
DetNet或Faster R-CNN實時視訊流demo(pytorch版)
最近要使用faster-rcnn,DetNet-FPN以及Light-Head三種目標檢測方案訓練自己的資料集,並做一個比較。在GitHub上搜羅了一番,發現下面三個開源專案一脈相承,正合我意。期中DetNet_pytorch和pytorch-lighthead我認為都是基於faster-rcnn.pytorch這個專案改的,作者貌似是佐治亞理工的Ph.D.,確實是高手中的高高手,程式碼寫得很流暢。我三個專案都fork了下來,做了不少的修改以適配自己的資料集(不能一天到晚玩coco、voc嘛),期中faster-rcnn.pytorch和DetNet_pytorch都成功地進行了適配並做了大量實驗,唯獨pytorch-lighthead死活沒有搞成功。哎,暫且不管了,考慮到我自己的資料集分類數很有限,用lighthead理論上並不會有啥優勢。事實上,我後面嘗試了LightHead的tensorflow版本,也印證了我的想法,mAP差異甚小。
以使用的較多的DetNet_pytorch為例,配合程式碼介紹視訊流demo(輸入為視訊檔案而非單張圖片)。對於DetNet的實現原理,不再做過多闡述,這一部分網路上已有大量詳細介紹的文章。
1. 準備
按照作者文件上的要求安裝好一些依賴包,這個過程可能會有一點小挫折,別一開始就放棄。
- Python 2.7 or 3.6
- Pytorch 0.2.0 or higher(not support pytorch version >=0.4.0)
- CUDA 8.0 or higher
從Git上下載程式碼,完成編譯。編譯也有可能遇到錯誤,繼續鍛鍊你Linux運維能力。
cd lib
sh make.sh
2.程式碼調整
作者已經提供了一個demo.py的程式,雖然不是我想要的視訊流demo,但主體架構沒問題,只要在這上面進行二次開發即可。以下是我修改後的demo.py程式,以供參考。如果是想要修改為faster rcnn版的視訊流demo也是很容易的,可自行修改。
# coding: utf-8 # -------------------------------------------------------- # Tensorflow Faster R-CNN # Licensed under The MIT License [see LICENSE for details] # Written by Jiasen Lu, Jianwei Yang, based on code from Ross Girshick # -------------------------------------------------------- from __future__ import absolute_import from __future__ import division from __future__ import print_function import _init_paths import os import sys import numpy as np import argparse import pprint import pdb import time import cv2 import cPickle import torch from torch.autograd import Variable import torch.nn as nn import torch.optim as optim import glob import torchvision.transforms as transforms import torchvision.datasets as dset from PIL import Image from scipy.misc import imread from roi_data_layer.roidb import combined_roidb from roi_data_layer.roibatchLoader import roibatchLoader from model.utils.config import cfg, cfg_from_file, cfg_from_list, get_output_dir from model.rpn.bbox_transform import clip_boxes from model.nms.nms_wrapper import nms from model.rpn.bbox_transform import bbox_transform_inv from model.utils.net_utils import save_net, load_net, vis_detections from model.utils.blob import prep_im_for_blob,im_list_to_blob import pdb from model.fpn.detnet_backbone import detnet import warnings warnings.filterwarnings("ignore") def parse_args(): """ Parse input arguments """ #減少篇幅,此處省略若干 args = parser.parse_args() return args lr = cfg.TRAIN.LEARNING_RATE momentum = cfg.TRAIN.MOMENTUM weight_decay = cfg.TRAIN.WEIGHT_DECAY def get_image_blob(im): """Converts an image into a network input. Arguments: im: data of image Returns: blob (ndarray): a data blob holding an image pyramid im_scale_factors (list): list of image scales (relative to im) used in the image pyramid """ im_scales = [] processed_ims = [] scale_inds = np.random.randint(0, high=len(cfg.TRAIN.SCALES), size=1) target_size = cfg.TRAIN.SCALES[scale_inds[0]] im, im_scale = prep_im_for_blob(im, cfg.PIXEL_MEANS, cfg.PIXEL_STDS, target_size, cfg.TRAIN.MAX_SIZE) im_scales.append(im_scale) processed_ims.append(im) # Create a blob to hold the input images blob = im_list_to_blob(processed_ims) return blob, im_scales if __name__ == '__main__': args = parse_args() print('Called with args:') print(args) args.cfg_file = "cfgs/{}.yml".format(args.net) if args.cfg_file is not None: cfg_from_file(args.cfg_file) if args.set_cfgs is not None: cfg_from_list(args.set_cfgs) #print('Using config:') #pprint.pprint(cfg) np.random.seed(cfg.RNG_SEED) cfg.TRAIN.USE_FLIPPED = False # train set # -- Note: Use validation set and disable the flipped to enable faster loading. if args.exp_name is not None: input_dir = args.load_dir + "/" + args.net + "/" + args.dataset + '/' + args.exp_name else: input_dir = args.load_dir + "/" + args.net + "/" + args.dataset if not os.path.exists(input_dir): raise Exception('There is no input directory for loading network from ' + input_dir) load_name = os.path.join(input_dir, 'fpn_{}_{}_{}.pth'.format(args.checksession, args.checkepoch, args.checkpoint)) classes = cfg.TRAIN.CLASSES fpn = detnet(classes, 59, pretrained=False, class_agnostic=args.class_agnostic) fpn.create_architecture() print('load checkpoint %s' % (load_name)) checkpoint = torch.load(load_name) fpn.load_state_dict(checkpoint['model']) if 'pooling_mode' in checkpoint.keys(): cfg.POOLING_MODE = checkpoint['pooling_mode'] # initilize the tensor holder here. im_data = torch.FloatTensor(1) im_info = torch.FloatTensor(1) num_boxes = torch.LongTensor(1) gt_boxes = torch.FloatTensor(1) # ship to cuda if args.ngpu > 0: im_data = im_data.cuda() im_info = im_info.cuda() num_boxes = num_boxes.cuda() gt_boxes = gt_boxes.cuda() # make variable im_data = Variable(im_data, volatile=True) im_info = Variable(im_info, volatile=True) num_boxes = Variable(num_boxes, volatile=True) gt_boxes = Variable(gt_boxes, volatile=True) if args.ngpu > 0: cfg.CUDA = True if args.ngpu > 0: fpn.cuda() fpn.eval() max_per_image = 100 thresh = 0.05 vis_thresh = 0.8 vis = True if not os.path.exists(args.video_file): raise Exception("video %s not exist".format(args.video_file)) vc = cv2.VideoCapture(args.video_file) i = 0 while True: i += 1 _, im = vc.read() if im is None: break blobs, im_scales = get_image_blob(im) assert len(im_scales) == 1, "Only single-image batch implemented" im_blob = blobs # (h,w,scale) im_info_np = np.array([[im_blob.shape[1], im_blob.shape[2], im_scales[0]]], dtype=np.float32) im_data_pt = torch.from_numpy(im_blob) # exchange dimension->(b,c,h,w) im_data_pt = im_data_pt.permute(0, 3, 1, 2) im_info_pt = torch.from_numpy(im_info_np) #im_info_pt = im_info_pt.view(3) im_data.data.resize_(im_data_pt.size()).copy_(im_data_pt) im_info.data.resize_(im_info_pt.size()).copy_(im_info_pt) gt_boxes.data.resize_(1, 1, 5).zero_() num_boxes.data.resize_(1).zero_() det_tic = time.time() rois, cls_prob, bbox_pred, \ _, _, _, _, _ = fpn(im_data, im_info, gt_boxes, num_boxes) #pdb.set_trace() scores = cls_prob.data boxes = rois.data[:, :, 1:5] if cfg.TEST.BBOX_REG: # Apply bounding-box regression deltas box_deltas = bbox_pred.data if cfg.TRAIN.BBOX_NORMALIZE_TARGETS_PRECOMPUTED: # Optionally normalize targets by a precomputed mean and stdev if args.class_agnostic: box_deltas = box_deltas.view(-1, 4) * torch.FloatTensor(cfg.TRAIN.BBOX_NORMALIZE_STDS).cuda() \ + torch.FloatTensor(cfg.TRAIN.BBOX_NORMALIZE_MEANS).cuda() box_deltas = box_deltas.view(1, -1, 4) else: box_deltas = box_deltas.view(-1, 4) * torch.FloatTensor(cfg.TRAIN.BBOX_NORMALIZE_STDS).cuda() \ + torch.FloatTensor(cfg.TRAIN.BBOX_NORMALIZE_MEANS).cuda() box_deltas = box_deltas.view(1, -1, 4 * len(classes)) #pdb.set_trace() pred_boxes = bbox_transform_inv(boxes, box_deltas, 1) pred_boxes = clip_boxes(pred_boxes, im_info.data, 1) else: # Simply repeat the boxes, once for each class pred_boxes = np.tile(boxes, (1, scores.shape[1])) pred_boxes /= im_scales[0] scores = scores.squeeze() pred_boxes = pred_boxes.squeeze() det_toc = time.time() detect_time = det_toc - det_tic if vis: im2show = np.copy(im) sys.stdout.write('im_detect: {:d} {:.3f}s \r'.format(i, detect_time)) sys.stdout.flush() for j in xrange(1, len(classes)): # 0 for background inds = torch.nonzero(scores[:,j] > thresh).view(-1) # if there is det if inds.numel() > 0: cls_scores = scores[:,j][inds] # confidence of the specified class _, order = torch.sort(cls_scores, 0, True) # sorted scores and indexes if args.class_agnostic: cls_boxes = pred_boxes[inds, :] else: cls_boxes = pred_boxes[inds][:, j * 4:(j + 1) * 4] cls_dets = torch.cat((cls_boxes, cls_scores.unsqueeze(1)), 1) # cls_dets = torch.cat((cls_boxes, cls_scores), 1) cls_dets = cls_dets[order] keep = nms(cls_dets, cfg.TEST.NMS) # after nms cls_dets = cls_dets[keep.view(-1).long()] # keep shape is ?x1 if vis: # cls_dets.cpu().numpy() make tensor->numpy array im2show = vis_detections(im2show, classes[j], cls_dets.cpu().numpy(), vis_thresh) #drawpath = os.path.join('images', "{}.jpg".format(i)) #cv2.imwrite(drawpath, im2show) cv2.imshow('demo', im2show) if (cv2.waitKey(25) & 0xFF) == ord('q'): break vc.release() cv2.destroyAllWindows()
3.執行
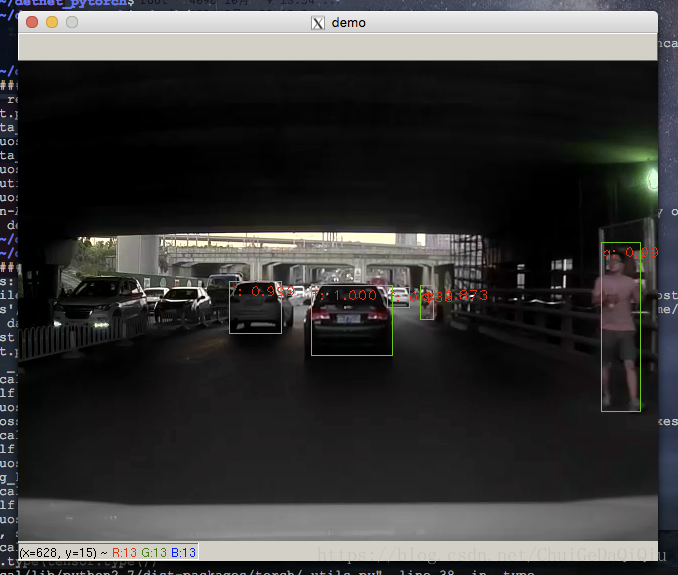
【程式碼】