識別沒多久,所以可能對許多問題還沒有深入的認識和正確的理解,如有不妥,還望海涵,另請各路前輩不吝賜教。
好啦,我們開始學習吧。。
同樣假設有樣本集:
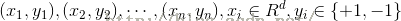
由於線性不可分,所以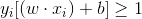
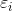
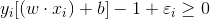
當樣本出現錯分時,則該樣本對應的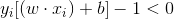
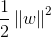
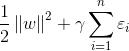
在上述目標函式中,我們的目的有兩個:(1)使分類間隔儘可能大;(2)使錯分程度儘可能小;gamma表示在上述兩個目的之間的平衡引數,這個引數比較重要,值的選擇很關鍵,值太大時,說明我們對樣本錯分的容忍小,值太小,說明對錯分容忍稍大,而比較重視大間隔分類。
基於上面兩個期望,同樣使用拉格朗日乘法來求解:
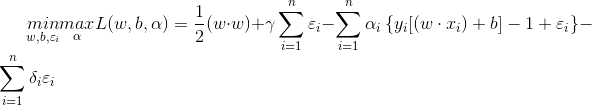
對上式泛函求導,得到下面的解:
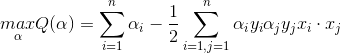
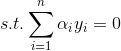
注意,這裡的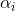
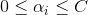
另外得到w的解:
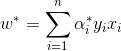
於是廣義問題的判別函式為:
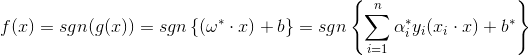
到這裡,你會發現上面幾個式子和線性可分下的完全一模一樣,唯一的不同是
下面,來看一看這種情況下的支援向量都有哪些樣本組成。
根據庫恩-塔克條件,泛函的鞍點出滿足以下式子:
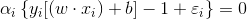
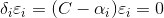
對右邊式子來說,
對左邊式子來說,與之前分析的一樣,{}中的那一項等於0時,才有可能使得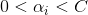
至此,可以發現,線性不可分的情況包含了可分的情況的,所以我們通常所說的SVM其實就是廣義的最優分類面形式,即無需考慮樣本可分不可分。